Prometheus-Alertmanage钉钉实现告警
获取钉钉的webhook地址
1、注册企业钉钉
a、注册企业钉钉
浏览器打开钉钉注册页面 填入手机号码,填入获取到的验证码,点注册

填入企业资料并注册
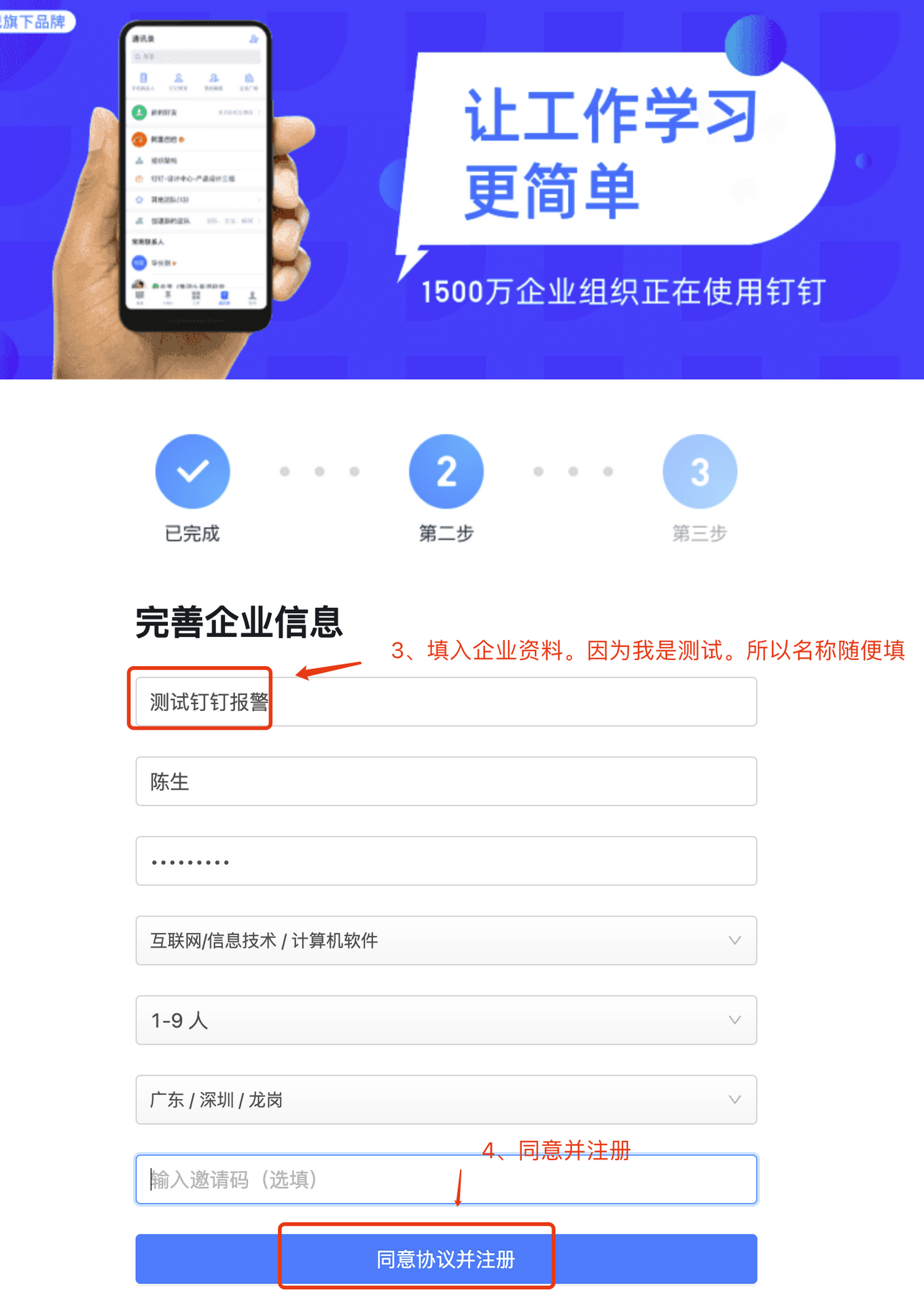
注册成功后,扫描二维码下载钉钉,如下图:

b、添加机器人
管理后台
因为机器人添加,只能是钉钉电脑版(手机版钉钉不能添加机器人)。“测试钉钉报警“ 这个企业只有我一个人,所以我就把报警消息发到默认的 ”测试钉钉报警 全员群“ 里面。实际使用时,请创建个运维群--添加对应的人员进来。
电脑钉钉登陆成功后----点击左下角的。。。---然后再点管理后台,如下图:

选择管理的组织,点击之前创建的企业名

点通讯录--组织架构--添加子部门
