Kafka Broker总体工作流程
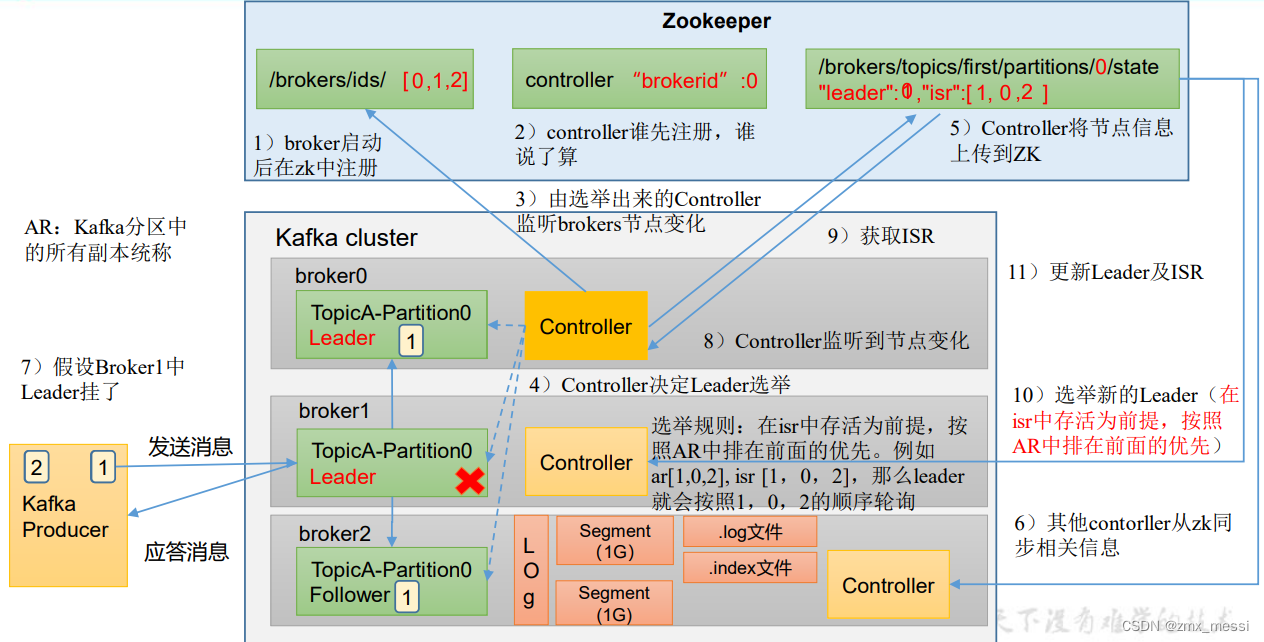
上面是Zookeeper集群,下面是Kafka集群,两个集群通信:
????????1)每台Kafka Broker节点启动之后,都会向Zookeeper进行注册,告诉他,我开启了。Zookeeper注册[0,1,2];三台Broker启动之后,在Zookeeper里的/brokers/ids/就会增加三个节点;
????????2)? ?注册完毕之后,Zookeeper就会选择Controller节点,每台Kafka Broke里面都有一个Controller,谁会成为未来Leader选举的老大呢?controller谁先注册,谁说了算,他们争先抢占名额,谁抢到了,谁负责日后Leader选举,假设broker0中的Controller抢到了;
? ? ? ? 3)上任第一天,由选举出来的Controller 监听brokers节点变化,随后Controller决定Leader选举。先来解释一下AR,AR:Kafka分区中 的所有副本统称。选举规则:在isr中存活为前提,按 照AR中排在前面的优先。例如 ar[1,0,2], isr [1,0,2],那么leader 就会按照1,0,2的顺序轮询;
? ? ? ? 4) 假设现在选举出来Broker1为Leader,Controller将节点信息上传到ZK进行备份,告诉它我选了Broker1为Leader, isr 为[1,0,2],(图中的5);
? ? ? ? 5)?其他contorller从zk同步相关信息,这样如果Controller Leader挂了,他们随时准备上位;
? ? ? ? 6)生产者往集群里发送数据,Follower主动跟Leader同步信息,底层存储的是Segment,大小1G;
? ? ? ? 7)集群应答,假设Leader挂了,Controller就能够监控到节点变化,从Zookeeper获取ISR,重新选举,选举规则一致,选举新的Leader之后,更新Zookeeper中的信息(Leader及ISR)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!