从原理到实践:探究一致性哈希算法的系统设计
前段时间有个朋友在面试过程中遇到了一个系统设计题,面试官先是让他聊了聊一致性哈希算法的原理和应用场景,而后又让他动手实现一致性哈希算法,一系列围绕一致性哈希算法的问题,并当场手撕代码,让他痛苦不堪,最后没能完成这道一致性哈希算法的系统设计题。
这个算法的原理和应用在我们平时的工作中,经常都会接触到,主要看你是不是够细心。说原理都没啥大问题,代码实现其实也不难,本文我们就结合一致性哈希算法在工程中的应用场景来探究一下这个算法,让你看完后就想说一句“忒简单么,你说!”。
原理
一致性哈希算法是一种分布式算法,用于将数据均匀地分布在多个节点中,同时最大限度地减少在集群中节点上线或下线时需要移动的数据量,降低热点出现的可能性,提高整体性能。
其主要思想就是抽象出一个哈希环,将节点和数据通过哈希函数映射到同一个哈希环上,映射后的数据通过顺时针方向寻找到的第一个节点,就是负责处理当前数据的节点。
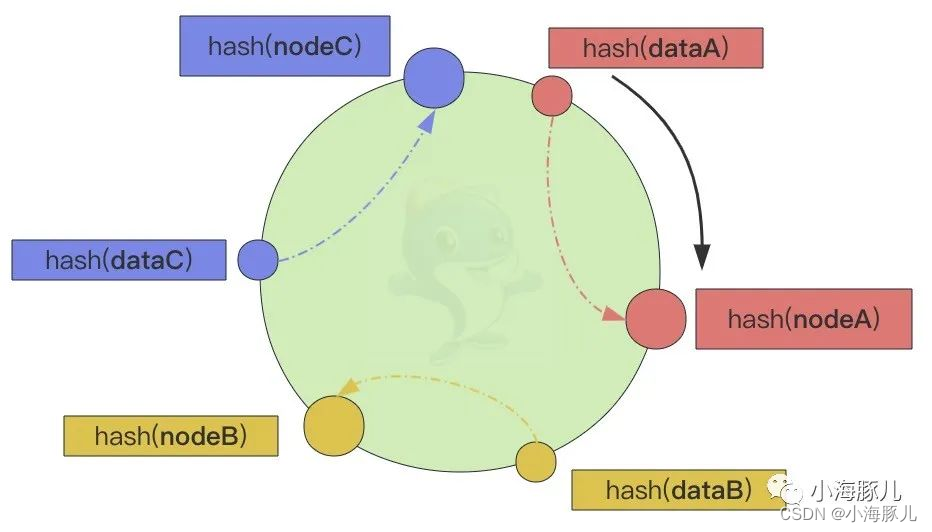
根据一致性哈希算法,dataA -> nodeA,dataB -> nodeB,dataC -> nodeC。上面看似挺好,但还存在一定的问题,由于哈希函数的不确定性,很可能会出现数据分布不均衡的情况。
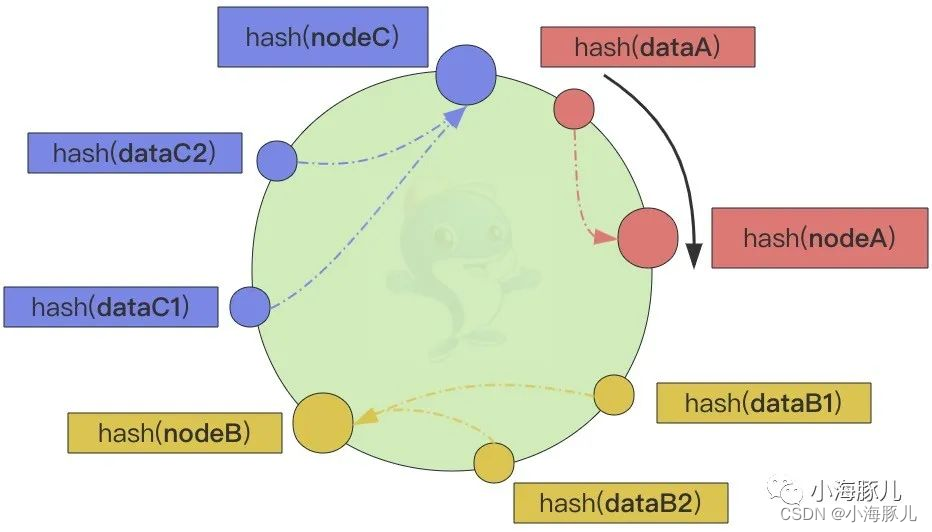
如上图,nodeB 和 nodeC 负责的哈希环比 nodeA 负责的哈希环要长很多,这样就会导致 nodeB 和 nodeC 的负载比 nodeA 的负载要高,存取的压力都要高于后者,负载很不均衡。尤其是某个节点下线后,这个节点的负载就会转移到顺时针方向的下一个节点上,导致下一个节点的哈希环变长,负载也在不断地增加,导致数据倾斜。节点上线亦可同理而论。
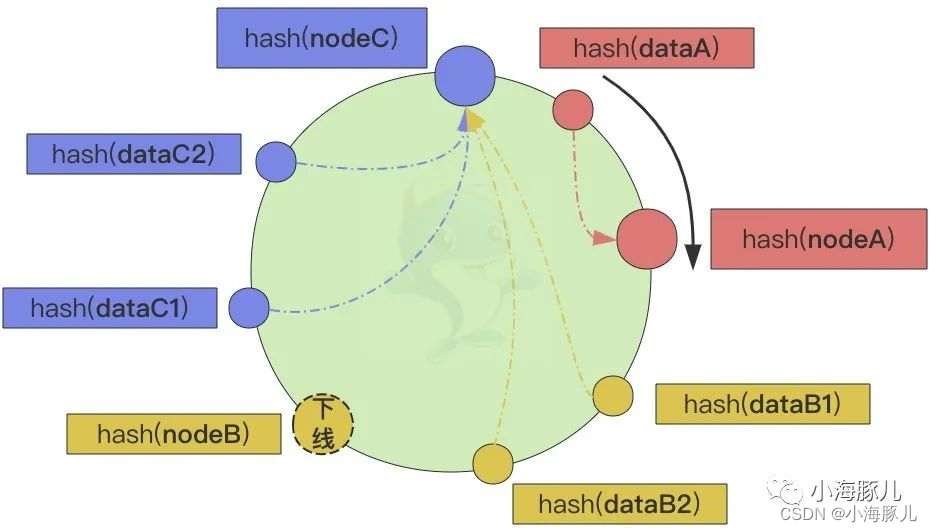
为了解决数据倾斜的问题,尤其是节点上下线时仍然能够正确地将数据均匀地映射到相应的节点上,一致性哈希算法引入了虚拟节点的概念,使得哈希环上的每个物理节点被映射为多个虚拟节点,从而增加哈希环上的节点数量,降低节点上下线时对哈希环的影响。
使用一致性哈希算法,当节点上线或者下线时,只需要将一小部分数据重新映射到新的节点上,从而使过程更加高效。此外,一致性哈希算法可以帮助平衡分布式系统中节点之间的负载,因为它可以确保数据在节点之间均匀分布,即使某些节点的容量比其他节点大。
具体操作时,我们可以以服务器节点 IP 或主机名后加入编号作为虚拟节点的 key 来实现,如下图:
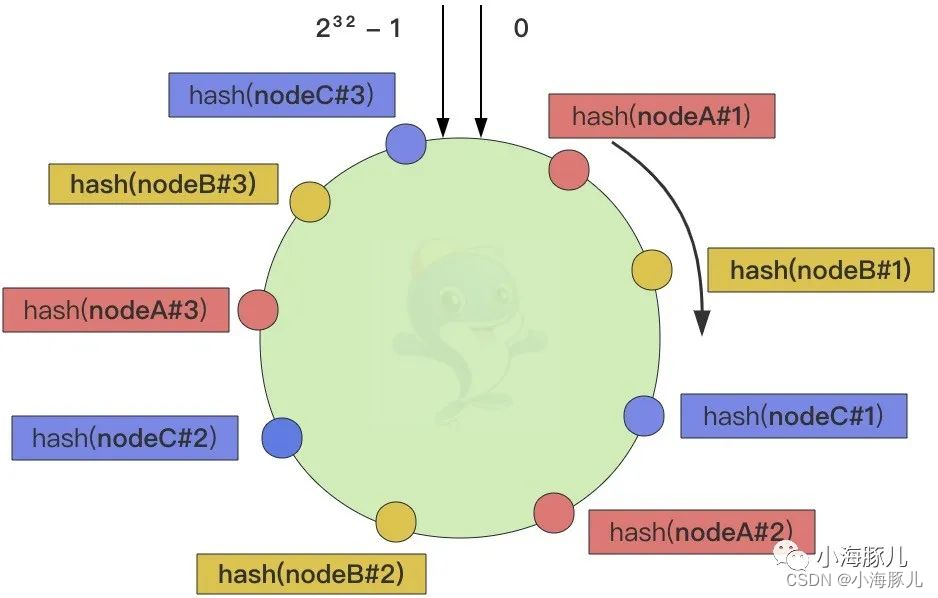
注:图片是为了美观,nodeA、nodeB、nodeC
均匀的间隔分布,实际上哈希函数存在随机性,它们的分布可能是穿插且无规律的,只是随着哈希槽位的增加,才会让节点变得相对均衡分布。
