Ceph Large omap objects现象及原理分析
Large omap objects现象
以下是真实的问题场景,以此文进行记录并分享。
Q1:集群出现了Large omap objects告警,这是什么问题?有什么影响?
Q2:Large omap objects告警的触发条件是什么?
Q3:这个告警怎么处理?或者怎么优化解决?
随着Ceph对象存储的产品不断成熟,用户数量的不断增加,对集群的性能考验也愈发严峻。特别是某些大型用户在特定场景下需要对单个bucket进行上传大量的对象,同时如果用户直接或者间接(应用程序调用list object接口)对单个bucket进行多次list object操作,会有一些IO响应慢,日志中可能会出现slow request,则可能会发现ceph出现了large omap objects告警。本文基于ceph luminous版本展开讨论,该版本引入了large omap objects告警功能。
集群出现如下large omap objects告警,下面对此展开分析:

出现上述告警后,运维人员可以通过ceph health detail查看具体的告警信息进行定位,一般large omap objects出现在存储池default.rgw.buckets.index。每个bucket在存储池default.rgw.buckets.index中都对应一个rados索引对象。存储池default.rgw.buckets.index中对象的格式为.dir.<marker>。
Bucket属性
先简单介绍bucket属性,并举例列出bucket的rados索引对象和bucket内对象名称的关系。

图1
上面给出了bucket的id,marker,owner,quota等属性。这里我们关注marker,通过marker信息,可以到对应的pool default.rgw.buckets.index找到该bucket,如下:

向bucket test1 分别上传obj1,obj2,obj3三个对象:

我们可以通过rados listomapkeys命令查看bucket的索引对象下的对象。

也就是说存储池default.rgw.buckets.index中bucket 对应的索引对象记录了bucket中对象等信息。这里联想单个bucket下大量对象的问题,大家应该会想到large omap objects的生成跟这个索引下的对象存在一定关系。
告警产生
接下来通过large omap objects中的告警信息追溯该告警产生的原因,并找出对应的指标值。
1. ?Large omap objects的告警来源如下:
void PGMap::get_health_checks(…) const
{
utime_t now = ceph_clock_now();
? const auto max = cct->_conf->get_val<uint64_t>("mon_health_max_detail");
? const auto& pools = osdmap.get_pools();
…
??? if (!detail.empty()) {
????? ostringstream ss;
????? ss << pg_sum.stats.sum.num_large_omap_objects << " large omap objects";//ceph -s中告警信息显示
????? auto& d = checks->add("LARGE_OMAP_OBJECTS", HEALTH_WARN, ss.str());
????? stringstream tip;
????? tip << "Search the cluster log for 'Large omap object found' for more "
????????? << "details.";
????? detail.push_back(tip.str());
????? d.detail.swap(detail);
}
…
}
从上述代码中可以发现large omap objects的数量统计来源于变量:pg_sum.stats.sum.num_large_omap_objects,那么通过对变量num_large_omap_objects的跟踪,得知large omap objects数量的来源是从ceph的deep scrub中检测出来的。
2.? Ceph deep scrub检测large omap objects
void PG::scrub_finish()
{
…
? if (deep_scrub) {
??? if ((scrubber.shallow_errors == 0) && (scrubber.deep_errors == 0))
????? info.history.last_clean_scrub_stamp = now;
??? info.stats.stats.sum.num_shallow_scrub_errors = scrubber.shallow_errors;
??? info.stats.stats.sum.num_deep_scrub_errors = scrubber.deep_errors;
info.stats.stats.sum.num_large_omap_objects = scrubber.omap_stats.large_omap_objects;
??? info.stats.stats.sum.num_omap_bytes = scrubber.omap_stats.omap_bytes;
??? info.stats.stats.sum.num_omap_keys = scrubber.omap_stats.omap_keys;
??? dout(25) << __func__ << " shard " << pg_whoami << " num_omap_bytes = "
???????????? << info.stats.stats.sum.num_omap_bytes << " num_omap_keys = "
