【easy-ES使用】1.基础操作:增删改查、批量操作、分词查询、聚合处理。
2023-12-22 14:57:33
easy-es、elasticsearch、分词器 与springboot 结合的代码我这里就不放了,我这里直接是使用代码。
基础准备:
创建实体类:
@Data
// 索引名
@IndexName("test_jc")
public class TestJcES {
// id注解
@IndexId(type = IdType.CUSTOMIZE)
private Long id;
// 如果需要分词查询,必须 FieldType.TEXT analyzer = "ik_max_word" 官网有说明
@IndexField(fieldType = FieldType.TEXT, analyzer = "ik_max_word")
private String name;
// 非分词查询类型 最好用 KEYWORD
@IndexField(fieldType = FieldType.KEYWORD)
private String sex;
/**
* [描述] 如果某字段数组类型,并且该类型后期需要聚合操作,必须 fieldData = true
* FieldType.TEXT:会将数组中的元素 “拆分单字符” 进行聚合
* FieldType.KEYWORD: 会对数组中的元素进行聚合
*/
@IndexField(fieldType = FieldType.TEXT,fieldData = true)
private List<String> industryTags;
@IndexField(fieldType = FieldType.KEYWORD,fieldData = true)
private List<String> productTags;
//时间类型
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss")
private String updateTime;
@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss")
private String createTime;
public TestJcES(Long id,String name, List<String> industryTags, List<String> productTags) {
this.id = id;
this.name = name;
this.industryTags = industryTags;
this.productTags = productTags;
}
}
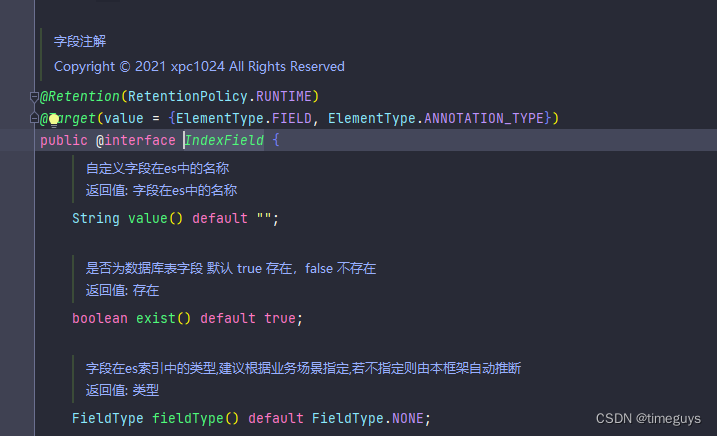
PS:在easy-es的注解 @IndexFiled 中源码会有说明:
对应的mapper:
// BaseEsMapper 来自 easy-es框架
public interface TestJcESMapper extends cn.easyes.core.core.BaseEsMapper<TestJcES> {
}
增删改(带批量):
testJcESMapper.deleteIndex("test_jd");
testJcESMapper.createIndex("test_jd");
TestJcES es = new TestJcES(1L,"小红",29,Arrays.asList("分类1","分类2","分类3"),Arrays.asList("标签1","标签2"));
TestJcES es2 = new TestJcES(2L,"小白",29,Arrays.asList("分类1","分类3"),Arrays.asList("标签1","标签3"));
TestJcES es3 = new TestJcES(3L,"小黑",30,Arrays.asList("分类4"),Arrays.asList("标签1"));
TestJcES es4 = new TestJcES(4L,"小明",18,Arrays.asList("分类1"),Arrays.asList("标签1","标签2","变迁3"));
testJcESMapper.insertBatch(Arrays.asList(es,es2,es3,es4));
//批量更新
//testJcESMapper.updateBatchByIds(Arrays.asList(es,es2,es3,es4));
//批量删除
//testJcESMapper.deleteBatchIds(Arrays.asList(1L,2L, 3L, 4L));
LambdaEsQueryWrapper<TestJcES> query = new LambdaEsQueryWrapper<>();
//相当于 select * from test_jc where name like '%红%' and sex = 29 and industryTags in ('标签1','标签2')
query.and(item->item.match(TestJcES::getName, "红"));
query.and(item->item.match(TestJcES::getSex, 29));
query.in("industryTags",Arrays.asList("标签1","标签2"));
// 默认按查询度倒叙
lambdaEsQueryWrapper.sortByScore(SortOrder.DESC);
//注意:从1开始起步 不是从0开始
EsPageInfo<TestJcES> pageQuery = testJcESMapper.pageQuery(query, 1, 10);
//查询数据
System.out.println(pageQuery.getList());
//总条数
System.out.println(pageQuery.getTotal());
//总页数
System.out.println(pageQuery.getPages());
聚合操作:
1.普通keyword类型字段聚合:
