Point-BERT:一种基于Transformer架构的点云深度网络
目录
1. 前言
从PointNet [1] 开始,点云深度网络逐渐成为解决点云特征提取与语义分析的主要研究方向。尤其在OpenAI的GPT模型获得了突破性成果后,一系列的点云深度学习研究开始向相同的技术方向靠拢,即基于Transformer架构的深度网络模型。早期利用Transformer架构的点云深度网络 [2],虽然采用了注意力机制来设计实现,但是受限于三维数据的标定,并未发挥出其在语言和视觉领域的性能。在数据规模方面,点云的数据量也远远不能满足类似语言和图像那样的超大体量。
引入基于掩码预测的BERT架构 [3],实现对点云弱监督条件下的特征训练,是解决上述问题的一个重要的思路。类似自然语言,点云在其局部邻域的数据分布上,自有其规律或语义约束。然而,应用BERT架构到点云任务上存在一定的困难。BERT架构初始是用于自然语言处理,其处理单元为每一个词汇。对应点云,如果将每一个点视为词汇,那么计算量将变得非常庞大,使得训练任务不能执行。为了解决该问题,Point-BERT被提出 [4]。Point-BERT将点云的局部邻域视为一个点云词汇,对应一个Token。通过Point Tokenization步骤能够将一个点云进行Token转换,建立局部几何特征和点云词汇的对应。之后,利用Transformer架构实现掩点建模Masked Point Modeling,通过局部临近的Token于此被掩注的Token区域。这样便能实现一个弱监督条件下的点云特征抽取。Point-BERT的流程图如下图所示:
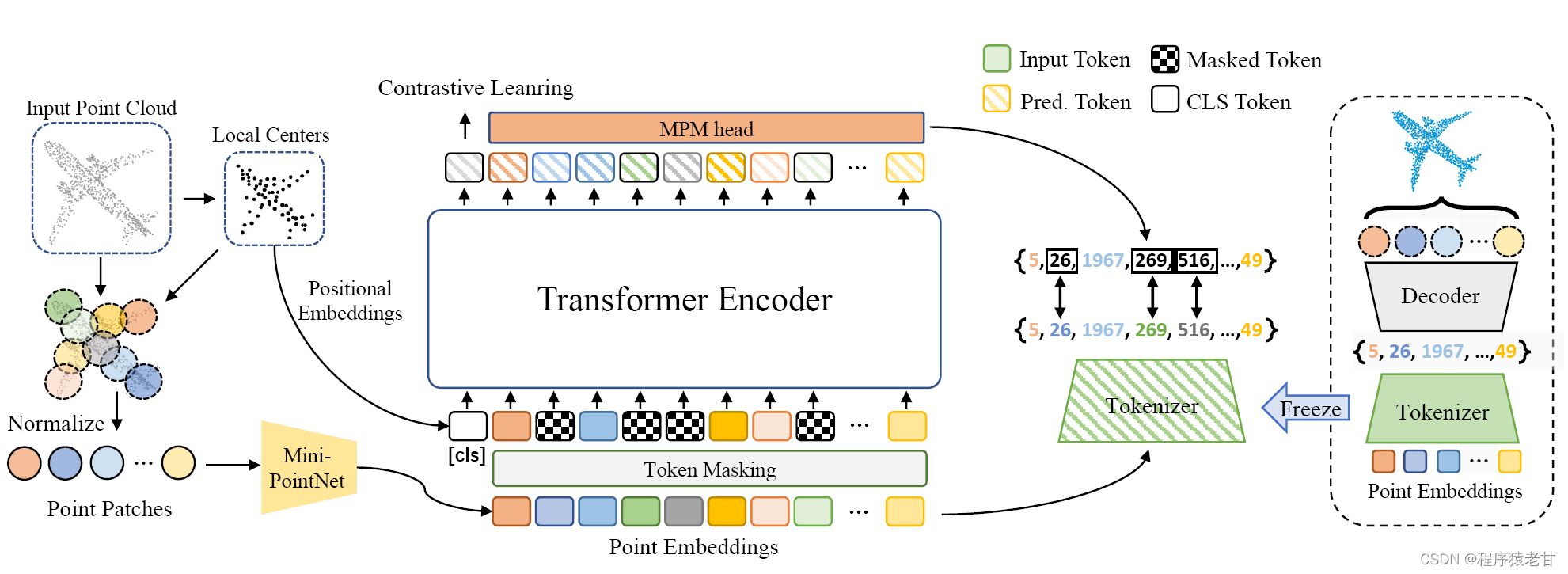
2. Point Tokenization
如前所述,Point-BERT的第一步是建立local patch到Token的表示。文章对这个过程的描述是非常清楚的。首先利用FPS算法将点云下采样出一组group中心,假设为g个中点。按照中心距离将点云划分成对应的g个组。每一个组被视为一个token对应的区域,就像文本的词汇和图片的patch。作者进一步使用mini-PointNet [1] 实现point embeddings,将点云的组变换成embedding后的特征f_i,i\in g。将f_i作为输入,转换成离散的token,这里的token对应为规模为N的词汇描述。DGCNN [5] 被用来作为Tokenizer的backbone。
对于点云重建,解码器被用来从token中恢复点相邻的组。由于词汇的规模是有限的,但是局部几何的分布又是十分复杂的,因此作者使用DGCNN来建立局部邻接点云组的关联关系,这在一定程度上能够弥补token对局部几何表达能力的缺陷。作者利用FoldingNet [6] 来最终恢复点云的局部几何。重建过程被赋予为一个点组到token的能量表达,其上界要逼近于原始点云和重建点云的编解码log-likelihood [7]:
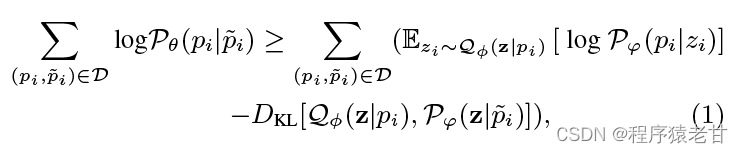
参考文献 [7], 作者使用一个Gumbel softmax relaxation来实现优化。
3. Backbone
Point-BERT基于Transformer架构的主干网络基本遵从Tokenization的设计步骤。首先使用FPS将一个点云分成g个组,每个组对应一个中心c。这些local组被mini-PointNet嵌入到特征f。mini-PoinrNet仅包含MLP层和maxpool操作。这里通过MLP,嵌入位置信息{pos_i}到c中。到此,我们组合了位置信息和特征f到一组输入嵌入{x_i}。{x_i}被作为Transformer的输入。基于 [3],我们附加一组tokenE[s]到输入序列,这样我们就得到了一个向量表示:
![]()
