大数据技术架构
2024-01-07 21:55:51
1 技术架构矩阵
大数据技术栈虽然比较多,但可以抽象为输入(数据接入)--处理(数据处理、数据分析)--输出(数据应用)。工作角色分工,数据处理以数据仓库开发人员为主,数据分析以数据分析师为主,其他所有组件、系统、技术相关归为数据平台。
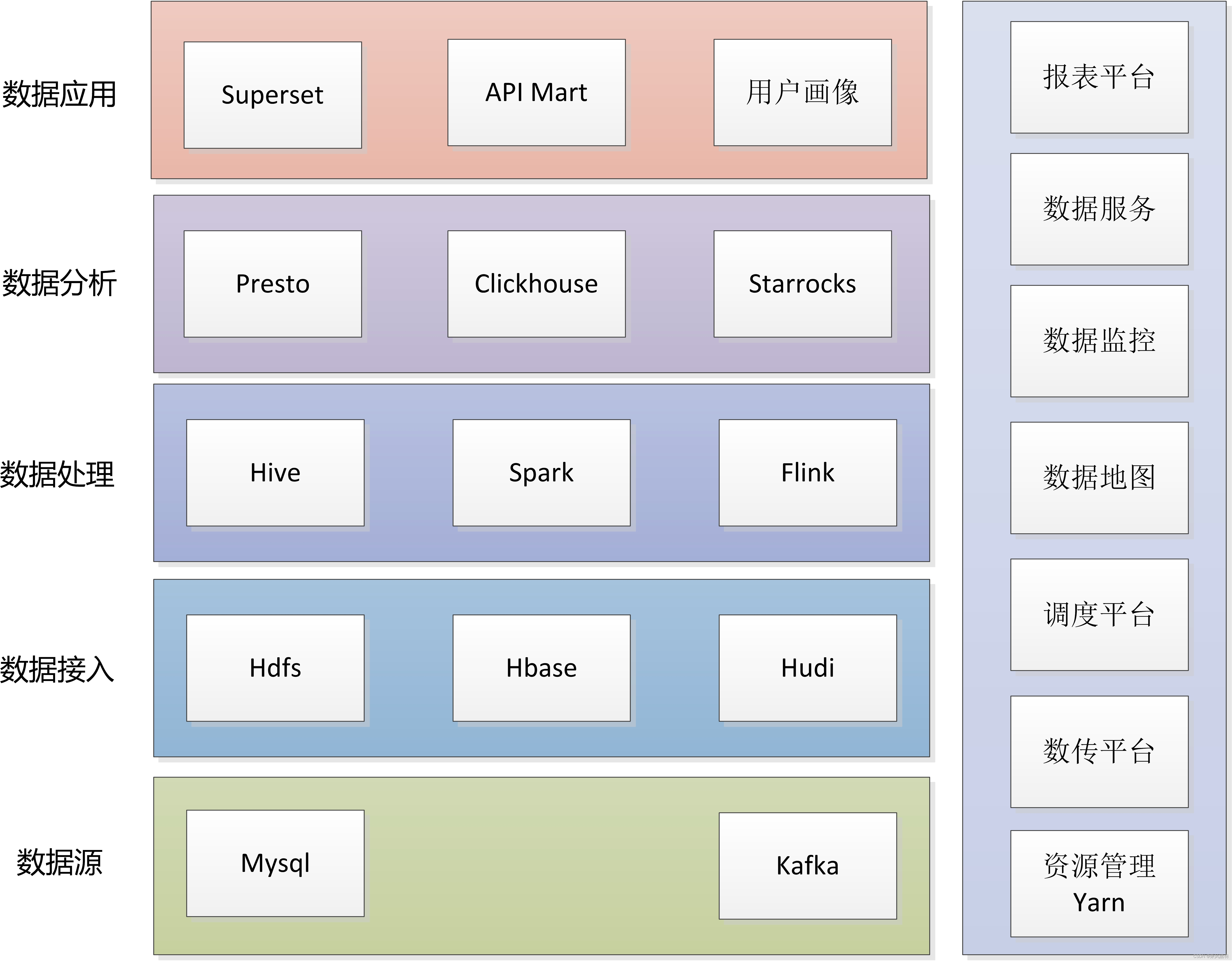
2 数据源
大数据的数据来源虽然多,但不杂。
mysql是业务主流数据库,支持整表同步和binlog实时同步。整表同步数据量大,一般是数仓T+1方式同步,保证数据一条不丢;还有做到H+2近实时同步。binlog通过canal收集发送到kafka,用于实时数仓计算。
kafka用于同步消息中间件,一般是mysql binlog和埋点日志数据。埋点日志数据量非常大,比如APP的所有曝光、点击行为数据,收集之后用于实时推荐系统,实时推荐模型交互推荐和用户最相关的列表内容。
除此之外,有人会问,是否还有日志文件数据,这些数据一般都会转化为kafka消息,kafka消息统一收集。但凡是json数据都可以转为字符串消息发送到kafka收集。
3 数据接入
数据接入这一层任务量非常大,离线方面,每个表每天0点都到同步数据中心。实时方面则根据消息格式自动生成入库表结构,一直运行。这里需要使用数传平台工具化配置提升效率。
mysql数据最终会落入hive表存储在hdfs上,按天生成hive表分区。对于近实时数据?
文章来源:https://blog.csdn.net/funy88/article/details/135442923
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!