训练 YOLOv8 实例分割模型
YOLOv8 是于2023年1月10日推出的。截至目前,它是计算机视觉领域中用于分类、检测和分割任务的最先进模型。该模型在精度和执行时间方面都优于所有已知模型。
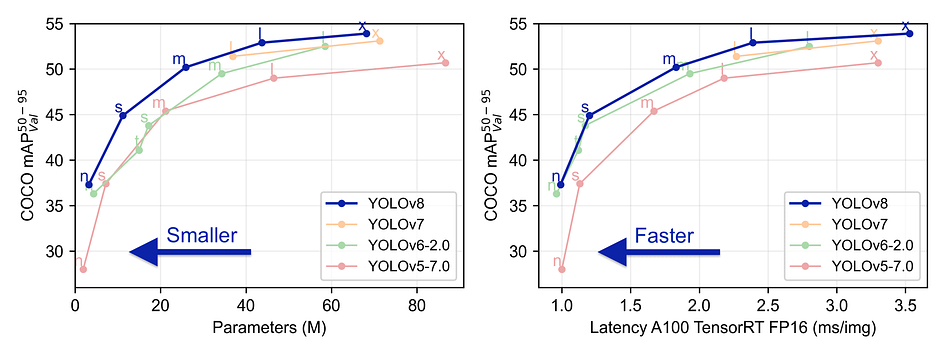
YOLOv8 与其他 YOLO 模型(来自 ultralytics)的比较 与以往所有的 YOLO 模型相比,ultralytics 团队在使该模型更易于使用方面做得非常出色,你甚至不再需要克隆 git 存储库!
创建图像数据集
在本文中,我创建了一个非常简单的示例,展示如何在你的数据上训练 YOLOv8,特别是针对分割任务。数据集很小且对模型来说“易学”,这样我们只需在普通 CPU 上训练几秒钟就能获得令人满意的结果。
我们将创建一个带有黑色背景的白色圆圈数据集。圆圈的大小会有所不同。我们将训练一个模型,对图像内的圆圈进行分割。
数据集如下所示:

数据集是使用以下代码生成的:
import numpy as np
from PIL import Image
from skimage import draw
import random
from pathlib import Path
def create_image(path, img_size, min_radius):
path.parent.mkdir( parents=True, exist_ok=True )
arr = np.zeros((img_size, img_size)).astype(np.uint8)
center_x = random.randint(min_radius, (img_size-min_radius))
center_y = random.randint(min_radius, (img_size-min_radius))
max_radius = min(center_x, center_y, img_size - center_x, img_size - center_y)
radius = random.randint(min_radius, max_radius)
row_indxs, column_idxs = draw.ellipse(center_x, center_y, radius, radius, shape=arr.shape)
arr[row_indxs, column_idxs] = 255
im = Image.fromarray(arr)
im.save(path)
def create_images(data_root_path, train_num, val_num, test_num, img_size=640, min_radius=10):
data_root_path = Path(data_root_path)
for i in range(train_num):
create_image(data_root_path / 'train' / 'images' / f'img_{i}.png', img_size, min_radius)
for i in range(val_num):
create_image(data_root_path / 'val' / 'images' / f'img_{i}.png', img_size, min_radius)
for i in range(test_num):
create_image(data_root_path / 'test' / 'images' / f'img_{i}.png', img_size, min_radius)
create_images('datasets', train_num=120, val_num=40, test_num=40, img_size=120, min_radius=10)
创建标签
既然我们有了图像数据集,我们需要为图像创建标签。通常情况下,我们需要手动完成这项工作,但由于我们创建的数据集非常简单,因此很容易编写代码来生成标签:
from rasterio import features
def create_label(image_path, label_path):
arr = np.asarray(Image.open(image_path))
# There may be a better way to do it, but this is what I have found so far
cords = list(features.shapes(arr, mask=(arr >0)))[0][0]['coordinates'][0]
label_line = '0 ' + ' '.join([f'{int(cord[0])/arr.shape[0]} {int(cord[1])/arr.shape[1]}' for cord in cords])
label_path.parent.mkdir( parents=True, exist_ok=True )
