在云计算环境中,如何利用 AI 改进云计算系统和数据库系统性能
前言
2023年我想大家讨论最多,热度最大的技术领域就是 AIGC 了,AI绘画的兴起,ChatGPT的火爆,在微软背后推手的 OpenAI 大战 Google几回合后,国内各种的大语言模型产品也随之各家百花齐放,什么文心一言、通义千问、科大讯飞的星火以及华为的盘古等等,一下子国内也涌现出几十种人工智能的大语言模型产品。ChatGPT 爆火之后,你是否有冷静的思考过 AIGC 的兴起对我们有哪些机遇与挑战?我们如何将AI 应用到我们现有的工作学习中?本文将结合四川大学唐明洁教授的分享来探讨如何利用人工智能技术来提高云计算和数据库系统的性能、可靠性和可扩展性。主要分享内容包括:AI和分布式系统;利用AI提高大规模AI和分布式计算任务的效率;利用AI提高数据库系统性能;大模型训练在云计算环境下的技术挑战;结论和方向。
一、关于唐明洁教授
因为本文是结合唐明洁教授的直播分享总结出来的博文,这里根据四川大学以及互联网公开资料来介绍一下唐明洁教授。
唐明洁教授于2007年四川大学本科毕业,2010年中科院大学硕士毕业,2016年美国普度大学计算机系博士毕业,博士论文指导老师 Walid Aref (IEEE Fellow), Elisa Bertino (ACM/IEEE Fellow), Sonia Fahmy(IEEE Fellow) , Sunil Prabhakar。从2018到2022年担任蚂蚁集团美国硅谷研究院AI工程科学家和研发主管,负责全集团AI及大数据云原生系统工作;2016年到2018年担任大数据公司Cloudera数据科学家,负责数据库OLAP方向,担任研发Apache Spark。还曾就职于Microsoft美国及IBM美国研究院。
是多个开源数据库和AI项目发起人及核心贡献者,包括AI训练业界标准Kubeflow,Couler,ElasticDL,SQLFlow等(Github stars>7000),Spark早期贡献者。发表ACM/IEEE汇刊论文34篇,CCF-A类论文11篇。包括数据库顶级会议VLDB,ICDE,IEEE TKDE, CIKM等。

二、AI for System
系统中会遇到各种问题,如何利用AI 技术进行解决系统中的这些问题将是该部分内容的讨论重点,该部分内主要会针对在分布式任务与数据库系统中如何利用AI 进行优化系统的性能。
2.1 面向分布式作业的人工智能
如果你需要更多详细资料可以参照唐教授的论文:An general framework to optimize the job in cloud (ICDE23)。
