2023.12.30 Pandas操作
目录
?2.2 使用列表,自定义索引,字典,元组方式创建series对象
1. pandas基础
????????1.1 pandas的基本介绍
Python在数据处理上独步天下:代码灵活、开发快速;尤其是Python的Pandas包,无论是在数据分析领域、还是大数据开发场景中都具有显著的优势:
-
Pandas是Python的一个第三方包,也是商业和工程领域最流行的结构化数据工具集,用于数据清洗、处理以及分析
-
Pandas和Spark中很多功能都类似,甚至使用方法都是相同的;当我们学会Pandas之后,再学习Spark就更加简单快速
-
Pandas在整个数据开发的流程中的应用场景
-
在大数据场景下,数据在流转的过程中,Python Pandas丰富的API能够更加灵活、快速的对数据进行清洗和处理
-
-
Pandas在数据处理上具有独特的优势:
-
底层是基于Numpy构建的,所以运行速度特别的快
-
有专门的处理缺失数据的API
-
强大而灵活的分组、聚合、转换功能
-
适用场景:
-
数据量大到excel严重卡顿,且又都是单机数据的时候,我们使用pandas
-
pandas用于处理单机数据(小数据集(相对于大数据来说))
-
-
在大数据ETL数据仓库中,对数据进行清洗及处理的环节使用pandas
?1.2 pandas基础使用
import pandas as pd
if __name__ == '__main__':
print('演示pandas的相关使用:入门案例')
# 1 读取数据
df = pd.read_csv(filepath_or_buffer='./1960-2019全球GDP数据.csv', encoding='GBK')
# 2 获取数据
print(df.head(10))
演示pandas的相关使用:入门案例
? ?year country ? ? ? ? ? GDP
0 ?1960 ? ? ?美国 ?543300000000
1 ?1960 ? ? ?英国 ? 73233967692
2 ?1960 ? ? ?法国 ? 62225478000
3 ?1960 ? ? ?中国 ? 59716467625
4 ?1960 ? ? ?日本 ? 44307342950
5 ?1960 ? ? 加拿大 ? 40461721692
6 ?1960 ? ? 意大利 ? 40385288344
7 ?1960 ? ? ?印度 ? 37029883875
8 ?1960 ? ?澳大利亚 ? 18577668271
9 ?1960 ? ? ?瑞典 ? 15822585033
?2. pandas的数据结构
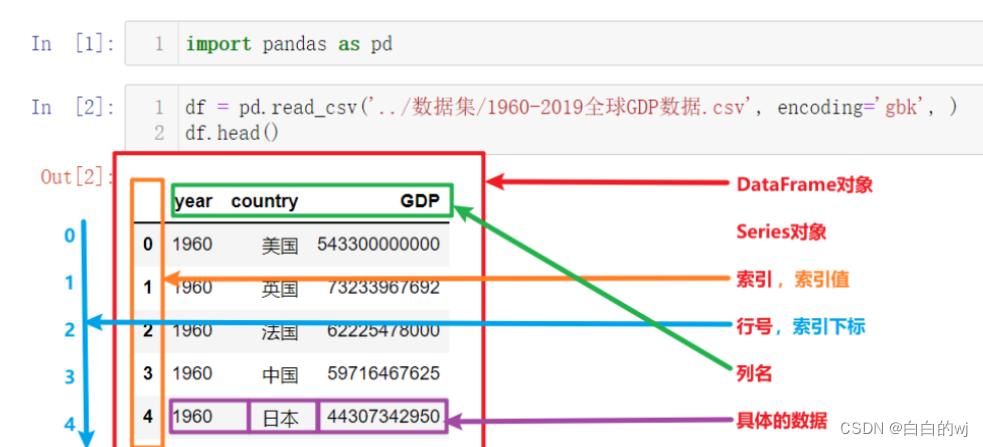
上图为上一节中读取并展示出来的数据,以此为例我们来讲解Pandas的核心概念,以及这些概念的层级关系:
- DataFrame
- Series
- 索引列
- 索引名、索引值
- 索引下标、行号
- 数据列
- 列名
- 列值,具体的数据
其中最核心的就是Pandas中的两个数据结构:DataFrame和Series
2.1 series对象
Series也是Pandas中的最基本的数据结构对象,下文中简称s对象;是DataFrame的列对象,series本身也具有索引。
Series是一种类似于一维数组的对象,由下面两个部分组成:
-
values:一组数据(numpy.ndarray类型)
-
index:相关的数据索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
?2.2 使用列表,自定义索引,字典,元组方式创建series对象
import pandas as pd
# 使用默认自增索引
s2 = pd.Series([1, 2, 3])
print(s2)
'''
0 1
1 2
2 3
dtype:int64
'''
# 自定义索引
s3 = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
print(s3)
'''
A 1
B 2
C 3
dtype: int64
'''
# 使用元组创建对象
tst = (1, 2, 3, 4, 5, 6)
print(pd.Series(tst))
'''
0 1
1 2
2 3
3 4
4 5
5 6
dtype: int64
'''
# 使用字典,key会成为索引,值会成为Series对象
dst = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6}