with label_path.open('w') as f:
f.write(label_line)
for images_dir_path in [Path(f'datasets/{x}/images') for x in ['train', 'val', 'test']]:
for img_path in images_dir_path.iterdir():
label_path = img_path.parent.parent / 'labels' / f'{img_path.stem}.txt'
label_line = create_label(img_path, label_path)
以下是标签文件内容的示例:
0 0.0767 0.08433 0.1417 0.08433 0.1417 0.0917 0.15843 0.0917 0.15843 0.1 0.1766 0.1 0.1766 0.10844 0.175 0.10844 0.175 0.1177 0.18432 0.1177 0.18432 0.14333 0.1918 0.14333 0.1918 0.20844 0.18432 0.20844 0.18432 0.225 0.175 0.225 0.175 0.24334 0.1766 0.24334 0.1766 0.2417 0.15843 0.2417 0.15843 0.25 0.1417 0.25 0.1417 0.25846 0.0767 0.25846 0.0767 0.25 0.05 0.25 0.05 0.2417 0.04174 0.2417 0.04174 0.24334 0.04333 0.24334 0.04333 0.225 0.025 0.225 0.025 0.20844 0.01766 0.20844 0.01766 0.14333 0.025 0.14333 0.025 0.1177 0.04333 0.1177 0.04333 0.10844 0.04174 0.10844 0.04174 0.1 0.05 0.1 0.05 0.0917 0.0767 0.0917 0.0767 0.08433
该标签对应于以下图像:

标签内容只是单独的一行文本。每个图像中只有一个对象(圆圈),每个对象在文件中由一行表示。如果每个图像中有多个对象,你应该为每个标记的对象创建一行。
第一个0表示标签的类别类型。因为我们只有一个类别类型(圆圈),所以始终为0。如果你的数据中有多个类别,你应该将每个类别映射到一个数字(0、1、2…),并在标签文件中使用该数字。
所有其他数字表示标记对象的边界多边形的坐标。格式为,坐标相对于图像的大小 — 你应该将坐标归一化为1x1的图像大小。例如,如果有一个点(15, 75),图像大小为120x120,则归一化点为(15/120,75/120)=(0.125,0.625)。
在处理图像库时,往往很难获得坐标的正确方向性。为了弄清楚这一点,对于 YOLO,X 坐标从左到右,Y 坐标从上到下。
YAML 配置
现在我们有了图像和标签。现在我们需要创建一个带有数据集配置的 YAML 文件:
yaml_content = f'''f'''
train: train/images
val: val/images
test: test/images
names: ['circle']
'''
with Path('data.yaml').open('w') as f:
f.write(yaml_content)
请注意,如果你有更多的对象类别,你需要在此处的 names 数组中添加它们,顺序与你在标签文件中的顺序相同。第一个类别为0,第二个为1,依此类推…
数据集文件结构
让我们使用 Linux tree 命令查看我们创建的文件结构:
tree .
data.yaml
datasets/
├── test
│ ├── images
│ │ ├── img_0.png
│ │ ├── img_1.png
│ │ ├── img_2.png
│ │ ├── ...
│ └── labels
│ ├── img_0.txt
│ ├── img_1.txt
│ ├── img_2.txt
│ ├── ...
├── train
│ ├── images
│ │ ├── img_0.png
│ │ ├── img_1.png
│ │ ├── img_2.png
│ │ ├── ...
│ └── labels
│ ├── img_0.txt
│ ├── img_1.txt
│ ├── img_2.txt
│ ├── ...
|── val
| ├── images
│ │ ├── img_0.png
│ │ ├── img_1.png
│ │ ├── img_2.png
│ │ ├── ...
| └── labels
│ ├── img_0.txt
│ ├── img_1.txt
│ ├── img_2.txt
│ ├── ...
