生成对抗网络——研讨会
时隔一年,再跟着李沐大师学习了GAN之后,仍旧没能在离散优化中实现通用的应用,实在惭愧,借着组内研讨会的机会,再队GAN的前世今生做一个简单的综述。
GAN产生的背景
目前与GAN相关的应用
去reddit社区的机器学习板块,可以看到很多网友提出GAN的应用
1.将韩国明星和马斯克的脸替换到JOJO的人物脸上

2. 视频里换脸,换背景。把一个真人的采访视频的脸换成动漫的。

3.给一个人的照片,再给个发型颜色,给照片里的人换发型。

4.把视频里的人脸换成动漫的脸,并且让动漫人物做出和人相同的动作。

这种换脸技术的出现,让加州颁布法律,明令禁止,这种换脸技术用到官员身上,避免用公众人物的样貌说出一些社会影响恶劣的话。
GAN文献检索结果
GAN 这篇文章2014年发表在NIPS上,到2023年12月3号已经有6w多次引用了。
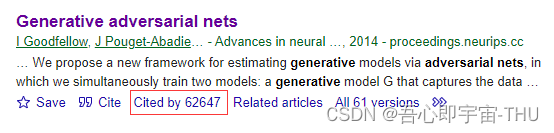
在WOS的已入库能检索的SCI论文关于GAN为主题的就有1.7w篇之多。
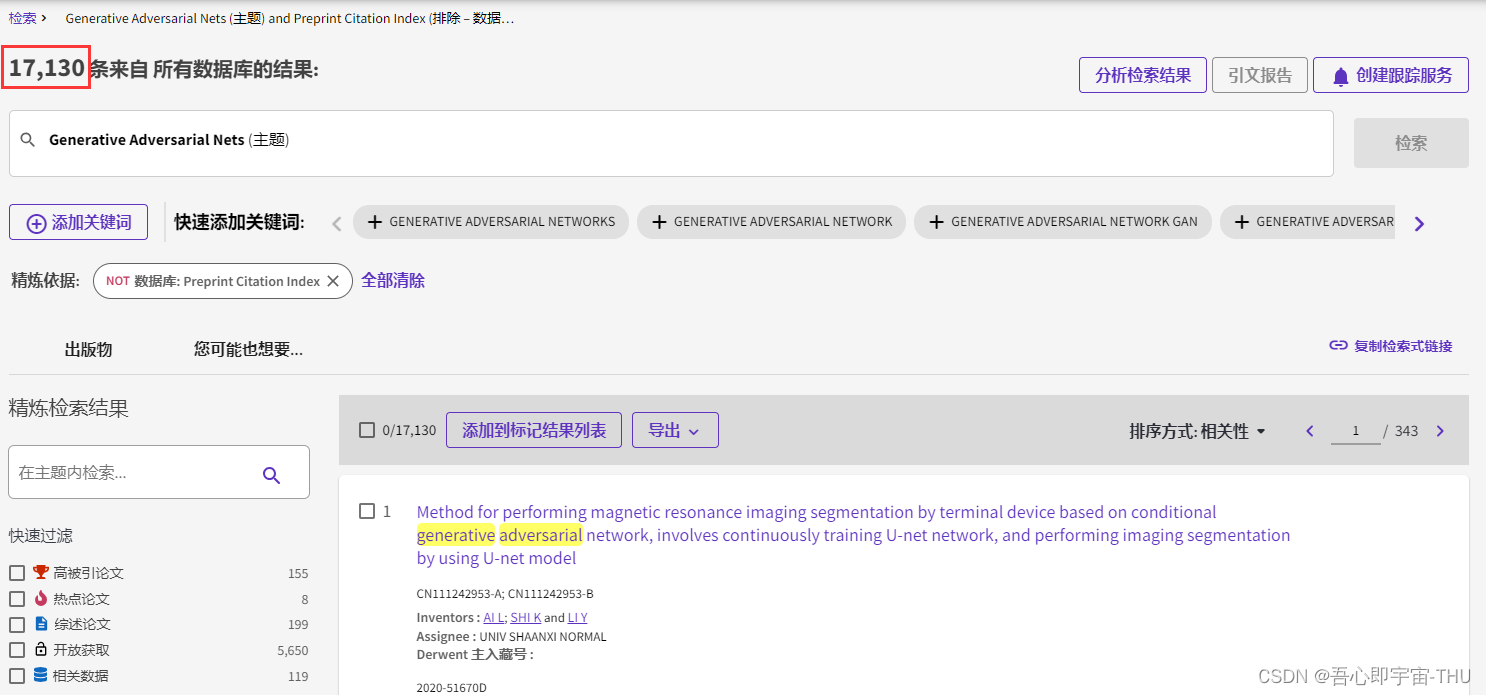
从出版的数量来看,从14年开始GAN横空出世后,每年的文章数量猛增,目前在每年4000篇左右的数量。可见热度及其高。

以GAN为标题的直接的文章有448篇。
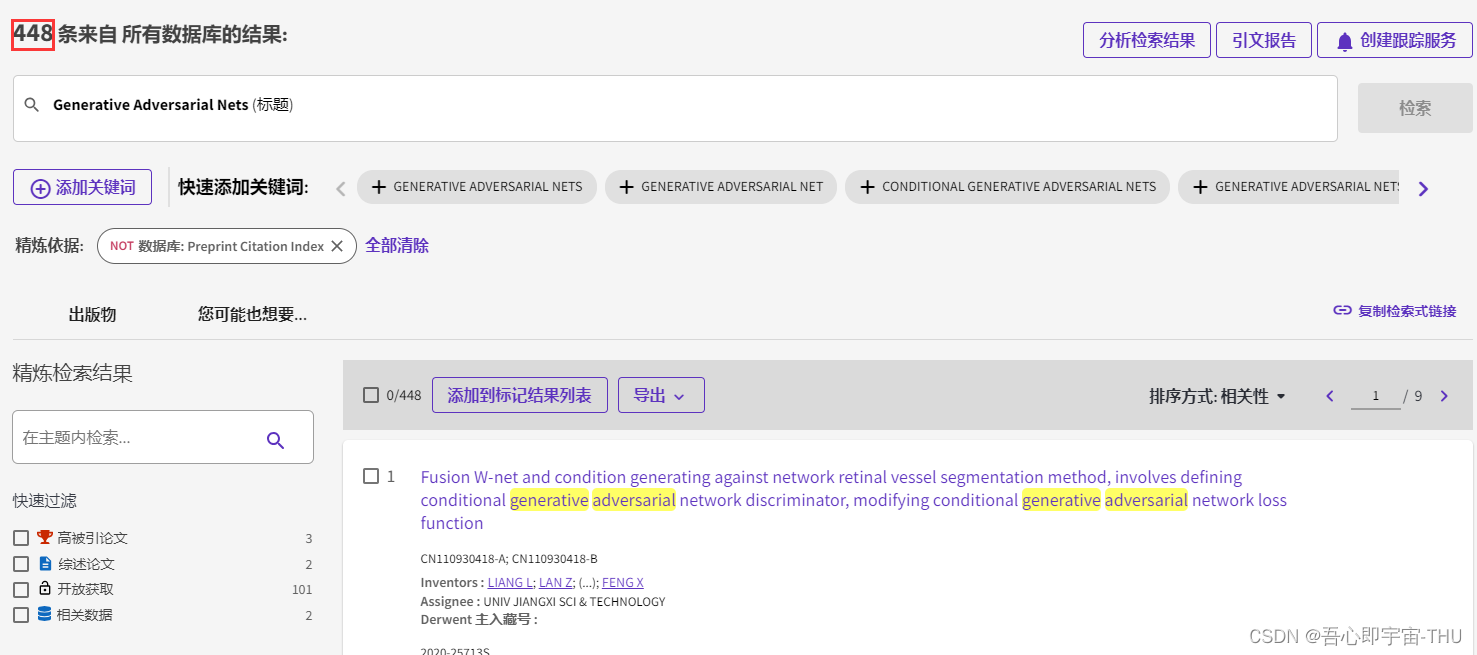
在知网中检索中文论文,以生成对抗网络为主题可以检索出7000多篇论文,其中一半以上是学位论文,4000篇是关于自动化技术。可见在国内期刊上,GAN也是十分火热的研究热点。
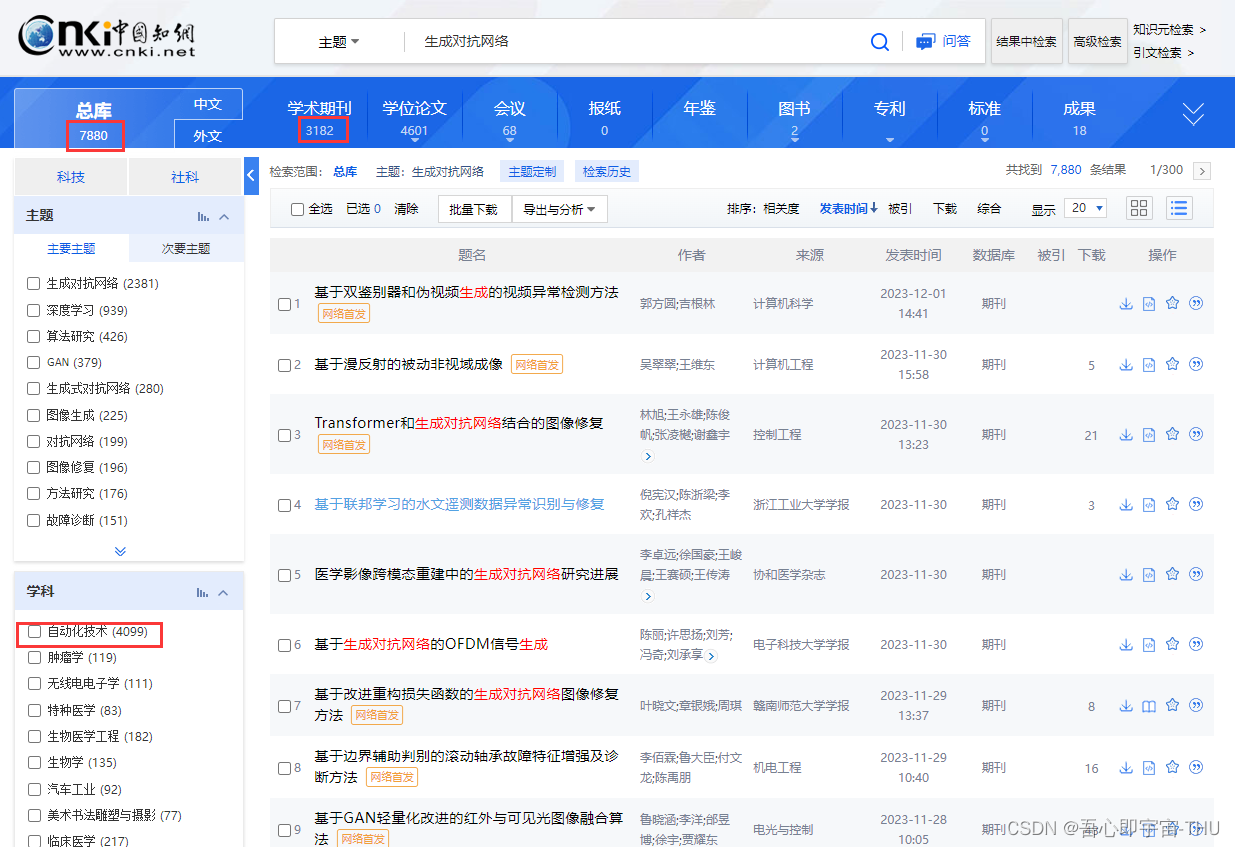
在19年到现在,每年都有1000多篇论文是讨论GAN的。
GAN之父——Ian的简介
希望简单介绍作者的成长背景,为大家提供借鉴,学习别人的成长路径,如何规划自己的学术生涯,以及如何做出开创性的工作,当时是什么情况,是如何想到的。
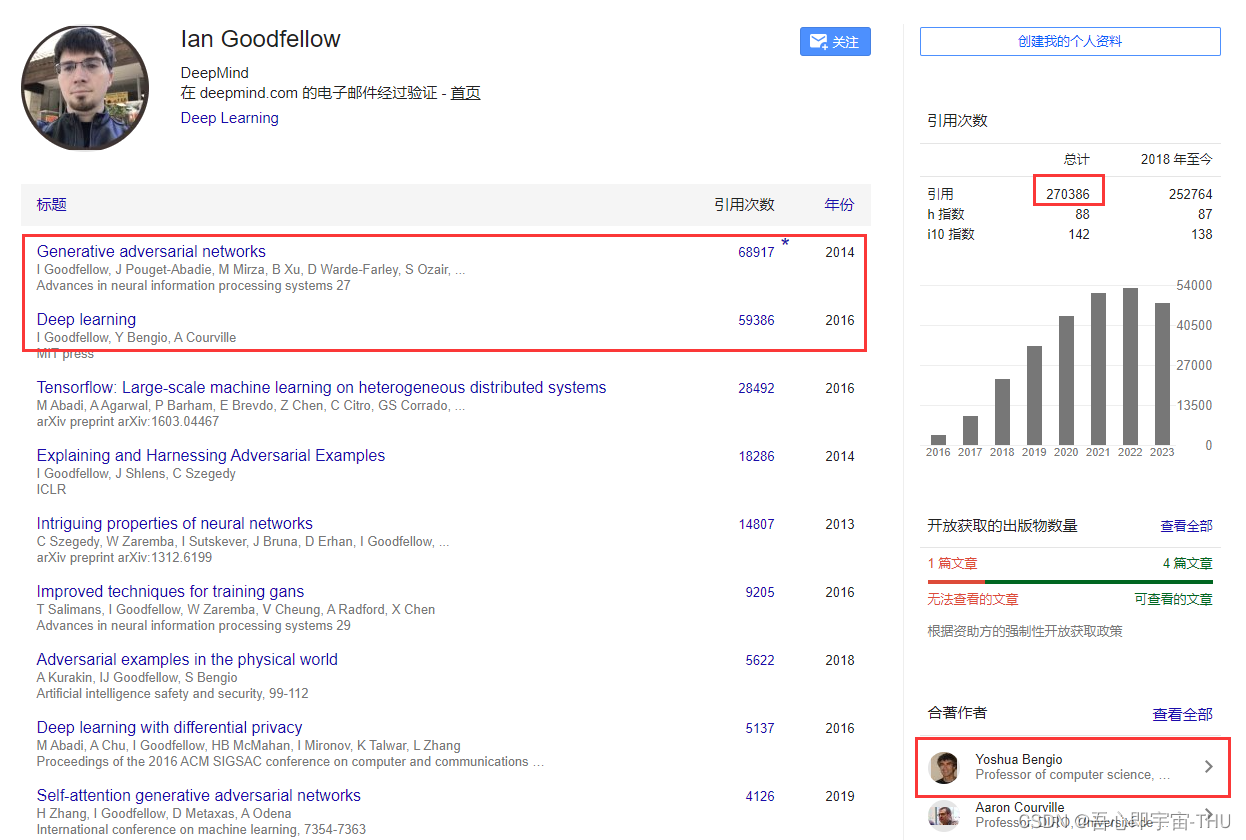
GAN的作者Ian J. Goodfellow是一名加州长大的美国人,被誉为"GAN之父"。目前谷歌学术的引用已经到了27w,目前是任职于谷歌的DeepMind,之前在苹果担任ML部门的总监,离职部分原因是需要在办公室上班,目前在goolge可以继续远程办公。其代表性的工作,GAN和Deep Learning《花书》已经达到6w的引用次数。其博导为深度学习三巨头之一的,图灵奖的获得者,加拿大蒙特利尔大学(Université de Montréal,AI领域的顶尖院校)的“Yoshua Bengio”。
机器学习领域最重要的教材西瓜书