2.1.1 现阶段企业云计算系统环境所遇到的普遍痛点
在当前较大规模的云计算集群环境中存在两个主要问题。首先,CPU、内存甚至GPU的利用率相对较低。其次,创建的任务存在较长的等待时间(pending time)。这些问题在实际的客户环境中普遍存在,例如下图所示的蚂蚁金服案例。

从上述的蚂蚁金服的案例中可以发现面临的主要几个问题
-
集群资源利用率问题
在资源利用率中可以发现,很多资源使用率都是比较低的,其中CPU的利用率在20%以下,而内存利用率在40%以下。 -
运行效率问题
在一些工作负载中,运行过程中可能会发生异常错误,这样在整理作业流程上,会出现内存溢出,甚至处理延迟增加等问题。在2020年的一个数据中表明,在65000个流作业中,1500个大约占比2.3%的作业的最大处理延迟超过30分钟。 -
管理维护系统困难且成本较高
在管理job的时候,在不同的业务线,会有不同的人会提交不同的job,这样在一个或者多个集群中,其运维成本会变得非常高。
2.1.2 云计算系统环境所遇到的普遍痛点的解决方案
在上述中我们讲解了在云计算系统环境所遇到的普遍痛点问题,针对这些问题我们应该如何解决呢?
(一)Google Autopilot Eurosys 2021方案(Pod级别)
Autopilot方案是在 Google Autopilot Eurosys 2021 大会上所提出的,该方案是以 Pod 级别为单位对资源进行弹性伸缩。
在给出的案例中可以看下图所示,一般我们用机器里面存放容器是有限度的。
因此,精确的限制对效率和可靠性至关重要。在下图中,第一部分资源的使用率不足,造成机器内存等资源浪费,而第三部分,请求的资源超过所存放容器的最大限制,这样也是不合理的。
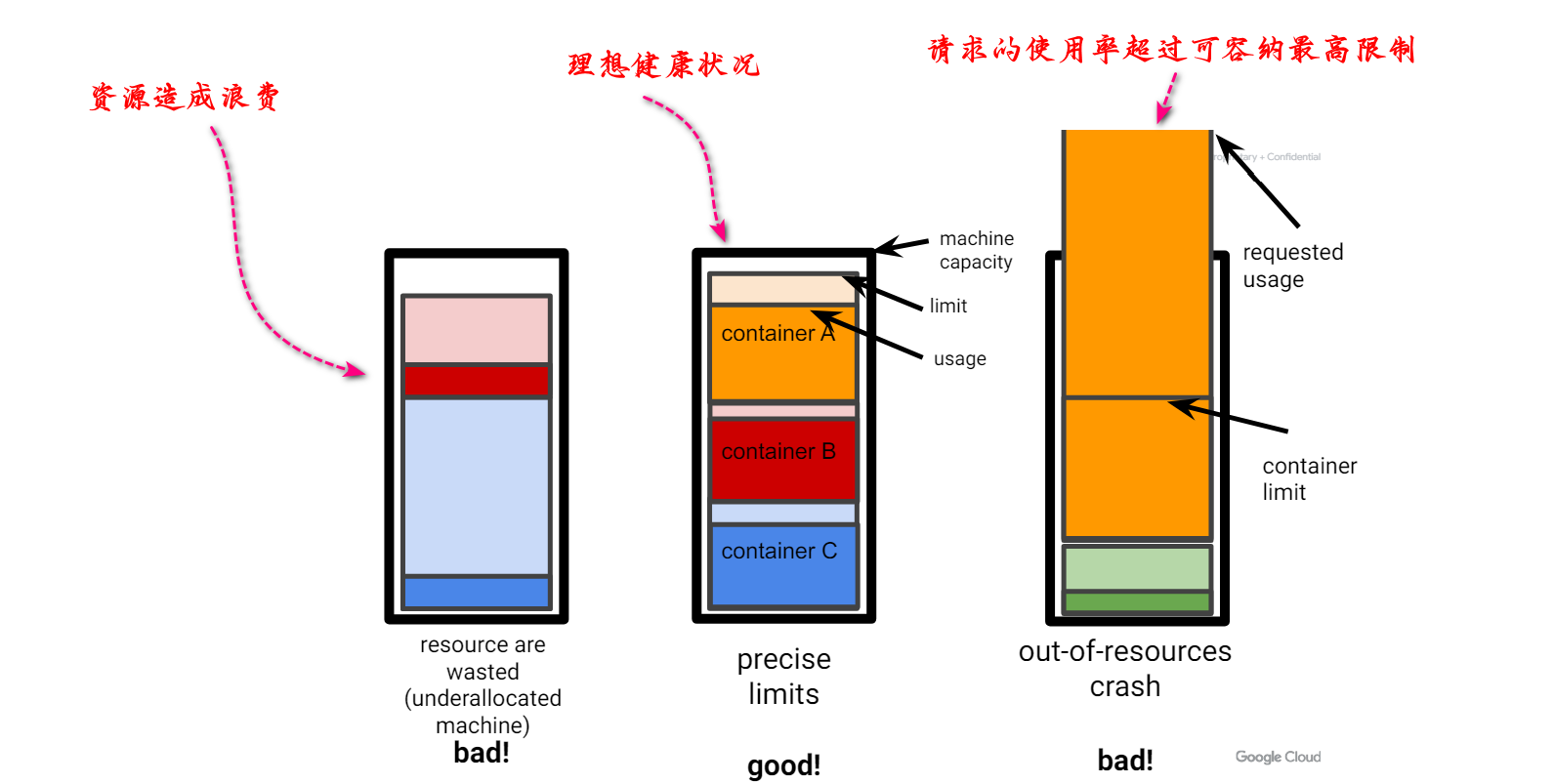
Autopilot 的工作原理大致可以理解为,有一些算法可以侦测到Pod的利用率,之后通过内部的 Borg 来进行横向或者纵向的进行弹性伸缩。Autopilot 现在已经是 Google 的落地组件产品,当你在使用 google 云的时候,可以选择使用 Autopilot 进行资源优化。
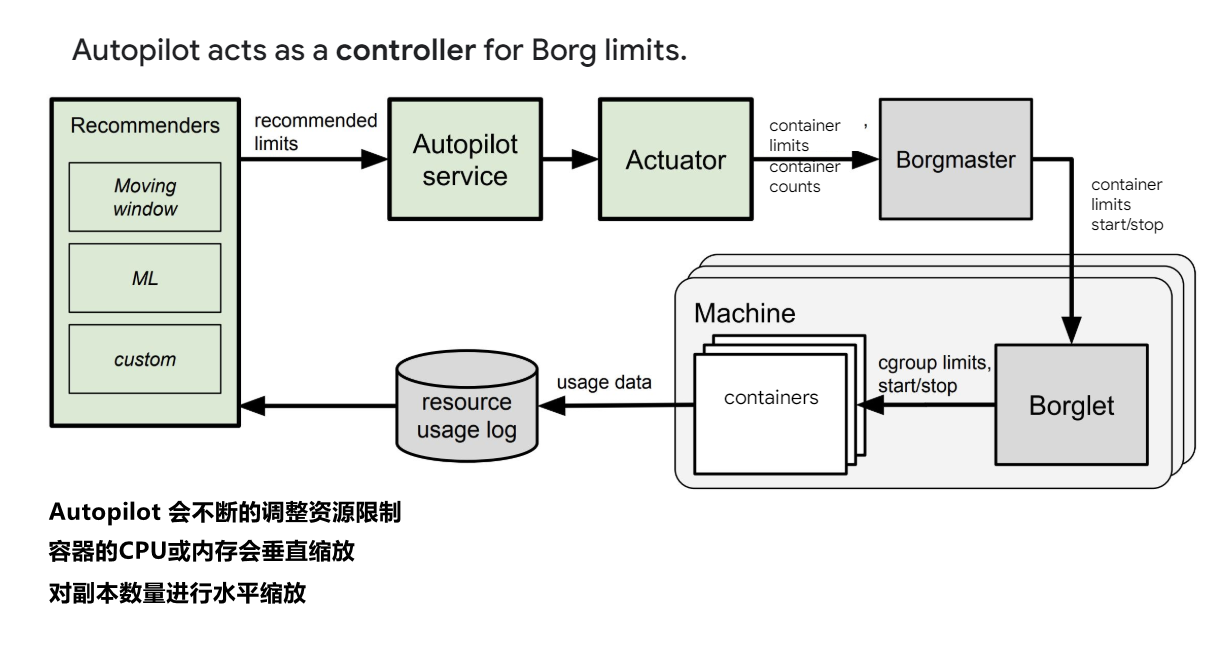
上述我们提到了Autopilot 是以 Pod 级别为单位的弹性伸缩,那么有人可能会有疑问,如果我的系统不是以 Pod 为单位的伸缩,这种方案是否可行,或者是否有问题呢。下面我们来了解一下阿里的方案