训练模型
既然我们有了图像和标签,我们可以开始训练模型了。首先让我们安装包:
pip install ultralytics==8.0.38
ultralytics 库更新很快,有时会破坏 API,因此我更喜欢使用一个版本。下面的代码依赖于版本8.0.38(我撰写这些文字时的最新版本)。如果你升级到更新的版本,可能需要进行一些代码适应以使其正常工作。
然后开始训练:
from ultralytics import YOLO
model = YOLO("yolov8n-seg.pt")
results = model.train(
batch=8,
device="cpu",
data="data.yaml",
epochs=7,
imgsz=120,
)
为了简化本文,我使用了纳米模型(yolov8n-seg),只在 CPU 上进行了7个时期的训练。在我的笔记本电脑上,训练只需几秒钟。
有关用于训练模型的参数的更多信息,你可以查看这里。
了解结果
训练完成后,你将在输出的末尾看到一行类似于以下内容的行:
Results saved to runs/segment/train60
让我们看一些在这里找到的结果:
验证标签
from IPython.display import Image as show_image
show_image(file)

在这里,我们可以看到验证集部分的真实标签。这应该几乎完美地对齐。如果你发现这些标签未很好地覆盖了对象,很可能是你的标注不正确。
预测的验证标签
show_image(file)

在这里,我们可以看到经过训练的模型在验证集的一部分上所做的预测(与上面看到的部分相同)。这可以让你对模型的表现有所感觉。请注意,为了创建这张图片,应选择一个置信度阈值,这里使用的阈值是0.5,这并不总是最优的(我们稍后将讨论)。
精度曲线
为了理解这个和接下来的图表,你需要熟悉精度和召回的概念。这里有一个关于它们如何工作的好解释。
show_image(file)
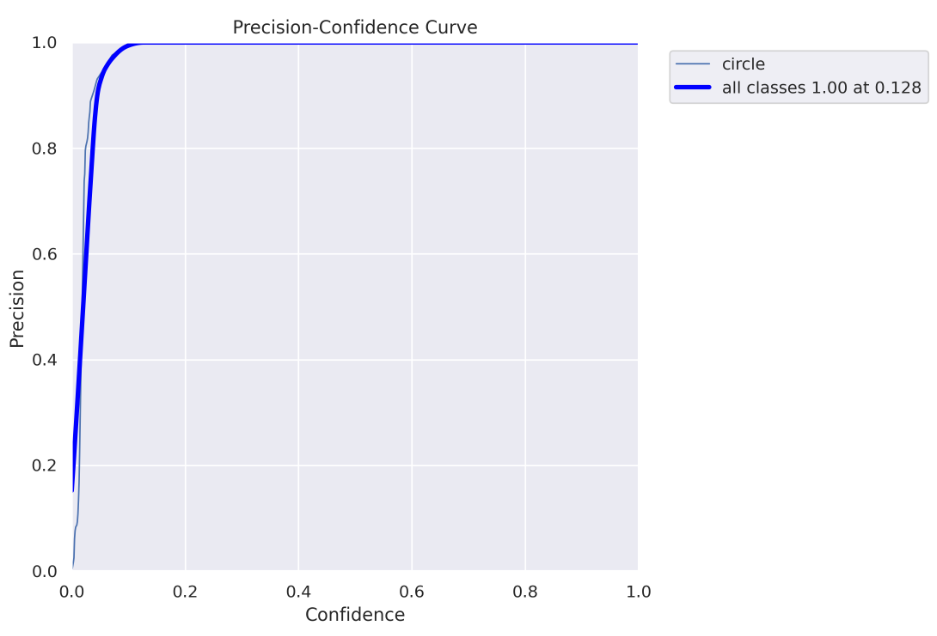
模型检测到的每个对象都有一定的置信度。通常情况下,如果在声明“这是一个圆圈”时越确定越好,你将只使用高置信度值(高置信度阈值)。当然,这是一种权衡——你可能会错过一些“圆圈”。另一方面,如果你希望“捕捉”尽可能多的“圆圈”,但愿意权衡一些不是真正的“圆圈”,你将同时使用低和高置信度值(低置信度阈值)。
上面的图表(以及下面的图表)可以帮助你决定使用哪个置信度阈值。在我们的案例中,我们可以看到,对于大于0.128的阈值,我们获得了100%的精度,这意味着所有对象都被正确预测。