首先,我们将哈希值的可用范围(如 0 ~ 232 - 1)划分为固定数量的槽位(别忘了对哈希环取模:hash(key) % 232)。上图我们假设有 3 个节点,每个节点设置 3 个虚拟节点,由于每个节点的虚拟节点基本上均衡分布在了哈希环上,那么数据也就相对比较均匀地分布在所有的节点上了。
不论节点上线还是下线,在虚拟节点增加或者删除的情况下,也只会影响部分数据需要重新路由并迁移到顺时针方向的下一个节点上。而虚拟节点存在多个,这些数据不太可能会映射到同一个物理节点的虚拟节点上,所以它们的负载会相对均衡,也就从理论上解决了数据倾斜的问题。
应用框架和场景
一致性哈希算法被广泛应用于各种框架和场景中。
框架
Apache Pulsar:Pulsar 是一个云原生分布式消息流平台,它利用一致性哈希算法来实现 Key_Shared 模式的订阅机制。
Apache Cassandra:Cassandra 是一个分布式数据库管理系统,它利用一致性哈希算法来实现将数据分布在多个节点上。
Amazon DynamoDB:DynamoDB 是一个基于云的 NoSQL 数据库服务,它使用一致性哈希算法来实现在多个服务器上分发数据。
Riak:Riak 是一个分布式 NoSQL 数据库,它使用一致性哈希算法来实现跨节点划分数据。
Memcached:Memcached 是一个分布式缓存系统,它使用一致性哈希算法来确保数据在服务器集群中均匀分布。
Varnish:Varnish 是一个流行的 HTTP 加速器,它使用一致性哈希算法来实现在多个服务器上分发传入请求。
场景
内容交付网络(CDN):CDN 使用一致性哈希算法来实现在多个边缘服务器之间分发内容,这有助于减少延迟并提高内容交付网络的性能。
分布式数据库:分布式数据库使用一致性哈希算法来实现在集群中的多个节点之间对数据进行分区,确保数据的均衡分布,并在节点故障期间将数据移动降至最低。
负载平衡:负载均衡器使用一致性哈希算法来实现在多个后端服务器上均匀分布流量,这样可以确保在服务器出现故障或添加时,防止任何一台服务器过载。
P2P文件共享:P2P文件共享应用程序使用一致性哈希算法来定位网络中的文件,并将其分布在对等点之间,以实现高效的文件传输。
代理和缓存:代理和缓存使用一致性哈希算法来实现将请求映射到不同的后端服务器,确保数据的高效缓存和检索。
总体而言,一致性哈希算法已成为各种分布式系统中的重要组成部分,实现了高效和可扩展的数据存储、检索和交付。
接下来我们就以 Apahce Pulsar 中 Key_Shared 模式的演进历程来探究一致性哈希算法。
真实场景探究
在 Key_Shared 模式中,多个 Consumer 可以附加到同一个 Subscription 上。消息是在 Consumer 之间分发传递的,具有相同 key 的消息只会传递给同一个 Consumer。无论消息被重新传递多少次,它都会传递到同一个 Consumer 上。