???????????? << info.stats.stats.sum.num_omap_keys << dendl;
??? publish_stats_to_osd();
? } else {
…
}
上述的关键变量,并给他们做出解释。
num_large_omap_objects:指存储池中omap key或omap bytes超过阈值的shard数。
num_omap_bytes:对象的omap大小,这里的对象可以是bucket所有shard。
num_omap_keys:对象的omap key数量,这里的对象可以是bucket所有shard。
跟踪变量num_large_omap_objects这里的large_omap_objects是从下面的函数获取。
3.获取变量large_omap_objects
void PGBackend::be_omap_checks(…) const
{
…
????? ScrubMap::object& obj = it->second;
????? omap_stats.omap_bytes += obj.object_omap_bytes;
????? omap_stats.omap_keys += obj.object_omap_keys;
????? if (obj.large_omap_object_found) {
??????? pg_t pg;
??????? auto osdmap = get_osdmap();
??????? osdmap->map_to_pg(k.pool, k.oid.name, k.get_key(), k.nspace, &pg);
??????? pg_t mpg = osdmap->raw_pg_to_pg(pg);
??????? omap_stats.large_omap_objects++;
??????? warnstream << "Large omap object found. Object: " << k
?????????????????? << " PG: " << pg << " (" << mpg << ")"
?????????????????? << " Key count: " << obj.large_omap_object_key_count
?????????????????? << " Size (bytes): " << obj.large_omap_object_value_size
?????????????????? << '\n';
??????? break;
????? }
…
}
从上述判断if (obj.large_omap_object_found)得知,需要根据变量large_omap_object_found来确定large omap对象的判断依据。
4.Ceph deep scrub获取omap相关属性,并将单个shard的omap_keys和omap_bytes跟阈值进行比较,判断当前shard是否为large omap objects。
int ReplicatedBackend::be_deep_scrub(…)
{
…
? int max = g_conf->osd_deep_scrub_keys;
? while (iter->status() == 0 && iter->valid()) {
??? pos.omap_bytes?+= iter->value().length();
??? ++pos.omap_keys;//获取omap_keys数量
??? --max;
??? fixme: we can do this more efficiently.
??? bufferlist bl;
??? ::encode(iter->key(), bl);
??? ::encode(iter->value(), bl);
??? pos.omap_hash << bl;
??? iter->next();
…
? }
? if (pos.omap_keys > cct->_conf->
??? osd_deep_scrub_large_omap_object_key_threshold ||
????? pos.omap_bytes > cct->_conf->
??? osd_deep_scrub_large_omap_object_value_sum_threshold) {
??? dout(25) << __func__ << " " << poid
??? ???? << " large omap object detected. Object has " << pos.omap_keys
??? ???? << " keys and size " << pos.omap_bytes << " bytes" << dendl;
o.large_omap_object_found = true;//比较每个分片的阈值
??? o.large_omap_object_key_count = pos.omap_keys;
??? o.large_omap_object_value_size = pos.omap_bytes;
??? map.has_large_omap_object_errors = true;
? }
…
}
当变量large_omap_object_found为true时需要满足以下两个条件之一即可:
1.pos.omap_keys>osd_deep_scrub_large_omap_object_key_threshold
2.pos.omap_bytes>osd_deep_scrub_large_omap_object_value_sum_threshold
默认阈值:
osd_deep_scrub_large_omap_object_key_threshold为200000(20万)
osd_deep_scrub_large_omap_object_value_sum_threshold为1G
