无脑019——MTMC代码复现 AI CITY CHALLENGE 2023 TRACK 1 TOP1 UWIPL_ERTI
参考官网:
https://github.com/ipl-uw/AIC23_Track1_UWIPL_ETRI
下载code到这个文件夹下:
AIC23_Track1_UWIPL_ETRI-main
准备好100GB左右的硬盘空间,配置环境1天,代码运行1天,时间大概两天
1. conda 环境
创建环境,
注意,这个项目的环境,
既可以是一个conda环境,例如跟我一样,uwipl_etri,
也可以是相互独立的,比如mmyolo一个,mmpose一个,bot-sort一个
我这里比较懒,使用了一个
conda create -n uwipl_etri python==3.8
conda activate uwipl_etri
总共需要4个框架:
Installation for mmyolo*
Installation for mmpose
Installation for torchreid*
Installation for BoT-SORT
注意:咱们复现跑它的代码,这些环境不一定全部用上,但是最好全部安装,方便以后大家理解。其实也可以需要哪一部分就安装哪一部分,例如我只是学习,只安装BoT-SORT部分就可以了,就能使用它提供的初始模型,实现他们的效果。
1.1. mmyolo
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
pip install openmim
mim install "mmengine>=0.6.0"
mim install "mmcv>=2.0.0rc4,<2.1.0"
mim install "mmdet>=3.0.0,<4.0.0"
#git clone https://github.com/open-mmlab/mmyolo.git
cd G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main
# Install albumentations
pip install -r requirements/albu.txt
# Install MMYOLO
mim install -v -e .
这个时候应该已经安装完成了,为了验证安装是否成功,可以进行如下测试:
mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
python demo/image_demo.py demo/demo.jpg yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
# Optional parameters
# --out-dir ./output *The detection results are output to the specified directory. When args have action --show, the script do not save results. Default: ./output
# --device cuda:0 *The computing resources used, including cuda and cpu. Default: cuda:0
# --show *Display the results on the screen. Default: False
# --score-thr 0.3 *Confidence threshold. Default: 0.3
如果报错,可以自己去解决,例如我的报错:
ImportError: DLL load failed while importing _imaging: 找不到指定的模块
说明pillow模块安装有问题,重新覆盖安装低版本的pillow
pip install pillow==8.3
报错mmdet等级过高:
AssertionError: MMDetection==3.2.0 is used but incompatible. Please install mmdet>=3.0.0rc6, <3.1.0.
于是重新安装mmde低等级版本
mim install "mmdet==3.0.0rc6"
