GEE:如何解决随机森林分类器的确定性伪随机性?使得每次运行OA和Kappa等不一样
2023-12-21 16:54:53
作者:CSDN @ _养乐多_
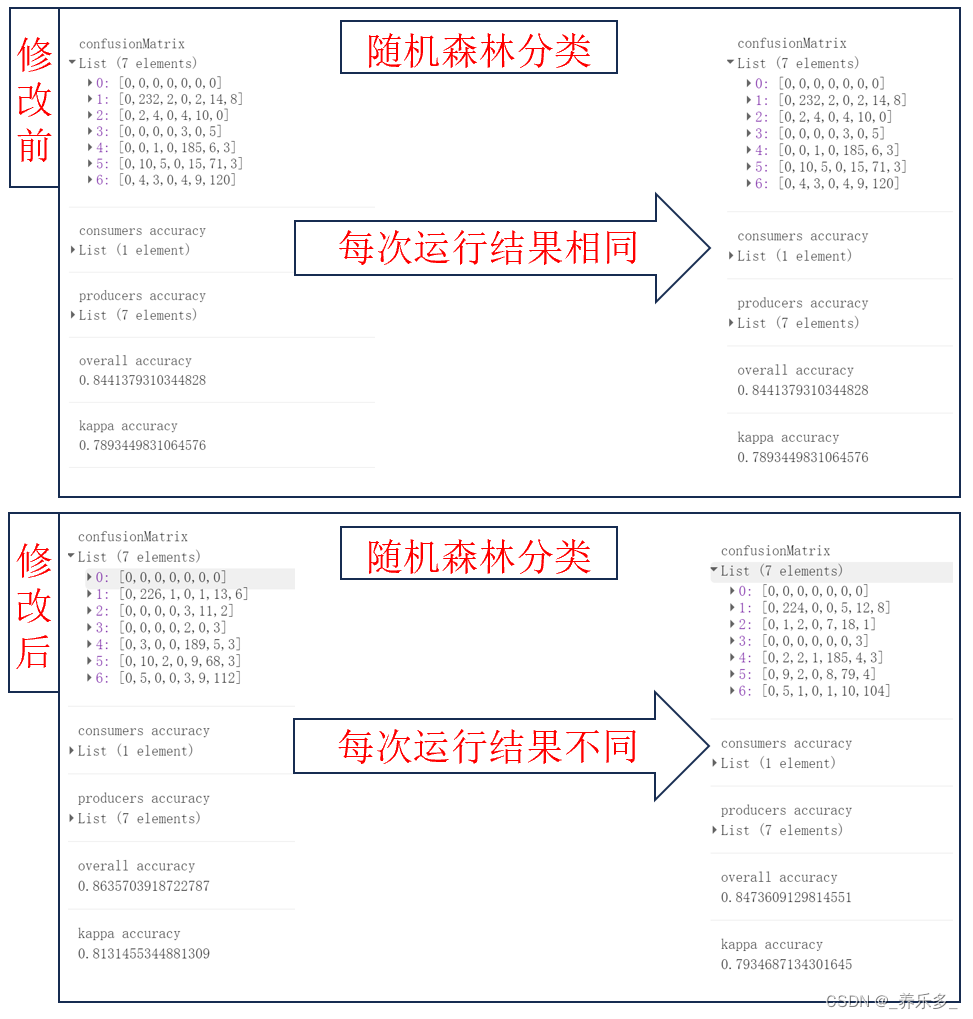
在使用 Google Earth Engine(GEE)平台进行土地利用分类时,我们采用了随机森林分类器。理论上,由于该算法的随机性,每次运行后的分类结果应该是不同的。然而,我们在实际应用中却观察到每次运行后总体精度OA值和Kappa值都呈现出完全相同的结果。
这种现象引发了对于实验结果的稳定性和随机性控制的深入思考。随机森林算法的随机性源自两个主要方面:首先,每个决策树的训练数据是通过有放回抽样(bootstrap)得到的;其次,在每个节点上,特征的选择是随机进行的。尽管如此,为了确保结果的可重复性和可对比性,GEE上的随机森林分类器采用了随机数生成器的固定种子(seed)。通过在每次运行中使用相同的随机数种子,算法的随机性被控制,导致每次运行的结果都保持一致。
本文将介绍如何在GEE中增加随机森林分类器的变异性,使得每次运行的结果都不同,从而更好地理解和优化土地利用分类的结果。
文章目录
文章来源:https://blog.csdn.net/qq_35591253/article/details/135125690
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!