阅读笔记-PRECISE ADJACENT MARGIN LOSS FOR DEEP FACE RECOGNITION
PRECISE ADJACENT MARGIN LOSS FOR DEEP FACE RECOGNITION
深度人脸识别的精确相邻边缘损失
1、这篇论文要解决什么问题?要验证一个什么科学假设?
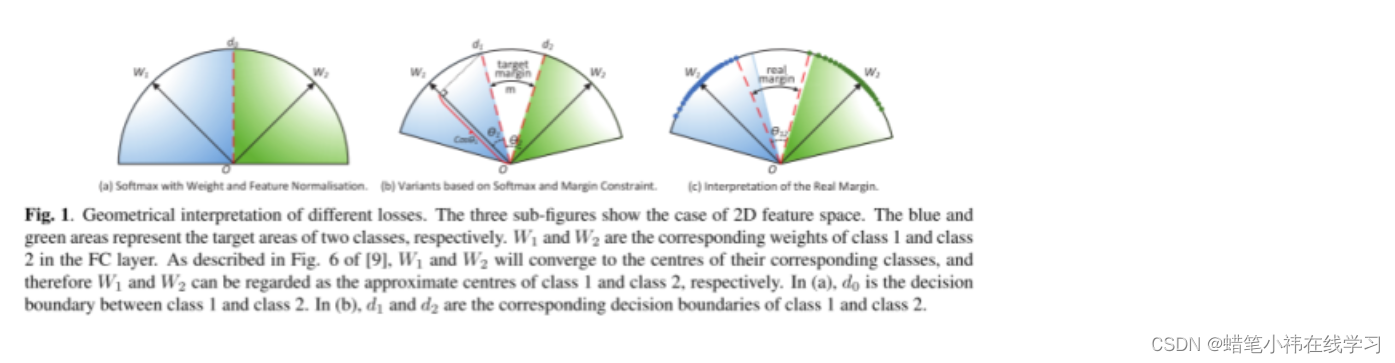
问题:首先,在以往的损失函数中提到的“边际”是Softmax 决策边界之间的边际,它不代表训练集中不同类别之间的真实的边际;其次,以往的损失函数对所有可能的类对组合施加了边界,这是不必要的。
验证PAM损失(精确邻接边际损失)比现有的基于边际的损失具有更好的几何解释。
2、这篇论文有哪些相关研究,这些研究是怎么分类的?有哪些研究员值得关注?
这篇论文对softmax、L- Softmax loss、A-Softmaxloss、AM-Softmax loss 和Arc- Face loss进行了研究。

3、论文中提到的解决方案是什么,关键点在哪儿?
在论文中提出了精确相邻边距损失(PAM loss),它赋予“边距”一种含义,表示训练集中不同类之间的真实边距。与上面的损失不同,PAM损失只对有限数量的类对优化边际。
关键点如下:
- 提出了PAM算法来提高深度特征的识别能力。PAM损失是第一个使用训练集中不同类之间的实际差值的损失。
- 为了实现PAM,提出了一种学习算法来获取每个类的范围( 即类中心与类边缘之间的余弦相似度) 。

4、论文中的实验是如何设计的?各个实验分别得到了什么结论?
实验一:提供了在两个类别的情况下上述损失函数的2D可视化。
实验二:用Tensorflow实现了四种方案,通过结合使用不同的损失函数 :ResNet + Softmax, ResNet + AM-Softmax, ResNet + AM-Softmax + PAM loss v1,ResNet + AM-Softmax + PAM loss v2。为了方便,在实验结果中分别使用 “ Softmax” 、 “ AM-Softmax”、“PAM loss v1”和“PAM loss v2”来表示这四种方案。
所有实验都使用 VGGFace2作为训练集。为了保证实验结果的可靠性,删除了 VGGFace2中可能与基准测试集重叠的人脸图像。最终的训练集包含了来自 8000 多个身份的 305 万张面部图像。
对于实验中使用的所有人脸数据集,都使用MTCNN进行人脸检测。如果对一个训练图像检测MTCNN失败,就将该图像从训练集中去除。如果MTCNN在测试图像上失败,使用由官方提供的标记或边界框。由于学习率在早期不稳定,超参数 λ 在前 275 个时期被设置为0。之后,手动优化 λ,因为它对性能不是很敏感,所以只是在每个测试集中尝试多个不同的值,并选择导致最佳结果的值。

