全新「机械手」算法:辅助花式抓杯子,GTX 1650实现150fps推断
新方法结合扩散模型和强化学习,将抓取问题分解为「如何抓」以及「何时抓」,平价显卡即可实现实时交互。
手是人类与世界交互的重要部分,手的缺失(如上肢残障)会大大影响人类的正常生活。

北京大学董豪团队通过将扩散模型和强化学习结合,使机械手能根据人手腕部的移动轨迹,自适应的抓取物体的不同部位,满足人类多样化的抓取需求。
有了这个机械手,只要动动手腕,机械手就能按照人类想要的方式抓起物体,比如抓取杯身和杯壁。

由于人类行为的复杂与多变性和真实世界物体的多样性,仅仅根据人手腕部的移动轨迹来不断预测人类想法是一件非常困难的事情。
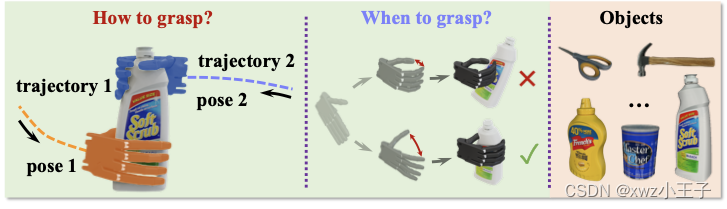
新方法真正实现了灵巧的抓取,能在真实世界中对于不同的物体,不同的抓取姿态,不同的抓取轨迹进行泛化。

01
机械手如何明白人类的想法?
我们提出将人类的想法分解成两个部分:
-
如何抓:考虑到人类和物体当前的相对姿势,机械手应该如何抓取物体?
-
何时抓:机械手应该根据用户历史运动轨在何时、以什么速度执行抓取动作?
如何抓?
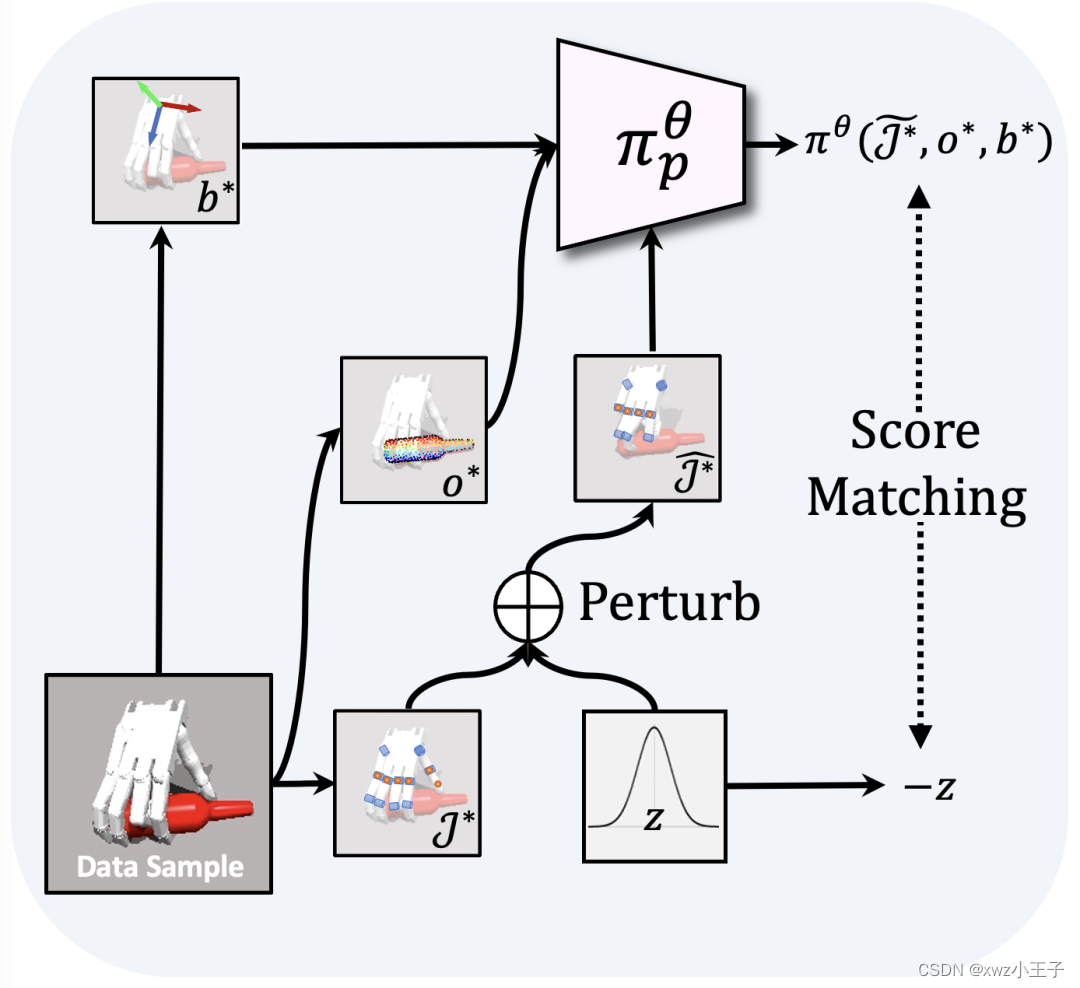
首先,如上图所示,新方法将学习人类想要「如何抓取物体」,定义为从一个包含各种抓取姿态的数据集中,学习抓取梯度场 Grasping Gradient Field(GraspGF)。
基于当前人手腕部和物体的相对关系,GraspGF 会输出一个梯度,这个梯度代表最快提高「抓取可能性」的方向。这个梯度可以转化为对每个手指关节的原始控制,使手指能够通过不断迭代达到适当的抓取姿态。
这样的梯度场可以随着人手腕部和物体的关系的变化,而不断的输出新的梯度指示当前人类的抓取意图,即意向抓取的物体区域及抓取姿态。
GraspGF 随着手腕的旋转,不断调整抓取姿态