这里我们引用官网的一张图,其中的 K 代表消息的唯一标识 key,V 就是消息的数据内容:
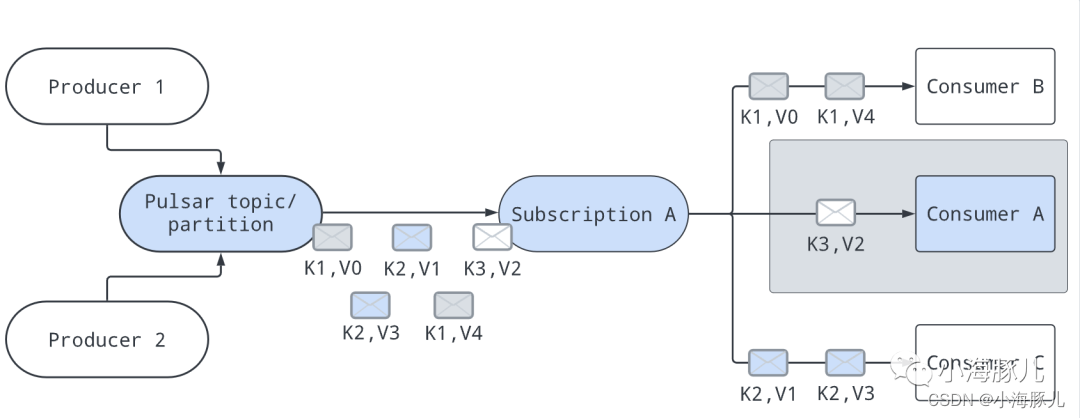
通过某种类型的映射算法,并根据给定消息的 key 来选择合适的 Consumer 进行消费。如上图中 Consumer B 处理 key = K1 的消息,Consumer A 处理 key = K3 的消息,Consumer C 处理 key = K2 的消息。
当有 Consumer 从 Consumer List 中退出时,算法会重新调整映射,使得映射到当前 Consumer 上的所有 key 被映射到其他未退出的 Consumer 上。比如 Consumer B 下线后,那么 key = K1 的消息会被映射到 Consumer A 和 Consumer C 上。
当有新的 Consumer 加入到 Consumer List 中时,算法也会重新调整映射,使得当前映射到现有 Consumer 上的一些 key 被映射到新添加的 Consumer 上。比如 Consumer D 上线后,那么当前的映射方案也可能会改变。
接下来我们就一起看下 Key_Shared 模式是如何实现这种映射算法的。在 Pulsar 2.6.0 之前,Key_Shared 模式是通过 Auto-split Hash Range 自动分裂来实现的,Pulsar 2.6.0 为 Key_Shared 模式新增了 Auto-split Consistent Hashing 的实现方式,需要在配置文件中启用该功能。
Auto-split Hash Range
该算法假设有一个介于 0 到 2^16(65536)之间的数字范围。每个 Consumer 都被映射到这个范围中的一个区域,所有 Consumer 覆盖了整个范围,彼此之间没有区域重叠。通过对消息的 key 计算哈希值并进行模运算映射到 [0, 65535] 区间,为给定的消息选择处理它的 Consumer。
例如:
假设我们有 4 个 Consumer(C1、C2、C3 和 C4),那么它们会平均分配整个范围区间:
0 16,384 32,768 49,152 65,536
|------- C3 ------|------- C2 ------|------- C1 ------|------- C4 ------|
给定一个消息 key = Order-3459134,它的哈希值将是 murmur32(“Order-3459134”) = 3112179635,并且它在该范围内的索引是 3112179635 mod 65536 = 6067。该索引在区间 [0, 16384) 内,因此该消息会被消费者 C3 消费。
