【python笔记】并发编程
前言
菜某的笔记总结分享。有错误请指正。
并发编程的意义
并发编程是用来提升代码执行的效率的。
名词理解
进程和线程
我们可以这样理解进程和线程。进程是一个工厂,线程是工厂里的一条流水线。
我们要让我们产品的生产效率提高,我们可以多开工厂(进程),也可以在一个工厂中增加流水线(线程)。
但是开设工厂的成本相对于增加流水线要高。
工厂(进程)给流水线(线程)原料,但是真正操作的是流水线(线程)。
当我们运行一个python文件时,他会创建一个进程,同时配备一个线程。进程储存了数据,线程真正执行代码。
当一个程序拿过来时,我们可以把他分开,一个进程或者线程做一部分,最后把结果总和起来,就实现并发。
多线程
多线程需要threading模块
创建线程并且使用的方法
设置函数创建线程
就是我们设置一个函数,我们可以创建一个线程帮助我们运行这个函数
import threading
def func(a,b,c):#定义一个函数
??? pass
t=threading.Tread(target=func,agrs=(1,2,3))#创建线程
t.start()#开始运行线程
agrs是参数,帮助我们传递函数的参数。
案例
利用多线程快速下载图片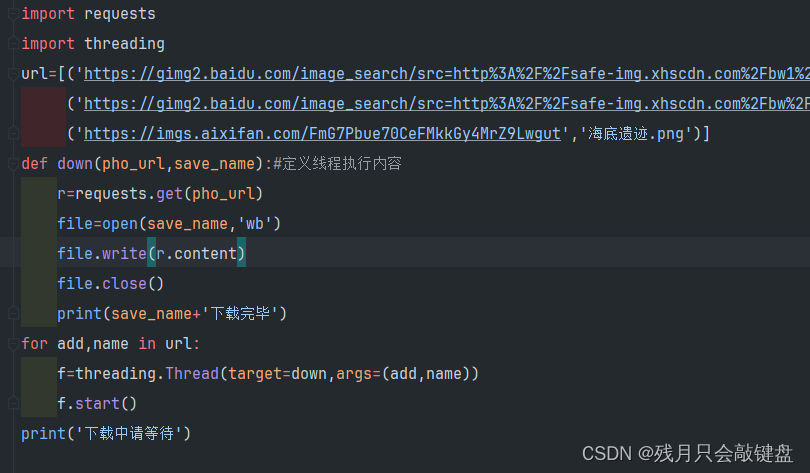
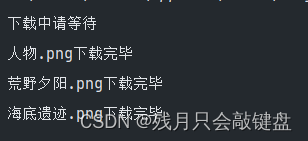
结果下载成功
设置类创建线程
创建一个类,让他继承父类之后,这个类中的run方法就会被执行。

这里定义了两个方法,但是结果会发现,他会发现只有run被执行了。
线程常用的方法
t.start()#开始执行线程
t.join()#主线程等待t线程运行完毕后再运行
t.setDaemon(布尔值)#创建守护进程
布尔值为true,主线程执行完线程自动关闭
false,主线程在线程都执行完毕后才会关闭
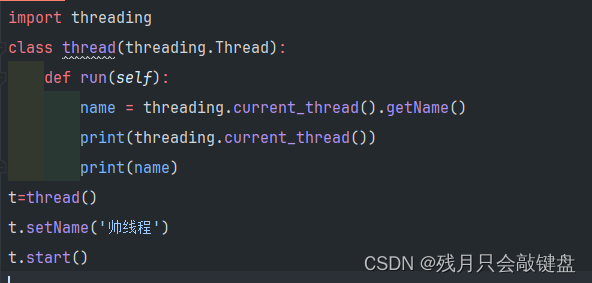
设置获取线程的名称
t.setName()#设置线程的名字
threading.current_thread().getName()#获取当前线程的名字
threading.current_thread()#获取当前运行的线程
案例
线程的名称设置案例
多线程应用可能出现的数据混乱问题
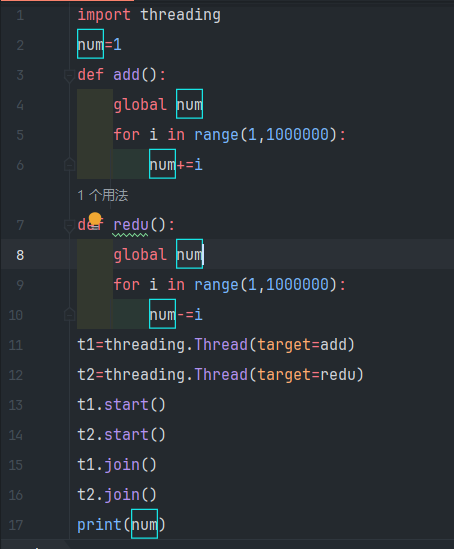
我们用多线程的时候,cpu会被划片的让一个片的线程进入,但是呢cpu是一个线程执行一部分然后再执行另一个线程,之后再回来执行当前的线程。这就会导致一个问题。
比如我们在执行一个大的计算的时候,有时我们一个线程算到一半,cpu去执行另一个线程,而另一个线程也会对原先的数进行操作,于是这个数就变化了,最后得到的结果就不一样了。
如下
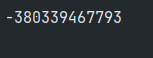
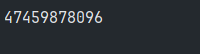
这个程序执行两次后分别得到的结果
线程锁
为了应对那种情况的发生,我们引进了线程锁这个函数,要求cpu只能执行有这把锁的线程,其他线程想要运行,必须要等运行这把锁的线程运行完,下面的线程才能拿到锁并运行。
lock=threading.RLock()#创造同步锁