如果运行成功,会在mmyolo/output文件夹下产出一张图片,就是一张椅子的预测结果
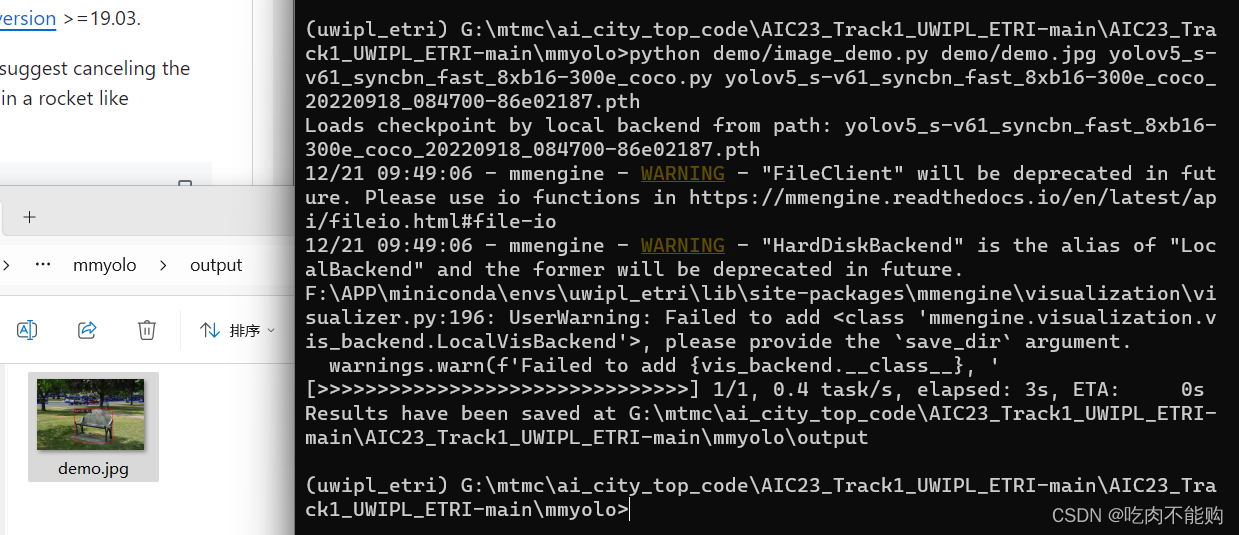
至此,mmyolo安装完成
此刻显示一下我的mim list版本
(uwipl_etri) G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main\mmyolo>mim list
Package Version Source
--------- --------- -----------------------------------------------------------------------------------------
mmcv 2.0.1 https://github.com/open-mmlab/mmcv
mmdet 3.0.0rc6 https://github.com/open-mmlab/mmdetection
mmengine 0.10.1 https://github.com/open-mmlab/mmengine
mmyolo 0.5.0 g:\mtmc\ai_city_top_code\aic23_track1_uwipl_etri-main\aic23_track1_uwipl_etri-main\mmyolo
1.2. mmpose
因为这个团队的代码是单独的conda环境,所以跟我的还不一样,我是一开始不懂可以单独使用,更推荐大家安装单独的环境。
这个团队提供的mmpose版本有点低,不能在一个环境里用,所以我去官网下载的,解压出来mmpose-main
先进入文件夹
cd G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main\mmpose-main>
#git clone https://github.com/open-mmlab/mmpose.git
#cd mmpose
pip install -r requirements.txt
pip install -v -e .
# "-v" means verbose, or more output
# "-e" means installing a project in editable mode,
# thus any local modifications made to the code will take effect without reinstallation.
验证安装是否成功:
python demo/image_demo.py tests/data/coco/000000000785.jpg configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w48_8xb32-210e_coco-256x192.py https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth --out-file vis_results.jpg --draw-heatmap
结果保存到mmpose下的vis_results.jpg

目前安装的版本
(uwipl_etri) G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main\deep-person-reid>mim list
Package Version Source
--------- --------- ----------------------------------------------------------------------------------------------
mmcv 2.0.1 https://github.com/open-mmlab/mmcv
mmdet 3.0.0rc6 https://github.com/open-mmlab/mmdetection
mmengine 0.10.1 https://github.com/open-mmlab/mmengine
mmpose 1.2.0 g:\mtmc\ai_city_top_code\aic23_track1_uwipl_etri-main\aic23_track1_uwipl_etri-main\mmpose-main