这里有L层,最后一层输出![]() 表示全局特征,是从输入点云组的编码表示获得的。? ? ?
表示全局特征,是从输入点云组的编码表示获得的。? ? ?
4. Masked Point Modeling
为了实现弱监督算法框架,作者扩展了掩码建模策略到Point-BERT架构中,即Masked point modeling (MPM)。具体分为三个部分:掩码序列生成、文本预测定义、点组混合以及目标优化。
掩码序列生成. Point-BERT的掩码序列生成不同于BERT和MAE,作者参考块尺度掩码策略 [8]. 作者使用邻域点组来定义一个连续的局部区域。通过mask在这个局部区域的所有点组,以生成掩码点云。掩码位置被表示为![]() ???????,r是掩码的比例。之后,作者替换所有的掩码嵌入点伴随一个相同可学习的预定义掩码学习嵌入E[M],同时保持位置不变。最终,损坏的输入嵌入被填充到Transformer编码器。
???????,r是掩码的比例。之后,作者替换所有的掩码嵌入点伴随一个相同可学习的预定义掩码学习嵌入E[M],同时保持位置不变。最终,损坏的输入嵌入被填充到Transformer编码器。
文本预测定义.?Point-BERT的目标是通过周边的几何来估计缺失的几何。预训练的dVAE编码每一个局部块到离散的token,以表示几何的模式,因此,Point-BERT能够直接应用这些token作为弱监督信息以训练Transformer。
点组混合.?受到CutMix的启发,作者提出了一个规范令牌预测作为文本预测的一个补充。由于每一个点云组的绝对位置被归一化,通过Point-BERT能够混合两个点组来创造新的虚拟样本,就像最优传输 [10] 一样。随着预训练的进行,我们将虚拟样本同时作为训练数据进行关联token的预测。在实际应用时,我们生成与样本规模相同的虚拟样本以增强Point-BERT的泛化学习能力。
优化目标.?MPM的目标是恢复在掩码区域的点token。优化目标能够被设定为最大正确点token的log-likelihood,由掩码输入嵌入提供:
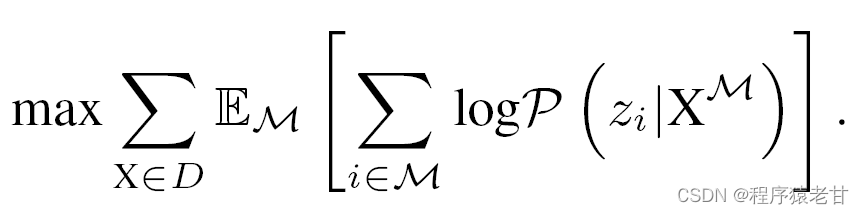
MPM任务估计模型预测掩码点云的几何结构,仅通过MPM任务训练transformer会导致对高层语义信息的解析缺陷。因此作者实用一个广泛使用的对比学习方法MoCo [11] 来改善transformer的语义学习能力。通过从虚拟样本中抽取符合现实样本的feature,以使模型更多的注意到语义信息。通过一个对比损失来实现:
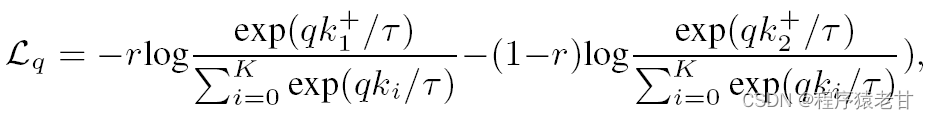
q表示混合样本的一个feature,通过momentum feature encoder获得,混合比率为r,K为存储尺度,τ表示温度。组合MPM与对比学习能够使Point-BERT同时捕获局部几何结构以及高层语义模式,这对于点云学习是至关重要的。
5. Experiments
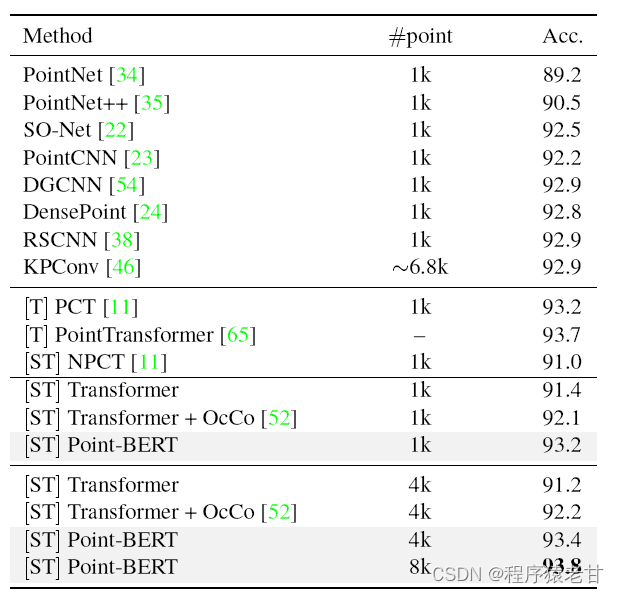
PointBert在ModelNet40的Acc准确率已经达到93.8。
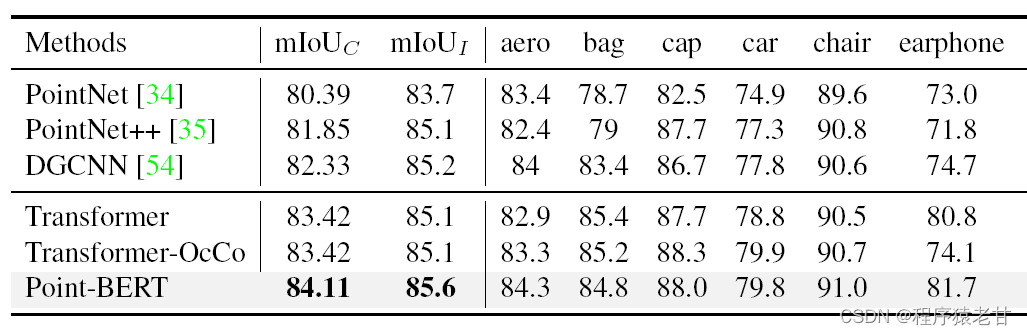
PointBert在ShapeNet上的分割准确率mIoU也到了84%的水平。
总结
整体来说,Point-Bert已经可以被认为是利用GPT相似技术,实现点云语义分析的一个比较成熟的处理框架了,包括MAE掩码预测,Transformer语义理解机制,以及利用混合编码扩展token的概念,基本与文本域图像处理的概念形成良好的对应。这里,如果将点组的token对应GPT的文本分析,理论来说,就可以打通LLM到三维点云的通道。综上,Point-Bert技术路线是一个非常值得深入挖掘的研究方向。