深度学习领域最重要的教材花书

Ian 的本科和硕士就读于Standford大学,导师是闻名世界的Andrew Wu(吴恩达)。在本科时候就展现了过人的天赋,“我本科时就开始学习人工智能了。那个时候,机器学习主要还是 SVM、boosted trees 等等。业余时间,我也写写游戏程序,会用 GLslang 完成一些小项目。一次,我的朋友 Ethan Dreyfuss(现在在 Zoox 工作)向我提到了两件事:Geoff Hinton 发表了一个关于 DBN(深度信念网络)的技术演讲;还有 CUDA GPUs,这些东西在当时都是很新鲜的。我意识到,深度学习可以弥补 SVM 的很多缺陷。一方面,SVM 在模型设计上并没有很大的自由度,而且即便投入很多的数据,它也没法变得更只能。但深度神经网络可以。另一方面,CUDA GPU 将训练更大的神经网络变为可能,而且我已经从游戏编程中学会了编写GPU代码。在寒假期间,我和 Ethan 开始在斯坦福大学搭建第一台 CUDA 机器,用它训练玻尔兹曼机。”——来自采访中Ian自己的话,在读本科时,Ian经常去找吴恩达请教问题,随后硕士就跟着吴恩达读。随后硕士毕业后进入的Bengio的组内继续攻读博士。
在2014 年的一个晚上,Goodfellow 在酒吧给师兄庆祝博士毕业。一群工程师聚在一起不聊姑娘,而是开始了深入了学术探讨——如何让计算机自动生成照片。当时研究人员已经在使用神经网络(松散地模仿人脑神经元网络的算法),作为“生成”模型来创建可信的新数据。但结果往往不是很好:计算机生成的人脸图像要么模糊到看不清人脸,要么会出现没有耳朵之类的错误。针对这个问题,Goodfellow 的朋友们“煞费苦心”,提出了一个计划——对构成照片的元素进行统计分析,来帮助机器自己生成图像。Goodfellow 一听就觉得这个想法根本行不通,马上给否决掉了。但他已经无心再趴体了,刚才的那个问题一直盘旋在他的脑海,他边喝酒边思考,突然灵光一现:“为什么要学习似然函数,我干脆用一个MLP去拟合这个分布不就行了”,但朋友们对这个不靠谱的脑洞深表怀疑。Goodfellow 转头回家,决定用事实说话。写代码写到凌晨,然后测试…
Ian的个人主页 https://www.iangoodfellow.com/
引言

GAN这篇文章的名字为生成对抗网络。机器学习的任务分为两大类,第一类是分辨模型,主要任务是通过数据学习一套知识用于分辨数据类型或预测数据的值。第二类是生成模型,即如何根据已有的数据,生成和这些数据同分布的另一些新的数据。其中GAN的目的就是解决生成问题。GAN的名字并不是Ian提出的,和AlexNet一样,是后人为了便于称呼,便取名为GAN。
GAN的主要创新点是提出了一种新的基于对抗过程的生成框架,其中需要训练两个网络,一个是生成模型G用于抓取整个数据的分布,第二个是辨别模型D用于估计采样数据来自训练集的概率,而非生成器G。在统计学眼里,世界万物都是由数据分布组成的,数据类型可以是各种各样的,可以是视频,音频,图片,文本等。而这个训练过程是让G最大化一个概率去让D犯错,最后,让G可以骗过D生成以假乱真的数据。

在GAN的引言中说明,深度学习是一种数据分布的特征表示方法(Bengio强调的观点),绝不是一种神经网络的设计。而目前DL在辨别模型上表现的很好,源于大量的数据,反向传播算法和dropout算法。但在生成模型上做的不好。原因是最大化似然函数的时候,需要对概率分布做许多近似计算,而近似计算是十分困难的。似然函数是再统计数据分布之后,用一种函数来表示数据分布,再调整函数参数是的最大似然估计的效果最好,分布估计的最合理。但由于数据的复杂性,很多时候似然函数长什么样是难以估计的。这就导致之前的生成模型,都在做似然函数的近似拟合,而似然函数的拟合需要使用马尔科夫链进行复杂的采样,造成了计算上的困难,效率效果不好。所以GAN直接另辟蹊径,不去近似似然函数,而是去通过数据分布的拟合。这种方法不需要进行马尔科夫链,只需要通过两个MLP,通过反向传播算法,进行训练,最后生成接近真实数据的fake数据。

在相关工作中,之前的生成模型的方法都是去构造一个数据分布的最大似然函数,并设置一些可训练的参数来近似。这通常都需要多次的近似。所以非常麻烦。同时自编码器,VAEs是一类和GAN非常相似的工作,

VAEs详细介绍
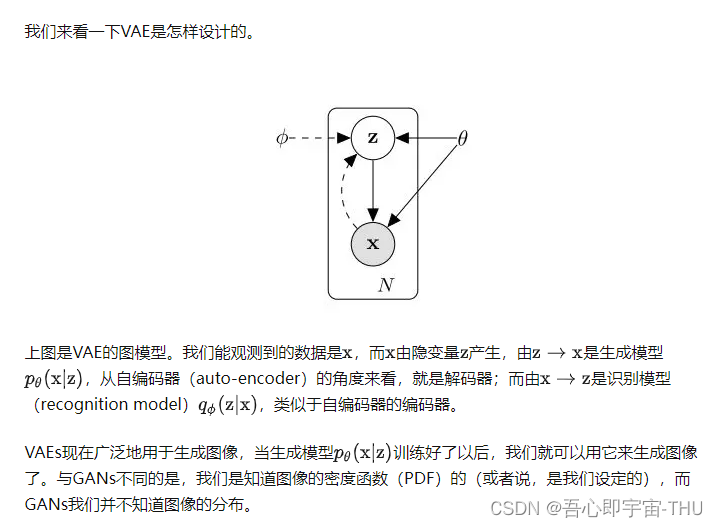

VAEs和GAN的区别
VAEs提前拟合似然函数,GAN不知道数据的分布。

GAN与NCE算法类似,但NCE算法局限于辨别器是由噪声分布和模型分布的概率密度函数的比值定义,因此需要同时通过BP训练并评估分子分母的密度,这种损失函数太复杂了,而GAN更简单。

GAN作者详细的论述了与PM算法的区别,总体来说是为了反驳当时这篇文章NIPS审稿人(Schmidhuber, Jurgen, LSTM的发明者,神经网络的奠基人之一)的comments, Jurgen认为GAN和他92年提出来的PM算法差不多,就是一种变种。所以两人在修稿的过程中进行了大量的battle,最后在NIPS大会的汇报上,Jurgen直接站起来指出Ian工作与PM是一样的,但被Ian无情反驳。

GAN的原理
首先通过样本
x
x
x学习生成器的数据分布
p
g
p_g
pg?,由于该分布未知,因此使用一个简单的已知的噪声分布
p
z
p_z
pz?去拟合
p
g
p_g
pg?。首先生成很多噪声z,随后通过MLP来讲z转换到x相同的分布。这时G(z)就是一些假的样本,那么需要将x和G(z)输入到判别器D中,让判别器分辨G(z)是来自于x还是否。最后损失函数变成了一种minmax的博弈过程,G的目的使得生成的G(z)和x的数据分布的相似最大化,但D的目的是将G(z)和x区别开来,是最小化过程。那么这属于博弈论里的概念,当两者对抗时,需要找到一个纳什均衡,使得G和D动态平衡,G不再增大,D不再减小。那么GAN就收敛了,但实际训练中是非常困难的。G训练太少,则生成的效果不好,D训练太少,则辨别效果弱智太容易被欺骗,D训练太多,则分辨效果太好,导致G难以骗过D。这使得GAN网络训练非常容易崩溃。这也是后续GAN改进的一个重点。


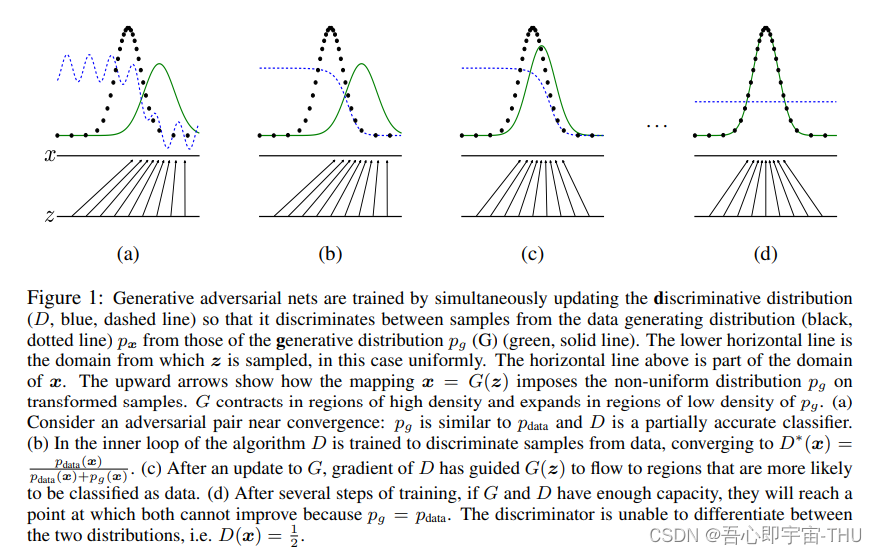
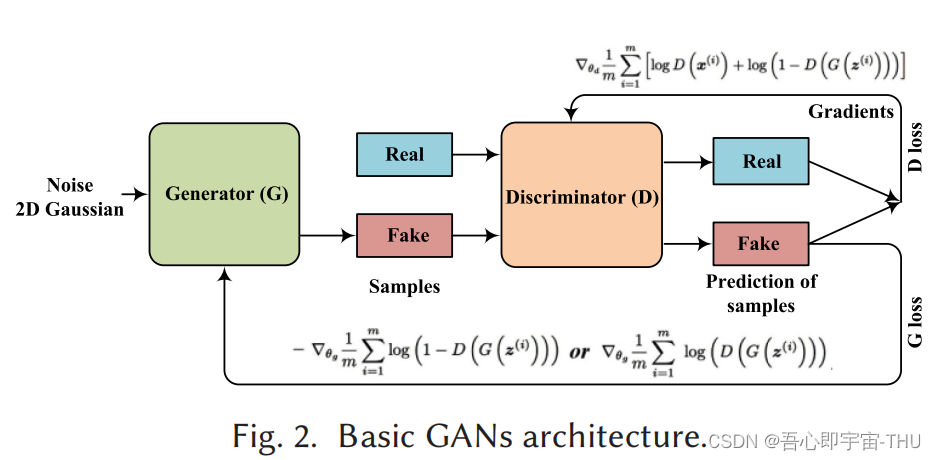
论文中将GAN的过程通过图1表示,z表示噪声分辨,x表示真实数据分布,点表示真实分布,绿色表示G(x)分布,蓝色表示判别器的效果。在训练过程中,刚开始生成的效果很差,判别器也不太好分辨,判别器先训练后,能够有效辨别x和G(z)的差别。但随着G的训练,D最后无法分辨出x和G(z)的差别,最终让G(z)和x的数据分布相似。即达到生成的目的。
后面算法性能的详细推理分析请参考该视频,GAN论文逐段精读-李沐
GAN的源代码请 参考Ian提供的GAN源码
GAN的改进
GAN相关的综述
[1]J. Gui, Z. Sun, Y. Wen, D. Tao and J. Ye, “A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications,” in IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 4, pp. 3313-3332, 1 April 2023, doi: 10.1109/TKDE.2021.3130191.论文地址
[2] Divya Saxena and Jiannong Cao. 2021. Generative Adversarial Networks (GANs): Challenges, Solutions, and Future Directions. ACM Comput. Surv. 54, 3, Article 63 (April 2022), 42 pages. https://doi.org/10.1145/3446374 论文地址
[3] K. Wang, C. Gou, Y. Duan, Y. Lin, X. Zheng and F. -Y. Wang, “Generative adversarial networks: introduction and outlook,” in IEEE/CAA Journal of Automatica Sinica, vol. 4, no. 4, pp. 588-598, 2017, doi: 10.1109/JAS.2017.7510583. 论文地址
[4] A. Creswell, T. White, V. Dumoulin, K. Arulkumaran, B. Sengupta and A. A. Bharath, “Generative Adversarial Networks: An Overview,” in IEEE Signal Processing Magazine, vol. 35, no. 1, pp. 53-65, Jan. 2018, doi: 10.1109/MSP.2017.2765202. 论文地址
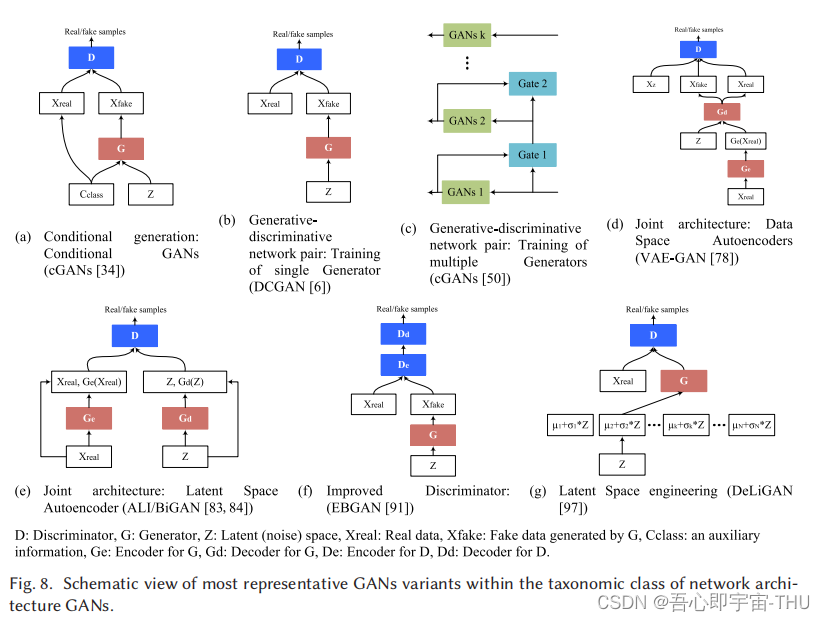
GAN的分类来自于文献[2]