当有新的 Consumer 上线时,会选择最大的区域,然后将其一分为二,新上线的 Consumer 将被映射到索引较小的区域上,原有 Consumer 继续映射到另一部分区域上。以下是 1 到 4 个 Consumer 的情况:
C1 connected:
|---------------------------------- C1 ---------------------------------|
C2 connected:
|--------------- C2 ----------------|---------------- C1 ---------------|
C3 connected:
|------- C3 ------|------- C2 ------|---------------- C1 ---------------|
C4 connected:
|------- C3 ------|------- C2 ------|------- C4 ------|------- C1 ------|
当 Consumer 下线时,其所在的区域将合并到其右侧的区域中。示例:
C4 下线:
|------- C3 ------|------- C2 ------|---------------- C1 ---------------|
C1 下线:
|------- C3 ------|-------------------------- C2 -----------------------|
该算法在上线/下线 Consumer 时,它只影响单个现有 Consumer,但是在一些 Consumer 下线后很容易产生数据倾斜的情况,无法将消息均匀地分配到所有的 Consumer 中。为了解决数据倾斜的问题,就需要用到一致性哈希算法了。
Auto-split Consistent Hashing
该算法抽象出一个从 0 到 MAX_INT(32位)数字范围的哈希环,和上面说的一致性哈希算法是一样的:
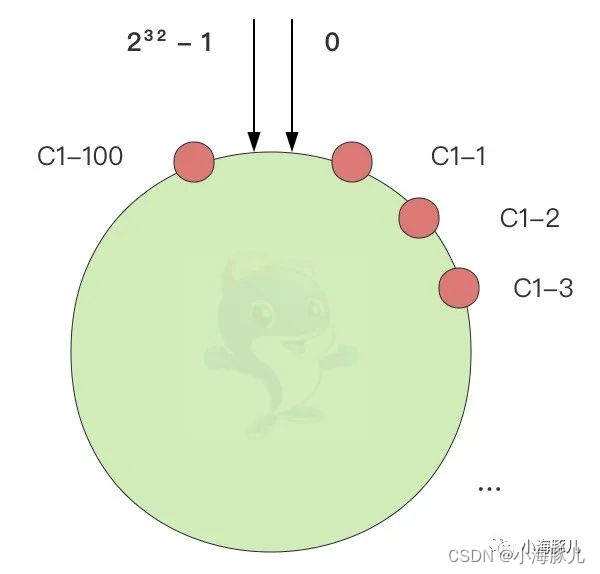
添加 Consumer 时,我们在哈希环上标记 100 个虚拟节点,并将它们与新添加的 Consumer 相关联。遍历 1~100 之间的每个数字,我们连接 Consumer 名字和当前数字,并对其运行哈希函数,以获得将被标记在哈希环上的点的位置。例如,如果 Consumer 名字是“orders-aggregator-pod-2345-consumer”,那么我们将在该哈希环上标记 100 个点:
murmur32("orders-aggregator-pod-2345-consumer1") = 1003084738
murmur32("orders-aggregator-pod-2345-consumer2") = 373317202
...
