Python急速入门——(第六章:字典)
Python急速入门——(第六章:字典)
1.什么是字典?
1.字典:
1)Python内置的数据结构之一,与列表一样是一个可变序列(可变是指可以进行增删改的操作);
2)以键值对的方式存储数据,字典是一个无序的序列(列表是有序序列);
3)有序指的是列表在存放元素时,是按顺序挨个存放的;而字典则是通过哈希函数,用序列的值,来计算这个序列的存储位置;
4)所以字典中的序列必须是不可变序列,意思是不可以进行增删改操作(目前学到的可变序列只有两个,一个是列表,一个是字典)。
2.语法结构:
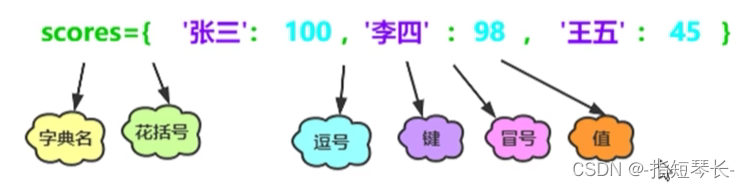
3.字典示意图:
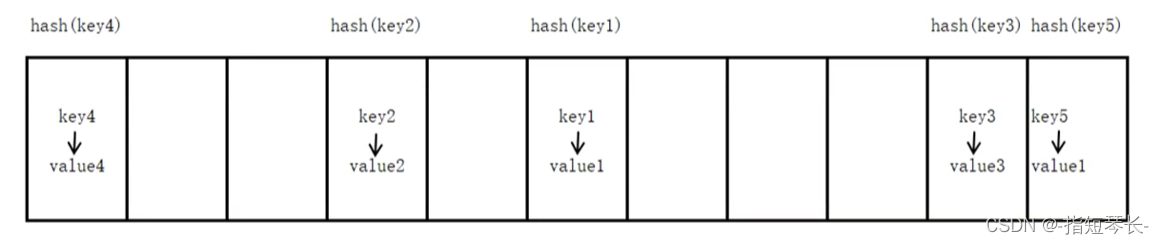
key后数字表示序列存放的先后顺序,可见字典是无序的。
4.字典的实现原理:
字典的实现原理和查字典类似,查字典是根据部首或拼音查找汉字对应的页码,Python中的字典是根据key查找value所在的位置;也通过哈希函数,用value直接计算出序列的位置,所以字典的查找效率是很快的。
2.字典的创建
1.最常用的方式:使用花括号
"""使用{}创建字典"""
score = {'zhangsan': 100, 'wangwu': 98, 'lisi': 78}
print(score)
print(type(score))
输出:
{'zhangsan': 100, 'wangwu': 98, 'lisi': 78}
<class 'dict'>
2.使用函数dict()
"""使用内置函数dict()创建字典"""
student = dict(name='zhangsan', age=18)
# 等号后的值要不要加引号,取决于数据类型
print(student)
print(type(student))
输出:
{'name': 'zhangsan', 'age': 18}
<class 'dict'>
3.创建空字典:
"""创建空字典"""
score = {}
print(score)
c = dict() # 不给任何参数
print(c)
输出:
{}
{}
3.字典的常规操作
3.1字典中元素的获取
1.字典中元素的获取:

2.[]取值与使用get()取值的区别:
[]取值,如果字典中不存在指定的key,抛出keyError异常;get()方法取值,如果字典中不存在指定的key,并不会抛出错误,而是返回None,可以通过参数设置默认的value,以便指定的key不存在时返回。
3.例:
print("--------------------使用[]取值--------------------")
score = {'zhangsan': 100, 'lisi': 89, 'wangwu': 77}
print(score['zhangsan']) # 取到了张三的对应的value:100
# print(score['maqi']) # 抛出keyError: 'maqi'
print("--------------------使用get()取值--------------------")
print(score.get('lisi'))
print(score.get('maqi')) # 返回None
print(score.get('maqi', 99)) # 当指定key值不存在时,返回99
"""以上元素的获取方法都是根据键(key)来确定对应的值(value)"""
输出:
--------------------使用[]取值--------------------
100
--------------------使用get()取值--------------------
89
None
99
3.2字典元素的增删改
1.key的判断:
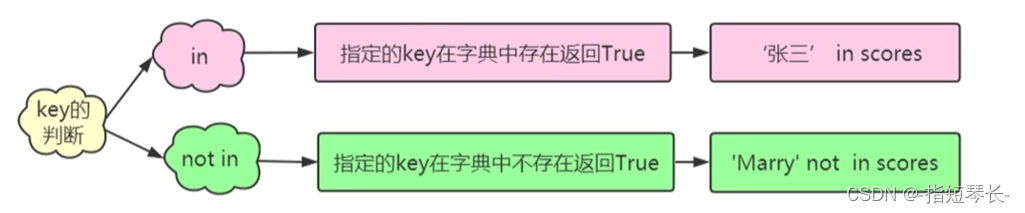
"""key值的判断"""
score = {'zhangsan': 100, 'lisi': 99, 'wangwu': 87}
print('zhangsan' in score)
print('lisi' not in score)
输出:
True
False
2.字典元素的删除:
删除单个元素:使用del语句删除一个键值对(键和值一并删除)。
删除全部元素:使用clear()删除字典中的全部元素。
"""字典元素的删除"""
# 删除单个元素
del score['zhangsan']
print(score)
# 删除全部元素
score.clear()
print(score)
输出:
{'lisi': 99, 'wangwu': 87}
{}
3.字典元素的新增和修改:
"""字典元素的增加"""
score = {'zhangsan': 100, 'lisi': 99, 'wangwu': 87}
print('增加前:', score)
score['maqi'] = 90
print('增加后', score)
score['lisi'] = 0
print('修改lisi:', score)
输出:
增加前: {'zhangsan': 100, 'lisi': 99, 'wangwu': 87}
增加后 {'zhangsan': 100, 'lisi': 99, 'wangwu': 87, 'maqi': 90}
修改lisi: {'zhangsan': 100, 'lisi': 0, 'wangwu': 87, 'maqi': 90}
3.3获取字典视图
1.获取字典视图的三个方法:
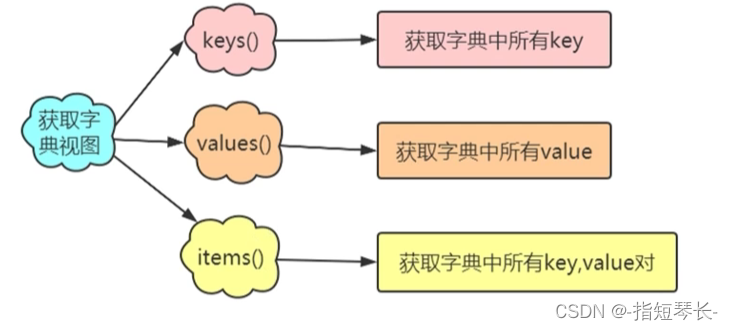
"""获取字典视图"""
print('---------------- 获取所有keys ---------------------')
score = {'zhangsan': 100, 'lisi': 98, 'wangwu': 45}
keys = score.keys()
print(keys)
print(type(keys)) # 为dict_keys类型
print(list(keys)) # 将dict_keys类型转换成列表
print('---------------- 获取所有values ---------------------')
values = score.values()
print(values)
print(type(values)) # dict_values类型
print(list(values))
print('-------------- 获取所有key-value对 ---------------------')
items = score.items()
print(items)
print(type(items)) # dict_items类型
print(list(items)) # 列表中有三个元素,每个元素为一个元组
# 元组将在下一章节讲解
输出:
---------------- 获取所有keys ---------------------
dict_keys(['zhangsan', 'lisi', 'wangwu'])
<class 'dict_keys'>
['zhangsan', 'lisi', 'wangwu']
---------------- 获取所有values ---------------------
dict_values([100, 98, 45])
<class 'dict_values'>
[100, 98, 45]
-------------- 获取所有key-value对 ---------------------
dict_items([('zhangsan', 100), ('lisi', 98), ('wangwu', 45)])
<class 'dict_items'>
[('zhangsan', 100), ('lisi', 98), ('wangwu', 45)]
3.4字典元素的遍历
直接上代码:
score = {'zhangsan': 100, 'lisi': 99, 'wangwu': 45}
for item in score:
print(item, score[item], score.get(item))
# item存的是字典中的键
输出:
zhangsan 100 100
lisi 99 99
wangwu 45 45
4.字典的特点
1.字典中的所有元素都是一个key-value对,key不允许重复,value可以重复:
"""key不允许重复"""
d = {'name': 'zhangsan', 'name': 'lisi'}
print(d) # 会发生值的覆盖现象
"""value可以重复"""
print()
d = {'name': 'zhangsan', 'nikename': 'zhangsan'}
print(d) # 值可以重复
输出:
{'name': 'lisi'}
{'name': 'zhangsan', 'nikename': 'zhangsan'}
2.字典中的元素是无序的:
字典当中元素的位置是通过值计算出来的,不是人来决定的,所以字典元素是无序的,不能像列表一样在指定位置插入元素。
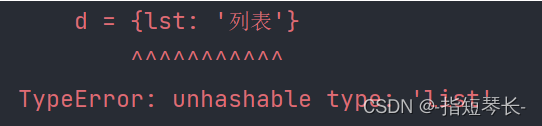
3.字典中的key必须是不可变对象:
"""字典中的key必须是不可变对象"""
lst = [1, 2, 4]
d = {lst: '列表'}
# 直接报错
字典也可以根据需要动态地伸缩;字典会浪费较大的内存,是一种使用空间换取时间的数据结构,查询速度快。
5.字典生成式
1.基本思想:
用列表生成字典。来看一个需求:

2.内置函数zip()
1)功能:将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表。
2)使用:

"""zip的使用"""
items = ['zhangsan', 'lisi', 'wangwu']
values = [20, 89, 100]
lst = zip(items, values)
print(lst)
print(type(lst))
print(list(lst))
输出:
<zip object at 0x000001AA349E4840>
<class 'zip'>
[('zhangsan', 20), ('lisi', 89), ('wangwu', 100)]
3.字典生成式:(图例中的生成式适用于1中的需求)

items = ['Fruits', 'Book', 'Others']
prices = [96, 78, 85]
record = {item.upper(): value for item, value in zip(items, prices)}
print(record)
输出:
{'FRUITS': 96, 'BOOK': 78, 'OTHERS': 85}
现在来解释一下这个生成式,item和value是我们自定义的两个变量,item表示键,value表示值。其中利用了一个for循环,表示item和value的值是从in后的迭代对象中取来的。item.upper(): value就表示键值对,其中:两边是关于item和value的表达式。上面例子中item.upper()的作用就是将所有字母全部变成大写字母。
- 如果两个列表元素个数不相等,会怎么样?
"""两个列表元素数目不等"""
items = ['zhangsan', 'lisi', 'wangwu']
values = [20, 89, 100, 22, 98]
score = {item: value for item, value in zip(items, values)}
print(score)
输出:
{'zhangsan': 20, 'lisi': 89, 'wangwu': 100}
结论:以元素数目少的那个列表为基准。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!