(二)ibaba Rose ICDCS 2019 方案(Job 级别)
该解决方案是来自于阿里的团队,发表在 ibaba Rose ICDCS 2019。
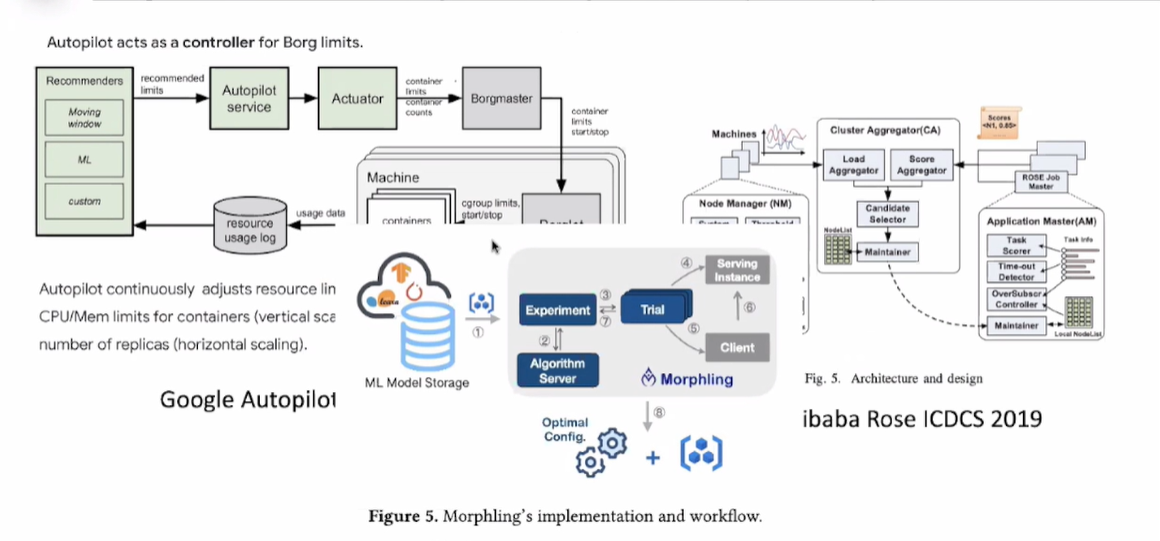
博主查阅了论文资料后得出该论文主要介绍了一种名为Rose的调度算法,用于优化数据中心作业的执行性能。该算法旨在解决数据中心中作业调度的挑战,其中不同的作业具有不同的性能目标和资源需求。通过动态地分配资源和调整作业的执行顺序,Rose 算法可以最大程度地提高作业的性能,包括减少作业完成时间、提高资源利用率和保证服务质量。
该方案的核心思想是通过将作业分为不同的组,并为每个组分配资源配额,以便在资源利用率和性能之间取得平衡。Rose 算法使用一种基于启发式的调度策略,根据作业的属性和资源使用情况来选择最佳的作业顺序和资源分配方案。通过实验评估,该方案在提高数据中心作业性能方面取得了显著的改进。
2.1.3 优化框架COUGAR的架构
在一个大规模的集群中,我们会面临各种不同类型的任务,如深度学习任务、大数据任务以及模型服务任务等。我们有一个共同的目标,即通过一个通用框架将这些任务与优化策略相结合。第二个目标是,在对一个作业进行优化时,不仅要考虑该作业本身所需的资源,还要考虑将某些作业的信息与集群的信息相结合,以实现整体任务的优化调度。
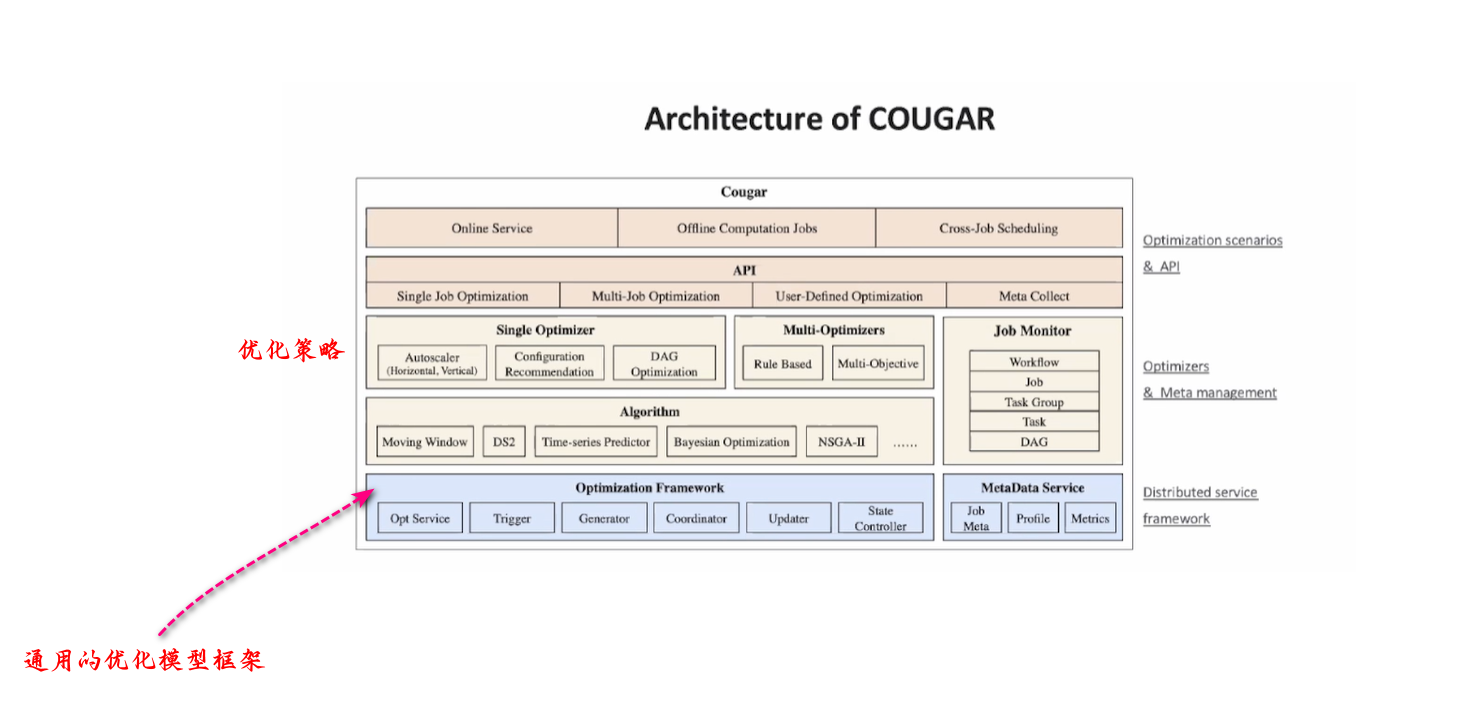
在架构图中可以看到,我们有一个通用的优化框架去接入不同的任务,在Framework 中可以接入不同的任务,同时不会破话这些任务的执行,并且在框架中内置一些优化算法,适配不同的场景。
在过去做优化的时候主要是“单目标优化(Single Optimizer)”以实现最大吞吐、实现最大利用率或者最小的IO等,现在我们更希望定义不同的优化组合目标,我们会希望这个优化既可以资源用的少又可以性能高且IO少,这也被称为“多目标优化(Multi-Optimizers)”
2.1.4 优化案例举例
这里结合上述的优化框架 COUGAR 的架构,列举两个案例,可以供大家结合实际工作进行参考。
(一) 流处理作业(Flink)的优化
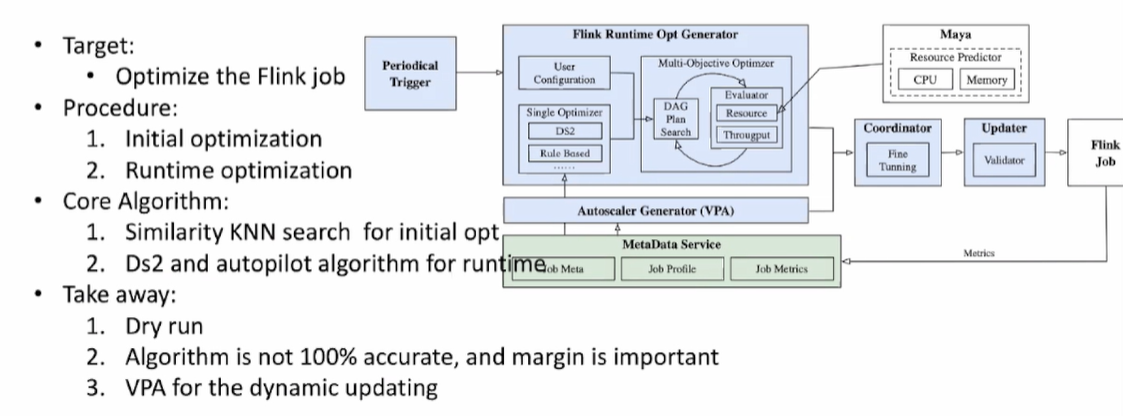
在这个案例中,我们设立的目标是优化 Flink ,使其 job 利用率变高,另外一个目标是他的吞吐不会受影响,也就是你的资源减少后不会减少它的吞吐。在优化Flink过程中采取了两种优化策略:
-
初始化优化策略