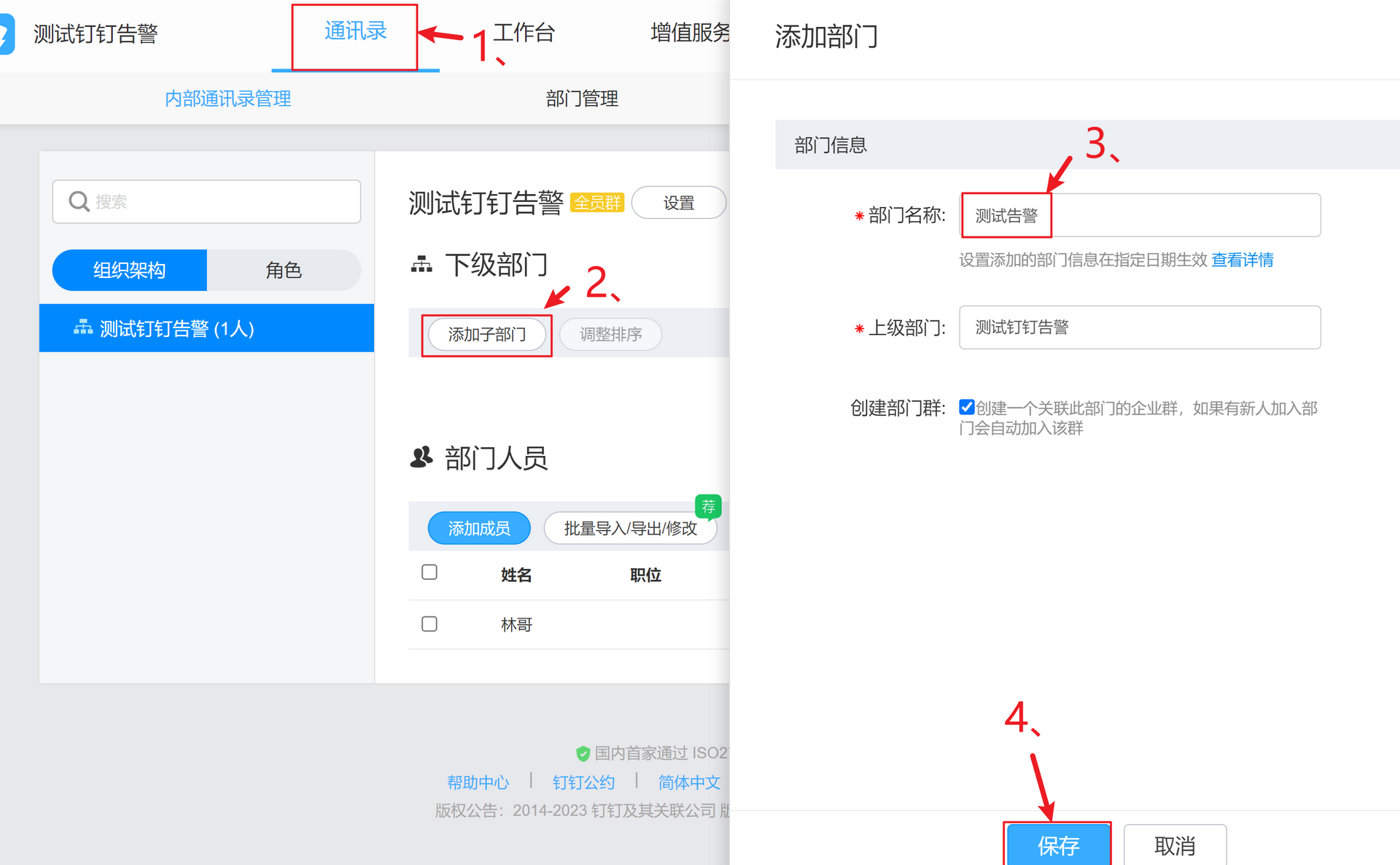
调整部门添加接收告警员工
刷新后,把接收告警的员工调整到刚刚添加的部门

添加告警部门

设置群消息机器人
添加成功后,电脑钉钉消息窗口--会弹出一个测试告警的群--点击这个群---群设置--机器人


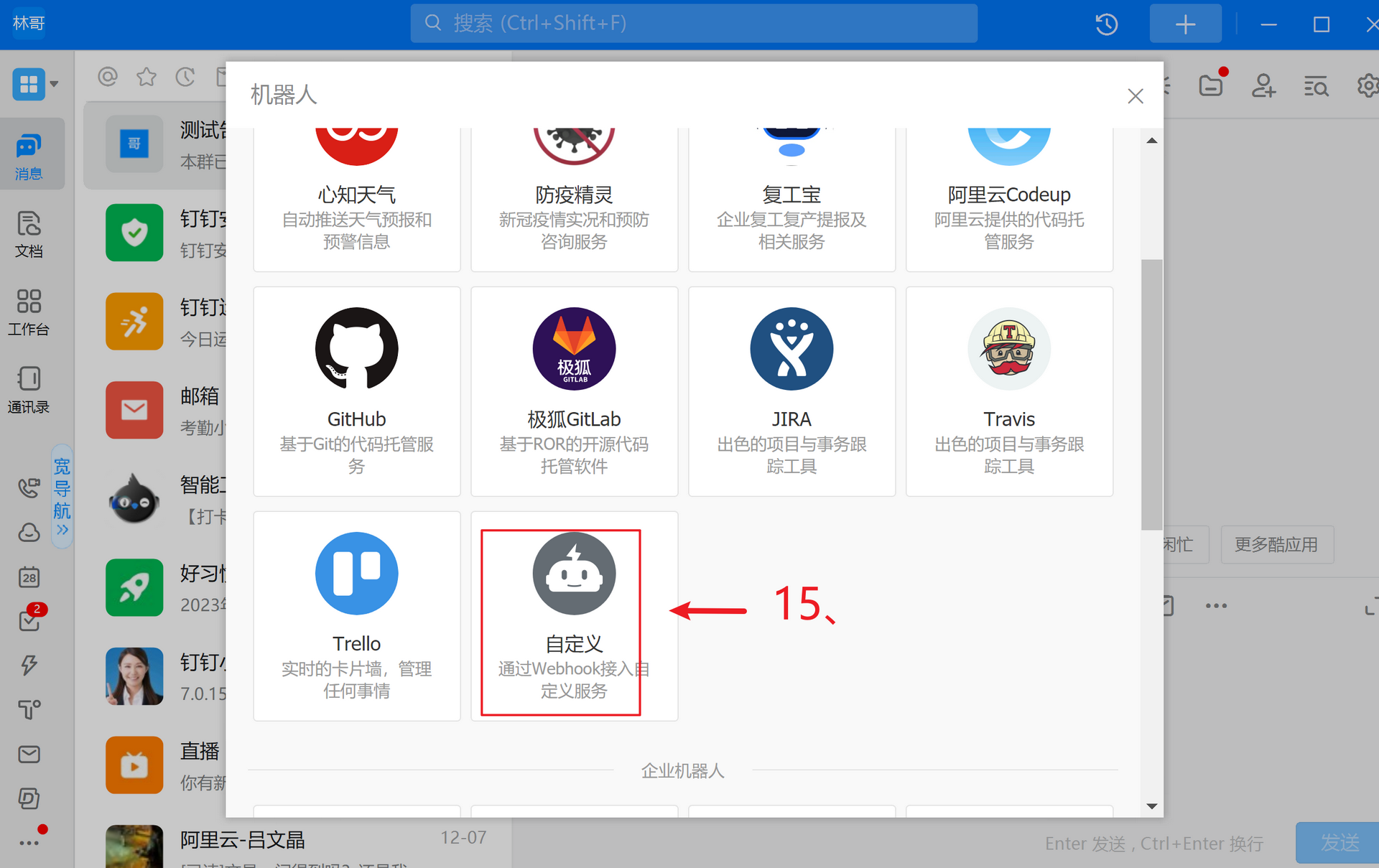
添加机器人

选择机器人类型--点自定义
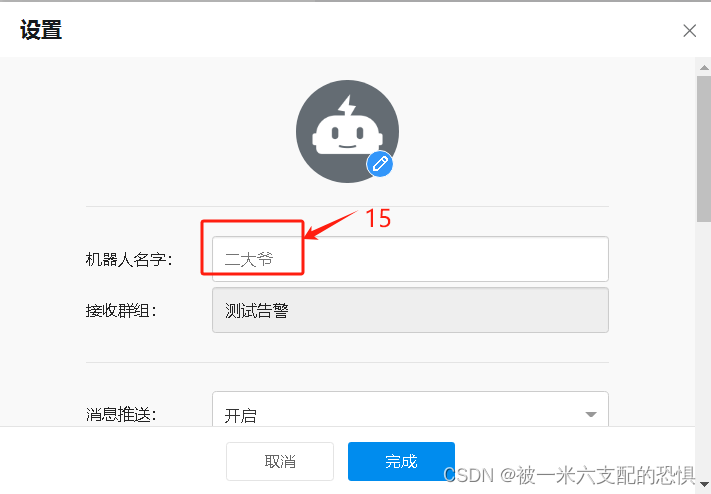
机器人名字:随意
勾选ip:填入alertmanager外网ip
检查发送告警的服务器的ip地址
如果在自己电脑上测试钉钉告警,获取Alertmanager外网ip地址的方法为浏览器打开http://ip138.com 您的iP地址是:[xxx.xx.xx.xx]得到自己外网ip地址。
c、复制机器人webhook地址(触发地址)
复制加签(可以理解成一个秘钥)

添加告警主机地址段信息

复制webhook的地址,例如:
https://oapi.dingtalk.com/robot/send?access_token=2ac0682516aa8634f3410c08339d21f7effeec5ac180eec60082a3ca66661f
我们真实需要的是access_token=后面的,如下:
2ac0682516aa8634f3410c08339d21f7effeec5ac180eec60082a3ca66661f
复制加签备用
SEC85684de209427ba29a4d20541e86b62520068ffb3fef2dfca91af2485627c
-----------------------------------------------至此钉钉端设置完成---------------------------------------------
设置服务器端
创建prometheus-webhook-dingtalk 目录用于存放docker-compose文件以及config.yml配置文件
?创建目录
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$mkdir -p /zpf/k8s/prometheus/prometheus-webhook-dingtalk
创建config.yml配置文件
(这个配置文件是向钉钉发起webhook请求使用的)?