GAN的网络结构的改进来自于文献[2]
GAN的优点与不足
优点
(以下部分摘自ian goodfellow 在Quora的问答)
● GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
● 相比其他所有模型, GAN可以产生更加清晰,真实的样本
● GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
● 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊
● 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
● GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了
不足
● 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但普遍在实践中它还是比训练玻尔兹曼机稳定的多
● GAN不适合处理离散形式的数据,比如文本
● GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
DCGAN (GAN网络结构改进)
概述
DCGAN全称Deep Convolutional Generative Adversarial Networks,即深度卷积生成对抗网络。有了上一章对GAN的原理的理解,大家都知道GAN的核心思想就是博弈,两者相互竞争,相互加强。GAN模型包括生成网络G和鉴别网络D,生成网络的目的是生成假的图像使判别网络无法鉴别真假,而判别网络的目的是努力分辨真假图像。最终直到鉴别网络分辨不出生成网络生成的以假乱真的图像为止。
DCGAN是继GAN之后比较好的改进,其主要的改进主要是在网络结构上,极大的提升了GAN的稳定性。到目前为止,DCGAN的网络结构还是被广泛的使用。
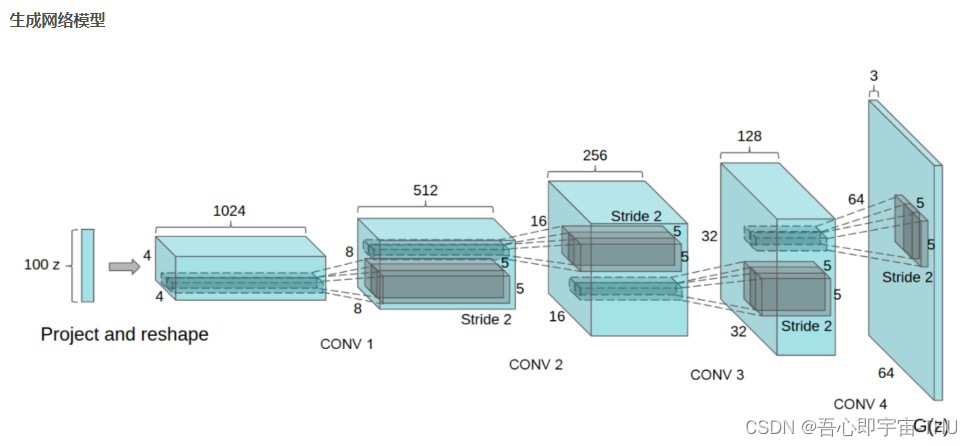
生成网络(Generator)接收一个随机噪声z,然后通过上采样(up-sampling)生成图像G(z)。上采样主要采用反卷积算法,G接收一个100-d随机噪声z,经过Project and reshape(实际上就是一个全连接层),转化为一个4 4 1024的feature map,然后经过多个反卷积层,生成大小为64 64 3的图像。(注意:官方给的生成网络只是为了帮助理解原理,并不是说DCGAN的生成网络就是一个反卷积网络,生成网络根据个人不同需求可以替换)
整个网络没有pooling层和上采样层的存在,实际上是使用了带步长(fractional-strided)的卷积代替了上采样,以增加训练的稳定性
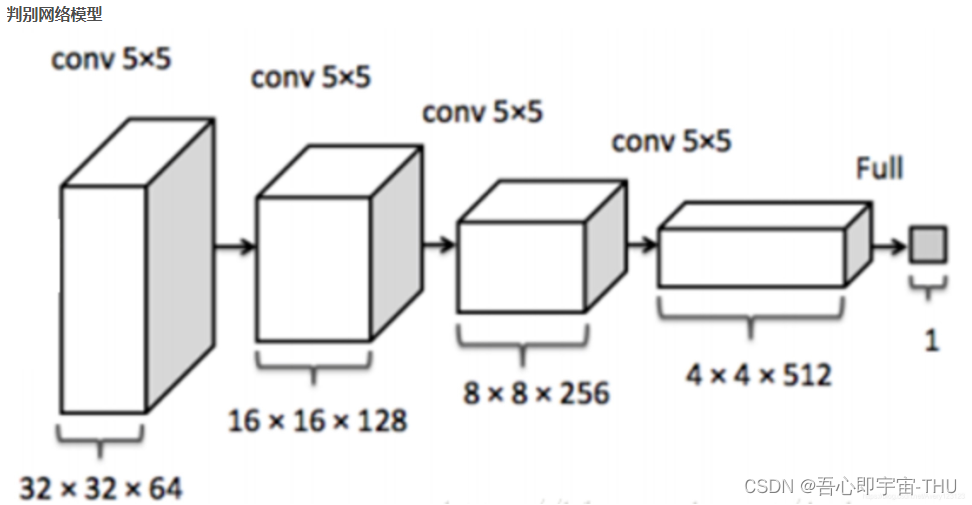
鉴别网络(Discriminator)的输入为一张图片,经过下采样(down-sampling,卷积运算),再接全连接层处理,送入sigmoid函数,输出真假概率。
注意
1)G,D网络不采取任何池化处理;
2)G,D网络每一层均使用批标准化处理(Batch-Normalization);
3)在G网络中,激活函数除了最后一层外,都是用Relu函数,最后一层使用tanh函数;
4)D网络中,激活函数均使用Leaky Relu函数。

优点和不足
优点
DCGAN能改进GAN训练稳定的原因主要有:
◆ 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层。
◆ 生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)
◆ 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh。
◆ 使用adam优化器训练,并且学习率最好是0.0002
不足
DCGAN虽然有很好的架构,但是对GAN训练稳定性来说是治标不治本,没有从根本上解决问题,而且训练的时候仍需要小心的平衡G,D的训练进程,往往是训练一个多次,训练另一个一次。
WGAN (GAN损失函数改进)
自从GAN问世就存在着训练困难、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。从那时起,很多论文都在尝试解决,但是效果不尽人意,比如最有名的一个改进DCGAN(见上章)依靠的是对判别器和生成器的架构进行实验枚举,最终找到一组比较好的网络架构设置,但是实际上是治标不治本,没有彻底解决问题。而今天的主角Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
1)彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
2)基本解决了模式崩溃的collapse mode的问题,确保了生成样本的多样性
3)训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高
4)以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
改进后相比原始GAN的算法实现流程却只改了四点:
1)判别器最后一层去掉sigmoid
2)生成器和判别器的loss不取log
3)每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
4)不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行

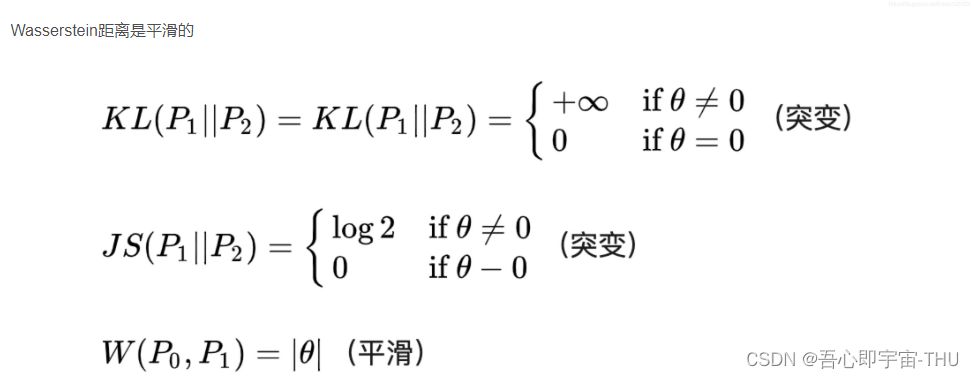
KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化参数时,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
优点和不足
与DCGAN不同,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,WGAN对GAN的改进主要有:
◆ 判别器最后一层去掉sigmoid
◆ 生成器和判别器的loss不取log
◆ 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的lipschitz连续性条件。
◆ 论文中也推荐使用SGD, RMSprop等优化器,不要基于使用动量的优化算法,比如adam,但是就我目前来说,训练GAN时,我还是adam用的多一些。
从上面看来,WGAN好像在代码上很好实现,基本上在原始GAN的代码上不用更改什么,但是它的作用是巨大的
◆ WGAN理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,转而使用wassertein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题。
◆ 解决了模式崩溃的(collapse mode)问题,生成结果多样性更丰富。
◆ 对GAN的训练提供了一个指标,此指标数值越小,表示GAN训练的越差,反之越好。
LSGAN (GAN损失函数改进)
最小二乘GAN
全称是Least Squares Generative Adversarial Networks



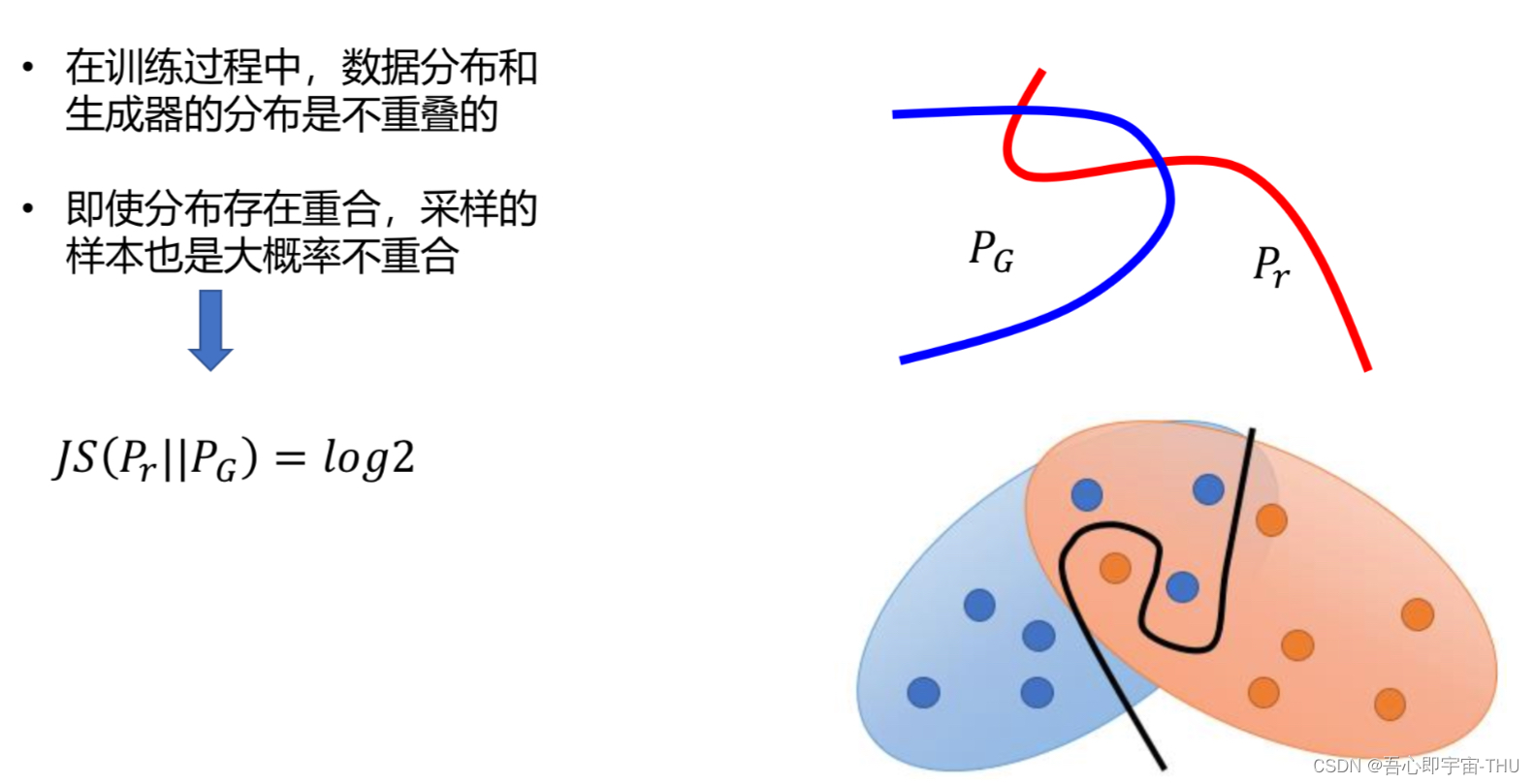
在采样样本与真实样本的分布不重合的情况下,JS散度等于一个常数,而常数的梯度是0,即出现了“梯度消失”现象,从而没法使用梯度下降法优化网络。
原理
其实原理部分可以一句话概括,即使用了最小二乘损失函数代替了GAN的损失函数。
但是就这样的改变,缓解了GAN训练不稳定和生成图像质量差多样性不足的问题。a,b,c为不同分布中的理想点,如果采样点在分布的边界,使得fake与real数据距离太远,那么最小二乘损失,就可以度量较差采样和理想采样的距离,通过最小化这个距离,把差的采样拉回好的范围,这样使得计算JS散度时就能动态的调整采样区域,使得算法趋于稳定,不会出现梯度消失的情况。
事实上,作者认为使用JS散度并不能拉近真实分布和生成分布之间的距离,使用最小二乘可以将图像的分布尽可能的接近决策边界,其损失函数定义如下:
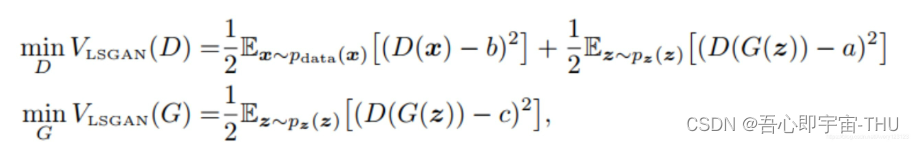
具体参考这篇博客
BEGAN (GAN损失函数改进)
概述
BEGAN全称是Boundary Equilibrium GANs
BEGAN是Google在17年上半年出的一篇论文,此论文对GAN做了进一步的改进,提出了一种新的评价生成器生成质量的方式,使GAN即使使用很简单的网络,不加一些训练trick比如BN,minibatch,使用SELU激活函数等等,也能实现很好的训练效果,完全不用担心模式崩溃(model collapse)和训练不平衡的问题。
以往的GAN以及其变种都是希望生成器生成的数据分布尽可能的接近真实数据的分布,当生成数据分布等同于真实数据分布时,我们就确定生成器G经过训练可以生成和真实数据分布相同的样本,即获得了生成足以以假乱真数据的能力,所以从这一点出发,研究者们设计了各种损失函数去令G的生成数据分布尽可能接近真实数据分布。
直观来讲,如果两个分布越相近, 我们可以认为他们越相似,当生成数据分布非常接近于真实数据分布的时候,这时候生成器就有足够的生成能力。其中比较好的改进成果主要有DCGAN、WGAN、WGAN-GP等等。 BEGAN代替了这种估计概率分布方法,它不直接去估计生成分布Pg与真实分布Px的差距,而是估计分布的误差的分布之间的差距,作者认为只要分布之间的误差分布相近的话,也可以认为这些分布是相近的
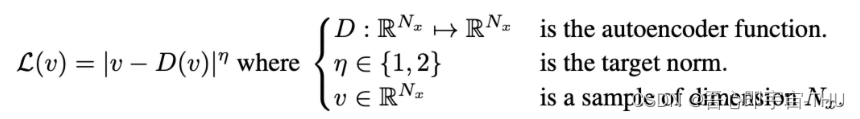
为了估计分布的误差,作者使用了auto-encoder作为D,D的输入是图像V,维度为RNx,输出的也是维度为RNx的图片。此处的L(v)是一个pixel-wise的损失,表示真实输入图像v和经过自编码网络D输出的D(v)的相似程度,L越小,说明v, D(v)越相似。
同样的,我们可以得到 L’(v)=|v-G(v)|n 这样一个pixl-wise误差。
此时重点来了,由于两者都是pixel-wise的, 那么L里的数值一定满足某种分布,在有足够大的像素的情况下,假设像素是满足IID即独立同分布条件,根据中心极限定理,像素的误差近似满足正太分布,那就是说L(v)和L’(v)分别是μ1 = N(m1; C1)和 μ2 = N(m2; C2)的正太分布,m为均值,维度为Rp,c为方差维度为Rp×p 。
那么根据wassertein公式,两个正太分布μ1、μ2的距离为:

对比WGAN就可以发现,这里不需要lipschize限制,这时,我们就可以给GAN分配任务了,令D不断的最大化m2,最小化m1,而G则不断最小化m2,当m2 接近m1的时候我们就认为GAN完成了训练。
分析到这里我们得出结论,我们可以去估计误差的分布而不是直接估计分布去拟合GAN,但是损失函数究竟是怎么样的呢?
损失函数网络结构
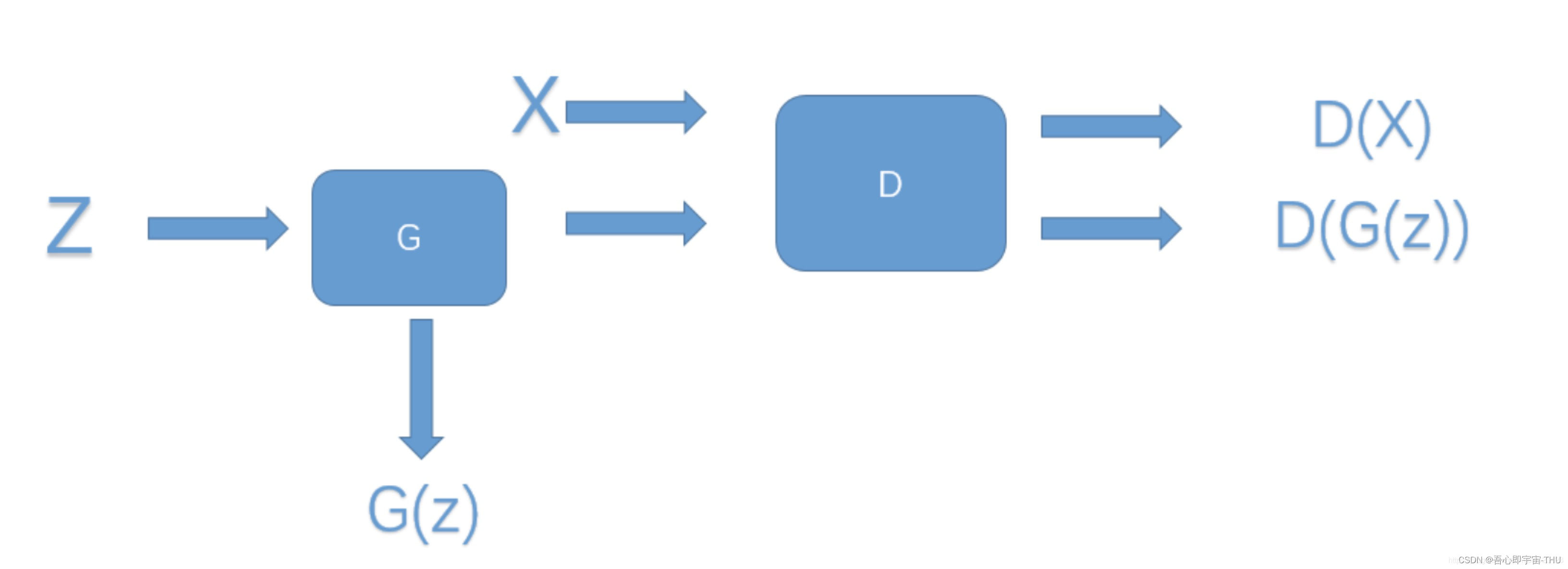
论文中给出的损失函数如下形式,关于另一个参数Kt上述图片没有表述出来:
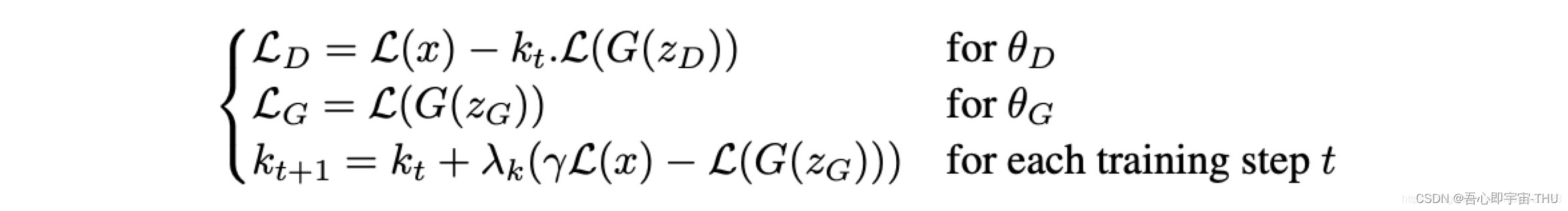
D,G的损失在图片中已经给出了描述,从以上分析的结果来看,只要按步骤优化损失函数,就能完成GAN的训练,但是还没有那么简单,或许也注意到,为什么论文的名字叫做Boundary Equilibrium GAN,到这里完全没有涉及到Boundary Equilibrium的概念,我们继续分析
Equilibrium
试分析以下,GAN完成训练时的结果是什么样子的,理想情况下肯定是m1=m2的时候是最好的,即:
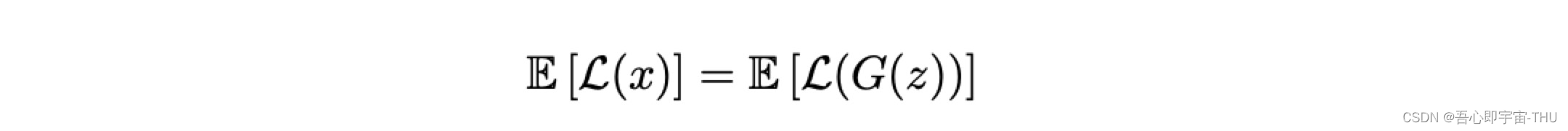
分布的期望相等,那就是G产生的图片和真实图像分布相同,这时出现了一个问题,m1=m2条件下,条件1不再是一个不可忽略项,反而趋近于无穷,作者为了解决这个问题,特意加入了一个超参数,γ 取值 [0;1]之间定义:
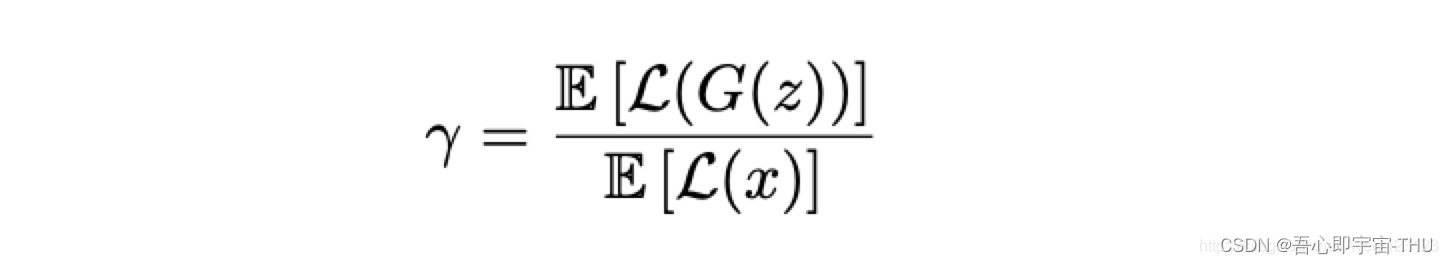
有了这个限制,就不会出现m1=m2的情形了,这就相当于一个boundary 将均衡条件限制住了,这就是论文名字的由来。
另外一个重要的参数就是Mgloable了,形式如下:
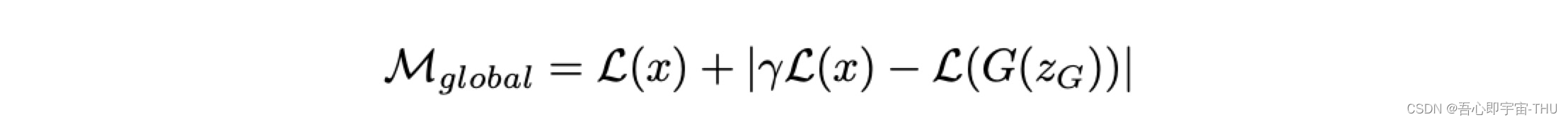
这个参数表示训练程度的多少,越小的话,训练程度越好,从公式中可见一斑。

优点和不足
BEGAN中,作者做出了以下四个贡献:
1.提出了一种新的简单强大GAN网络结构,使用标准的训练方式不加训练trick也能很快且稳定的收敛(有一种将自己乱走火的王八盖子换了一个准点打击的狙的感觉)
2.对于GAN中G,D的能力的平衡提出了一种均衡的概念(GAN的理论基础就是goodfellow理论上证明了GAN均衡点的存在,但是一直没有一个准确的衡量指标说明GAN的均衡程度)
3.提供了一个超参数,这个超参数可以在图像的多样性和生成质量之间做均衡(熟悉GAN的小伙伴就知道这又多难得)
4.提出了一种收敛程度的估计,这个机制只在WGAN中出现过。作者在论文中也提到,他们的灵感来自于WGAN
StyleGAN (图像生成)
之前的GAN网络都存在着一个问题:控制图像生成特定特征的能力有限。比方说,对随机噪声的某一维进行限制,与其相关的其它特征也跟着变化,导致输出大变样,效果与我们预期相符的概率很小 。

