数字助听器如何处理声音?
数字助听器如何处理声音?

助听器的作用不仅仅是放大声音。为了创建可改进语音识别的自定义声音配置文件,他们以多种方式处理声音。
麦克风
与人耳一样,数字助听器不直接处理声波。首先是麦克风。它们充当换能器,捕获机械波能并将其转换为电能。
现代助听器配有两个麦克风:
1.全向麦克风可拾取来自任何方向的声音。
2.定向麦克风针对来自佩戴者前方的声音;它的主要重点是捕捉语音。
指向性麦克风可以是固定的,也可以是自适应的。自适应指向性麦克风可以根据需要打开或关闭。打开后,它会根据聆听环境在不同的定向麦克风算法之间自动切换。
模数转换
来自麦克风的模拟信号被转换为数字信号 (A/D)。二进制信号经过数字信号处理 (DSP)。然后将处理后的数字信号转换回声音信号 (D/A),通过接收器进入耳道。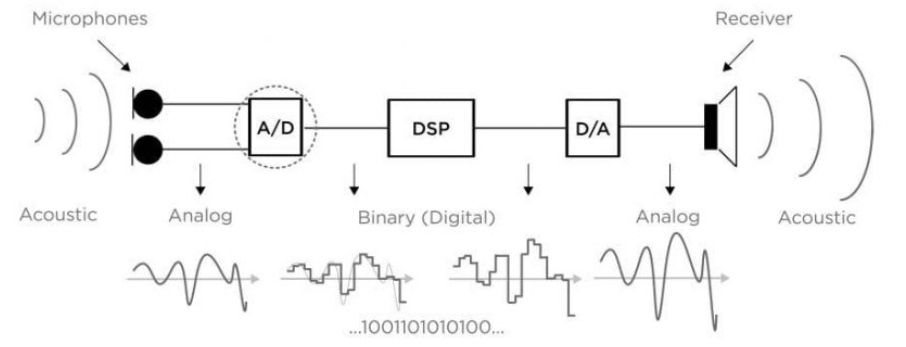
在这些转换过程中,很多事情都可能出错。听证会审查指出:
如果不仔细设计,这种(转换)过程可能会引入噪声和失真,最终会影响助听器的性能。
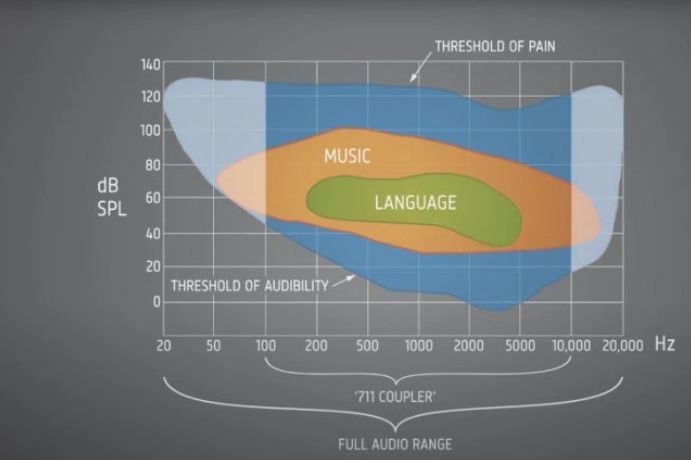
A/D转换的一个关键问题是其有限的动态范围。人类平均听觉的动态范围为140dB,帮助我们听到从沙沙作响的树叶(0dB)到烟花(140dB)的任何声音。仍然常见的 16 位 A/D 转换器被限制在 96dB 的动态范围内,与 CD 一样,动态范围可能在 36-132dB 之间。虽然提高下限可以消除柔和的声音,例如在 30dB 时窃窃私语,但降低上限会在嘈杂的环境中产生较差的音质。
无法通过转换器的声音无法放大。
放大和频率压缩
放大是助听器的一项关键功能,而且很微妙。
一般来说,听力损失会降低个人的动态范围,通常低至 50dB。这缩小了声音需要压缩到的范围,以保持可听性,但听起来舒适。
然线性放大会使柔和的声音更响亮,理想情况下是可听见的,但它也会使响亮的声音不舒服甚至痛苦。因此,大多数助听器使用宽动态范围压缩 (WDRC)。这种压缩方法强烈地放大了柔和的声音,只对中等声音应用了适度的放大,并且几乎不会使响亮的声音变得更响亮。
频道和频段