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$vim config.yml
#templates:
# - /etc/prometheus-webhook-dingtalk/templates/default.tmpl
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=aa06a9c58dfa03080c46cd243f3e81560e43d66da434d0a84ecbe2954bc58c
secret: SEC85684de209427ba29a4d20541e86b62520068ffb3fef2dfca91af2485627c3
# message:
# text: '{{ template "default.content" . }}'
?创建dockercompose文件
用于单机启动prometheus-webhook-dingtalk
#创建dockercompose文件用于单机启动prometheus-webhook-dingtalk
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$cat docker-compose.yml
version: '3.3'
services:
webhook:
image: timonwong/prometheus-webhook-dingtalk:v2.1.0 #指定镜像文件
container_name: prometheus-webhook-dingtalk #容器名称
restart: "always" #失败后重启形式
ports:
- 8060:8060 #对外暴漏端口
command:
- '--config.file=/etc/prometheus-webhook-dingtalk/config.yml' #指定配置文件
volumes:
- ./config.yml:/etc/prometheus-webhook-dingtalk/config.yml #挂载宿主机配置文件
- /etc/localtime:/etc/localtime:ro #同步主机时间启动docker-compose
#启动prometheus-webhook-dingtalk
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$docker-compose up -d
Creating network "prometheus-webhook-dingtalk_default" with the default driver
Creating prometheus-webhook-dingtalk ... done
检查容器进程
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$docker ps |grep 8060