Reference
[1] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660.
[2] Zhao H, Jiang L, Jia J, et al. Point transformer[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 16259-16268.
[3] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[4] Yu X, Tang L, Rao Y, et al. Point-bert: Pre-training 3d point cloud transformers with masked point modeling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 19313-19322.
[5] Wang Y, Sun Y, Liu Z, et al. Dynamic graph cnn for learning on point clouds[J]. ACM Transactions on Graphics (tog), 2019, 38(5): 1-12.
[6] Yang Y, Feng C, Shen Y, et al. Foldingnet: Point cloud auto-encoder via deep grid deformation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 206-215.
[7] Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation[C]//International Conference on Machine Learning. PMLR, 2021: 8821-8831.
[8] Hangbo Bao, Li Dong, and FuruWei. Beit: Bert pre-training?of image transformers. arXiv preprint arXiv:2106.08254, 2021. 1, 3, 4, 5, 8
[9] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk?Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization?strategy to train strong classifiers with localizable?features. In ICCV, 2019. 5
[10] Jinlai Zhang, Lyujie Chen, Bo Ouyang, Binbin Liu, Jihong?Zhu, Yujing Chen, Yanmei Meng, and Danfeng Wu. Pointcutmix:?Regularization strategy for point cloud classification.?arXiv preprint arXiv:2101.01461, 2021. 5
[11] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross?Girshick. Momentum contrast for unsupervised visual representation?learning. In CVPR, 2020. 3, 5, 8
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!