通过上述变量的跟踪,可以得知large omap objects是通过ceph deep scrub进行发现并上报的,遍历每个索引对象bucket中的分片(分片配置下文会讲),当分片的omap_keys的数量或omap_bytes的大小超过上述阈值时,会影响到large omap objects,并产生告警。
分片配置
当用户将大量对象(数百万个)都存在一个bucket中时,存储桶的索引操作会让性能受到严重影响。RGW中存在配置可以对索引进行分片,减少性能瓶颈。在对象存储中存在配置分片(shard)存在两个方法:
1.? rgw_override_bucket_index_max_shards(默认值为0)
2.? bucket_index_max_shards(这个在multisite中应用较多,这里不讨论)
在图1中看到的bucket info中rgw_override_bucket_index_max_shards值为0 ,表示桶的索引分片处于关闭状态。下面我们可以看下这个配置的生效阶段。
1.? 获取bucket分片值
int RGWRados::init_complete()
{
…
? bucket_index_max_shards = (cct->_conf->rgw_override_bucket_index_max_shards ? cct->_conf->rgw_override_bucket_index_max_shards :
???????????????????????????? get_zone().bucket_index_max_shards);
? if (bucket_index_max_shards > get_max_bucket_shards()) {
??? bucket_index_max_shards = get_max_bucket_shards();//最大值不能超过65521
??? ldout(cct, 1) << __func__ << " bucket index max shards is too large, reset to value: "
????? << get_max_bucket_shards() << dendl;
? }
? ldout(cct, 20) << __func__ << " bucket index max shards: " << bucket_index_max_shards << dendl;
…
}
上述bucket分片值在创建桶的时候进行了初始化,如下:
int RGWRados::create_bucket(…)
{
…
??? if (pmaster_num_shards) {
????? info.num_shards = *pmaster_num_shards;
??? } else {
? info.num_shards = bucket_index_max_shards;
}
…
??? int r = init_bucket_index(info,?info.num_shards);
…
}
bucket_index_max_shards最终写入到bucket info的num_shards中。
对象的shard分配
下面我们通过上传一个对象来跟踪该对象最终是怎么分配到具体的shard中的。为了测试方便我们将rgw_override_bucket_index_max_shards设置为5.
RGW中上传对象的函数入口:
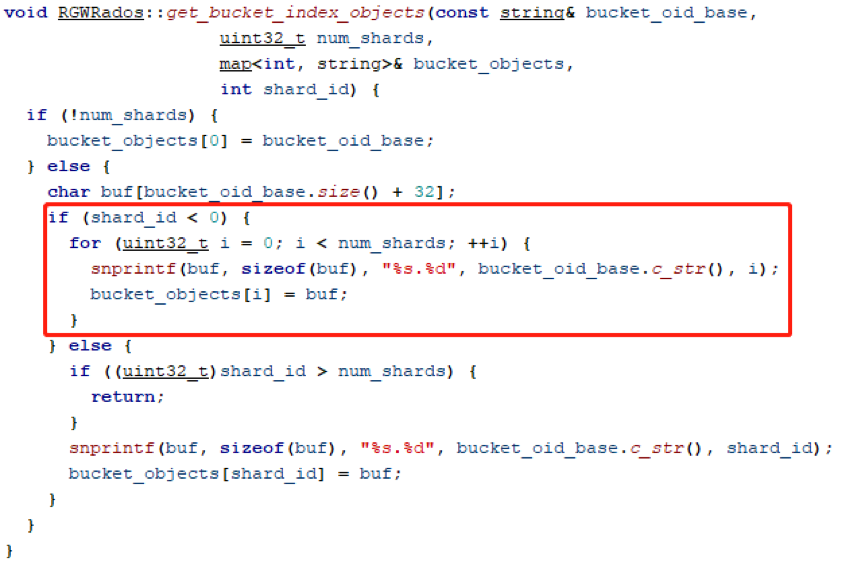
int RGWRados::get_bucket_index_object(const string& bucket_oid_base, const string& obj_key,//上传的对象名称
??? uint32_t num_shards, RGWBucketInfo::BIShardsHashType hash_type, string *bucket_obj, int *shard_id)
{
? int r = 0;
? switch (hash_type) {
??? case RGWBucketInfo::MOD:
????? if (!num_shards) {
??????? By default with no sharding, we use the bucket oid as itself
??????? (*bucket_obj) = bucket_oid_base;
??????? if (shard_id) {
????????? *shard_id = -1;
??????? }
????? } else {
??????? uint32_t sid = rgw_bucket_shard_index(obj_key, num_shards);//用hash算法获取shard_id
…
??????? }
????? }
????? break;
??? default:
????? r = -ENOTSUP;
? }
? return r;
}
inline函数如下,rgw_bucket_shard_index将obj_key和设置的shard数,通过哈希和求模算法,得到具体的分片序号。根据哈希的伪随机可知,同名对象的shard分配是固定的,也就是如果对象删除后,再次上传,在相同的shard上仍然能找到同名的对象。
static inline uint32_t rgw_bucket_shard_index(const std::string& key,
????????????????? ????? int num_shards) {
? uint32_t sid = ceph_str_hash_linux(key.c_str(), key.size());
? uint32_t sid2 = sid ^ ((sid & 0xFF) << 24);
? return?rgw_shards_mod(sid2, num_shards);
}
这里做如下测试,向同一个bucket中上传两次同名文件,但是大小不一样,验证其shard分片:
1.查看创建桶的shard数,rgw_override_bucket_index_max_shards值为5.对应的bucket的分片数也为5,格式为.dir.<markder>.<shard>.