当Flink启动后,我们可以看到任务和过去历史任务的相似性与匹配度,我们从Flink任务中抽取任务的各种特征,比如:数据表类型,哪个用户提交操作等等,从而建立一个任务,通过相似性的方法最终得出这个任务初始化时候的最优plan。 -
运行时优化策略
当任务运行起来后,我们可以看到任务输入数据量,任务的节点的计算情况,根据节点运行情况进行预测与Job的吞吐量进行预测,之后对这个节点进行动态的弹性优化。
在这里有个核心点是,我们的 AI 预测准确度要足够高,但是以经验来说,我们不能100%来相信 AI,即使 99.5% 的正确率,但是还是有0.5% 的错误率的情况,这 0.5% 就会影响在线服务的质量,所以需要设置最后各种策略以及最后的“兜底”方式,来保证 AI 的正确执行。当 AI 被部署到生产环境后,需要一个较长时间的 Dry run,当 Dry run 很久之后,AI 的预测结果逐渐趋于稳定,才会最终上线。
所以最后总结来说,我们的 Framework 本质是来帮我忙做这些事情,如何设置 Dry run 时间,多少次调节一次利用率,怎么收集资源,这些都是 Framework 介入的。当如果想要提供给外部开发者使用的时候,你只需要接入 Framework 的通用 API,将所要执行的计划传给它,它会执行底层帮你来优化资源,同时把这个计划返回给 Flink,最后让 Flink 做这个任务本身的优化。
(二) 深度学习推理和训练任务的配置
另外一个案例是在进行深度学习的时候,对预测任务或者训练任务的时候,如何对 GPU 进行配置。
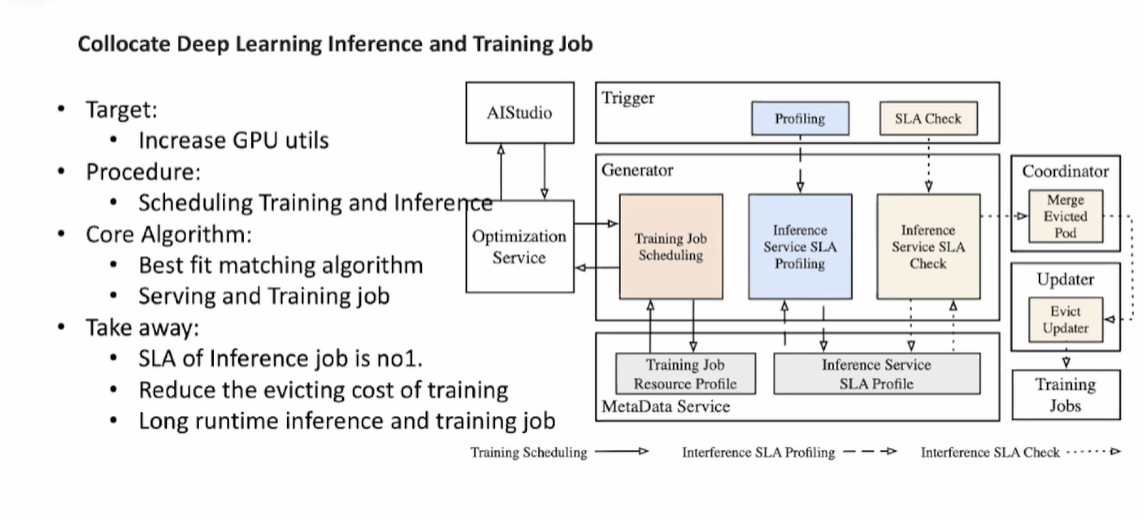
为了满足一个任务在线预测的时候,常常会给一个 AI 分配一个比较大的资源,在运行的时候我们会发现,资源的利用率会出现波峰波谷的现象。比如说晚上的时候在预测方面的资源利用率不高的时候,我们是否可以将训练任务调度到这个节点,同时让这个节点分享 GPU 给训练任务,这样就增加了资源的利用率。
那么在这个案例中,比较重要的就是如何进行安排这些任务,这个时候就需要AI的帮忙,需要预测出未来一段时间的利用情况,而且需要从众多任务 job 中找到一个自身所匹配的 job 来,匹配后即可将两个 job 放到一个 GPU 的 Pod 中,通过虚拟化技术提高 GPU 利用率。
注意这里有个潜在风险:已经正在运行在线任务 Job 是否能够保证他原有的 SLA。因为我们有可能会降低原有在线业务的 SLA,所以我们需要定义一些策略来预防这种可能,以确保原有业务的 SLA。

通过蚂蚁集团的案例最后总结可知,使用案例中的方案后,可以减少资源的浪费,可以提高GPU的利用率10%~20%左右。