mmyolo 0.5.0 g:\mtmc\ai_city_top_code\aic23_track1_uwipl_etri-main\aic23_track1_uwipl_etri-main\mmyolo
1.3. torchreid
直接使用作者提供的安装包:
cd 进入目录
# cd to your preferred directory and clone this repo
#git clone https://github.com/KaiyangZhou/deep-person-reid.git
# create environment
cd G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main\deep-person-reid
#conda create --name torchreid python=3.7
#conda activate torchreid
# install dependencies
# make sure `which python` and `which pip` point to the correct path
pip install -r requirements.txt
# install torch and torchvision (select the proper cuda version to suit your machine)
#conda install pytorch torchvision cudatoolkit=9.0 -c pytorch
# install torchreid (don't need to re-build it if you modify the source code)
python setup.py develop
运行最后一行代码报错:
AttributeError: module 'setuptools._distutils' has no attribute 'version'
覆盖安装
pip install setuptools==59.5.0
然后就可以正常安装了。
这个还不会验证,因为是可选项,先不仔细研究,先把整体模型跑通
1.4. Bot-SORT
因为这个队伍作者的代码已经修改了demo.py文件,无法测试是否安装成功,我更推荐使用BOT-SORT官方的代码来安装,最后只使用比赛队伍的tools文件夹里的内容。
例如我从官网下载代码:
https://github.com/NirAharon/BOT-SORT
解压到BOT-SORT-MAIN文件夹中
cd G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main\BoT-SORT-main
pip install -r requirements.txt
pip install cython
pip install cython_bbox
pip faiss-cpu #因为GPU版本的很麻烦,我直接用的cpu版本的
测试:
从bot-sort官网下载预训练模型到新建的文件夹/
G:\mtmc\ai_city_top_code\AIC23_Track1_UWIPL_ETRI-main\AIC23_Track1_UWIPL_ETRI-main\BoT-SORT-main\pretrained
然后运行我的测试代码:
官网的运行规范
#python tools/demo.py video --path <path_to_video> -f yolox/exps/example/mot/yolox_x_mix_det.py -c pretrained/bytetrack_x_mot17.pth.tar --with-reid --fuse-score --fp16 --fuse --save_result
它的测试
#python tools/demo.py video --path 1.mp4 -f yolox/exps/example/mot/yolox_x_mix_det.py -c pretrained/bytetrack_x_mot17.pth.tar --with-reid --fuse-score --fp16 --fuse --save_result
我的测试