2. ?向测试桶testbk中上传对象test_obj,对象存储在分片2中,即.dir.<marker>.2。
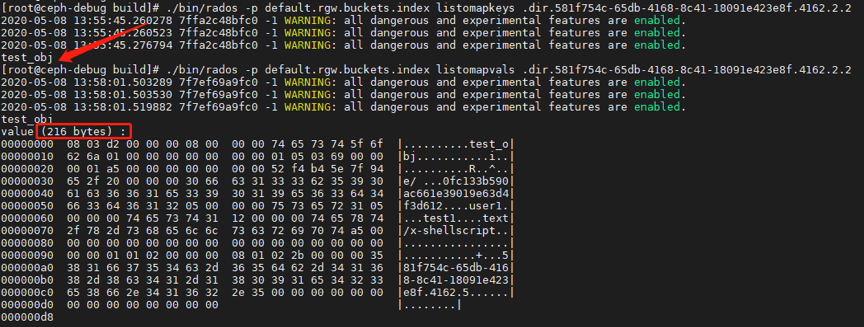
3.? 删除原test_obj,并上传不同大小的test_obj,对象仍然存储在分片2中
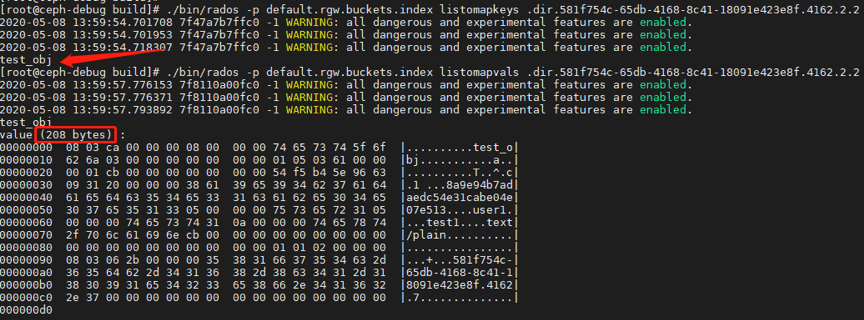
从上述测试结果来看,验证了同名对象分配的shard是不变的。
Bucket list请求
这次问题发生的前提条件就是通过RGW日志发现client存在大量的bucket list请求,导致IO无法及时响应,存在slow request问题。我们下面探索一下list请求的底层处理。
RGW请求处理
RGW作为client,在发出list object请求时,调用关系如下:

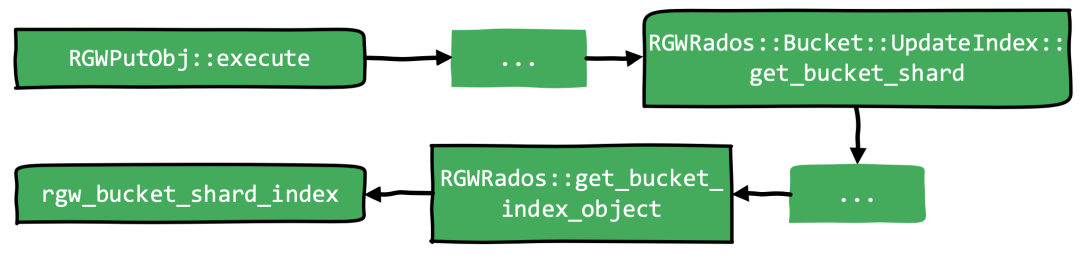
1. ?RGWRados::open_bucket_index调用如下函数,根据bucket_info.num_shards获取bucket全部的分片,便于后面进行遍历查找。
2. ?issue_bucket_list_op操作分类两个主要步骤:
1)?定义bucket list操作类型,便于OSD进行对应的请求处理。
2) 进行异步操作。
static bool issue_bucket_list_op(…) {
? librados::ObjectReadOperation op;
? cls_rgw_bucket_list_op(op, start_obj, filter_prefix,
???????????????????????? num_entries, list_versions, pdata);
? return manager->aio_operate(io_ctx, oid, &op);
}
上述函数首先定义了bucket list的操作类型,然后异步执行这个操作。我们进一步查看这个OP的类型如下。
通过cls_rgw_bucket_list_op定义了这个请求的OP类型,以便于后续OSD接收到请求后对应的请求处理。
void cls_rgw_bucket_list_op(…)
{
…
? op.exec(RGW_CLASS, RGW_BUCKET_LIST, in, new ClsBucketIndexOpCtx<rgw_cls_list_ret>(result, NULL));
}
#define RGW_CLASS "rgw"
#define RGW_BUCKET_LIST "bucket_list"
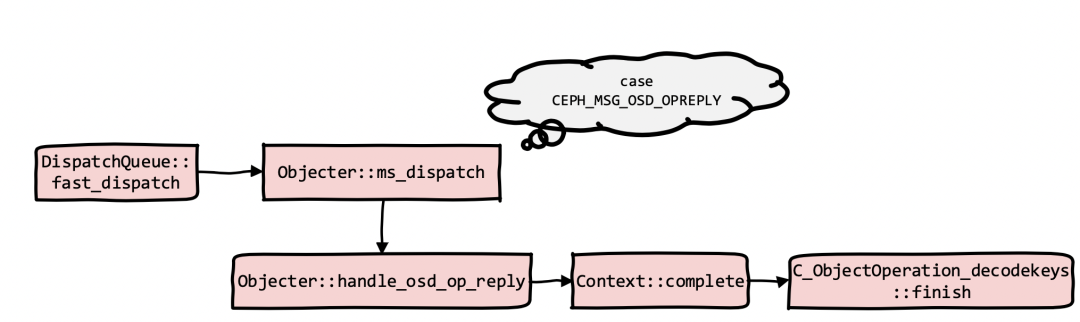
以下是RGW请求发送及OSD请求处理关系图

图2?RGW,OSD发送消息处理
Op类型定义