2.2 数据库中的人工智能
2.2.1 学习索引(Learned Index)
(一)认识了解学习索引(Learned Index)

与大家熟知的传统索引不同,学习索引(Learned Index)是一种通过机器学习方法学习索引结构的概念。传统的索引结构(如 B树、哈希表等)是基于固定的规则和算法构建的,而学习索引则采用了不同的方法。
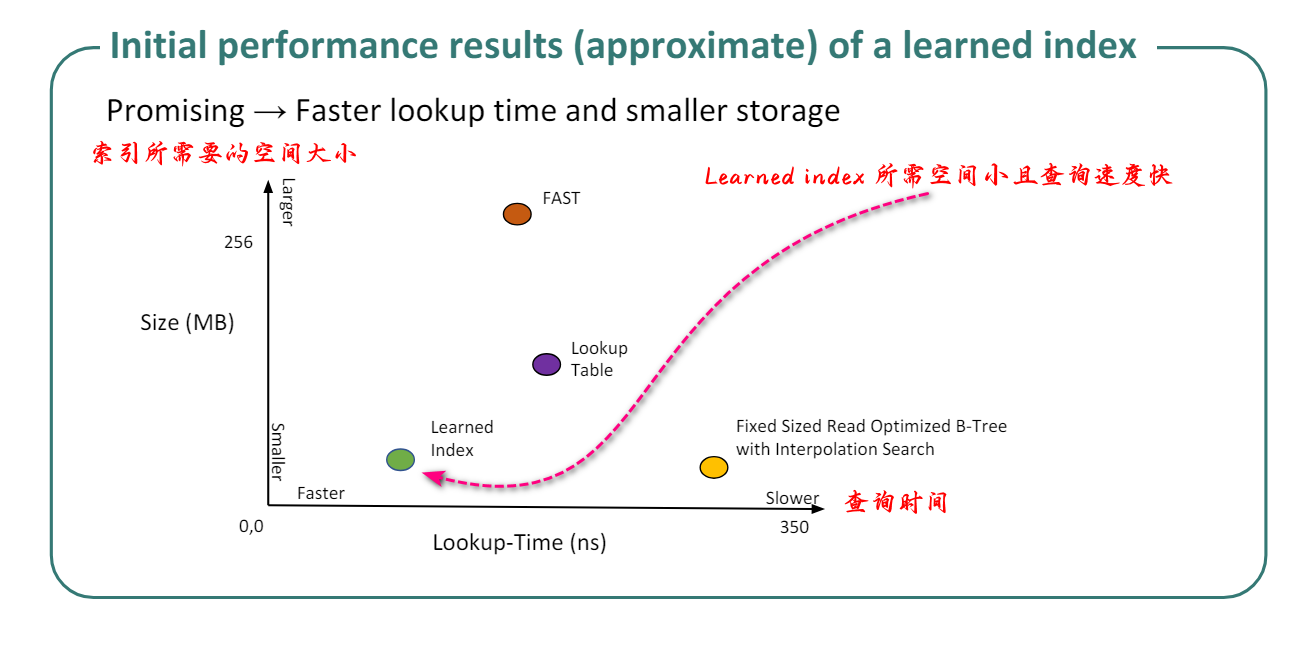
学习索引的基本思想是使用机器学习模型来学习数据集的分布和查询模式,从而能够更加智能地选择和定位索引节点,提高查询效率。学习索引的优点是可以根据数据集的特征和查询模式来自适应地构建索引,从而提供更高效的数据访问性能。
下图可以明显看出,使用Learned index,不仅所需要的空间小且查询速度快。
(二)学习索引的分类
在学习索引(Learned Index)领域,“Learning the index”、“Indexing Learned Models” 和 "Benchmarking"是三个大的分类。

-
Learning the index(学习索引):这个分类关注的是如何通过机器学习方法来学习索引结构本身。学习索引的目标是通过学习数据集的分布和查询模式,构建更智能和高效的索引结构。这个分类中的研究主要集中在如何选择索引节点、确定索引的层次结构以及优化查询策略等方面。
-
Indexing Learned Models(学习模型的索引):这个分类涉及学习索引与机器学习模型之间的关系。学习模型通常用于处理和分析数据,而学习索引则用于加速对这些学习模型的查询。这个分类中的研究主要关注如何有效地构建和维护针对学习模型的索引,以便在查询过程中快速定位到相关的模型。
-
Benchmarking(基准测试):这个分类关注的是对学习索引方法进行评估和比较。由于学习索引是一个相对较新的研究领域,需要进行实验和评估来了解不同方法的性能和效果。这个分类中的研究主要包括定义评估指标、设计实验方法以及比较学习索引与传统索引的性能等方面。
(三)学习索引结构的案例
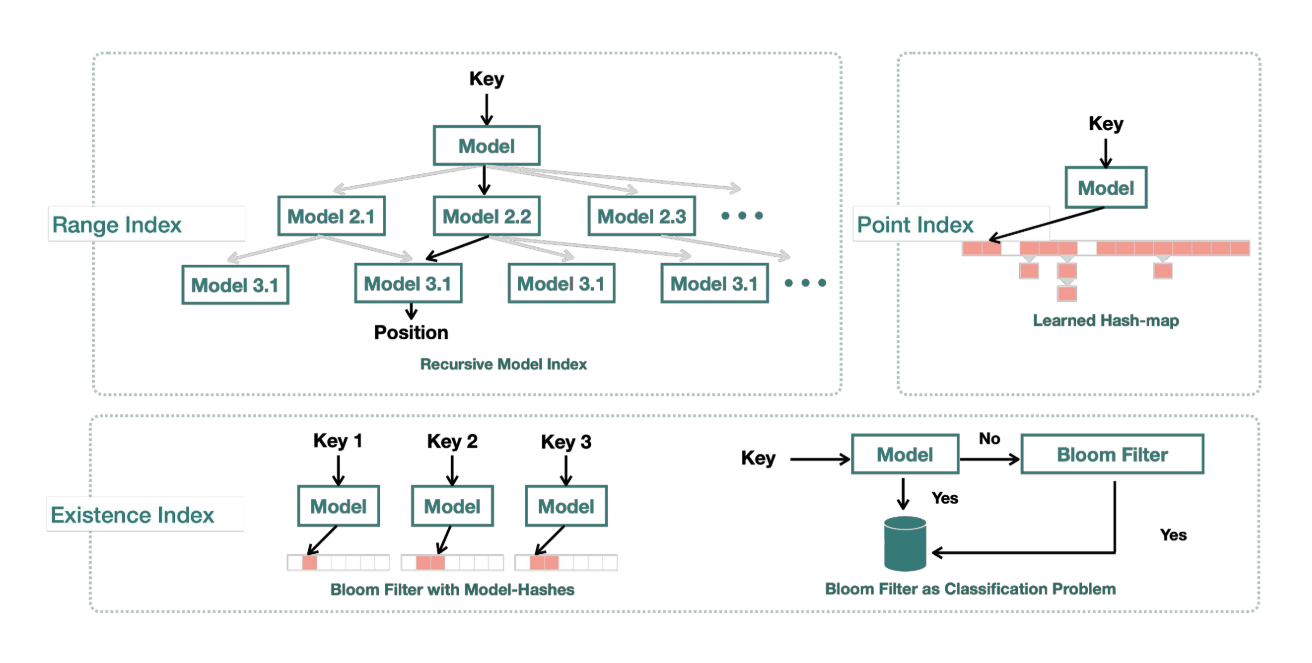
学习索引结构有三种:Range Index、Point Index与Existence Index。
-
Range Index(范围索引):Range Index 是一种学习索引结构,用于高效地支持范围查询。范围查询是指根据某个范围条件检索数据集中满足该条件的数据。传统的索引结构(如 B-树)在范围查询时需要遍历索引树的各个节点,而 Range Index 则通过学习数据集的分布和查询模式,可以更加智能地确定索引节点的选择和访问顺序,从而提高范围查询的性能。