为了解决上述问题,styleGAN提出了不同的网络结构,也就是基于“样式”的生成器。输入随机噪声后经过“映射网络”得到潜在因子,再送入GAN。
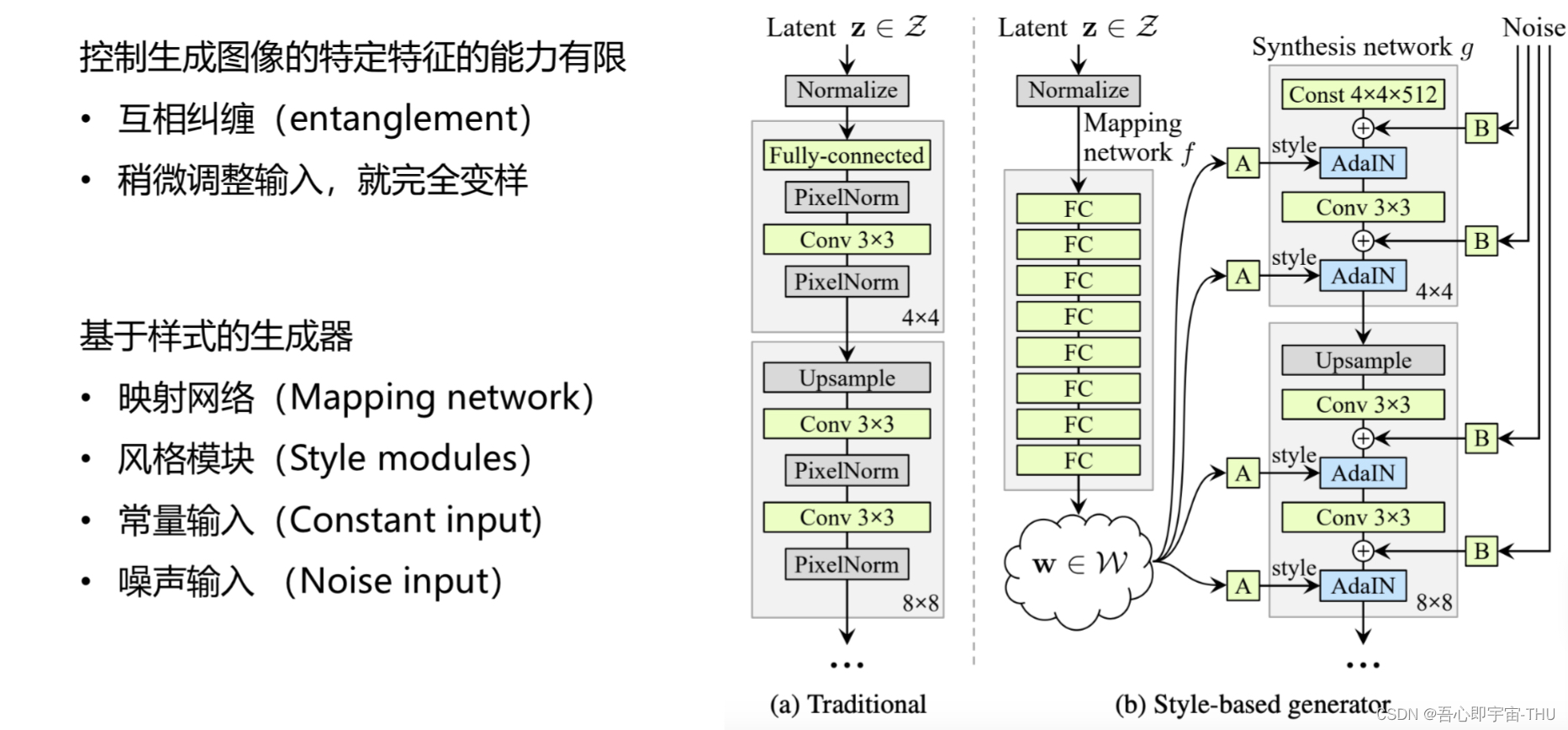
映射网络
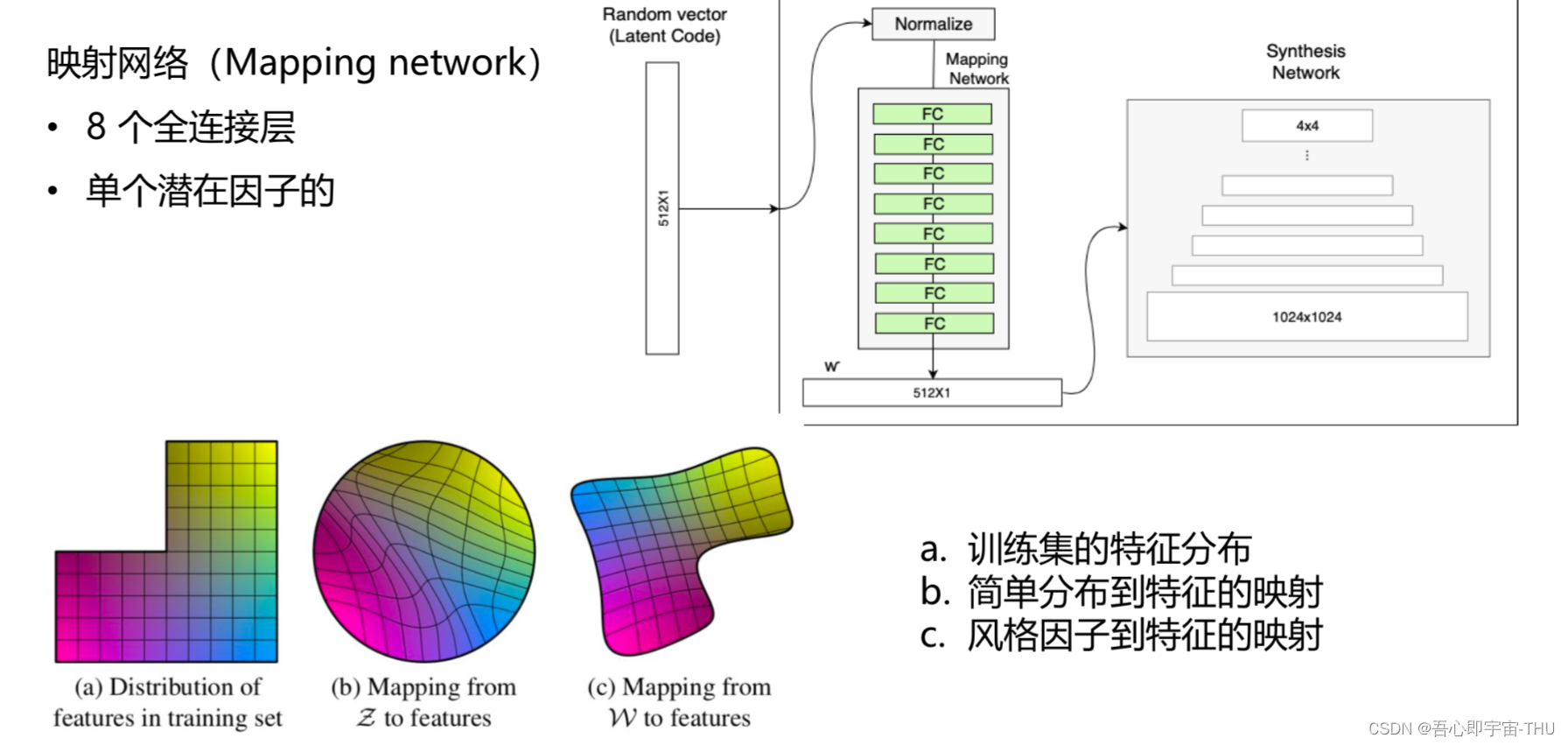
这是映射网络的结构。随机噪声输入后经过标准化、连续全连接层(每层后接一个LeakyReLU)后,得到新的、与输入相同维度的潜在因子。
这么做的目的是这样解释的:现在图a代表训练集的特征分布, 颜色代表输出,实线代表某个特征。比如说,纵轴代表头发长度,横轴代表男子气概;那么右上角的数据分布代表长发女生,而左下角的数据则是短发男生,左上角不存在的就是长发男生(对于数据集)。
采集到的数据服从简单分布,而简单分布是对称分布,就像图b那样。为了弥补数据在某区域的缺失,我们对数据分布进行了扭曲。这么做的后果就是:对某一特征的改动会影响到其它特征,这就是“特征纠缠”。而映射网络则缓解了这种情况。
风格模块
在解释风格模块之前,先插入一点归一化的知识。
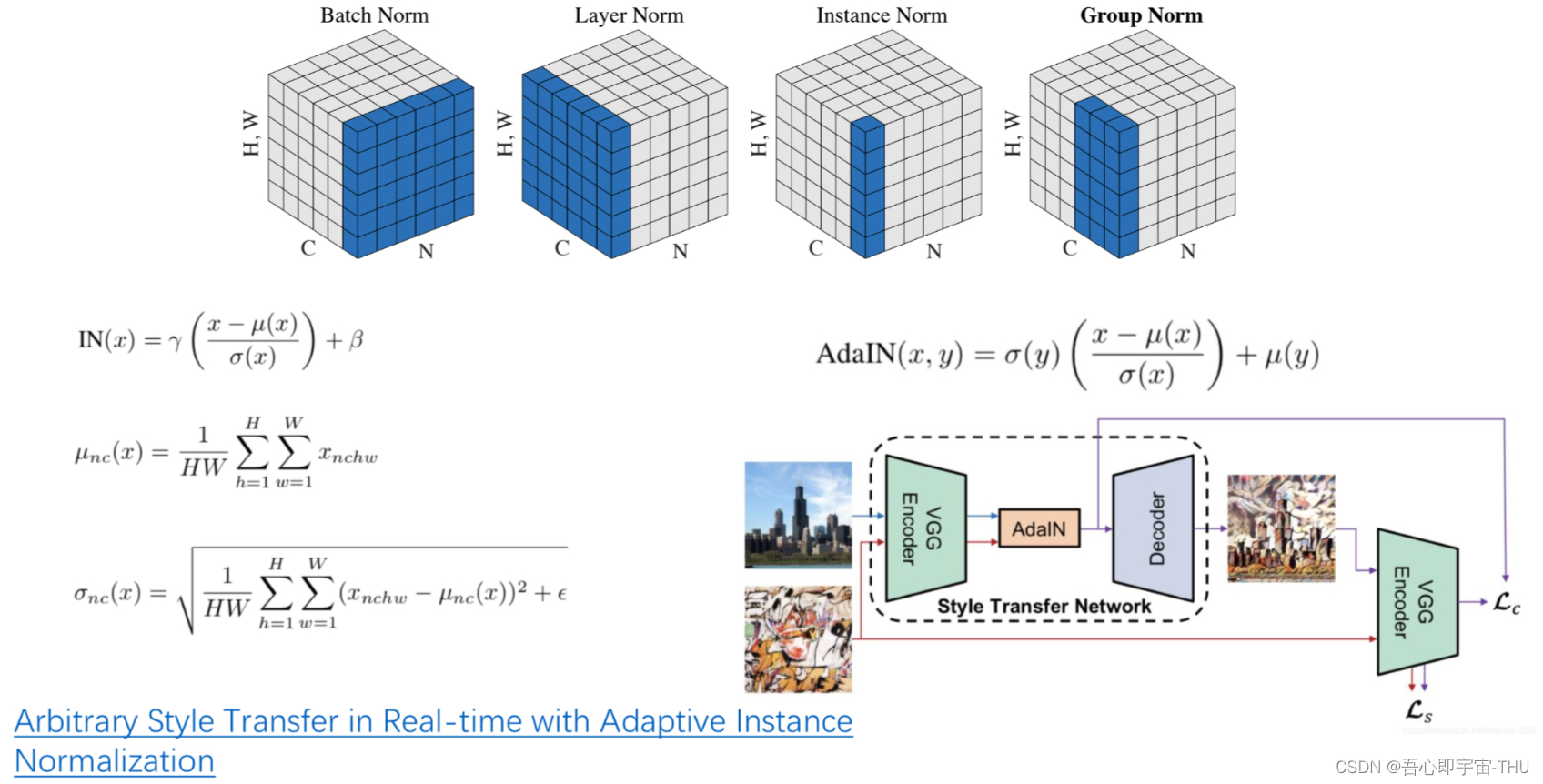
以上展示了几种归一化操作。,在此主要解析实例归一化(Instance Norm)和它的变种——自适应归一化(AdaIN)。实例归一化的均值和标准差来自于batch中的某个样本,而自适应归一化则是将算式中的缩放系数和偏置替换成了目标图片的均值和方差。这种做法是在风格迁移任务中发现的,并且取得了不错的效果。
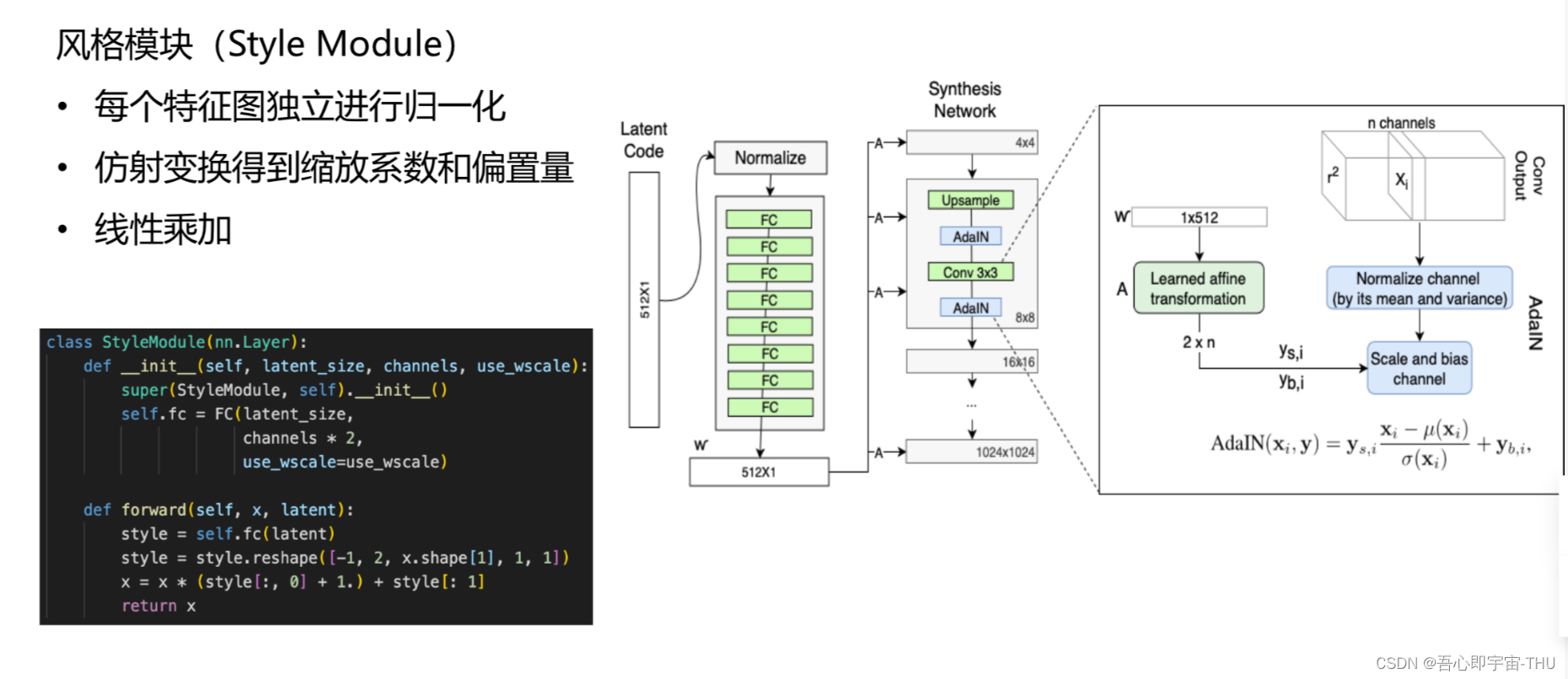
StyleGAN借鉴了上述操作的思路,也就是其中的风格模块。处理的流程为:随机噪声经过一可学习(也就是参数可“进化”的网络层,结构等同于全连接层)的仿射变换层,之后维度变为原来的两倍:前一半作为缩放系数,后一半是偏置,再进行归一化。
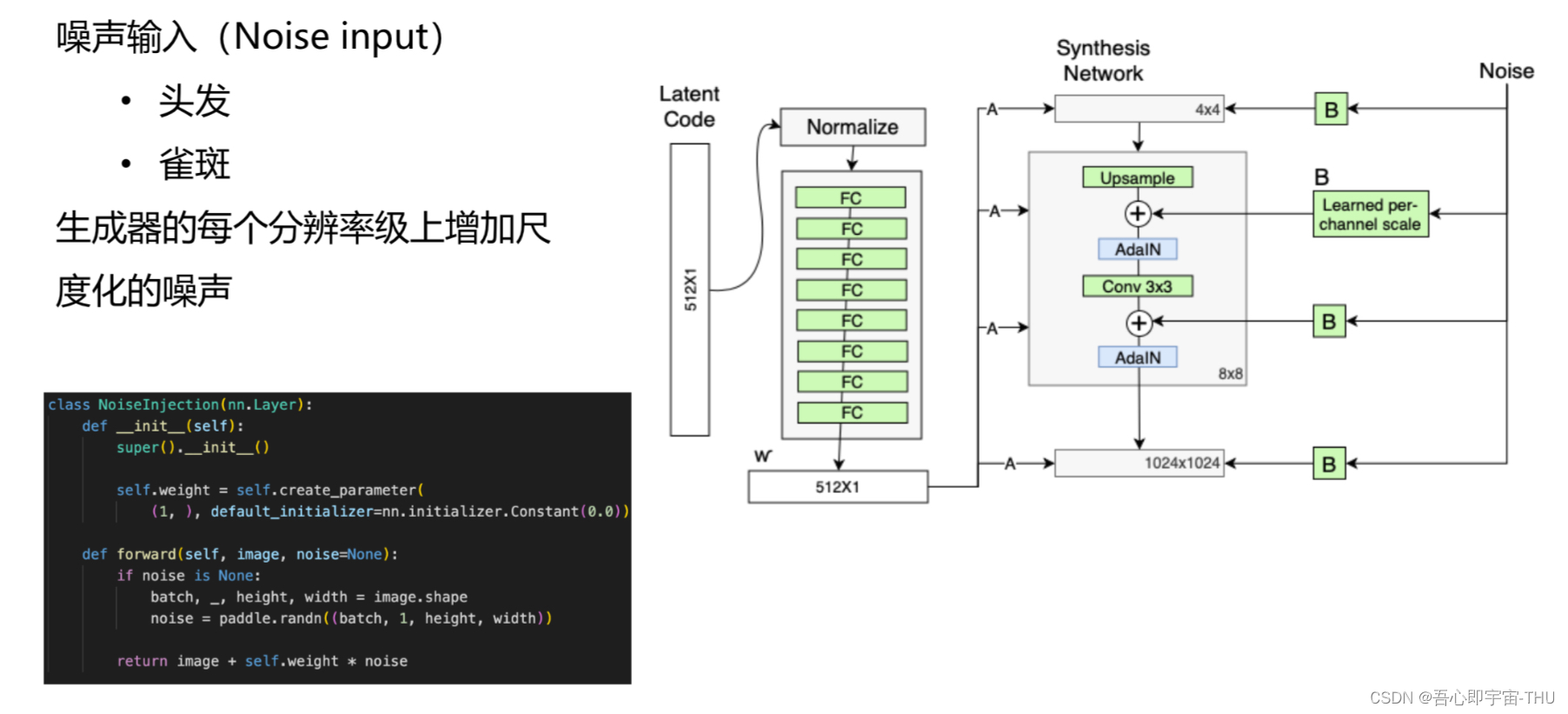
常数输入
用新的潜在因子代替随机噪声输入进网络,减小网络对输入向量的依赖,一定程度抑制特征纠缠。所以,网络的输入部分就是个常数,格式为:Batch??Size??Size??Channel。

噪声输入
图片除了包含一些大体上的基本特征之外,还会有一些随机性特征。例如,对于人脸生成,大体的轮廓是比较容易学习的,但是诸如发型、脸上的雀斑、或者是戴的眼镜这样的特征在时间序列上的变化就不具有规律。解决方法就是增加噪声输入, 利用这个噪声去增加模型输出的多样性。在此网络中,噪声来自于高斯分布,经过缩放因子后参与运算。
混合正则化

