系统设计-缓存介绍
该图说明了我们在典型架构中缓存数据的位置。
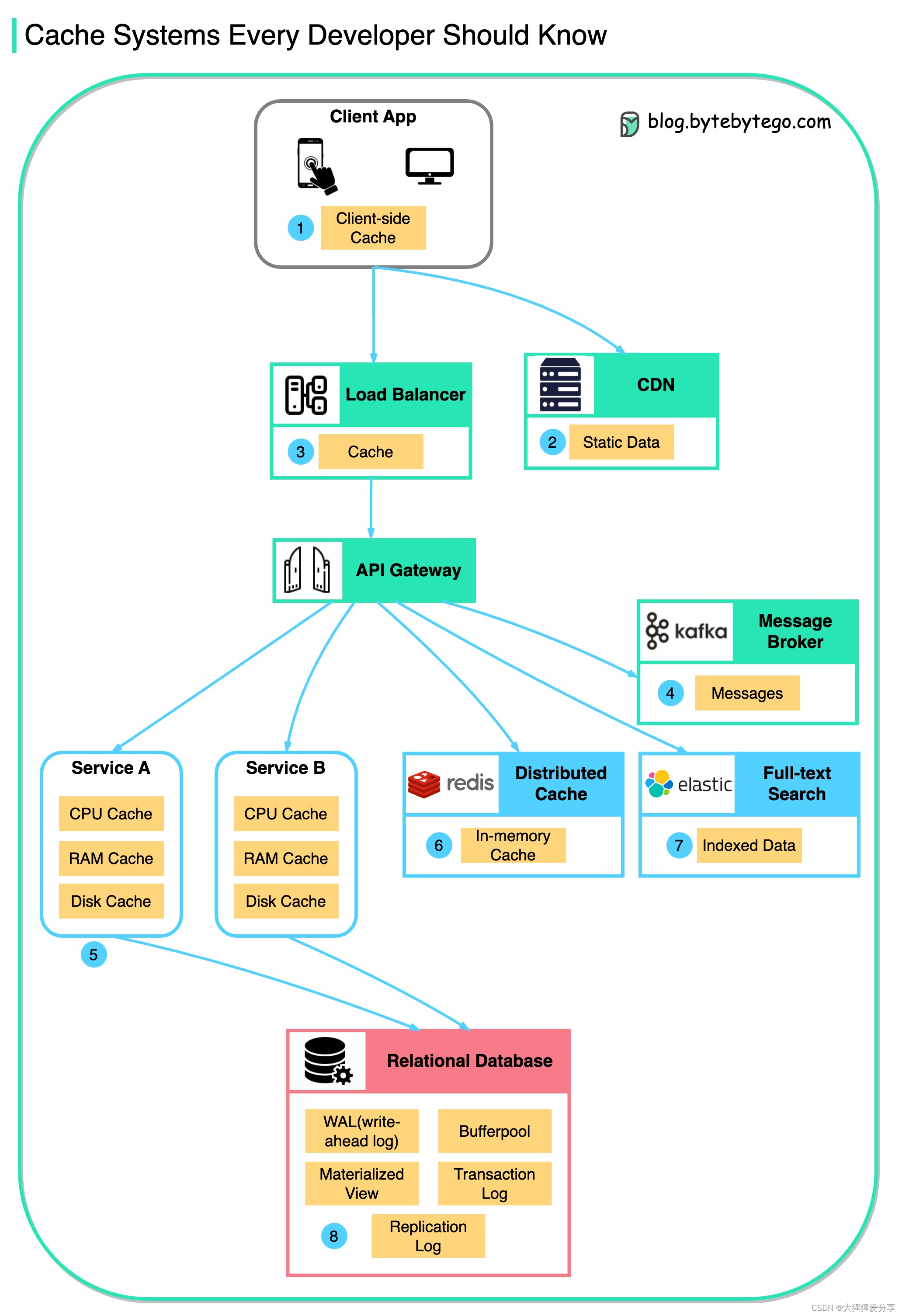
沿着流程有多个层次。
- 客户端应用程序:HTTP 响应可以由浏览器缓存。我们第一次通过 HTTP 请求数据,返回时在 HTTP 标头中包含过期策略;我们再次请求数据,客户端应用程序首先尝试从浏览器缓存中检索数据。
- CDN:CDN缓存静态网页资源。客户端可以从附近的CDN节点检索数据。
- 负载均衡器:负载均衡器也可以缓存资源。
- 消息传递基础设施:消息代理首先将消息存储在磁盘上,然后消费者按照自己的节奏检索消息。根据保留策略,数据会在Kafka集群中缓存一段时间。
- 服务:服务中有多层缓存。如果数据没有缓存在CPU缓存中,服务将尝试从内存中检索数据。有时服务有二级缓存来将数据存储在磁盘上。
- 分布式缓存:像Redis这样的分布式缓存在内存中保存多个服务的键值对。它提供比数据库更好的读/写性能。
- 全文搜索:我们有时需要使用全文搜索,例如Elastic Search来进行文档搜索或日志搜索。数据副本也会在搜索引擎中建立索引。
- 数据库:即使在数据库中,我们也有不同级别的缓存:
- WAL(Write-ahead Log):在构建B树索引之前,先将数据写入WAL
- Bufferpool:分配用于缓存查询结果的内存区域
- 物化视图:预先计算查询结果并将其存储在数据库表中以获得更好的查询性能
- 事务日志:记录所有事务和数据库更新