通过宏定义知道这个OP类型是bucket_list操作,结合图2,后续OSD收到该请求后会调用对应的函数进行处理。
紧接着librados::ObjectOperation::exec à ObjectOperation::call
查看ObjectOperation::call,增加了OSD的操作类型是CEPH_OSD_OP_CALL。
void call(const char *cname, const char *method, bufferlist &indata,
??? ??? bufferlist *outdata, Context *ctx, int *prval) {
??? add_call(CEPH_OSD_OP_CALL, cname, method, indata, outdata, ctx, prval);
? }
请求异步执行

发送对应的请求给OSD处理。_send_op中定义的消息类型是MOSDOp
class MOSDOp : public MOSDFastDispatchOp
通过类的定义可知,继承了fastdispatch。消息类型是CEPH_MSG_OSD_OP。
MOSDOp()
??? : MOSDFastDispatchOp(CEPH_MSG_OSD_OP, HEAD_VERSION, COMPAT_VERSION),
????? partial_decode_needed(true),
????? final_decode_needed(true) { }
OSD消息处理
通过发送的fastdispatch消息类型定义,OSD会从ms_fast_dispatch入口进行处理,调用关系如下,OSD将此消息进行入队操作,如图2。
OSD消息队列处理
PrimaryLogPG::do_osd_ops函数中涉及到omap key操作的有三种情况:
1.case CEPH_OSD_OP_CALL
这里会处理RGW过来的bucket list请求操作。
ClassHandler::ClassMethod *method = cls->get_method(mname.c_str());
??? if (!method) {
??? ? dout(10) << "call method " << cname << "." << mname << " does not exist" << dendl;
??? ? result = -EOPNOTSUPP;
??? ? break;
??? }
??? int flags = method->get_flags();
??? if (flags & CLS_METHOD_WR)
??? ? ctx->user_modify = true;
??? bufferlist outdata;