print(pd.Series(dst))
'''
0 1
1 2
2 3
3 4
4 5
5 6
dtype: int64
'''2.3??Series对象常用API
import pandas as pd
s4 = pd.Series([i for i in range(6)],index=[i for i in 'ABCDEF'])
print(s4)
'''
A 0
B 1
C 2
D 3
E 4
F 5
dtype: int64
'''?
import pandas as pd
s4 = pd.Series([i for i in range(6)], index=[i for i in 'ABCDEF'])
print(s4)
'''
A 0
B 1
C 2
D 3
E 4
F 5
dtype: int64
'''
# s对象有多少个值,int
print(len(s4)) # 6
print(s4.size) # 6
# s对象有多少个值,单一元素构成的元组 (6,)
print(s4.shape)
# 查看s对象中数据的类型,int64
print(s4.dtypes)
# s对象转换为list列表 [0, 1, 2, 3, 4, 5]
print(s4.to_list())
# s对象的值 array([0, 1, 2, 3, 4, 5], dtype=int64)
print(s4.values)
# s对象的值转换为列表
print(s4.values.tolist())
# s对象可以遍历,返回每一个值
for i in s4:
print(i)
# 下标获取具体值, 1
print(s4[1])
# 返回前2个值,默认返回前5个,
# A 0
# B 1
print(s4.head(2))
# 返回最后1个值,默认返回后5个
# F 5
print(s4.tail(1))
# 获取s对象的索引 Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
print(s4.index)
# s对象的索引转换为列表
s4.index.to_list()
# s对象中数据的基础统计信息
print(s4.describe())
# 返回结果及说明如下
# count 6.000000 # s对象一共有多少个值
# mean 2.500000 # s对象所有值的算术平均值
# std 1.870829 # s对象所有值的标准偏差
# min 0.000000 # s对象所有值的最小值
# 25% 1.250000 # 四分位 1/4位点值
# 50% 2.500000 # 四分位 1/2位点值
# 75% 3.750000 # 四分位 3/4位点值
# max 5.000000 # s对象所有值的最大值
# dtype: float64
# 标准偏差是一种度量数据分布的分散程度之标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少,反之亦然。
# 四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。
# seriest对象转换为df对象
s4.to_frame()
s4.reset_index()
2.4 Series 对象的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
两个Series之间计算,索引值相同的元素之间会进行计算;索引不同的元素最终计算的结果会填充成缺失值,用NaN表示
-
Series和数值型变量计算
print(s4 * 5)
# # 返回结果如下
# A 0
# B 5
# C 10
# D 15
# E 20
# F 25
# dtype: int64# 构造与s4索引相同的s对象
s5 = pd.Series([10]*6, index=[i for i in 'ABCDEF'])
# 两个索引相同的s对象进行运算
print(s4 + s5)
# 返回结果如下
'''
这个是s4
A 0
B 1
C 2
D 3
E 4
F 5
这个是s5
A 10
B 10
C 10
D 10
E 10
G 10
这个是s4+s5
A 10
B 11
C 12
D 13
E 14
F 15
dtype: int64
'''本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!