python tools/demo.py video --path 1.mp4 -f yolox/exps/example/mot/yolox_m_mix_det.py -c pretrained/bytetrack_m_mot17.pth.tar --with-reid --fuse-score --fp16 --fuse --save_result
报错:
AttributeError: module 'numpy' has no attribute 'float'
因为numpy版本过高,降级就好了
pip install numpy==1.23
测试结果:
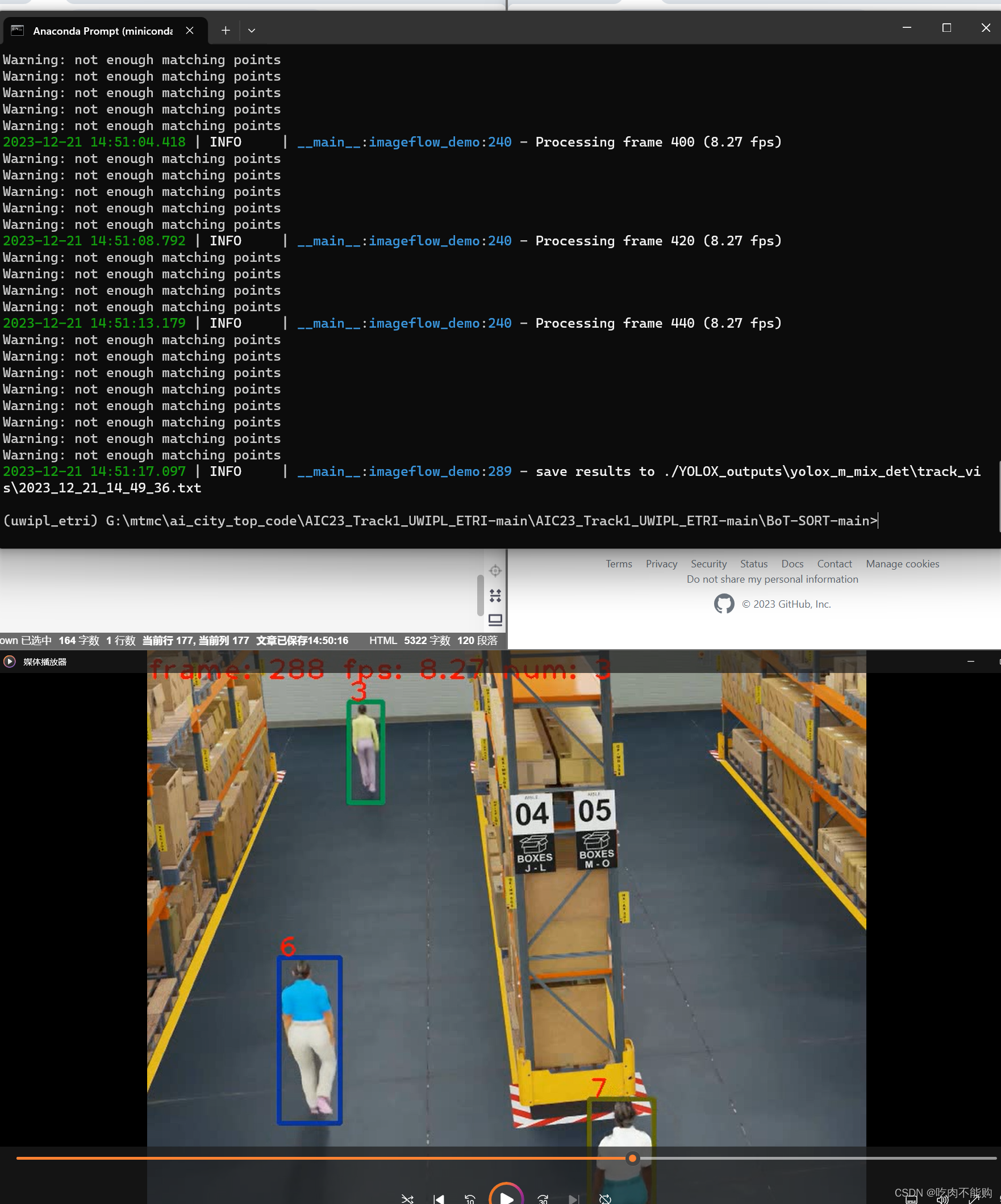
测试成功
2. 该队伍的代码测试
这部分按照它提示的流程进行
https://github.com/ipl-uw/AIC23_Track1_UWIPL_ETRI
可以直接把所需要的npy文件、模型等文件下载好,直接从2.2.3开始
2.1. 训练Training(可跳过)
2.1.1. (可跳过)训练目标检测模型
因为现有的目标检测模型对于真实世界的视频可以检测,但是比赛用的一部分数据是来自合成的数据,也就是NVIDIA 平台的元宇宙的数据,如下图所示,所以要使用yolov7目标检测模型继续训练一个检测人物的模型,来适配合成的数据,也可以跳过,直接使用目标检测的模型即可

2.1.2. (可跳过)训练ReID模型:
ReID模型也是同样的道理,这两部分我都没有训练,我想直接测试
2.2. 推理Inferencing
2.2.1. (可跳过)获取检测结果Get Detection
直接使用文件夹中的txt文件data/test_det
2.2.2. (可跳过)获取嵌入结果Get Embedding
https://drive.google.com/drive/folders/1qbwu37PlFSxmJIBLzJq1L9cAwryahAj7
从这个google云盘下载文件放在data/test_emb
一共11个文件 15GB左右,下载时间不短,
2.2.3. 获取脚点(但是我跳过了)
这部分用于继续优化,效果区别不大,我就没用。
2.2.4. 运行跟踪run_track.py
打开tools/run_tracking.py文件,可以看到他执行了三个命令:
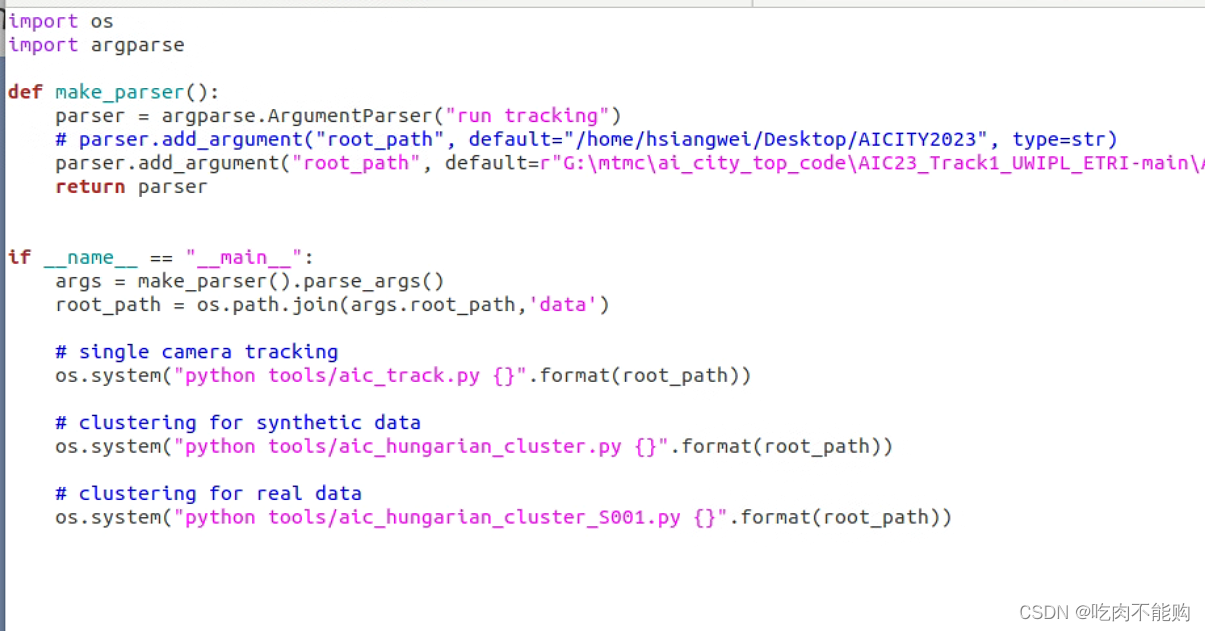
分别是tools/aic_track.py
tools/aic_hungarian_cluster.py
tools/aic_hungarian_cluster_soo1.py
这三个文件,我们拆分来看这三个文件是什么作用。
2.2.4.1. tools/aic_track.py
这段代码是一个目标跟踪系统的实现,主要通过BoT-SORT(Bounding Box Tracker with Single Object Tracker)算法来进行目标跟踪。
该代码的目标跟踪结果保存在两个文件中:
SCT结果文件包含了每帧中检测到的目标的信息,而Tracklet结果文件包含了完整的目标轨迹信息。
SCT(Single Camera Tracking)结果文件:
文件路径:<root_path>/SCT/_.txt
结果格式:每行表示一个检测框的信息,包括帧号、目标ID、左上角坐标、宽度、高度、置信度等信息。
文件里的内容长这样子:

每一行都代表:
frame_id,person_id,x,y,w,h,conf,-1-1-1
帧号、目标ID、左上角坐标、宽度、高度、置信度等信息。注意看,这里有置信度,并且有三个-1
Tracklet结果文件:
文件路径:<root_path>/tracklet/_.pkl
结果格式:一个二进制文件,包含了跟踪轨迹的详细信息,可以使用pickle库进行反序列化。
我没有对这个文件详细了解,大家自行研究。
这个代码,正常运行,从22:17开始,到22:47才只把s001的test的frame处理完,就第一个s001大约4GB,处理的慢,后边比较快,用时40分钟,处理完test文件夹的所有图片,产生SCT和tracklet两个文件夹。

2.2.4.2. tools/aic_hungarian_cluster.py
聚类合成数据,因为我没有加入脚点,所以要修改代码中的enable_feet=False:
_track_file.split('_')[-1][:-4]: load_tracking(_track_file, enable_feet=False) for _track_file in