-
Point Index(点索引):Point Index 是一种学习索引结构,主要用于高效地支持点查询。点查询是指根据给定的键值检索数据集中对应的数据。Point Index 通过学习数据集的分布和查询模式,可以根据查询键值智能地选择索引节点,从而减少不必要的访问和提高点查询的性能。
-
Existence Index(存在性索引):Existence Index 是一种学习索引结构,用于判断给定键值是否存在于数据集中。存在性查询是指根据给定的键值判断该键值是否存在于数据集中。传统的索引结构(如哈希表)在存在性查询时需要访问索引节点并比较键值,而 Existence Index 利用机器学习方法学习数据集的分布和查询模式,可以更智能地判断键值的存在性,从而提高查询性能。
2.2.2 华为云案例中的自适应的Art index
在这个案例中ES引擎中做KV查询的时候,使用了FST(Finite Stage Transducer)来支持数据的倒排索引查询,在应用的场景遇到了几个问题,比如内存消耗过大,查询时间过长以及吞吐量低。
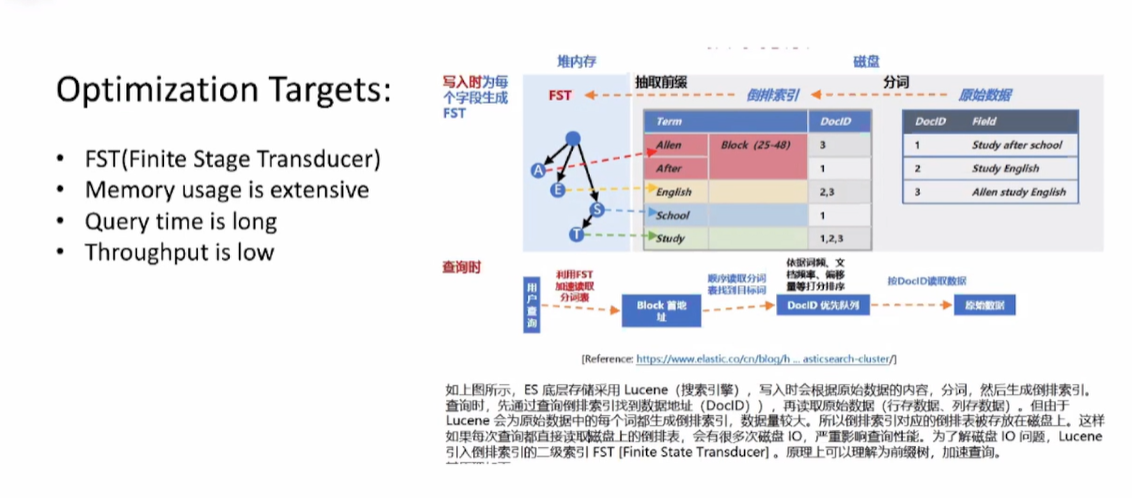
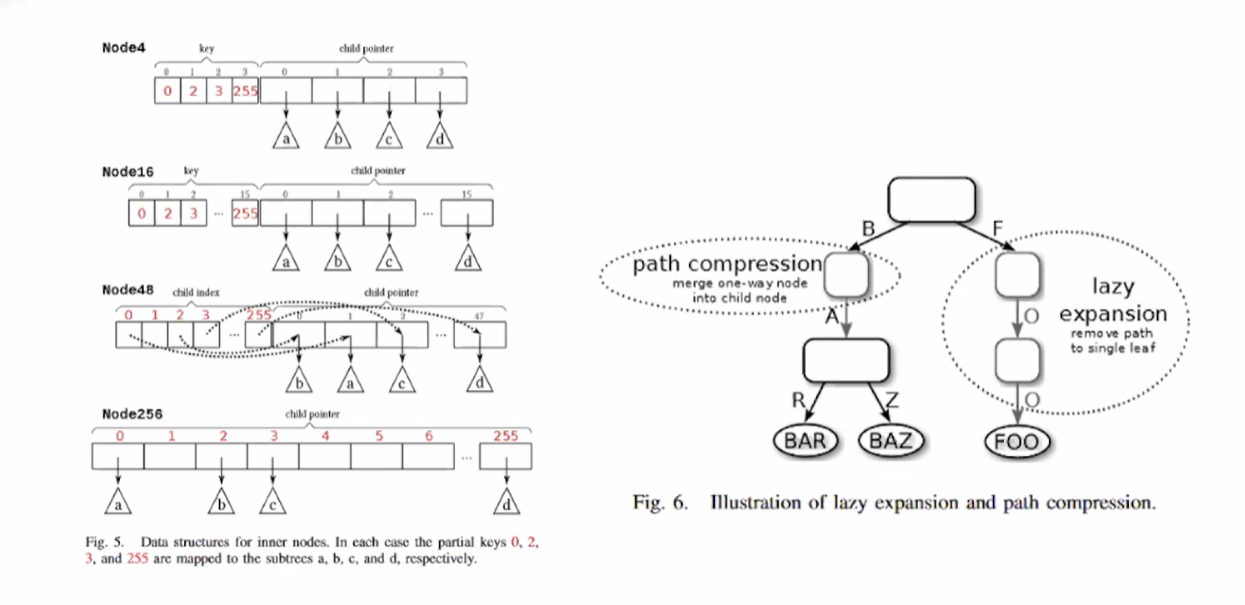
为了解决该问题,在该案例中采用了经典的Art index,并且对其进行了相应的优化,比如对节点进行优化,对压缩路径进行优化等。
当在该案例中引入Art index并进行优化之后,与现有的FST方式对比,系统的利用率和性能普遍得到明显提升
- 堆内存减少43%
- 单线程QPS提高了2.3倍
- 单线程查询速度提高了2.4倍
- 在并发32个多线程查询的时候提高了4倍

三、System for AI(人工智能系统)
3.1 面临的挑战
在爆火的ChatGPT后,对于这种具有大参数的且有大数据量的大语言模型,有的企业或者组织会遇到一个共同的问题,我已经有大语言模型了,但是就是训练不出来,因为这里所涉及到的优化不仅在框架层,在调度资源层也同样存在。
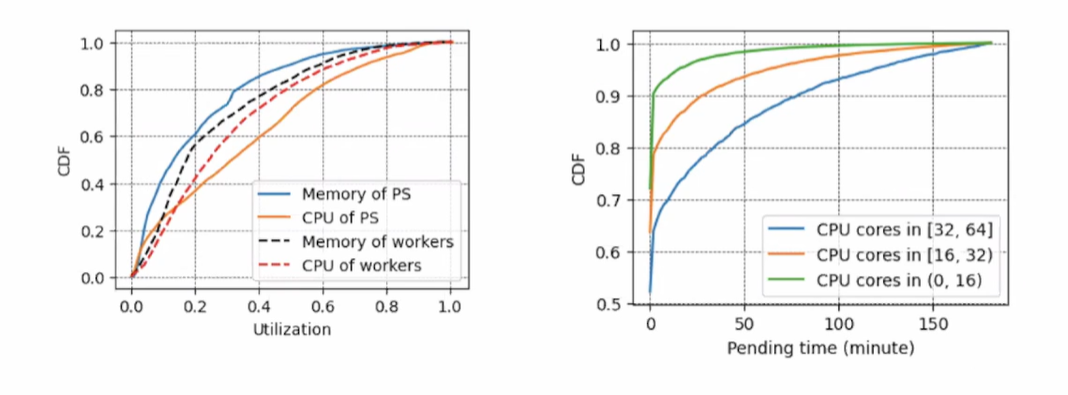
我们如何利有限的资源去做分布式的大规模训练成了一个巨大挑战。
在生产集群中,大部分的集群的内存、CPU、GPU 利用率通常是比较低的,且任务排队时间较长。
3.2 大模型训练方式
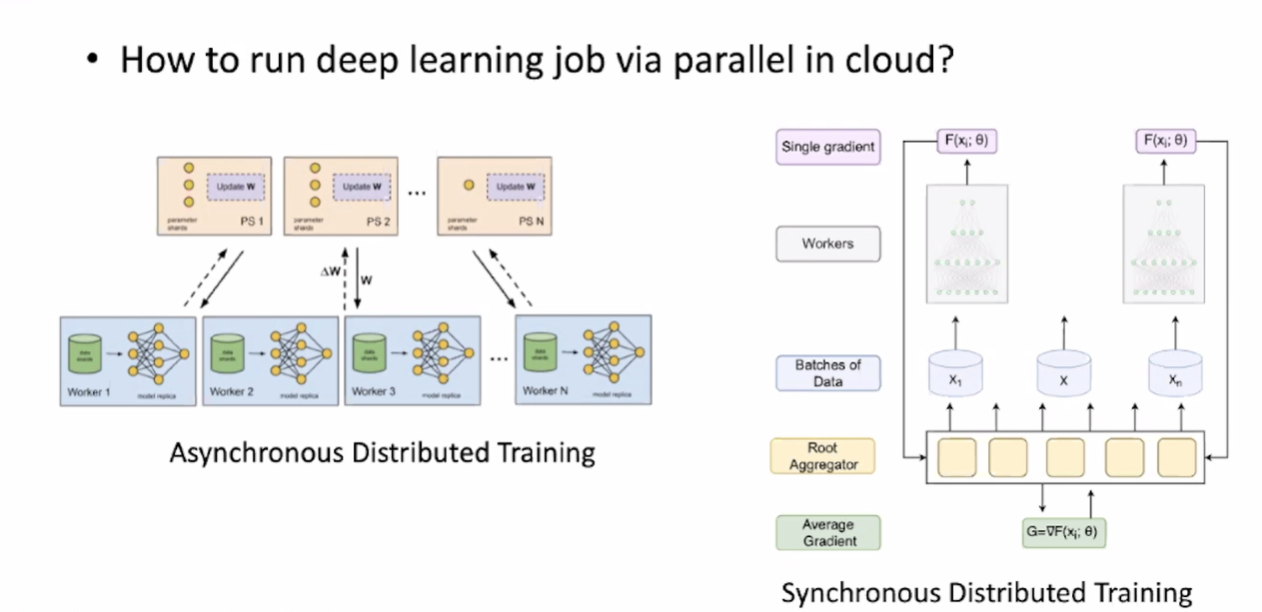
