声音.wav文件的读取与保存
2023-12-21 17:50:47
?声音.wav文件的读取与保存-示例代码:
import librosa
import librosa.display
import numpy as np
from scipy.io.wavfile import write
def split_wav():
# 读取音频文件
audio_data, sample_rate = librosa.load(input_file, sr=None) # sr不指定为None,就会读取为22050Hz
print("文件的采样率为: {}Hz".format(sample_rate))
# 计算音频时长
total_duration = len(audio_data) / sample_rate
print("文件的总时长为: {}S".format(total_duration))
# 分割点位置
start_time = 90 # 录音开始的时长min
end_time = 120
start_sample = int(start_time * 60 * sample_rate)
end_sample = int(end_time * 60 * sample_rate)
# 分割音频
audio_part = audio_data[start_sample:end_sample]
# 保存分割后的音频文件
# 为了符合 WAV 文件的格式,我们需要将浮点数表示的归一化音频数据转换为整数。乘以 32767 是为了将范围从 [-1, 1] 映射到 [-32767, 32767],并且将浮点数转换为整数。
write(output_file1, sample_rate, np.int16(audio_part * 32767.0))
write(output_file2, sample_rate, audio_part)
return audio_part
# 文件地址
input_file = r"C:\Users\85007\Desktop\test_wave\yaofeijie_20231101210759.wav"
output_file1 = r"C:\Users\85007\Desktop\test_wave\yaofeijie_20231101210759_part1.wav"
output_file2 = r"C:\Users\85007\Desktop\test_wave\yaofeijie_20231101210759_part2.wav"
audio_part = split_wav()
print("切割音频文件结束")
# 对比实验
print("读取原始文件的数值为: {}".format(audio_part[:5]))
temp_data1, sample_rate = librosa.load(output_file1, sr=None)
print("乘了32767文件的数值为: {}".format(temp_data1[:5]))
temp_data2, sample_rate = librosa.load(output_file2, sr=None)
print("未乘32767文件的数值为: {}".format(temp_data2[:5]))ChatGPT声称:为了符合 WAV 文件的格式,我们需要将浮点数表示的归一化音频数据转换为整数。乘以 32767 是为了将范围从 [-1, 1] 映射到 [-32767, 32767],并且将浮点数转换为整数。
后续实验证明,GPT是错误的!
上述代码的运行结果
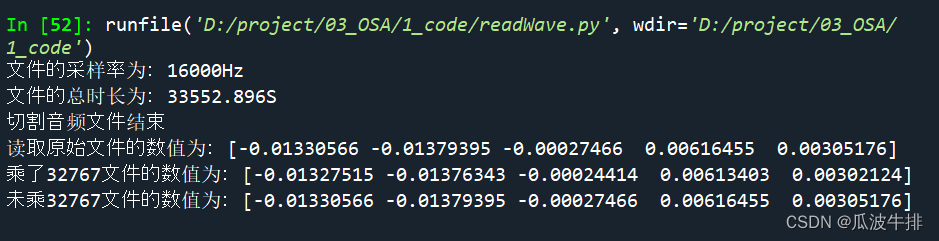 ?测试结论:
?测试结论:
(1)通过librosa.load读取wav文件,会自动把数值缩放到【-1,1】。
(2)不要听ChatGPT胡说八道,乘了32767后反而把新保存的结果和原始结果不一样。
文章来源:https://blog.csdn.net/Amigo_1997/article/details/135130025
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!