- 复制日志:用于记录数据库集群中的复制状态
?为什么Redis这么快?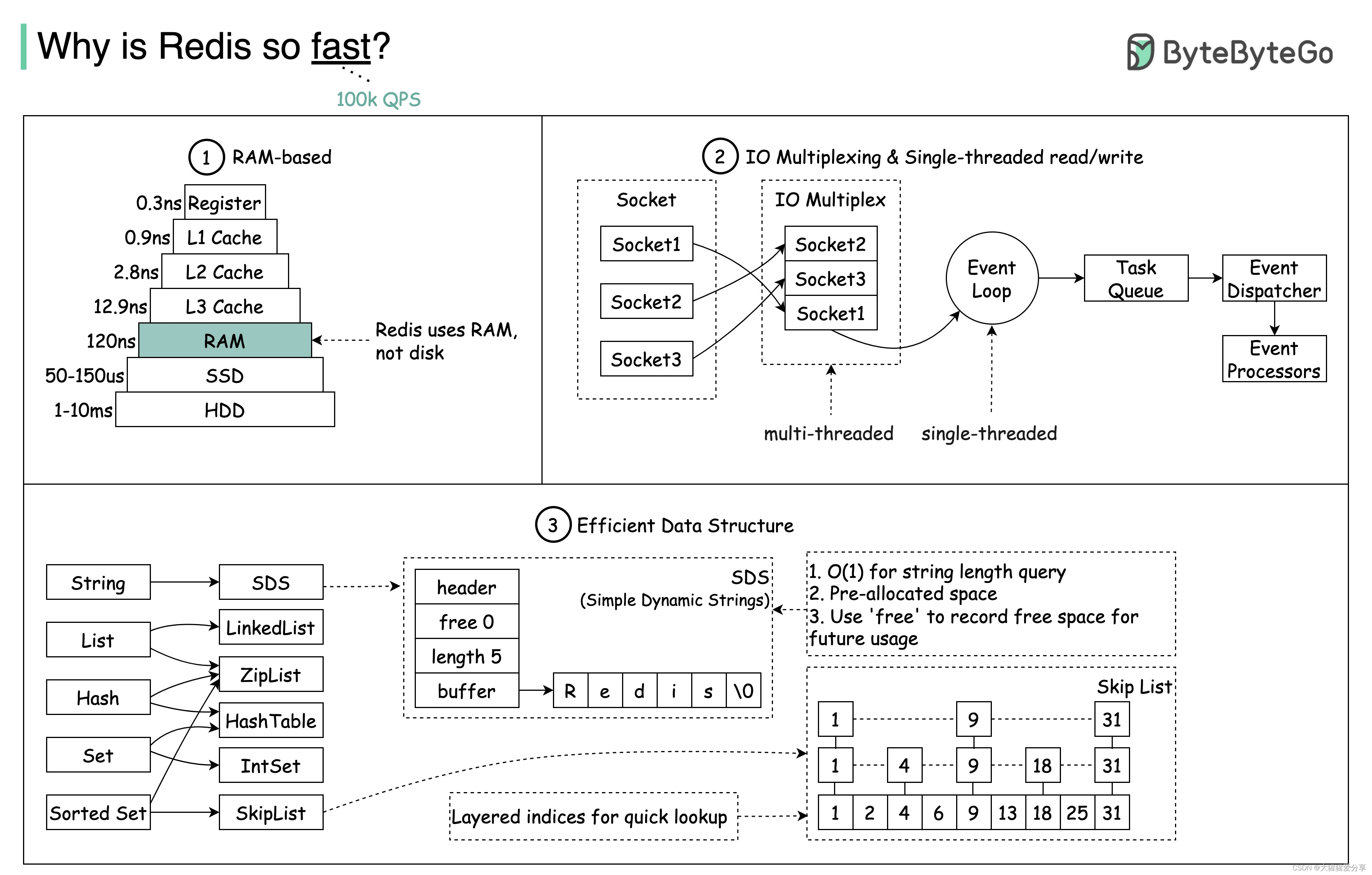
- Redis 是一个基于 RAM 的数据存储。RAM 访问至少比随机磁盘访问快 1000 倍。
- Redis 利用 IO 多路复用和单线程执行循环来提高执行效率。
- Redis 利用多种高效的低级数据结构。
?如何使用Redis

Redis 使用场景
Redis 可用于多种场景,如图所示。
-
会话
我们可以使用Redis在不同服务之间共享用户会话数据。
-
缓存
我们可以使用Redis来缓存对象或页面,尤其是热点数据。
-
分布式锁
我们可以使用Redis字符串来获取分布式服务之间的锁。
-
统计
我们可以统计文章的点赞数或阅读量。
-
速率限制器
我们可以对某些用户 IP 应用速率限制器。
-
全局 ID 生成器
我们可以使用 Redis Int 作为全局 ID。
-
购物车
我们可以使用 Redis Hash 来表示购物车中的键值对。
-
计算用户保留率
我们可以使用Bitmap来表示每天的用户登录情况并计算用户留存情况。
-
消息队列
我们可以使用 List 作为消息队列。
-
排行
我们可以使用ZSet对文章进行排序。
顶级缓存策略
设计大型系统通常需要仔细考虑缓存。以下是五种常用的缓存策略。
?
1. Cache Aside (Lazy-Load):
-
工作原理: 应用程序负责直接读写缓存。数据在被读取时,首先尝试从缓存获取;在写入时,直接更新缓存,并且可能在后续异步或同步地更新数据源。