这段代码的主要目标是对行人进行聚类,以获得每个行人的全局ID,并在后续分析中使用。、结果将被写入 hungarian_cluster 文件夹下
这部分产生的是S003-S022的场景,虽然没有用
2.2.4.3. tools/aic_hungarian_cluster_001.py
这个代码跟上一个差不多,就是生成的是真实数据的,生成的文件在 hungarian_cluster_001 文件夹下
2.2.5. 生成最终结果Generate final submission
cd ../BoT-SORT
python tools/aic_interpolation.py <root_path>
python tools/boundaryrect_removal.py <root_path>
python tools/generate_submission.py <root_path>
这部分其实提升的效果也不多,所以我就没继续研究,大家感兴趣可以自己看。
3. 可视化代码
其实到2.2.4就已经结束了,
这里插一个代码脚本,因为作者的代码中没看见,所以我写一下:来显示聚类后的txt对应视频的显示:
效果如下:

只有人物出现的帧,才会再submission.txt中,
这个代码是使用bot_sort 跟踪算法结果绘制到视频上的,要求你的txt文件中的内容是这样的:
0,4,1219.87,175.98,89.43,243.91,-1,-1,-1,-1
0,3,225.09,163.6,67.81,236.63,-1,-1,-1,-1
2,4,1219.51,173.51,89.41,247.18,-1,-1,-1,-1
2,3,224.97,163.17,67.82,237.36,-1,-1,-1,-1
2,2,361.32,313.33,131.7,448.91,-1,-1,-1,-1
每一行代表着:
frame_id,person_id,x,y,w,h,-1-1-1-1
如果没有人物出现的帧,是不会显示的。
使用下边的代码可以绘制并保存结果,你要自己创建一个output文件夹。
import cv2
import numpy as np
from tqdm import tqdm
def draw_boxes_on_frame(frame, boxes):
for box in boxes:
person_id, x, y, w, h = map(float, box[1:6])
x, y, w, h = int(x), int(y), int(w), int(h)
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Display person_id as text in the top-left corner of the bounding box
text = f'ID: {int(person_id)}'
frame = cv2.putText(frame, text, (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return frame
def process_video(video_path, annotation_path,out_path):
cap = cv2.VideoCapture(video_path)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
with open(annotation_path, 'r') as f:
annotations = [line.strip().split(',') for line in f.readlines()]
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(out_path, fourcc, 30.0, (int(cap.get(3)), int(cap.get(4))))
for i in tqdm(range(total_frames)):
ret, frame = cap.read()
if not ret:
break
frame_boxes = [anno for anno in annotations if int(anno[0]) == i]
if frame_boxes:
frame = draw_boxes_on_frame(frame, frame_boxes)
out.write(frame)
cap.release()
out.release()
if __name__ == "__main__":
video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c001/video.mp4"
annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c001.txt'
out_path = "output/out_S001_C001.mp4"
process_video(video_path, annotation_path,out_path)
video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c002/video.mp4"
annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c002.txt'
out_path = "output/out_S001_C002.mp4"
process_video(video_path, annotation_path, out_path)
video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c003/video.mp4"
annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c003.txt'
out_path = "out_S001_C003.mp4"
process_video(video_path, annotation_path, out_path)
#
# video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c004/video.mp4"
# annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c004.txt'
# out_path = "output/out_S001_C004.mp4"
# process_video(video_path, annotation_path, out_path)
#
video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c005/video.mp4"
annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c005.txt'
out_path = "output/out_S001_C005.mp4"
process_video(video_path, annotation_path, out_path)
video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c007/video.mp4"
annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c007.txt'
out_path = "output/out_S001_C007.mp4"
process_video(video_path, annotation_path, out_path)
video_path = "/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/test/S001/c006/video.mp4"
annotation_path = '/media/dell/t5/ai_city/AIC23_Track1_UWIPL_ETRI-main/data/final_n=15_dist200_pk_filter_margin_2/S001_c006.txt'
out_path = "output/out_S001_C006.mp4"
process_video(video_path, annotation_path, out_path)
祝大家,看的开心,也可以点个赞~👍
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!