在大语言模型训练中,现阶段大家普遍采用的是同步模式进行训练,采用同步模式训练的原因总结起来有如下几点:
训练效率高:与异步训练相比,同步模式训练可以充分利用并行计算的能力,提高训练效率。在同步模式下,多个计算设备(如 GPU)可以同时进行模型参数更新,每个设备负责处理一部分训练数据。这样可以加快训练速度,提高训练效率。
参数一致性高:同步模式训练确保在每个训练步骤结束时,所有设备上的参数都得到更新,并保持一致。这对于大型语言模型是至关重要的,因为模型的参数需要保持同步以确保正确的预测结果。如果使用异步模式训练,不同设备上的参数更新可能会出现不一致,导致模型性能下降。
内存占用低:同步模式训练可以更有效地管理内存占用。在异步模式下,每个设备都会维护自己的参数副本,导致额外的内存消耗。而同步模式下,参数共享并进行同步更新,减少了内存需求。
算法稳定性高:同步模式训练通常具有更好的数值稳定性。由于同步模式下所有设备在每个训练步骤中都使用相同的参数,可以更好地控制数值计算的稳定性和一致性,减少梯度更新的不稳定性和震荡。
3.3 DLRover 案例
DLRover 在分布式集群上自动训练深度学习模型。它可以帮助模型开发人员专注于模型架构,而无需考虑任何工程方面的东西,比如硬件加速、分布式运行等。现在,它为K8s/Ray上的深度学习培训工作提供自动化运维。
- 项目地址:https://github.com/intelligent-machine-learning/dlrover
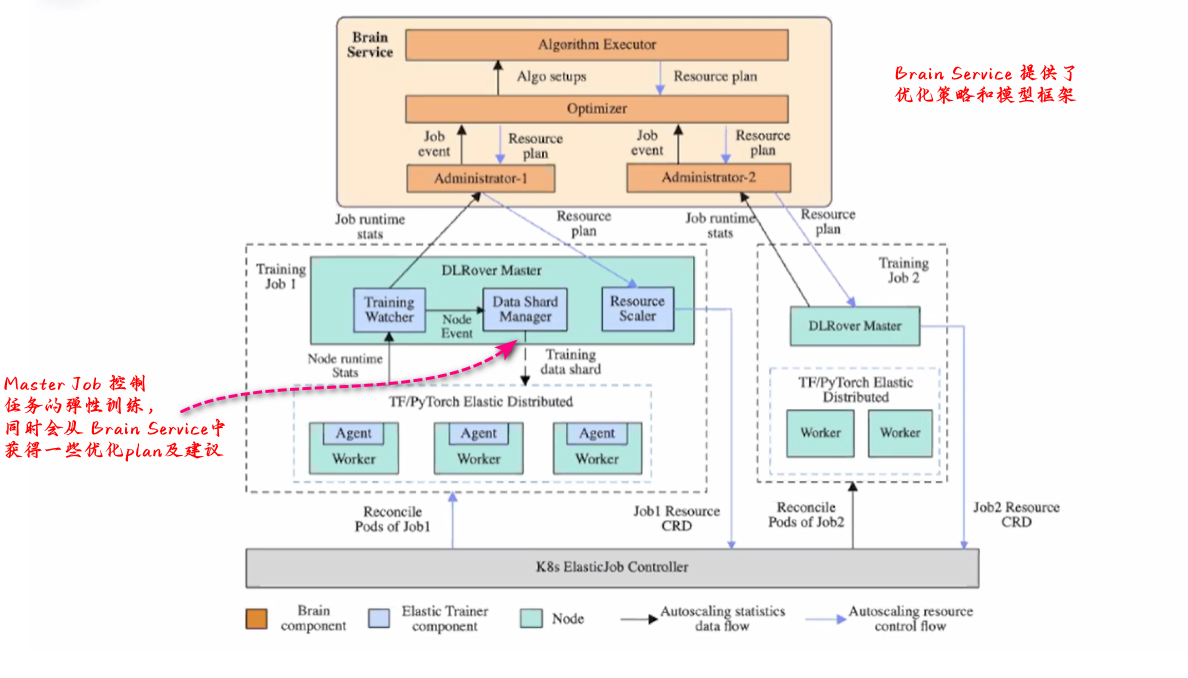
从上图中可以看出 DLRover 系统框架分为两块:一部分是 Brain Service,另一部分是 Training Job 部分。
Brain Service 提供了不同的优化策略和一些模型框架,在这里决定了你如何进行优化,如何进行决策策略。Training Job 中有一个 Mater,它负责管理 Jobs,并且会从 Brain Service 中获得一些优化plan以及建议。
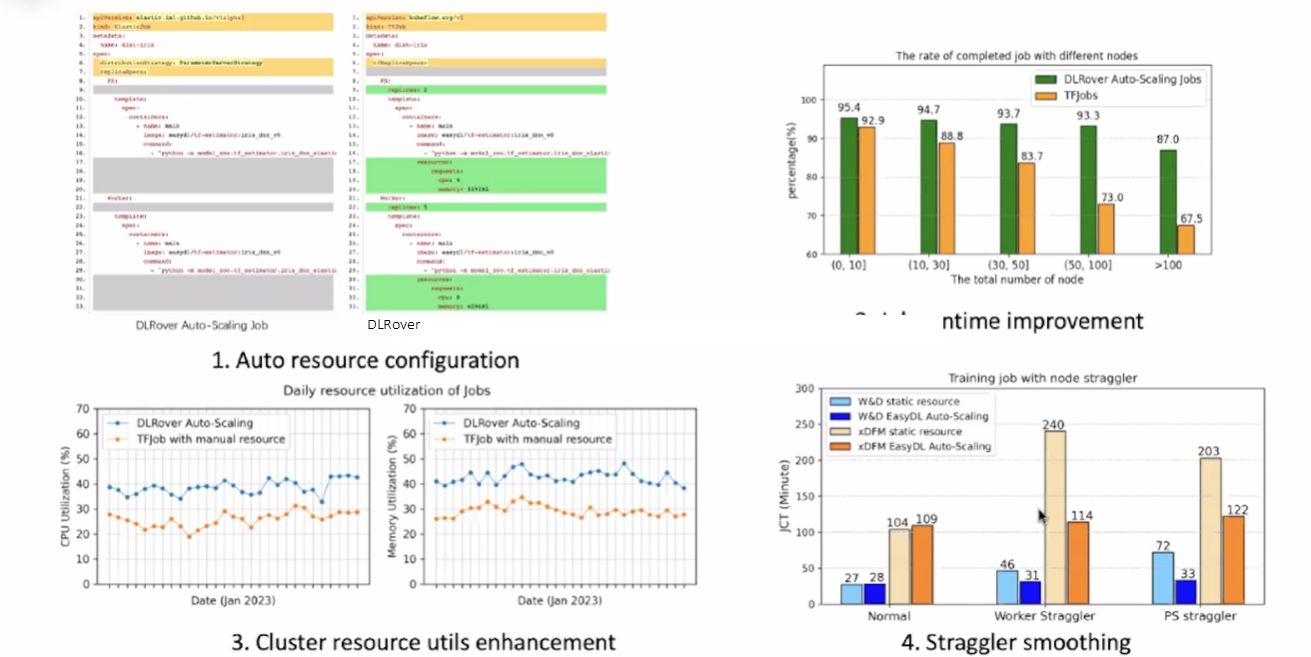
DLRover 优点以及改善状况
相对传统的 TensorFlow Job(TFJob)需要用户需要使用多少 CPU、多少内存等,DLRover 可以自动弹性伸缩;在 Job 的运行时间方面,当节点比较多的时候,性能优化的改善会更大,从图中可以看出 DLRover 有明显的改善;在资源利用率中,利用率有 20% 左右的提升;当某一个节点出现故障的时候,与传统相比,弹性动态的功能可以达到提出掉有问题的节点。