-
适用场景:
- 读密集型工作负载。
- 数据变更不频繁的情况。
- 实时性要求不高的应用。
2. Read Through:
-
工作原理: 缓存系统管理缓存,并在数据未命中时从数据源(通常是数据库)读取数据。应用程序直接访问缓存,而缓存负责从数据源读取数据。
-
适用场景:
- 读操作频繁,对实时性要求较高。
- 数据源对应用程序相对透明。
3. Write-Around:
-
工作原理: 写操作直接更新数据源,而不是直接更新缓存。只有被读取的数据才会放入缓存。
-
适用场景:
- 写操作频繁,但读操作相对较少。
- 数据变更频繁,但不是立即被读取的情况。
4. Write-Back (Write-Behind):
-
工作原理: 写操作首先更新缓存,然后异步地或在特定条件下将缓存中的数据批量写回到数据源。
-
适用场景:
- 写操作频繁,对实时性要求相对较低。
- 提高写操作性能,通过批量写回减少对数据源的频繁写入。
5. Write Through:
-
工作原理: 写操作直接更新缓存,并且同步更新到数据源,确保数据一致性。
-
适用场景:
- 需要强一致性的场景,对实时性要求较高。
- 适用于事务性应用,要求写入后立即生效。
比较与选择:
- 不同的缓存模式适用于不同的应用场景,选择应根据应用程序的读写模式、数据变更频率以及对实时性和一致性的需求进行权衡。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!