混合正则化(Mixing Regularization)是风格混合任务中比较重要的操作之一。我们希望对不同的Block输入不同的潜在因子,有一种方法是“直接”将不同的潜在因子送入网络(“每个”潜在因子都不一样),而实际采用的方法是输入一组随机因子,“分段”地送入Block。一个例子:取出两个潜在因子,经过映射网络中得到两个输出w1、w2.此时对网络段进行随机划分,前一段输入的是w1,剩下的Block输入w2。
seqGAN (文本生成)
摘要
本文主要贡献是提出了seq_Gan的框架。
使用了GAN主要解决的问题是:
暴露偏差问题。
但同时Gan也带来了两个问题。
1.只考虑最后一步,没有考虑中间步骤,能评价句子的整个生成过程,不能评价每一步。
2.文字是离散型的数据导致Gan的反向传播常常失效;
相关工作介绍
文本生成的故事从很久很久以前开始。 但我们只追溯到2014年。
<Kingma and Welling 2014>说:
我们可以尝试用(变分编码器+深度学习+统计推断)试图将数据学习到一个潜在隐藏空间中,然后从这个空间中得到文本。
但其本质是还是一个求最大似然的过程。
<Goodfollow 2014> 说:
“不行,求似然太困难了,现在还没有适合我们的解法。我们发现GANs可以通过GAN生成器和判别器不断迭代的过程,悄咪咪的绕过maximum likelihood learning问题,我们干脆用GAN来做文本生成吧。”
然而效果不见得有多好。
“怎么效果就是不行呢!怎么就是不行呢!”吃饭想,睡觉想,天天琢磨。
于是,2016年,他明白问题出在哪里了。
<Goodfellow 2016> 大声咆哮:
“Gan在NLP中效果不好,原因还是连续数据到离散数据的传导问题。
你的反向传导是可以传导回去。但你一点点传导根本没什么用。字典空间里的编号是【0,1,2,3】,你新生成的句子是【1.1, 2, 3】有什么意义?在字典空间里,根本没什么卵用。”
虽然goodfollow已经想绕过最大似然方法了。但效果不成啊,还是有人在刚最大似然函数。
随着时代的发展,当时的文本翻译的RNN模型发展起来了,人们用RNN来做文本生成。
可是这个模型根子上还是一个最大似然函数。
(最大似然函数是估计一个模型的参数,使得参数最大的符合数据集)
(梯度下降只是最大似然函数的一种解法。)
<Bengio 2015>说:
不管你们怎么变形,都逃不开最大似然方法。可这种方法天生有问题,它有一个问题叫
暴露偏见。随着序列不断迭代训练,会训练出许多从来没有被观察过的例子。总之,这种处理办法是次优的,就让我Bengio来解决这个问题吧。
于是他提出了一种SS算法,用自己合成的前缀代替了训练集。
Bengio刚一说完,Huszar就跳出来了。
Huszar(2015)说:SS简直扯淡,数学证明,Gan是有潜力生成自然样例的,但在当前是不可能的。还有待发簪。
<Bachman 2015>瑟瑟发抖的说道: 这个问题可以当做序列决策问题,然后增强学习或许可以解这个问题。
《Sil- ver 2016》就动手了,那我就试试看。
然后作者<Lantao Yu 2016>就跳出来了:silver 你这样子不行啊,你这样子只看最后一步 ,不科学啊。我们就老牛逼了。
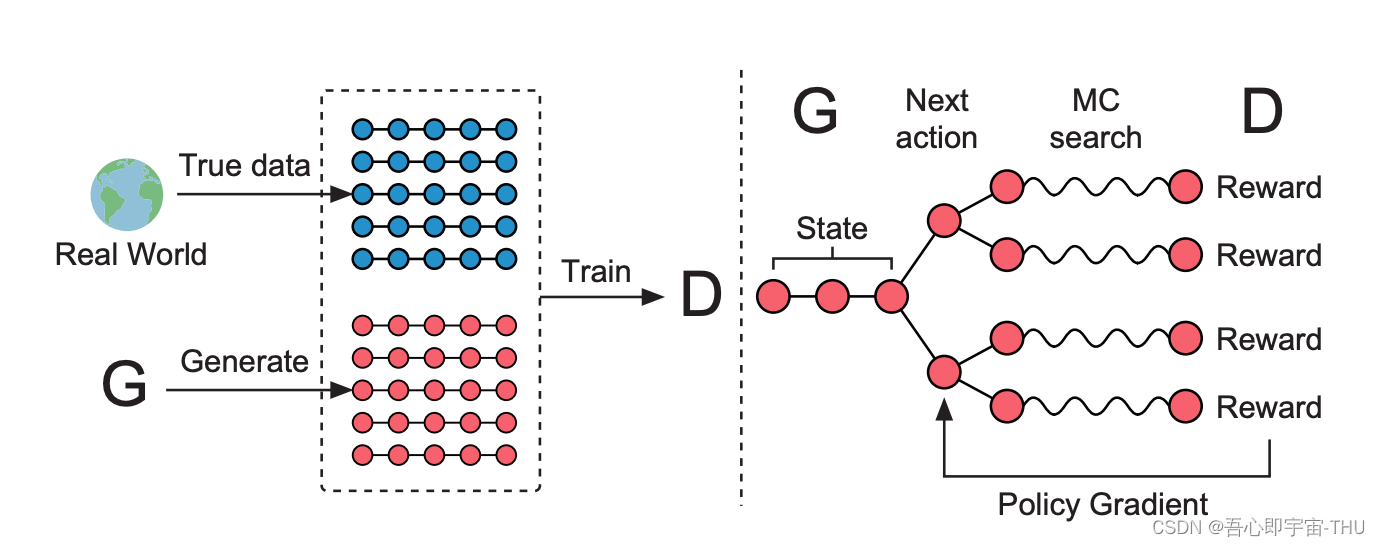
我们提出了seqGan,Gan本身解决暴露偏差问题,用强化学习的蒙特卡洛方法解Gan,每生成一个字,我们都会对它的效果进行考量。这种强化学习方法顺便还能解决离散数据反向传播失败的问题。
算法框架

以下理解用a替换
θ
\theta
θ,用b替换
β
\beta
β
1.随机给G(a)和D(a)进行调参
2.训练G(a)用最大似然估计进行预训练
3.这个时候G(b)和G(a)的参数一样
4 G(a)生成负例给D,D的损失函数是交叉熵
5.然后开始Gan的过程,不断迭代:
进行G的过程
1.用G(a)生成一个序列(一个或者N个)
2.然后对每一个时间步:
计算奖励Q(这里的Q是用G(b)来计算的)
3.通过梯度更新生成器的参数
进行Dis的过程:
1.生成器的序列生成一系列句子,生成句子和真实句子联合起来
2.训练判别器B
把G(b)和G(a)同步;
seqGAN

判别器
在本文中,我们选择CNN作为我们的鉴别器,因为最近CNN在文本(令牌序列)分类中显示出了很好的效果,大多数判别模型只能对整个序列进行分类,而不能对未完成的序列进行分类。在本文中,我们还重点研究了鉴别器预测完成序列为真的概率的情况。

生成器
作者使用RNN来嵌入轨迹表示,

其中,g为LSTM模型。最后,使用softmax函数来生成目标token的分布。首先当前的状态S通过MC采样,递归地向下搜索N步,每一步的尝试都返回一个reward,选择当前采样后回报最大的策略,再返回上层,当前S选择什么文本确定后,再充分步骤确定下面的序列是什么文字token。最后训练生成器时,使得这些MC采样的策略中选择回报最大的策略,即判别器分不出来的策略集。
GAN在优化领域的应用
由于我是做进化计算的,所以重点关注如何将GAN应用与优化领域。 目前GAN能够通过学习分布并生成数据的特点在进化计算领域得到了一些关注,但由于GAN的特点,GAN无法处理离散的问题,因此如果直接将GAN用于进化算法,则只能求解连续优化问题。下面讲两篇典型的论文。提供应用的思路。
进化算法驱动的GAN (图像生成问题)
Evolutionary Generative Adversarial Networks,2019 TEVC,

把GAN中生成器当中一个进化问题,利用G生成大量的噪声,使用一些变量的扰动,生成一些自带,然后使用D来计算分类分数即适应值函数,最后通过选择机制,选择一些无法被分出来的噪声,来更新G,使得G向着这些优质噪声的方向靠近优化参数。
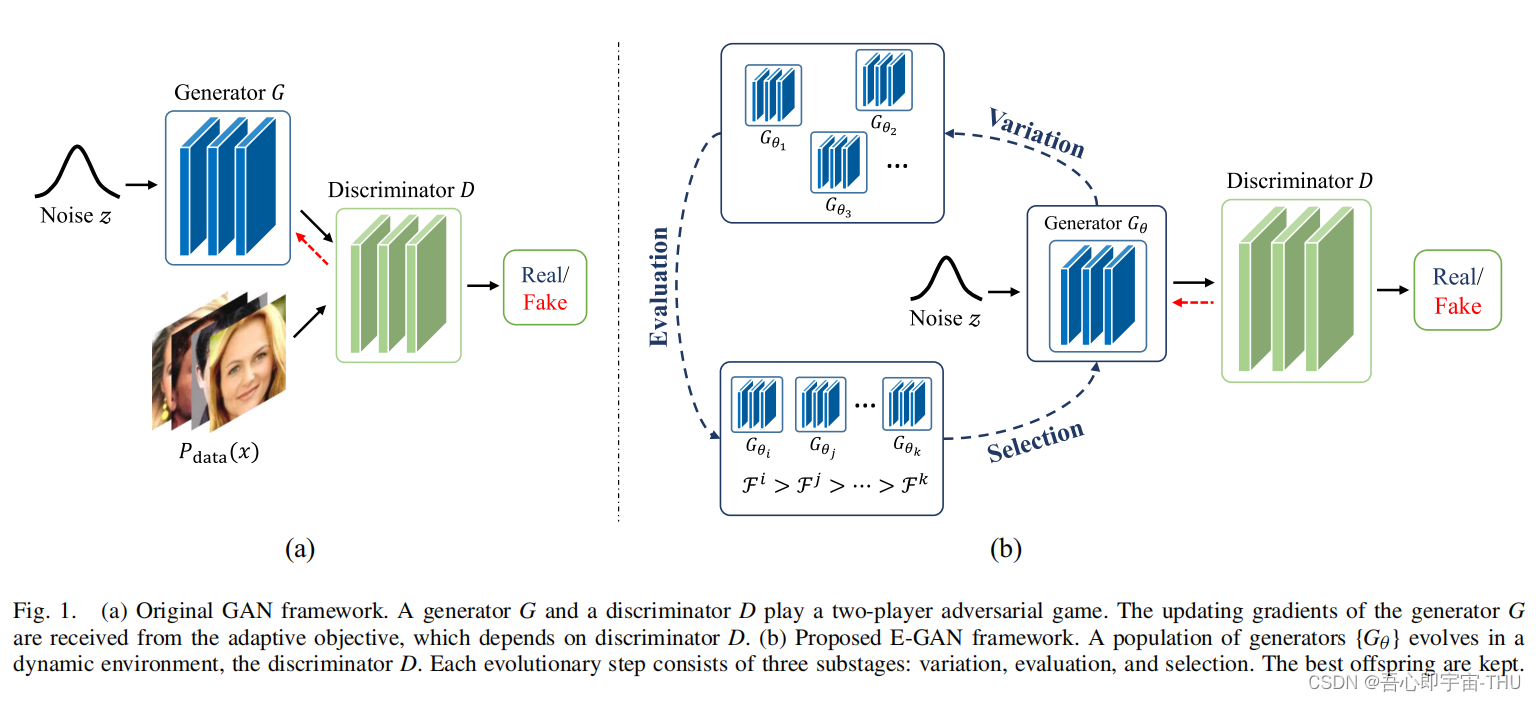
GAN 应用与多目标优化
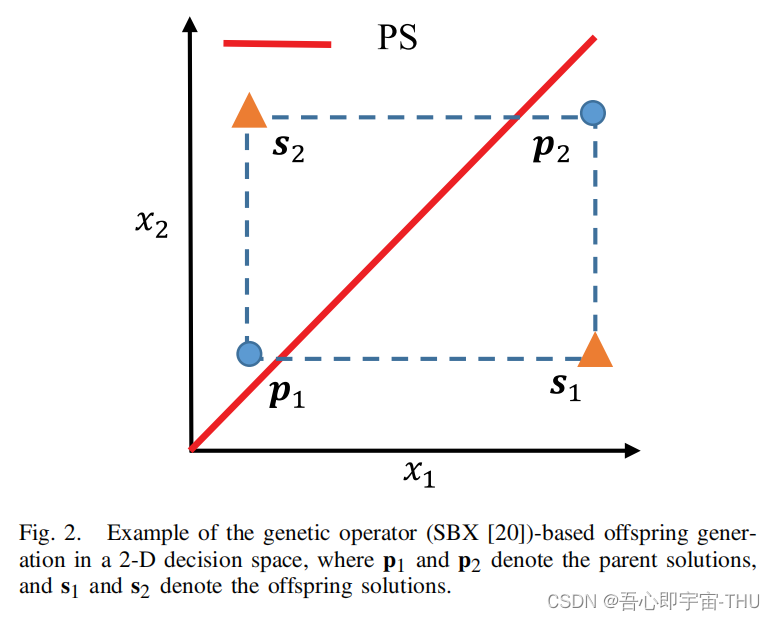
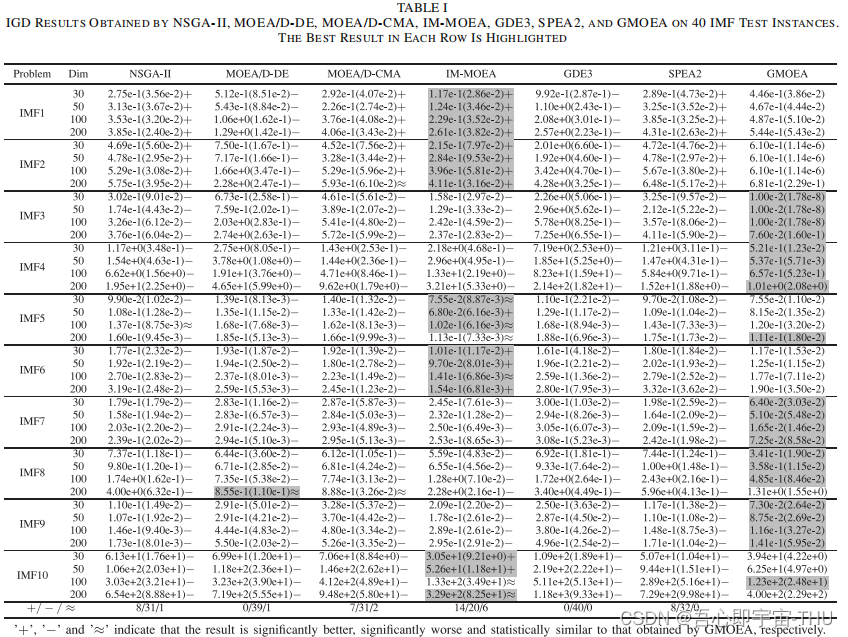
论文题目:Evolutionary Multiobjective Optimization Driven by Generative Adversarial Networks (GANs),2021 TCYB

