Keras实现seq2seq
2024-01-09 08:45:28
概述? ? ??
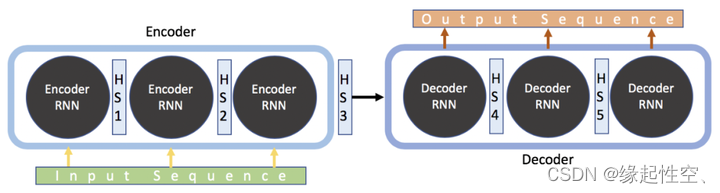
? ? ? ? ? Seq2Seq是一种深度学习模型,主要用于处理序列到序列的转换问题,如机器翻译、对话生成等。该模型主要由两个循环神经网络(RNN)组成,一个是编码器(Encoder),另一个是解码器(Decoder)。
? ? ? ? Seq2Seq被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
工作原理
- 编码阶段:输入一个序列,使用RNN(Encoder)将每个输入元素转换为一个固定长度的向量,然后将这些向量连接起来形成一个上下文向量(context vector),用于表示输入序列的整体信息。
- 转换阶段:将上下文向量传递给另一个RNN(Decoder),在每个时间步,根据当前的上下文向量和上一个输出生成一个新的输出,直到生成一个特殊的结束符号,表示序列的结束。
- 训练阶段:根据目标序列和生成的输出之间的差异计算损失,并使用反向传播算法优化模型的参数,以减小损失。
- 预测或生成阶段:使用训练好的模型根据输入序列生成目标序列。
示例?
# 导入所需的库
import numpy as np
from keras.models import Model
from keras.layers import Input, LSTM, Dense
# 定义输入序列的长度和输出序列的长度
input_seq_length = 10
output_seq_length = 10
# 定义输入序列的维度
input_dim = 28
# 定义LSTM层的单元数
lstm_units = 128
#定义编码器模型
#定义编码器的输入层,形状为(None, input_dim),表示可变长度的序列
encoder_inputs = Input(shape=(None, input_dim))
#定义一个LSTM层,单元数为lstm_units,返回状态信息
encoder = LSTM(lstm_units, return_state=True)
#将编码器的输入传递给LSTM层,得到输出和状态信息
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
#将状态信息存储在列表中
encoder_states = [state_h, state_c]
#定义解码器模型
#定义解码器的输入层,形状为(None, input_dim),表示可变长度的序列
decoder_inputs = Input(shape=(None, input_dim))
#定义一个LSTM层,单元数为lstm_units,返回序列信息和状态信息
decoder_lstm = LSTM(lstm_units, return_sequences=True, return_state=True)
#将解码器的输入和编码器的状态传递给LSTM层,得到输出和状态信息
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
#定义一个全连接层,输出维度为input_dim,激活函数为softmax
decoder_dense = Dense(input_dim, activation='softmax')
#将LSTM层的输出传递给全连接层,得到最终的输出
decoder_outputs = decoder_dense(decoder_outputs)
# 定义seq2seq模型,输入为编码器和解码器的输入,输出为解码器的输出
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 编译模型,使用RMSProp优化器和分类交叉熵损失函数进行编译
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# 打印模型结构
model.summary()模型结构?
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None, 28)] 0 []
input_2 (InputLayer) [(None, None, 28)] 0 []
lstm (LSTM) [(None, 128), 80384 ['input_1[0][0]']
(None, 128),
(None, 128)]
lstm_1 (LSTM) [(None, None, 128), 80384 ['input_2[0][0]',
(None, 128), 'lstm[0][1]',
(None, 128)] 'lstm[0][2]']
dense (Dense) (None, None, 28) 3612 ['lstm_1[0][0]']
==================================================================================================
Total params: 164380 (642.11 KB)
Trainable params: 164380 (642.11 KB)
Non-trainable params: 0 (0.00 Byte)? ? ? ? ?
? ? ? 在以上示例代码中首先导入了所需的库和模块,包括Keras中的Model、Input、LSTM和Dense。然后定义了输入维度,包括词汇表大小和序列最大长度。接下来分别定义了编码器和解码器模型。编码器模型使用LSTM层作为主要结构,输出维度为128;解码器模型同样使用LSTM层作为主要结构,输出维度为词汇表大小,并使用softmax激活函数。最后,通过将编码器和解码器模型组合起来构建了Seq2Seq模型。在构建完Seq2Seq模型后,使用compile方法对模型进行编译,设置了损失函数为分类交叉熵,优化器为Adam,评估指标为准确率。最后一行代码是训练示例,实际使用时需要根据具体的训练数据和训练过程进行设置。
文章来源:https://blog.csdn.net/lymake/article/details/135418923
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!