12d9be31dc1a timonwong/prometheus-webhook-dingtalk:v2.1.0 "/bin/prometheus-web…" About a minute ago Up About a minute 0.0.0.0:8060->8060/tcp, :::8060->8060/tcp prometheus-webhook-dingtalk
检查端口
#检查端口
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$netstat -lntup|grep 8060
tcp 0 0 0.0.0.0:8060 0.0.0.0:* LISTEN 99842/docker-proxy
tcp6 0 0 :::8060 :::* LISTEN 99847/docker-proxy检查日志
[root@node1-prome /zpf/k8s/prometheus/prometheus-webhook-dingtalk]$docker logs -f 12d9be31dc1a
ts=2024-01-05T07:03:48.953Z caller=main.go:59 level=info msg="Starting prometheus-webhook-dingtalk" version="(version=2.1.0, branch=HEAD, revision=8580d1395f59490682fb2798136266bdb3005ab4)"
ts=2024-01-05T07:03:48.953Z caller=main.go:60 level=info msg="Build context" (gogo1.18.1,userroot@177bd003ba4d,date20220421-08:19:05)=(MISSING)
ts=2024-01-05T07:03:48.953Z caller=coordinator.go:83 level=info component=configuration file=/etc/prometheus-webhook-dingtalk/config.yml msg="Loading configuration file"
ts=2024-01-05T07:03:48.953Z caller=coordinator.go:91 level=info component=configuration file=/etc/prometheus-webhook-dingtalk/config.yml msg="Completed loading of configuration file"
ts=2024-01-05T07:03:48.953Z caller=main.go:97 level=info component=configuration msg="Loading templates" templates=