现代助听器根据佩戴者的听力损失来处理声音。为此,他们将频率分成多个通道,从三个到40多个不等。每个通道覆盖不同的频率范围,并分别进行分析和处理。
虽然通道决定了处理,但频段控制不同频率的音量或增益。大多数现代助听器至少有十几个频段可以放大。这类似于耳机或扬声器均衡器,您可以在其中手动提高特定频率范围的电平,例如,增强低音。
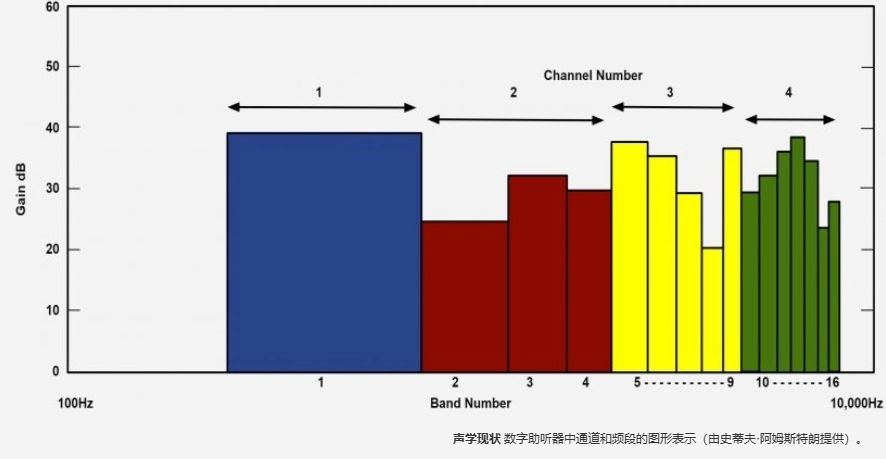
拥有更多通道和频段的好处是增加了微调。助听器可以更好地将语音与背景噪音分开,抵消反馈,减少噪音,并将不同频率的音量和压缩与佩戴者的特定需求相匹配。
拥有额外通道的缺点是处理时间较长。对于没有助听器仍然可以听到环境声音的人来说,这可能是一个问题。研究表明,三到六毫秒的处理延迟会被视为音质下降。
那么,在通道级别会发生什么样的处理呢?
针对不同环境的自定义程序和人工智能
没有一种助听器设置适合所有场合。当您在家听安静的音乐时,您需要与在嘈杂的环境中与朋友外出时不同的处理。为了解决这个问题,大多数助听器都带有不同的程序,可让您从默认程序切换到音乐友好处理或更积极地消除背景噪音。
虽然您的听力保健提供者可以根据您的听力定制这些程序,但它们只能涵盖有限数量的场景。由于您将处于一个安静的环境中进行助听器验配,因此他们必须猜测您对不同声音场景的偏好。这就是人工智能 (AI) 的用武之地。

人工智能配备了机器学习能力,可以了解不同的环境,利用其他用户的数据,预测你认为最愉快的设置,并自动调整其处理。
频率偏移和降低可提高语音识别能力
我们已经确定助听器无法恢复正常听力,因为它们无法修复损坏的东西。他们的主要任务是通过使用剩余的听力能力来恢复语音识别。但是,当听力损失影响覆盖言语的频率时会发生什么?

在非声调(西方)语言中,语音清晰度的关键频率范围为 125-8,000Hz。这是标准听力测试和助听器所覆盖的确切带宽。请记住,人类的听力可以达到 20,000Hz,中年人通常为 17,000Hz。
当听力损失非常严重,以至于影响到低于 8,000Hz 的频率时,助听器可以将这些高频声音转移到较低频段。不幸的是,以这种方式转调声音会产生伪影。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!