何时抓?

GraspGF的动作会导致提前合拢
然而,只知道「如何抓」并不够完备,如果不知道要「何时抓」(如上图所示),虽然最终的抓取姿态是合理的,但是在达到抓取姿态的过程中会和物体发生碰撞。
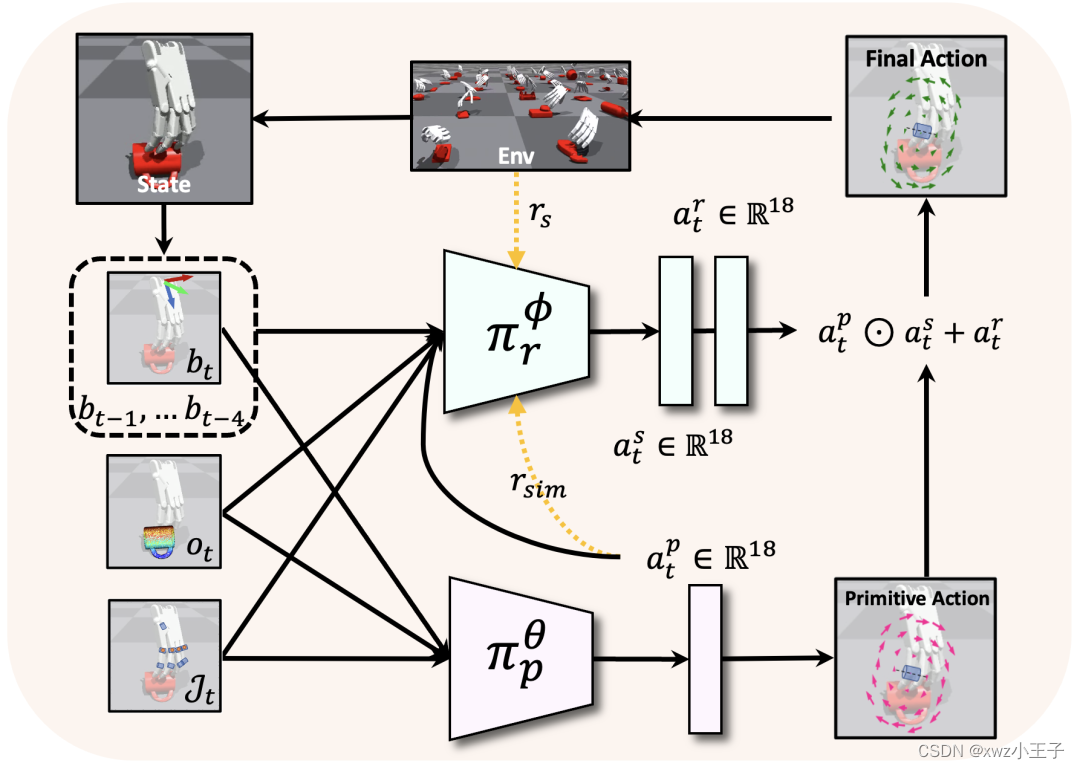
如上所示,为了解决「何时抓取」的问题,新方法还训练了一个基于强化学习的残差策略,它首先会输出一个「缩放动作」,根据手腕轨迹的历史,决定手指关节应该以多快的速度沿着原始动作的方向移动。
此外,因为原始策略是基于最终抓取姿态数据集离线训练得到的,原始策略并不了解环境的物理约束 ,残差策略还会输出一个「残差动作」来进一步校正原始动作。通过结合残差策略,模型能够通过残差策略学习到的「何时抓」更好地实现原始策略学习到的「如何抓」。