动机:传统的进化算法生成解靠 不同解之间交换信息,这种交叉变异仅在已知的解的分布内进行,这样难以搜索到一些边界的解。如图所示,如果父代和自带都在一个矩形的四个点上,那么无论怎么交叉,都无法将解生成到最优解集PS上
因此作者采用GAN来替换GA算子生成解,首先对一个多目标优化问题,将种群中的PF前沿,作为精英解,即realdata,而剩余种群的解表示被支配的较差的解,那么作者希望用噪声,通过GAN来生成精英解附件的解,这样达到替换GA的目的。则将三种数据输入判别器,即G(z),real data,和较差的解。那么辨别器需要区分出,什么解是好的,什么解是坏的,什么解是假的,D的损失函数如下:
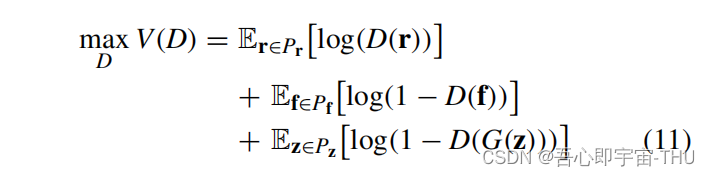
而G的目的是生成解决PF的解,那么最终D失效,G能成功生成好的解。

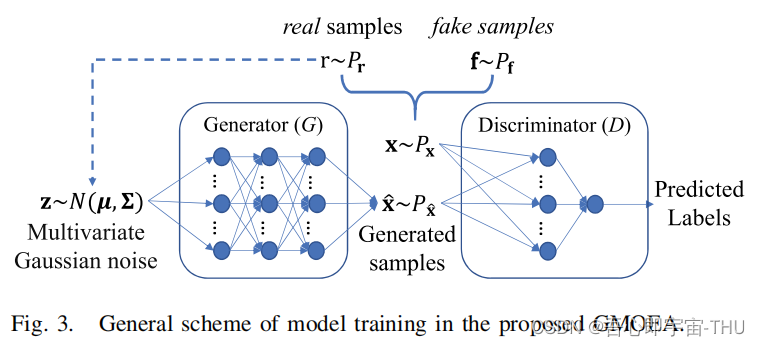
最后优化结果还可以,但不能打败IM-MOEA。
GAN 应用与多目标多任务优化
Evolutionary Multitasking for Multiobjective Optimization Based on Generative Strategies, 2023, TEVC

多目标多任务优化的定义,同时优化多个多目标优化任务,通过解的交流机制,使得相互之间能够分享求解知识和经验,然后能够加速每个任务的求解。
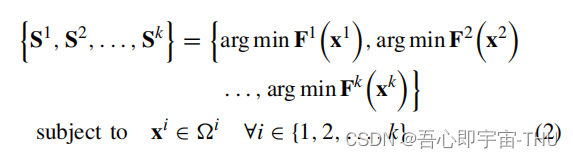
主要框架如下,多任务中知识迁移的关键有几种方法,一个是解的迁移,一个是数据分布的迁移,一个是隐式知识的迁移。而GAN的特性,刚好可以用一个数据分布,源分布,通过MLP去拟合目标分布,最终达到分布迁移的目的。那么思路就很清晰了,在每个任务之间,建立两个GAN,x->y建立一个,y->x又建立一个,支撑不同数据分布之间的数据迁移。最终达到加速优化的目的。
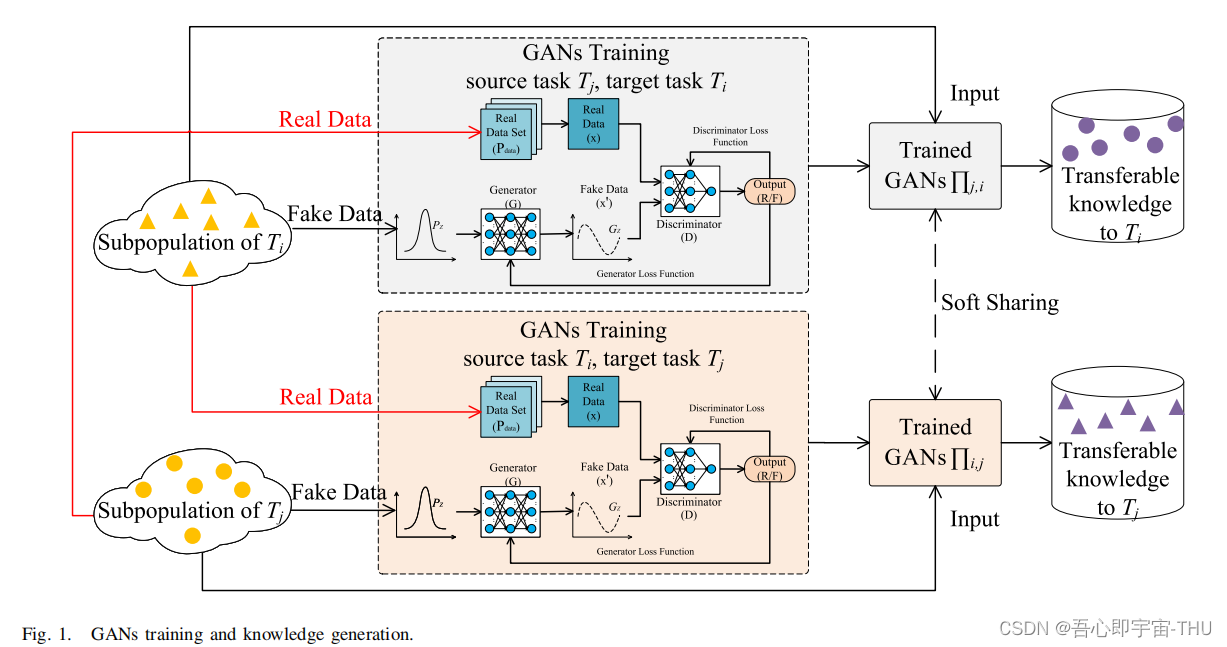
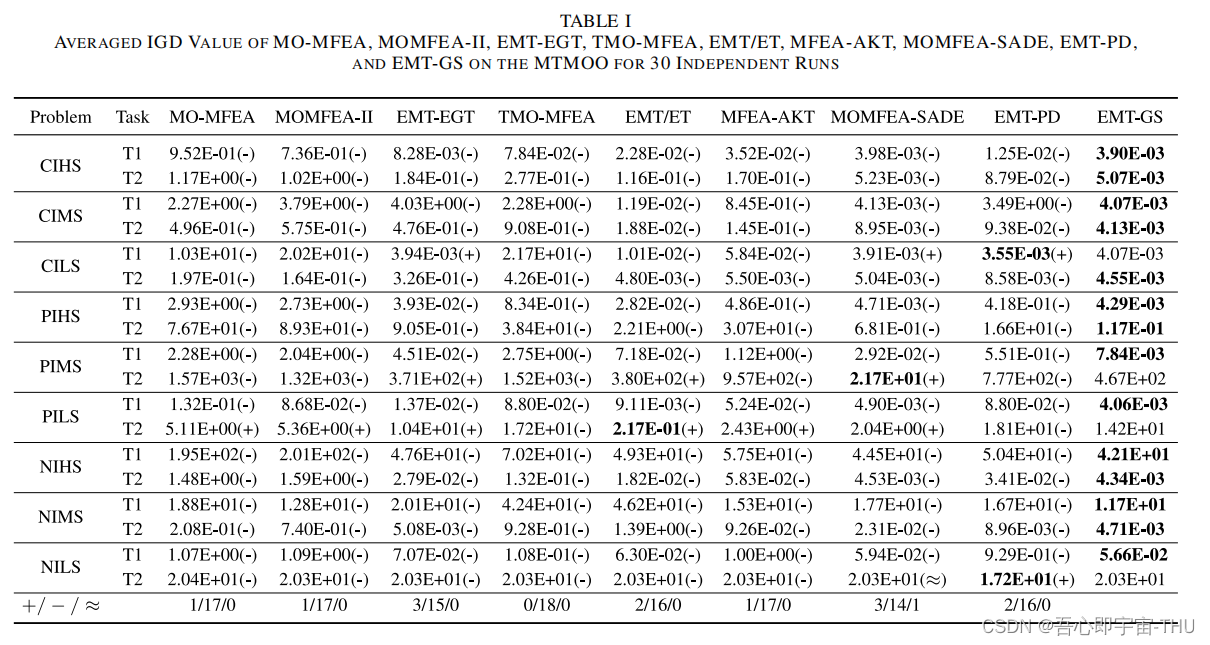
从优化的指标结果上来看,GAN的效果比其他多目标多任务算法都好。
展望
GAN可以用于不同类型的优化问题,昂贵优化问题,约束优化问题,多模态优化等等,只要是连续优化问题,不考虑时间成本的前提下,可以无限制的使用GAN来生成数据。但对于离散优化问题,是个很难的问题,需要大量的计算量。本身seqGAN的技术因为有MC采样,所以训练时候随着维度增长会爆炸。但由于是一个优化问题,在优化过程中,如果在线训练的话,就完全无法使用了。所以只能端到端的生成。这仍旧是个很难的问题。
稳定扩散模型 Stable Diffusion (目前最火的生成技术)
目前主流的生成模型在结构上的区别,据统计,在今年的ICLR上有一半论文投稿都是关于扩散模型的。可见该技术如此火爆。
参考博客——图解stable diffusion模型



Stable Diffusion 组成

Token 表示NLP中最小的语义单元,可以翻译为词/令牌

1. 图像信息创建器 Creator

2 图像解码器 Decoder


什么是扩散 Diffusion

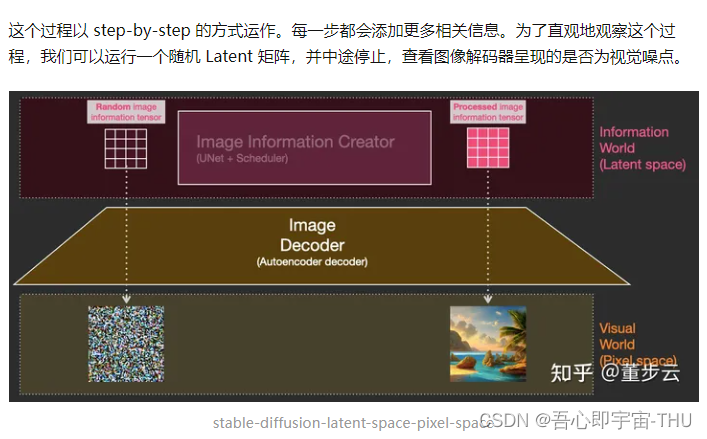


扩散模型的工作原理


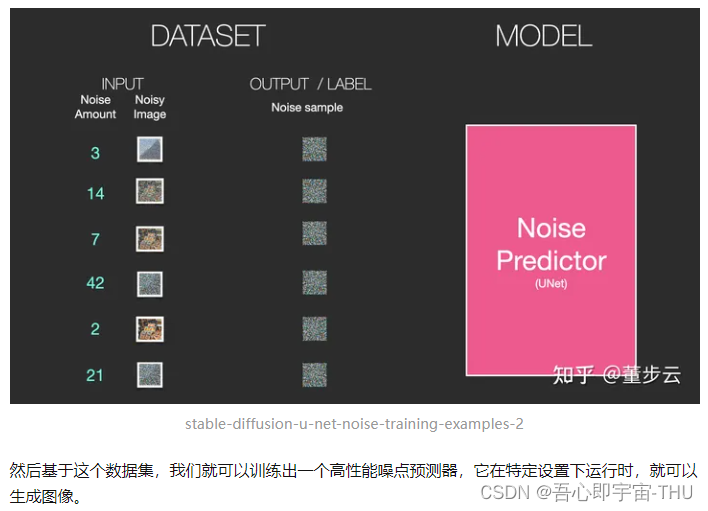
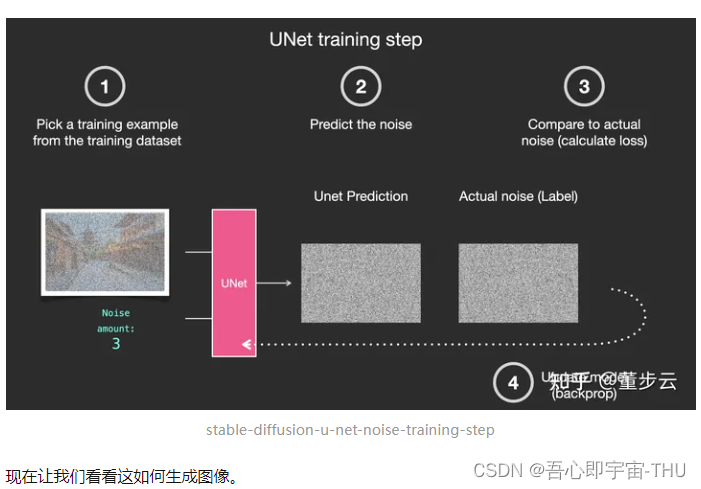
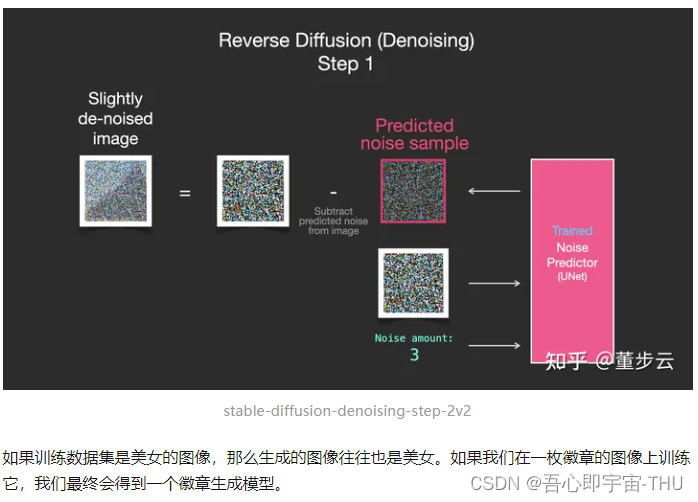
移除噪点,绘制图像

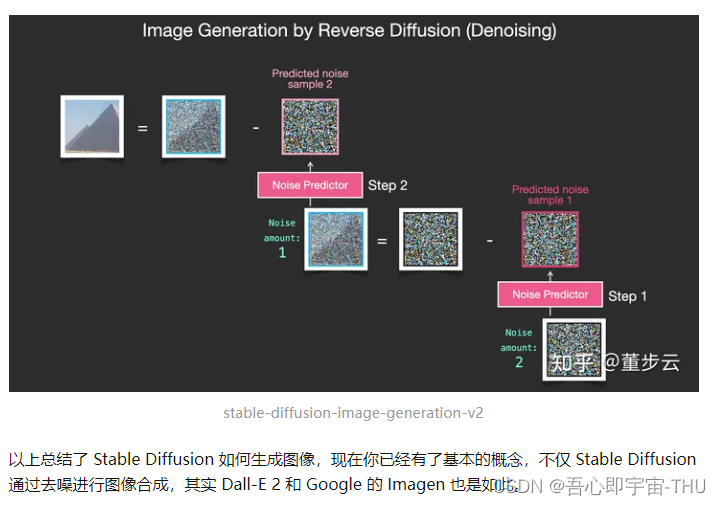
参考文献 https://arxiv.org/abs/2006.11239
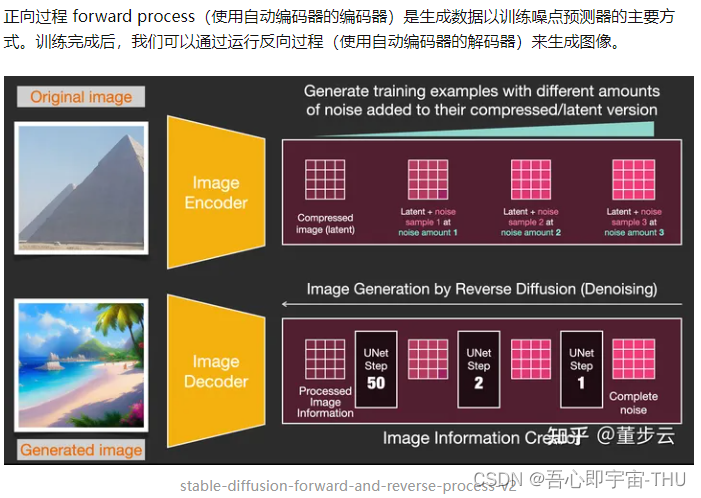
加速潜在空间(Latent)压缩数据上扩散
为了加快图像生成过程,Stable Diffusion 并不是在像素图像本身上运行扩散过程,而是在图像的压缩版本上运行。该论文称其为“Departure to Latent Space”。
参考文献:https://arxiv.org/abs/2112.10752