??? dout(10) << "call method " << cname << "." << mname << dendl;
??? int prev_rd = ctx->num_read;
??? int prev_wr = ctx->num_write;
??? result = method->exec((cls_method_context_t)&ctx, indata, outdata);
上述method是调用RGW的bucket list,也就是OP类型定义中确定的rgw_bucket_list函数。然后调用read_bucket_header à cls_cxx_map_read_header
再次调用do_osd_ops 的case CEPH_OSD_OP_OMAPGETHEADER
int cls_cxx_map_read_header(cls_method_context_t hctx, bufferlist *outbl)
{
? PrimaryLogPG::OpContext **pctx = (PrimaryLogPG::OpContext **)hctx;
? vector<OSDOp> ops(1);
? OSDOp& op = ops[0];
? int ret;
? op.op.op =?CEPH_OSD_OP_OMAPGETHEADER;
? ret = (*pctx)->pg->do_osd_ops(*pctx, ops);
? if (ret < 0)
??? return ret;
? outbl->claim(op.outdata);
? return 0;
}
2.case CEPH_OSD_OP_OMAPGETHEADER
1.? omap get header的处理情况
case?CEPH_OSD_OP_OMAPGETHEADER:
????? tracepoint(osd, do_osd_op_pre_omapgetheader, soid.oid.name.c_str(), soid.snap.val);
????? if (!oi.is_omap()) {
??? return empty header
??? break;
????? }
????? ++ctx->num_read;
????? {
??? osd->store->omap_get_header(ch, ghobject_t(soid), &osd_op.outdata);
??? ctx->delta_stats.num_rd_kb += SHIFT_ROUND_UP(osd_op.outdata.length(), 10);
??? ctx->delta_stats.num_rd++;
????? }
????? break;
2. ?如果ceph底层采用filestore,那么调用关系如下:
FileStore::omap_get_header?