请注意,因为我们实际上在进行分割任务,还有另一个重要的阈值需要关注——IoU(交并比),如果你对此不熟悉,可以在这里阅读有关它的信息。对于这个图表,使用了0.5的IoU。
召回曲线
show_image(file)
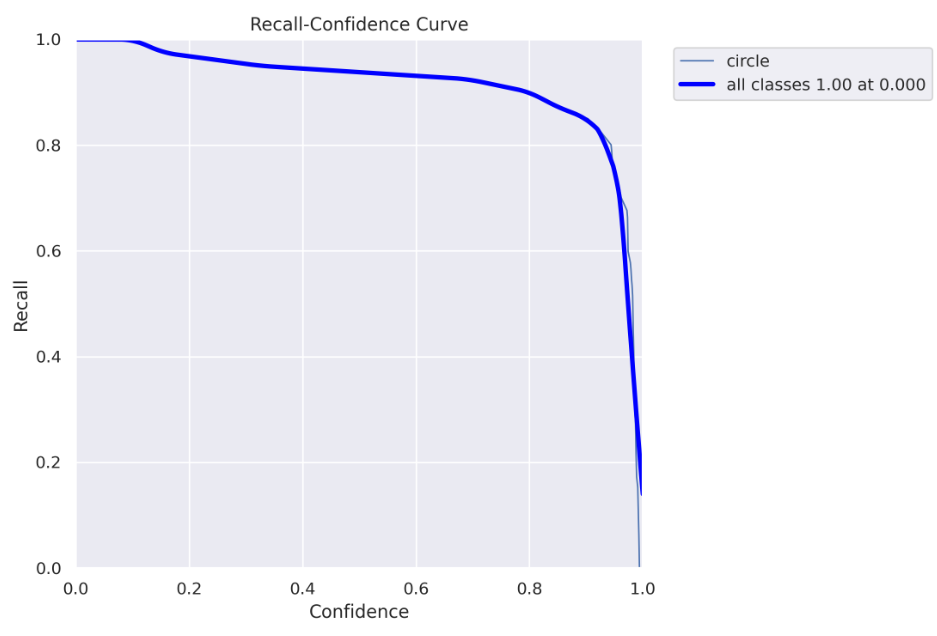
在这里,你可以看到召回图表,随着置信度阈值值的提高,召回率下降。这意味着你“捕捉”到的“圆圈”越少。
在这里,你可以看到为什么在这种情况下使用0.5的置信度阈值是一个不好的主意。对于0.5的阈值,你大约可以获得90%的召回率。然而,在精度曲线中,我们看到对于大于0.128的阈值,我们获得了100%的精度,所以我们不需要达到0.5,我们可以安全地使用0.128的阈值,既获得100%的精度,又几乎获得100%的召回率 😃
精度-召回曲线
这里有一个关于精度-召回曲线的好解释。
https://medium.com/@douglaspsteen/precision-recall-curves-d32e5b290248
show_image(file)
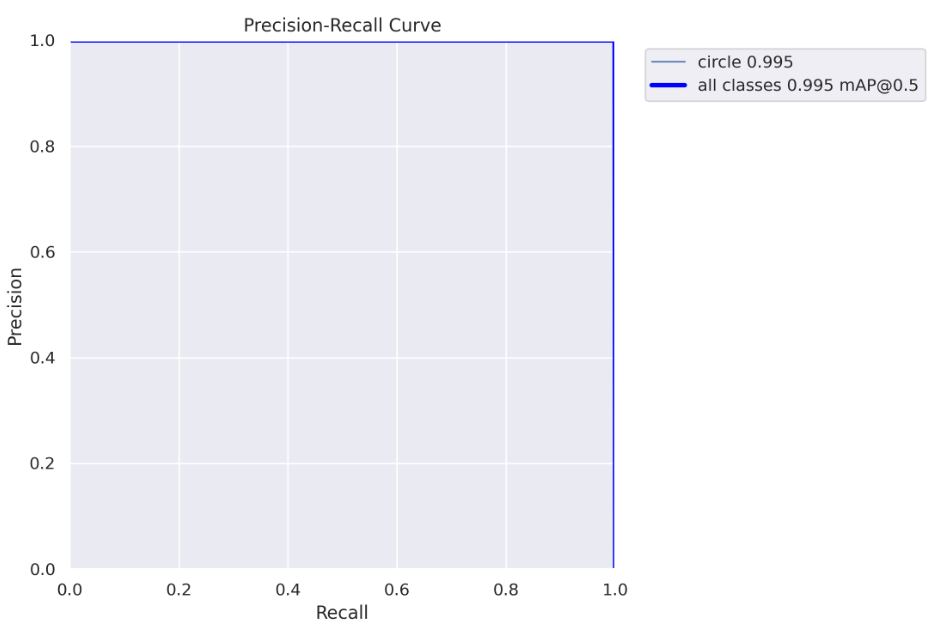
我们可以清楚地看到之前得出的结论,在这个模型中,我们可以获得几乎100%的精度和100%的召回率。
这个图表的缺点是我们无法看到应该使用哪个阈值,这就是为什么我们仍然需要上面的图表。
随时间变化的损失
show_image(file)
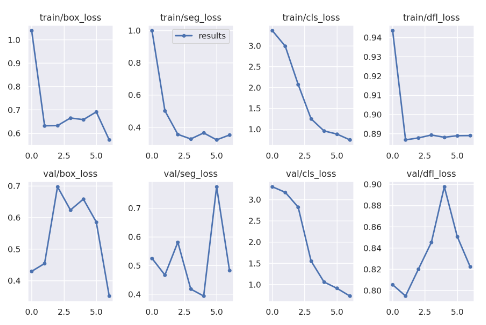
在这里,你可以看到不同损失在训练过程中如何变化,以及它们在每个时期后在验证集上的表现。
有很多关于损失的内容以及从这些图表中可以得出的结论,然而,超出了本文的范围。我只是想指出,你可以在这里找到相关信息 😃
使用训练好的模型
在结果目录中还可以找到模型本身。以下是如何在新图像上使用模型的方法:
my_model = YOLO('runs/segment/train60/weights/best.pt')'runs/segment/train60/weights/best.pt')
results = list(my_model('datasets/test/images/img_5.png', conf=0.128))
result = results[0]
结果列表可能具有多个值,每个检测到的对象一个值。因为在这个示例中,每个图像中只有一个对象,我们取第一个列表项。
你可以看到,我在这里传递了我们之前找到的最佳置信度阈值值(0.128)。