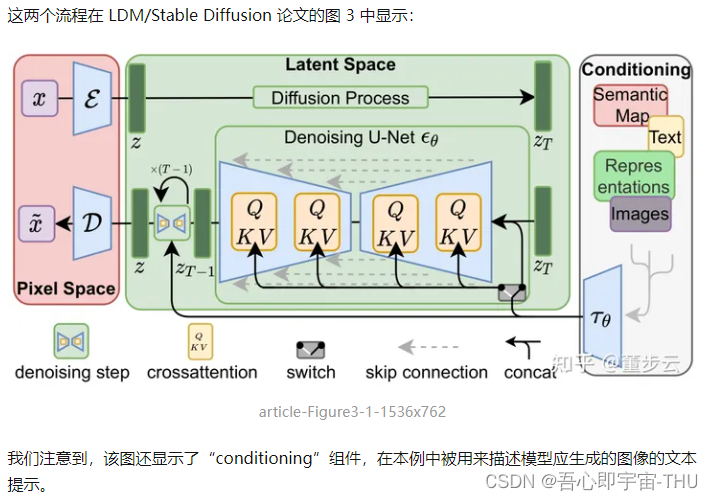
文本编码器:一种Transformer语言模型
Transformer 语言模型被用作语言理解组件,通过接受文本提示并转换为 Token 嵌入向量。目前发布的 Stable Diffusion 模型使用的是 ClipText(基于 GPT 的模型),而这篇为了方便讲解使用的是 BERT 模型。
https://jalammar.github.io/illustrated-gpt2/
https://jalammar.github.io/illustrated-bert/
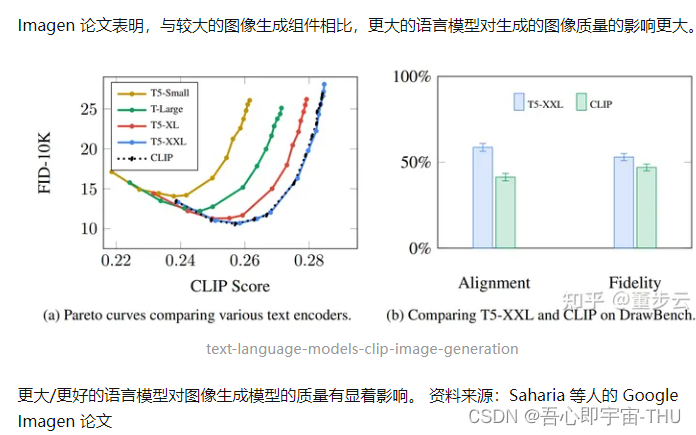
https://arxiv.org/abs/2205.11487
早期的 Stable Diffusion 模型只是插入了 OpenAI 发布的预训练 ClipText 模型。未来的模型可能会切换到新发布的更大的 OpenCLIP。
https://laion.ai/blog/large-openclip/
https://stability.ai/blog/stable-diffusion-v2-release
CLIP是如何训练的

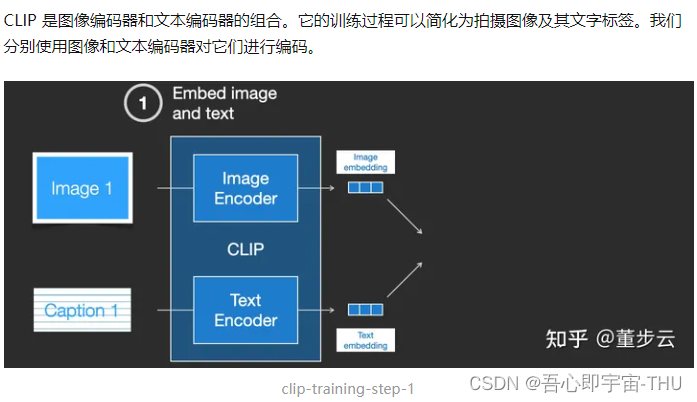
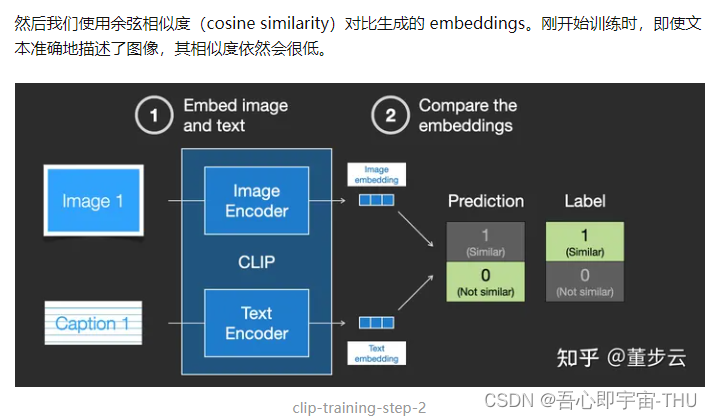
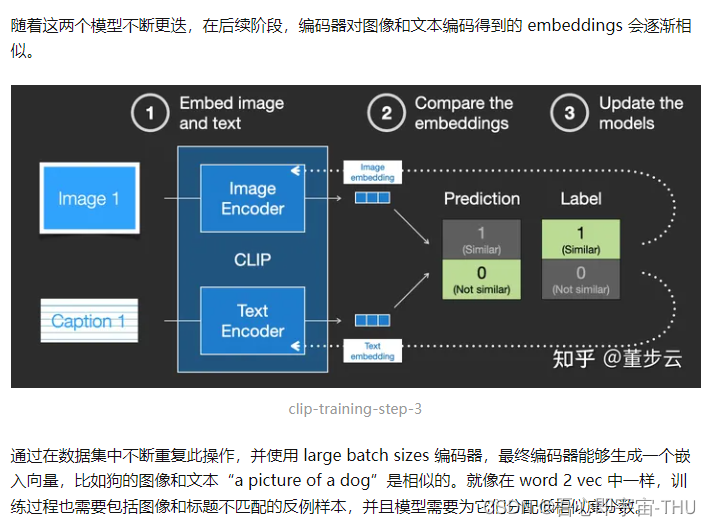
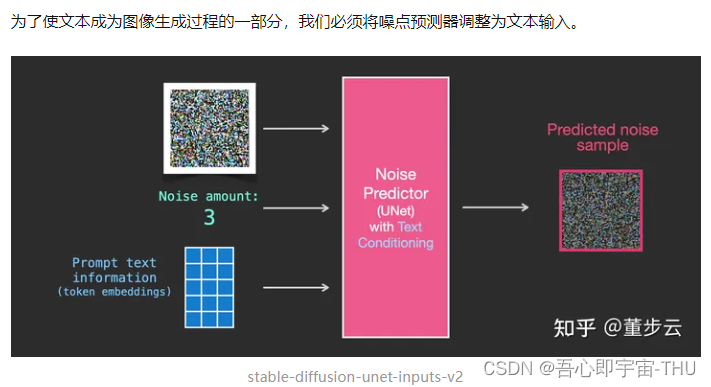
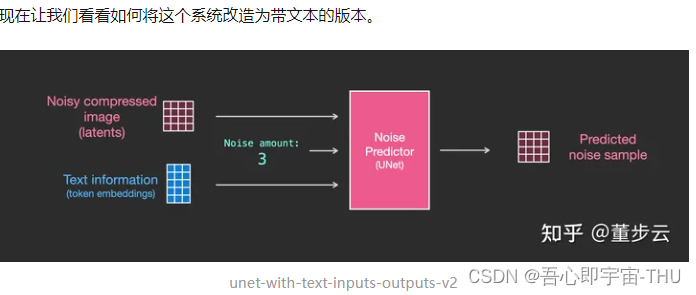
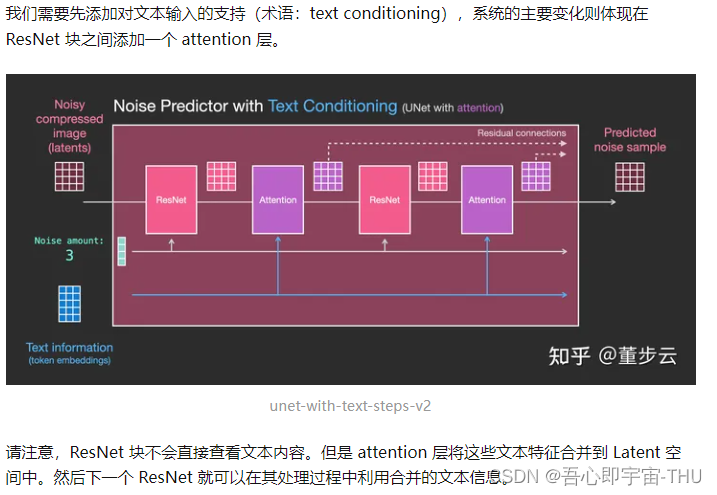
将文本信息输入图像生成过程
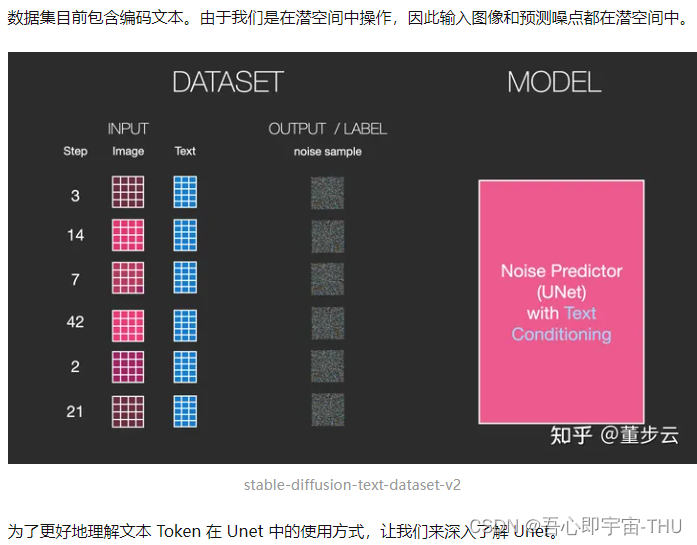
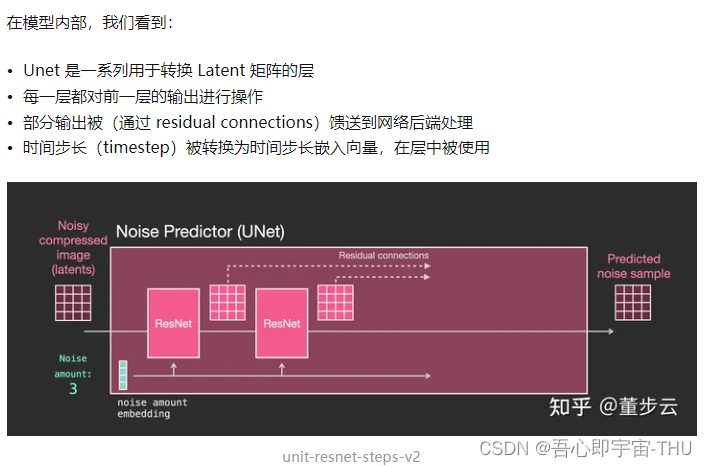
Unet噪点预测器的层级

Unet噪点预测器的层级(带文本)
原文结论
我希望这能让您对 Stable Diffusion 的工作原理有一个良好的第一印象。涉及许多其他概念,但我相信一旦您熟悉了上面的构建块,它们就会更容易理解。 下面的资源是我发现有用的重要后续步骤。如有任何更正或反馈,请在 Twitter 上与我联系。
https://twitter.com/JayAlammar
我的感受
稳定扩散模型,更像是大模型背景下的一项复杂的生成系统,每一个模块都由一个复杂的网络构造。其主要作用是通过文本的提示,让模型生成一个想要的图像。这种图像可能是训练库里的,也可能是生成的。SD的主要过程是,将大量的图像与本文对做成组成一个训练集,每个训练集加入多层噪声构成最终的训练集。1)首先要将文本信息与图像信息关联起来,那么就需要两个编码器,让文本的嵌入和图像的嵌入联系起来,这个过程需要通过预先相似度和网络训练调整。2)将文本提示信息的嵌入,和带噪声的图像输入到 噪声预测单元,来预测噪声。3)随后将噪声输入到解码单元,层层解码输出不同的噪声,最后把噪声完全去掉,生成最终的精美的图像。4)而图像编码这边就需要,将图像信息和噪声信息合成,层层递进,直到得到一个复杂的噪声图像。图像编码器与解码器联合起来训练,使得解码器最终达到可用的状态。5)图像编码器是一个Unet加一个调度器,图像解码器是一个自编码器,其中自编码器的编码和解码器里有很多注意力机制用于理解输入的文本提示。6)训练好的模型生成图像的流程是,输入文本,然后文本编码器CLIP转换为提示词,随后与一个随机噪声输入到图像生成器,做一个正向的扩散。扩散50步后,得到一个处理过的图像噪声。 随后输入图像解码器。再经过解码器的层层去噪就能生成最终的图片。

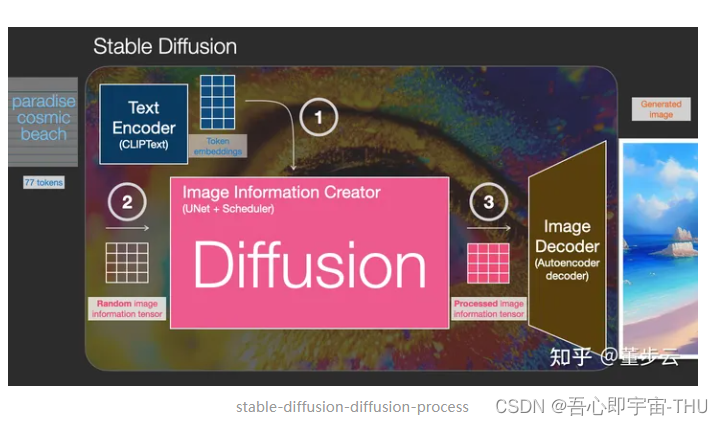
这是一个复杂的系统,对于优化过程有什么借鉴作用呢?我只能说,也许你可以通过一个文本提示,也不一定是文本提示,也许是某个解空间的解,输入后,和噪声一起稳定扩散,然后再解码得到一堆最优解。不过这个过程肯定需要巨大的计算量。对于普通的优化问题来说是一个性价比很低的事情。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!