murmur32("orders-aggregator-pod-2345-consumer100") = 320276078
由于哈希函数具有均匀分布的特性,因此这些点将均匀分布在整个哈希环上。
通过将给定消息的 key 散列放在哈希环上,然后在哈希环上按顺时针方向找到最近的虚拟节点。该点上可能有多个 Consumer(哈希函数可能有冲突),因此,我们运行以下计算以在该点的 Consumer List 中获取一个位置,保证相同的 key 都会分配到同一个 Consumer 上:
hash % consumer_list_size = index
接下来我们看下 Pulsar 的源码,看一下 Auto-split Consistent Hashing 是如何实现一致性哈希算法的,我们从源码中提取主要逻辑,并对重要的部分添加详细注释,我们给出完整类路径,以便有人想要看完整代码:
org.apache.pulsar.broker.service.ConsistentHashingStickyKeyConsumerSelector
public class ConsistentHashingStickyKeyConsumerSelector {
// 一致性哈希环,由于存在哈希冲突,多个虚拟节点可能会映射到同一个哈希值,所以Map的Value值是一个List
private final NavigableMap<Integer, List<Consumer>> hashRing;
// 每个Consumer的虚拟节点数量,通过构造方法初始化
private final int numberOfPoints;
public ConsistentHashingStickyKeyConsumerSelector(int numberOfPoints) {
this.hashRing = new TreeMap<>();
this.numberOfPoints = numberOfPoints;
}
// 上线Consumer
public void addConsumer(Consumer consumer) throws ConsumerAssignException {
// 将每个Consumer的多个虚拟节点添加到哈希环上
for (int i = 0; i < numberOfPoints; i++) {
// 计算虚拟节点在哈希环上的index
String key = consumer.consumerName() + i;
// 框架内部的哈希函数
int hash = Murmur3_32Hash.getInstance().makeHash(key.getBytes());
// 将虚拟节点放到哈希环上
hashRing.putIfAbsent(hash, new ArrayList<>());
hashRing.get(hash).add(consumer);
}
}
// 下线Consumer
public void removeConsumer(Consumer consumer) {
// 删除哈希环上所属Consumer的所有虚拟节点
for (int i = 0; i < numberOfPoints; i++) {
String key = consumer.consumerName() + i;
// 框架内部的哈希函数
int hash = Murmur3_32Hash.getInstance().makeHash(key.getBytes());
if (hashRing.containsKey(hash)) {
hashRing.get(hash).remove(consumer);
}
}
}
// 选择Consumer
public Consumer select(int hash) {
if (hashRing.isEmpty()) {
return null;
}
List<Consumer> consumerList;
// 顺时针方向上的第一个Consumer
Map.Entry<Integer, List<Consumer>> ceilingEntry = hashRing.ceilingEntry(hash);
if (ceilingEntry != null) {
consumerList = ceilingEntry.getValue();
} else {
// 顺时针方向上找不到Consumer,回到哈希环上的第一个Consumer节点
consumerList = hashRing.firstEntry().getValue();
}
// 划重点:对Consumer List取模,保证消息相同的key都会分配到同一个Consumer上
return consumerList.get(hash % consumerList.size());
}
}
当有新的 Consumer 上线时,通过 addConsumer 方法将其虚拟节点映射到哈希环上,并接收对应 key 的消息;
当已有的 Consumer 下线时,通过 removeConsumer 方法将其虚拟节点从哈希环上摘除,并由其他在线的 Consumer 接收对应 key 的消息;
当有新的消息产生时,通过 select 方法选择固定的 Consumer 处理当前消息。
以上就是我们对一致性哈希算法的探究过程。看完这篇文章,你是不是想说一句”忒简单么,你说!“。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!