分支预测失败的处理
2023-12-13 11:33:15
? ? 由于现代的超标量处理器采用了很多预测的方法来执行指令,并不是流水线中所有的指令都可以退休(retire),例如当流水线中的某条分支指令发生了预测错误,或者某条指令发生了异常,那么在这条指令之后进入流水线的所有指令就不允许退休了;
- 此时需要将这些指令从流水线中抹掉,并且对处理器进行状态恢复,然后从指定的地址开始重新取指令来执行。
- 在流水线的提交(Commit)阶段需要重点关注的指令还有store指令,由于它只有在退休的时候才可以真正地改变处理器的状态(即写D-Cache),如果在这个过程中发生了DCache 缺失,store指令会阻碍流水线中所有位于它后面的指令继续退休,因此需要对store指令进行特殊的处理。
- 在流水线的提交阶段还会对其他的指令有一些特殊的限制,以减少对处理器中其他部件的影响等
- 上述的这些内容都是在提交阶段需要考虑的特殊情况
分支预测失败的处理?
当在流水线中发现一条分支指令预测失败时,在它之后进入到流水线的所有指令都变得不正确了,但是这些指令可能已经完成了取指令、重命名甚至是执行的过程,所以当发现分支预测失败时,这些错误的指令都应该从流水线中被抹掉,同时处理器的状态(包括RAT,ARF和PC值等内容)都应该被恢复到开始执行分支指令时的状态。
处理器状态恢复过程分为两个独立的任务
- front-end recovery
- rename stage之前的所有指令都抹掉;
- 分支预测其中的GHR/BHR等历史状态表,进行恢复;
- 使用正确的地址来取址;
- back-end recovery
- 将issue queue/store buffer/rob等内部组件中的错误指令都抹掉;
- 对RAT进行恢复;
- 被错误指令占据的物理寄存器和ROB空间也要被释放;
前端的状态恢复很快就可以完成,处理器此时可以从正确的地址开始取指令,这些被取出来的指令可以一直执行到流水线的重命名阶段之前,在这段时间内,后端的状态恢复也在继续。
![]()
当满足如上的时间关系时,流水线就不需要暂停;
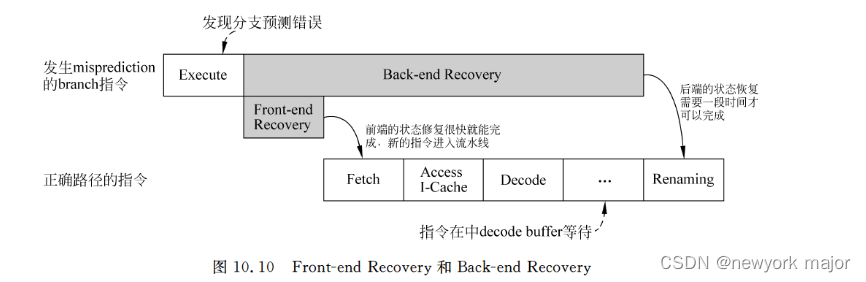
在backend阶段,最重要的恢复是RAT的恢复,此处只描述基于统一的PRF的RAT恢复;
- 此种方式,存在两个RAT:
- 一个在renaming stage使用,其状态是speculative的,Speculative RAT;
- 一个在commit stage使用,其状态永远是正确的,Architecture RAT(backup RAT);?
? ? ??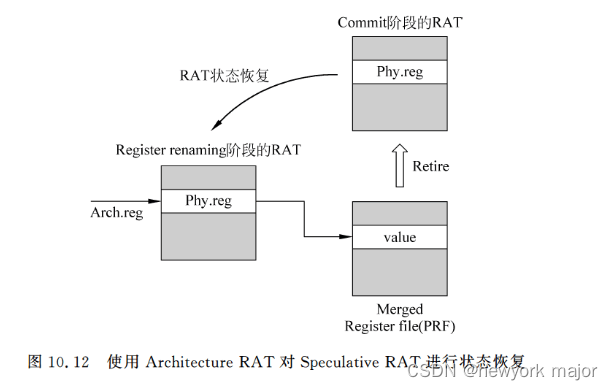
恢复流程如下:
- ?发现预测失败的分支指令;
- 停止取新的指令,让流水线drain out, 等待分支指令之前进入到流水线的所有指令,都顺利离开流水线,包括分支指令;
- 此时,还处在流水线中的所有指令,都是处于错误的路径上,可以将所有的指令都抹掉;
- 将architectural RAT复制到speculative RAT, 完成恢复动作;
- 从正确的地址开始取指令;
如果在等待分支指令之前的D-cache缺失的指令时,会因为等待时间过长而出现miss-prediction panalty过大的情况;
这种方式称之为recovery at retire, 需要等待预测失败的分支指令retire的时候,才可以进行处理器的状态恢复;
也可以不再retire阶段再恢复,比如在execution阶段进行恢复,可以使用checkpoint的方式,此处不描述;
?
文章来源:https://blog.csdn.net/zhangshangjie1/article/details/134964464
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!