四、问题汇总
-
数据库如何支撑大量数据的AI训练,比如说有百亿参数的训练?
数据库训练模型中,计算节点和训练节点通常在不同位置,一般情况我们会从远程数据存储的数据库中拉去数据,假设在大量高并发同时拉去数据的时候,很有可能会造成数据库宕机。针对该问题有几个策略,一方面是想办法将数据库缓存到训练节点的内存中,做一些调度;另外的做法是将数据库的数据dump成文件形式进行训练。 -
Learned Index有商用的案例吗?
相关案例比较少,只有在小范围google公司内使用。 -
Learned Index模型是在线训练实时更新的吗?
不是实时更新 -
LLM的长处是对任务的生成,对index的生成与优化上大模型的优势有哪些?
虽然LLM模型主要针对自然语言处理,但是LLM依然可以做一些分类或者预测问题,大语言模型具有一定的扩展能力,现阶段大家在思考以及一些团队研究如何使用大语言模型使用一个index就可以搞定一切事情。 -
如何看到国内的大厂都在争先的做大语言模型训练,但是仍然无法做出与ChatGPT同类型的爆款产品,原因是什么?
ChatGPT之所以功能强大,并不仅仅是因为其模型本身足够庞大。实际上,早在几年前,ChatGPT就已经开始使用人类反馈强化学习(reinforcement learning from human feedback, RLHF)。然而,国内某些大型语言模型在这方面的训练相对较少。
总结
本文深入探讨了 AI for System 和 System for AI 两个关键领域。在 AI for System 部分,介绍了面向分布式作业的人工智能以及当前企业云计算系统所面临的常见问题和相应解决方案。其中提到了 Google Autopilot Eurosys 2021 方案和 ibaba Rose ICDCS 2019 方案作为解决痛点的示例。还介绍了优化框架 COUGAR 的架构,并给出了流处理作业(Flink)优化和深度学习任务配置的案例。在 AI for Database 部分,讨论了学习索引(Learned Index)的概念、分类和案例,以及华为云中的自适应 Art index 案例。接着,文章转向 System for AI,探讨了该领域面临的挑战,大模型训练方式,并提供了 DLRover 案例。最后,文章对前文讨论的问题进行了总结。通过这些内容,读者可以更好地了解和应用 AI 和系统领域的关键概念和解决方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!