表 2显示了本文方法和最新研究方法在 LFW和YTF数据集上的结果,可以看出:在LFW上,PAM loss 的两个版本均优于相关方法Softmax、L-Softmax、A-Softmax 和 AM-Softmax。FaceNet具有与 PAM loss v1 相同的准确性。然而,FaceNet使用了2亿张图像进行训练,而PAM loss 只使用了305万张图像进行训练。与其他先进的方法相比,PAM损耗具有最高的验证精度。在 YTF 数据集上,PAM loss v1 的准确率为96.14%,高于其他所有方法。PAM loss v2 在准确性上与Marginal loss 相似,但Marginal loss 使用了更大的训练集,在 LFW上性能较差。在 LFW和YTF 数据集上的结果证明了该方法的有效性和最先进的性能。
实验三:对MegaFace 数据集和FaceScrub数据集进行实验。遵循 MegaFace Challenge 1 的实验协议,其中MegaFace设置为干扰集,FaceScrub设置为测试集。评估代码由MegaFace团队提供。
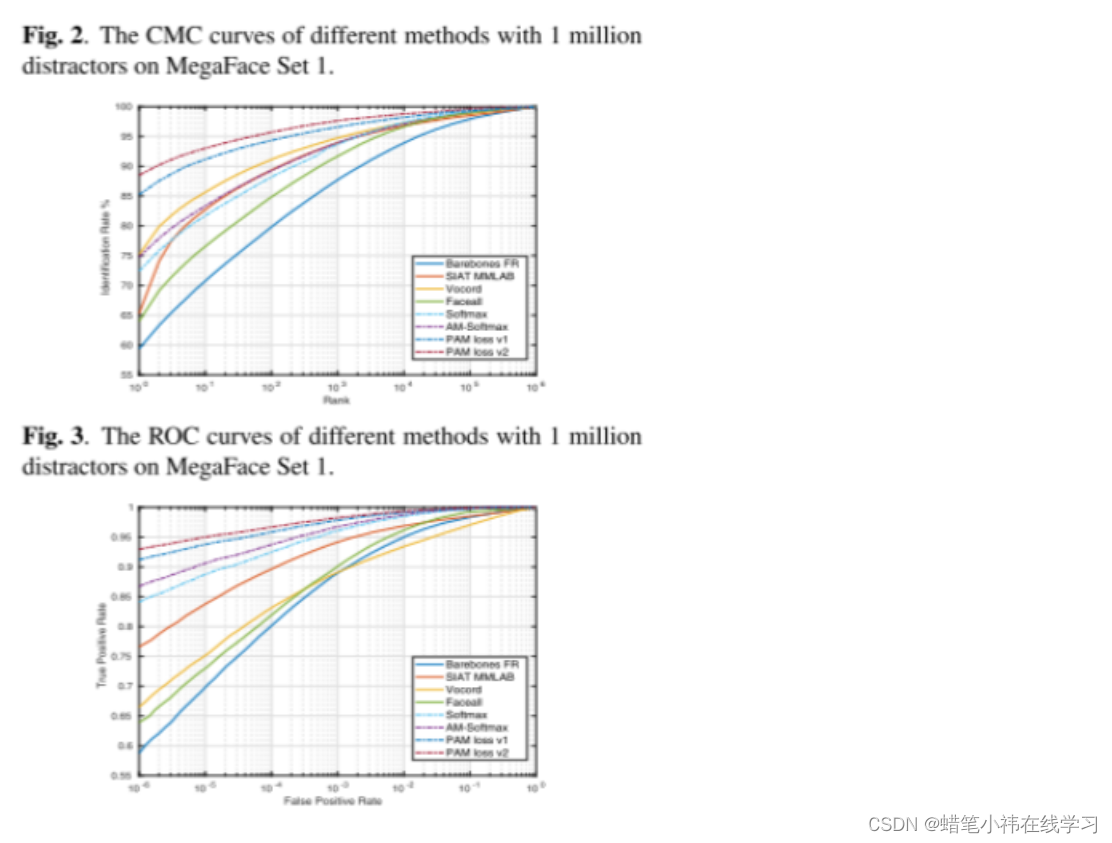
图 2 和图 3 分别为MegaFace Set 1上 100万干扰物时的CMC曲线和ROC 曲线。基准测试方法(包括Barebones FR、SIATMMLAB、Vocord 和 Faceall)的结果是由MegaFace 团队提供
的功能生成的。从图 2 和图 3 可以看出,PAM loss v1 和PAM loss v2 比Softmax、AM-Softmax 等基准方法具有更好的识别和验证性能。两幅图中 PAM损失 v2 都优于 PAM损失v1,说明 PAM损失 v2 在干扰量为 100 万的情况下具有更强的能力。MegaFace 和 FaceScrub 数据集的结果证实了所提方法的有效性。
5.用于定量评估的数据集是什么?代码开源的话找到链接
实验一:LFW、YTF
实验二:VGGFace2
实验三:MegaFace 和 FaceScrub 数据集
6、这篇论文到底有什么贡献?(三句话内说明)新在什么地方?
这篇论文提出了 PAM损失,它赋予了“边际”一种含义,表示训练集中不同类之间的真实边际。为了实现 PAM,还提出了一种学习算法来获取每个类的范围。在LFW、YTF、MegaFace和 FaceScrub数据集上进行了大量的实验。结果证明了所提方法的有效性,并证实了PAM性能的先进性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!