有两种方法可以获取图像中检测到的对象的实际位置。选择正确的方法取决于你打算如何处理结果。我将展示这两种方法。
result.masks.segments
[array([[ 0.10156, 0.34375],0.10156, 0.34375],
[ 0.09375, 0.35156],
[ 0.09375, 0.35937],
[ 0.078125, 0.375],
[ 0.070312, 0.375],
[ 0.0625, 0.38281],
[ 0.38281, 0.71094],
[ 0.39062, 0.71094],
[ 0.39844, 0.70312],
[ 0.39844, 0.69531],
[ 0.41406, 0.67969],
[ 0.42187, 0.67969],
[ 0.44531, 0.46875],
[ 0.42969, 0.45312],
[ 0.42969, 0.41406],
[ 0.42187, 0.40625],
[ 0.41406, 0.40625],
[ 0.39844, 0.39062],
[ 0.39844, 0.38281],
[ 0.39062, 0.375],
[ 0.38281, 0.375],
[ 0.35156, 0.34375]], dtype=float32)]
这将返回对象的边界多边形,类似于我们传递的标记数据的格式。
第二种方法:
result.masks.masks
tensor([[[0., 0., 0., ..., 0., 0., 0.],0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
这将返回一个形状为(1、128、128)的张量,表示图像中的所有像素。属于对象的像素接收1,背景像素接收0。
让我们看看蒙版的样子:
import torchvision.transforms as T
T.ToPILImage()(result.masks.masks).show()

这是原始图像:

虽然不完美,但对许多应用来说已经足够好了,IoU肯定高于0.5。
总之,新的 ultralytics 库与以前的 Yolo 版本相比更容易使用,特别是对于分割任务来说,现在已经成为了一流的工具。你还可以在 ultralytics 的新包中找到 Yolov5,因此如果你不想使用新的 Yolo 版本,你可以继续使用众所周知的 yolov5:
有一些主题没有涵盖,比如模型使用的不同损失函数,为创建 yolov8 所做的架构变化等等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!