简单的奖励函数
该方法在奖励函数的设置上不需要过多的 human design,因为原始动作已经提供了一个比较好的「如何抓」的引导,在训练强化学习模型时,除了给定成功抓取和抓取后的高度变化奖励,仅仅只需要一个奖励函数去鼓励机械手跟随原始动作即可。
该方法的优势
该方法仅需要成功抓取的抓取姿态数据集用于训练,与需要专家演示的方法相比,不需要大量的人工标注或者工程工作。
GraspGF 借助了扩散模型强大的条件生成建模能力,这使它能够根据新颖的用户意图输出有效的原始动作。
残差学习的设计改善了强化学习探索效率低下的问题,提升了强化学习模型在未见过物体和轨迹上的泛化能力。
02
结 果
最终在4900多个物体,200条不同的人类移动轨迹上,新方法都优于基准。
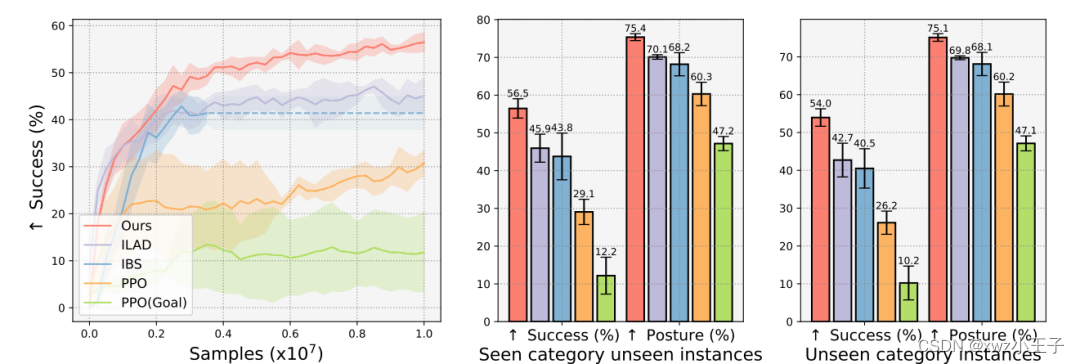
该方法的最终的抓取姿态相比于基线更符合人类的抓取意图。

此外,该方法在抓取过程中对物体造成的扰动要小于其他基准。
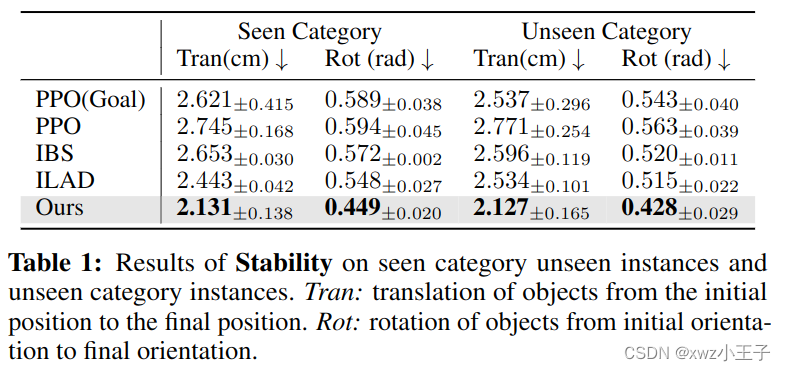
经过测试,该模型在 GTX1650 的显卡上,能达到 150fps 的推断速度,能做到与人类的实时交互,也许未来能真正用于辅助手部缺失的人更好地进行日常生活。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!