【Hadoop】
2023-12-14 09:41:46
Hadoop是一个开源的分布式离线数据处理框架,包含了HDFS、MapReduce、Yarn三大部分。
一、HDFS
二、MapReduce
MapReduce程序在运行时有三类进程:
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程
- 在一个MR程序中MRAppMaster只有一个,MapTask和ReduceTask可以有一个也可以有多个
- 在一个MR程序中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段
- 在整个MR程序中,数据都是以kv键值对的形式流转的
MapReduce整体执行流程图:
左边是maptask,右边是reducetask,红框里是shuffle过程(shuffle包含了map和reduce)
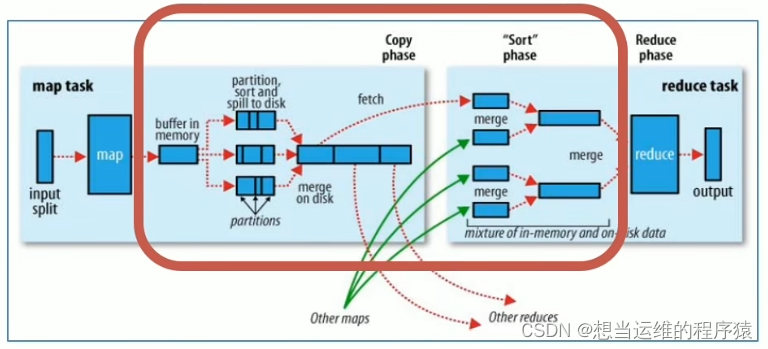
2.1 map阶段执行过程
- 第一阶段: 把所要处理的文件进行逻辑切片(默认是每128M一个切片),每一个切片由一个MapTask处理。
- 第二阶段: 按行读取切片中的数据,返回<key,value>对,key对应行数,value是本行的文本内容
- 第三阶段: 调用Mapper类中的map方法处理数据,每读取解析出来一个<key,value>,调用一次map方法
- 第四阶段(默认不分区): 对map输出的<key,value>对进行分区partition。默认不分区,因为只有一个reducetask,分区的数量就是reducetask运行的数量。
- 第五阶段: Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key按照字典序(a~z)进行排序sort
- 第六阶段: 对所有溢出文件进行最终的merge合并,形成一个文件(即一个maptask只输出一个文件)
2.2 reduce阶段执行过程
- 第一阶段: ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据
- 第二阶段: 把拉取来的数据,全部进行合并merge,即把分散的数据合并成一个大的数据,再对合并后的数据进行排序
- 第三阶段: 对排序后的<key,value>调用reduce方法,key相同<key,value>调用一次reduce方法。最后把输出的键值对写入到HDFS中
2.3 shuffle机制
- shuffle指的是将map端的无规则输出变成具有一定规则的数据,便于reduce端接收处理。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称为Shuffle
- Shuffle过程是横跨map和reduce两个阶段的,分别称为Map端的Shuffle和Reduce端的Shuffle
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复,是导致mapreduce计算慢的原因
三、Yarn
文章来源:https://blog.csdn.net/qq_33218097/article/details/134985257
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!