lock=threading.RLock()#创造递归锁
lock.acquire()#加锁
lock.release()#释放锁
类似案例
import threading
num=1
lock=threading.RLock()
def add():
lock.acquire()
global num
for i in range(1,1000000):
num+=i
lock.release()
def redu():
lock.acquire()
global num
for i in range(1,1000000):
num-=i
lock.release()
t1=threading.Thread(target=add)
t2=threading.Thread(target=redu)
t1.start()
t2.start()
t1.join()
t2.join()
print(num)
类似于药匙,一个旅馆,只有第一个线程拿到药匙才能进入运行,第二个线程想要进去运行就必须要等上一个线程运行完毕,拿到这个药匙再进去运行
结果

同步锁与递归锁的区别
同步锁只能申请锁,解除锁。
这个锁你不能申请两遍。
但是递归锁不同,你可以先申请一遍,没解开的情况下再申请一遍,之后两次解开退出。
死锁现象
有两种死锁
1.lock()锁,申请了两遍,第一次没释放就又申请了一遍,相当于这个线程需要申请这个锁才能往下走,但是呢他自己就拿了这个锁,还没释放,这里就申请不到,而申请不到就无法向下执行,相当于自己不自己卡住
2.两个线程需要两个锁,第一个锁两个不同,第二个锁是对方的第一个锁,但是又没释放,两个就相互卡住了。
多进程
多进程需要使用到multiprocessing这个库
创建进程并且使用的方法
其实说实话,跟创建多线程差不多。
import multiprocessing
def pnt(name):
print("新进程{}帮我打印了这串字符".format(name))
if __name__=="__main__":
f = multiprocessing.Process(target=pnt, args=('打印机',))
f.start()
值得注意的是,创建进程我发现他必须在 if __name__=="__main__":下才能创建,否则报一个错误。
GIL锁
CPU的相关解释
python中,我们通常执行的计算操作是需要CPU的,而我们执行的io操作,比如下载图像视频文件增删呀啥的不怎么太需要CPU的
功能
在cpython解释器中(也就是我们平常用的解释器),当用到CPU时,GIL锁会阻止线程一起进入CPU,它只会允许一个线程进入CPU。但是他不会阻止进程进入CPU。
也就是说,我们执行下载任务,可以一个线程指定一个下载位置,他们都会直接进去网卡。
但是执行大的计算任务的时候,线程就只能一一进入了
对于开发的影响
因此,当我们在执行运算时,尽量使用多进程去操作,比如计算一些大的数据,在执行一些文件操作或者下载的时候,更偏向于使用线程去完成。
实际上,开发起来更加的灵活多变,因为进程是可以包含线程的。我们可以创建一些进程去计算,进程中也可以创建一些线程,去操作与这一部分计算有关的文件或者下载呀什么的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!