ts=2024-01-05T07:03:48.954Z caller=main.go:113 component=configuration msg="Webhook urls for prometheus alertmanager" urls=http://localhost:8060/dingtalk/webhook1/send
ts=2024-01-05T07:03:48.954Z caller=web.go:208 level=info component=web msg="Start listening for connections" address=:8060
正常启动.
配置Alertmanage
配置Alertmanage调用timonwong/prometheus-webhook-dingtalk服务向钉钉发送报警信息
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus/alertmanager]$cat config.yml
global:
route:
group_by: ['warn']
# 当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去
group_wait: 10s
# 如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待group_interval配置的时间才可以发送出去
group_interval: 10s
# 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval配置的时间再次发送告警数据
repeat_interval: 10m
# 全局报警组,这个参数是必选的
receiver: 'dingtalk'
receivers:
- name: "dingtalk" #报警组名称
webhook_configs:
- url: 'http://192.168.75.41:8060/dingtalk/webhook1/send' 这里配置的是timonwong/prometheus-webhook-dingtalk 暴漏的服务地址(就是刚刚启动的容器端口+路径地址)
send_resolved: true #貌似是当这个告警解除了会发送一个告警通知
inhibit_rules: #告警抑制规则(这个有点绕详情后续整明白了再补上)
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
?reload一下Alertmanage,加载配置
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus/prometheus]$curl -X POST http://localhost:9093/-/reload测试