—> DBObjectMap::get_header
int DBObjectMap::get_header(const ghobject_t &oid,
?????????? ??? bufferlist *bl)
{
? MapHeaderLock hl(this, oid);
? Header header = lookup_map_header(hl, oid);
? if (!header) {
??? return 0;
? }
? return _get_header(header, bl);
}
从上述函数可知,最后是从数据库中获取对应数据,并存入内存变量bl中
3.case CEPH_OSD_OP_OMAPGETKEYS
这里调用DBObjectMap::get_iterator获得数据库的迭代器,用来处理listomapkeys请求,从下面代码得知最终是根据oid从数据库中获取数据。最后将获得的key序列化到内存变量bl中。如果是对default.rgw.buckets.index中索引对象进行listomapkeys,那么这里encode到bl中的就是bucket内的对象名。
ObjectMap::ObjectMapIterator DBObjectMap::get_iterator(
? const ghobject_t &oid)
{
? MapHeaderLock hl(this, oid);
? Header header = lookup_map_header(hl, oid);
? if (!header)
??? return ObjectMapIterator(new EmptyIteratorImpl());
? DBObjectMapIterator iter = _get_iterator(header);
? iter->hlock.swap(hl);
? return iter;
}
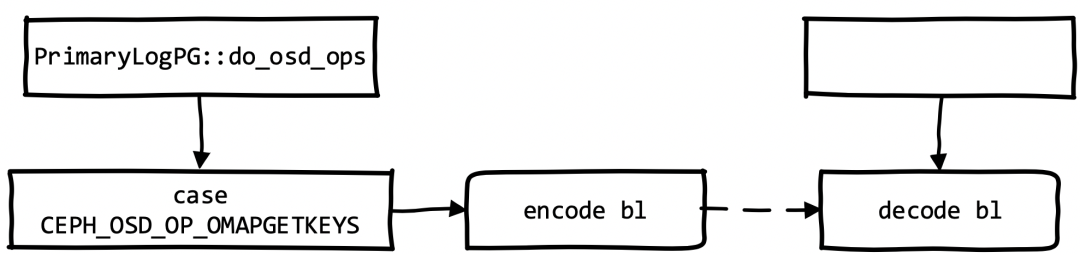
Object收到OSD消息的处理
C_ObjectOperation_decodekeys::finish如下:
void finish(int r) override {
????? if (r >= 0) {
??? bufferlist::iterator p = bl.begin();
??? try {
??? ? if (pattrs)
??? ??? ::decode(*pattrs, p);
??? ? if (ptruncated) {
??? ??? std::set<std::string> ignore;
??? ??? if (!pattrs) {
??? ????? ::decode(ignore, p);
??? ????? pattrs = &ignore;
??? ??? }
??? ??? if (!p.end()) {
??? ????? ::decode(*ptruncated, p);
??? ??? } else {
??? ????? // the OSD did not provide this.? since old OSDs do not
??? ????? // enfoce omap result limits either, we can infer it from
??? ????? // the size of the result
??? ????? *ptruncated = (pattrs->size() == max_entries);
??? ??? }
??? ? }
??? }
??? catch (buffer::error& e) {
??? ? if (prval)
??? ??? *prval = -EIO;
??? }
????? }
??? }
将传入的bl进行反序列化得到该bucket下的对象名称。
rados listomapkeys
用户采用RGW进行list objects操作时,其实是对bucket instance的每个分片进行遍历。底层提供了rados listomapkeys命令可以对单个分片进行list操作,下面简单介绍其调用关系。
我们从命令说起,如下:
rados -p default.rgw.buckets.index listomapkeys .dir.<marker>.<shard_id>
命令执行的入口
rados_tool_common?
->librados::IoCtx::omap_get_keys
在librados::IoCtx::omap_get_keys分为两个重要的操作
1. ibrados::ObjectReadOperation::omap_get_keys2 ->librados::ObjectReadOperation::omap_get_keys:定义请求OP类型为CEPH_OSD_OP_OMAPGETKEYS
2. ?librados::IoCtx::operate:发送操作的消息至OSD。后续的消息发送路径与RGW的请求一致。这里给出调用关系:librados::IoCtxImpl::operate_read—> … Objecter::_send_op
OSD根据请求类型CEPH_OSD_OP_OMAPGETKEYS,在PrimaryLogPG::do_osd_ops对该场景进行处理,获取bucket instance分片下的omap keys即对象名称。
总结
1.large omap objects的告警信息来源于ceph deep scrub。
2.假设存在如下值,根据以上的分析逻辑,当pool default.rgw.buckets.index中单个bucket分片超过20万时会出现告警,那么在不产生large omap objects告警的情况下,单个bucket最多存放64*20万=1280万个对象。
osd_deep_scrub_large_omap_object_key_threshold=200000(20万,默认值)
rgw_override_bucket_index_max_shards=64
3.如果想提高bucket list性能,业界常用的做法是用SSD为索引pool加速,同时修改以上两个参数值到一个合理值。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!