生成唯一ID的常用方法与技术应用
2024-01-02 16:36:00

文章目录
🎈个人主页:程序员 小侯
🎐CSDN新晋作者
🎉欢迎 👍点赞?评论?收藏
?收录专栏:Java学习
?文章内容:唯一ID
🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!🤗
在软件开发中,生成唯一ID是一个常见的需求,特别是在分布式系统和数据库中。唯一ID的生成涉及到多方面的考虑,包括性能、分布式环境下的唯一性、趋势递增等方面。本文将探讨一些常用的生成唯一ID的方法和技术应用,并提供相应的代码示例。
1. UUID(Universally Unique Identifier)
UUID是一种由标准化的128位大小的值所生成的标识符,通常表示为32个十六进制数字,以连字符分隔。UUID的生成是基于当前时间、计算机的MAC地址和随机数等因素,因此具有足够的唯一性。但是,由于其长度较长,不适合作为数据库表的主键。
代码示例:
import java.util.UUID;
public class UUIDGenerator {
public static String generateUUID() {
return UUID.randomUUID().toString();
}
public static void main(String[] args) {
System.out.println(generateUUID());
}
}
2. 数据库自增主键
数据库自增主键是一种常见的生成唯一ID的方式,通常用于关系型数据库表的主键。数据库会自动为每条记录分配一个唯一的、递增的ID。
代码示例(使用MySQL的自增主键):
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255)
);
在使用时,插入数据时无需指定ID:
INSERT INTO users (name) VALUES ('John Doe');
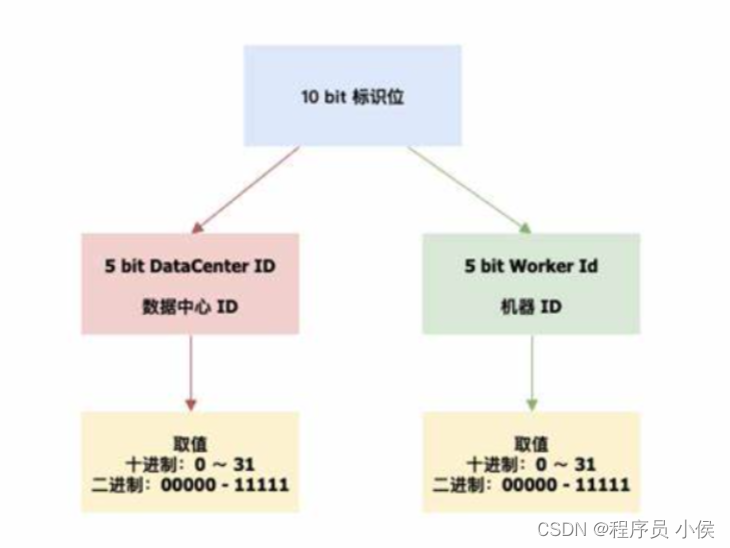
3. 雪花算法(Snowflake Algorithm)
雪花算法是Twitter开源的分布式ID生成算法,可以在分布式系统中生成全局唯一的ID。它的结构如下:
0 41位时间戳 | 10位节点ID | 12位序列号
代码示例:
public class SnowflakeIdGenerator {
private final long epoch = 1609459200000L; // 2021-01-01 00:00:00
private final long workerIdBits = 10L;
private final long sequenceBits = 12L;
private long workerId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId) {
if (workerId < 0 || workerId >= (1L << workerIdBits)) {
throw new IllegalArgumentException("Worker ID must be between 0 and " + ((1L << workerIdBits) - 1));
}
this.workerId = workerId;
}
public synchronized long generateId() {
long timestamp = System.currentTimeMillis();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate ID for " + (lastTimestamp - timestamp) + " milliseconds");
}
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & ((1L << sequenceBits) - 1);
if (sequence == 0) {
// Sequence overflow, wait for next millisecond
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - epoch) << (workerIdBits + sequenceBits))
| (workerId << sequenceBits)
| sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
public static void main(String[] args) {
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1);
// Generate 5 IDs
for (int i = 0; i < 5; i++) {
System.out.println(idGenerator.generateId());
}
}
}
4. 使用数据库分布式ID生成器
一些数据库提供了分布式ID生成器,例如MySQL的auto_increment和PostgreSQL的serial。这些数据库可以在分布式环境中生成唯一ID。
代码示例:
-- MySQL的auto_increment
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255)
);
-- PostgreSQL的serial
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255)
);
5. 结语
在选择生成唯一ID的方法时,需要根据具体的业务场景和需求进行选择。UUID适用于不依赖于数据库的独立系统,数据库自增主键适用于关系型数据库,雪花算法适用于分布式系统,而数据库分布式ID生成器适用于特定数据库环境。在实际应用中,也可以根据需要结合多种方法来满足业务需求。
后记 👉👉💕💕美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!! 🌹🌹🌹
文章来源:https://blog.csdn.net/weixin_65175398/article/details/135335868
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!