这里手动开启告警将原来的正常值修改成触发告警的值
prometheus配置文件
# 全局配置
global:
scrape_interval: 15s # 将搜刮间隔设置为每15秒一次。默认是每1分钟一次。
evaluation_interval: 15s # 每15秒评估一次规则。默认是每1分钟一次。
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
# 报警(触发器)配置
rule_files:
- "alert.yml"
- "rules/*.yml"
# 搜刮配置
scrape_configs:
- job_name: 'prometheus'
# 覆盖全局默认值,每15秒从该作业中刮取一次目标
scrape_interval: 15s
static_configs:
- targets: ['192.168.75.41:9090']
- job_name: 'alertmanager'
# 覆盖全局默认值,每15秒从该作业中刮取一次目标
scrape_interval: 15s
static_configs:
- targets: ['alertmanager:9093']
alertmanage配置文件:
groups:
- name: node-exporter
rules:
- alert: HostOutOfMemory
# expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 > 10
for: 1m
labels:
severity: warning
annotations:
summary: "主机内存不足,实例:{{ $labels.instance }}"
# description: "内存可用率<10%,当前值:{{ $value }}"
description: "内存可用率>10%,当前值:{{ $value }}"
reload一下Prometheus加载配置
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus/prometheus]$curl -X POST http://localhost:9090/-/reload查看prometheus监控数据报警情况
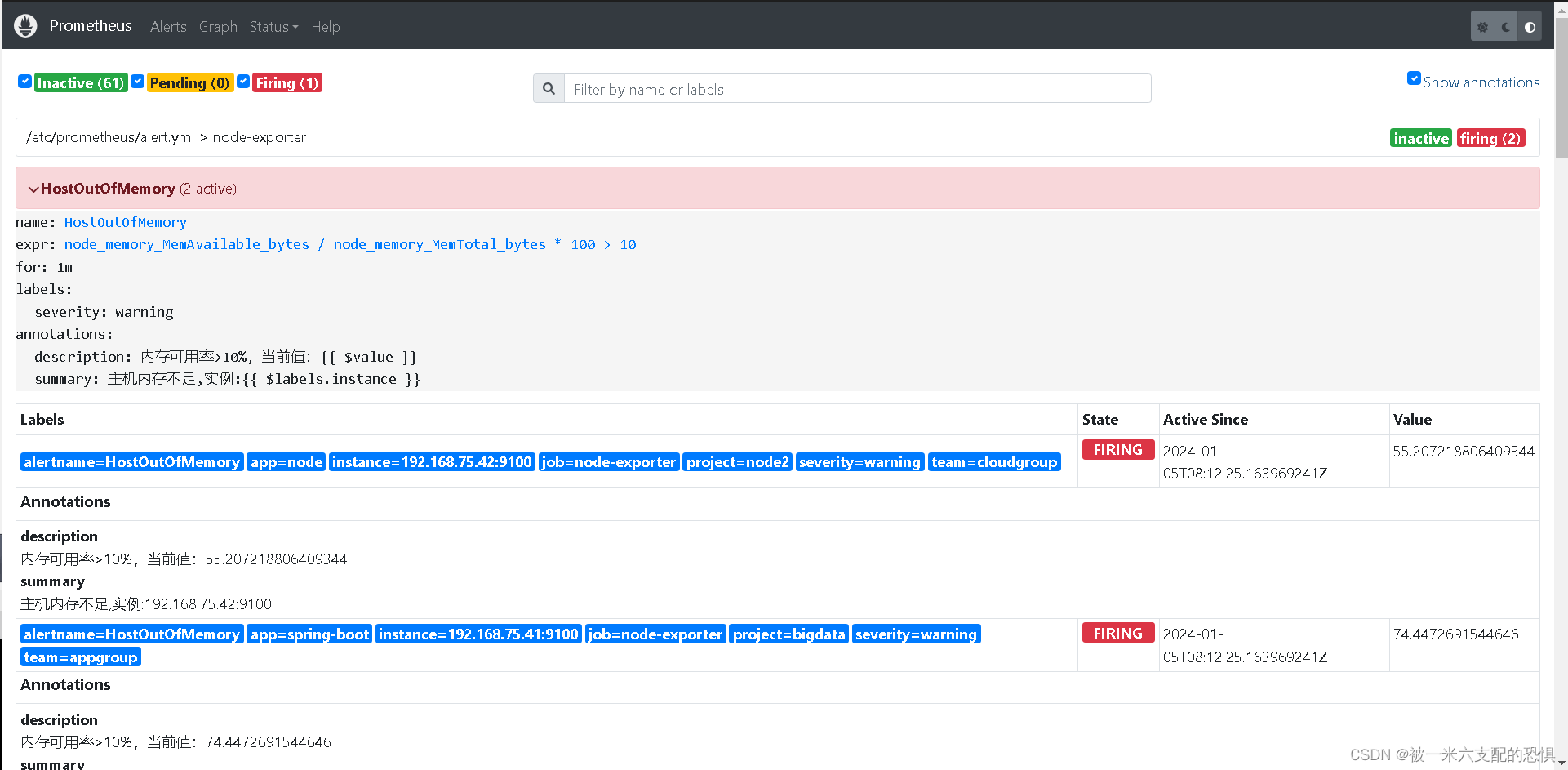
?查看alertmanage报警情况
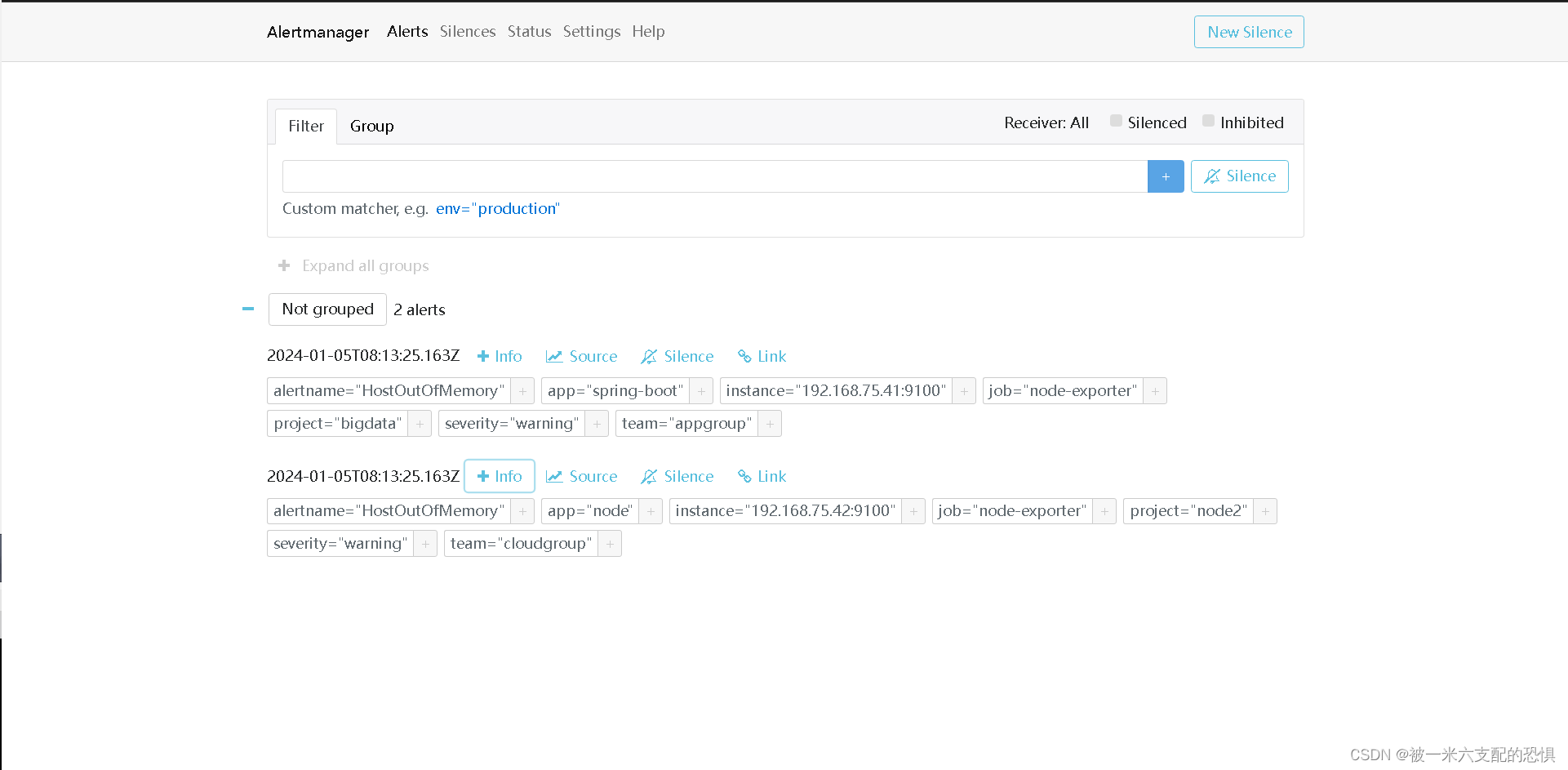
查看钉钉机器人告警
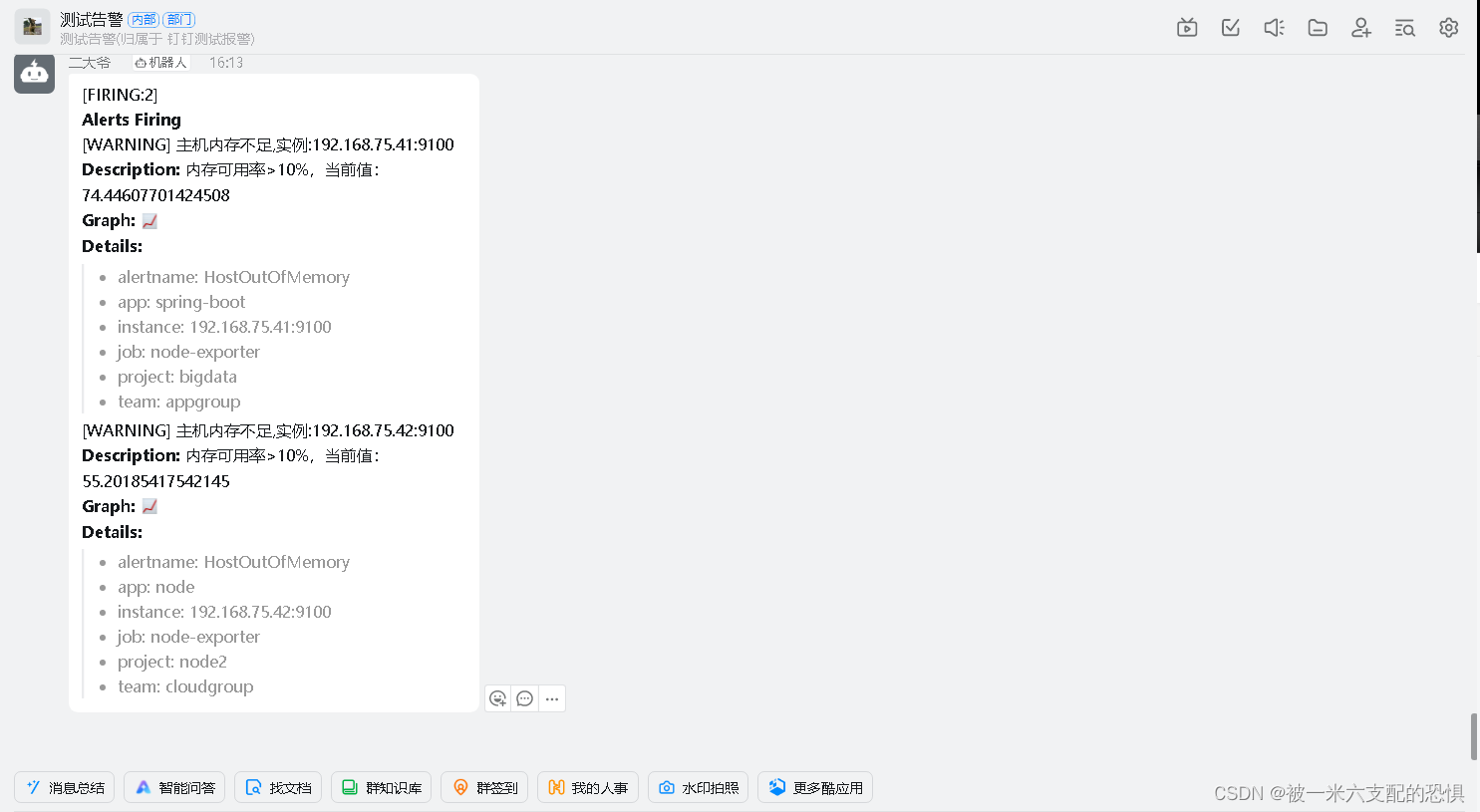
至此钉钉告警配置成功
撒花撒花!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!