LambdaEsQueryWrapper<TestJcES> query = new LambdaEsQueryWrapper<>();
//TODO 这里也可以通过query带条件进行聚合
//比如: query.match(TestJcES::getName, "红");
// 这里类似 select * from test_jc group by sex
String filedName = "sex";
query.groupBy(filedName);
// 是否统计hits的数据总数 设置为0 则不统计 数据量大的时候聚合速度会更快一些
//query.size(0);
SearchResponse searchResponse = testJcESMapper.search(query);
//7. 获取命中对象 SearchHits
SearchHits hits = searchResponse.getHits();
//7.1 获取总记录数 如果 query.size(0) 则这里值就为0
Long total= hits.getTotalHits().value;
System.out.println("被聚合的数据总条数:"+total);
// aggregations 对象
Aggregations aggregations = searchResponse.getAggregations();
//将aggregations 转化为map
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//通过key获取 filedName+"Terms" 对象 使用Aggregation的子类接收 buckets属性在Terms接口中体现
// Aggregation goods_brands1 = aggregationMap.get(filedName+"Terms");
Terms resultTerms =(Terms) aggregationMap.get(filedName+"Terms");
//获取buckets 数组集合
List<? extends Terms.Bucket> buckets = resultTerms.getBuckets();
Map<String,Object>map=new HashMap<>();
//遍历buckets key 属性名,doc_count 统计聚合数
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKey());
System.out.println(bucket.getDocCount());
map.put(bucket.getKeyAsString(),bucket.getDocCount());
}
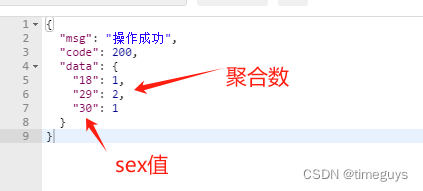
聚合效果:
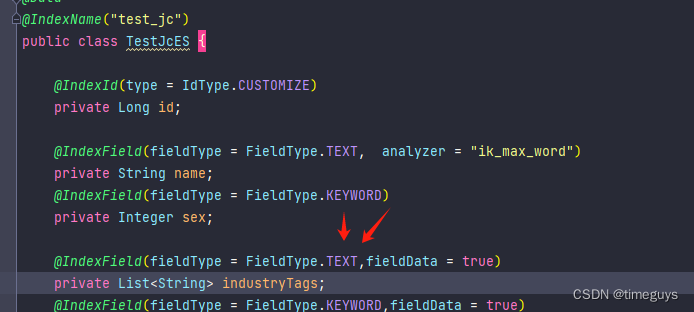
2.数组(text类型)类型聚合:
LambdaEsQueryWrapper<TestJcES> query = new LambdaEsQueryWrapper<>();
//TODO 这里也可以通过query带条件进行聚合
//比如: query.match(TestJcES::getName, "红");
String filedName = "industryTags";
query.groupBy(filedName);
// 是否统计hits的数据总数 设置为0 则不统计 数据量大的时候聚合速度会更快一些
//query.size(0);
SearchResponse searchResponse = testJcESMapper.search(query);
//7. 获取命中对象 SearchHits
SearchHits hits = searchResponse.getHits();
//7.1 获取总记录数 如果 query.size(0) 则这里值就为0
Long total= hits.getTotalHits().value;
System.out.println("被聚合的数据总条数:"+total);
// aggregations 对象
Aggregations aggregations = searchResponse.getAggregations();
//将aggregations 转化为map
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//通过key获取 filedName+"Terms" 对象 使用Aggregation的子类接收 buckets属性在Terms接口中体现
// Aggregation goods_brands1 = aggregationMap.get(filedName+"Terms");
Terms resultTerms =(Terms) aggregationMap.get(filedName+"Terms");
//获取buckets 数组集合
List<? extends Terms.Bucket> buckets = resultTerms.getBuckets();
Map<String,Object>map=new HashMap<>();
//遍历buckets key 属性名,doc_count 统计聚合数
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKey());
System.out.println(bucket.getDocCount());
map.put(bucket.getKeyAsString(),bucket.getDocCount());
}
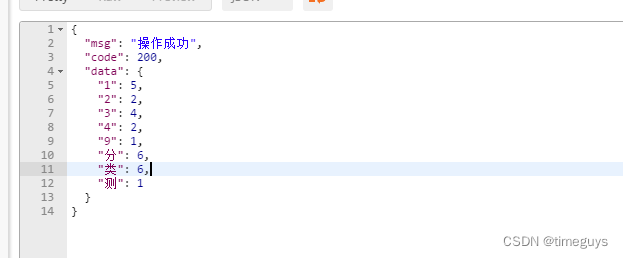
如果实体类的属性类型采用 text,则会把该属性里面的所有值分词然后进行聚合:
聚合效果:
2.数组(keyword类型)类型聚合:
LambdaEsQueryWrapper<TestJcES> query = new LambdaEsQueryWrapper<>();
//TODO 这里也可以通过query带条件进行聚合
//比如: query.match(TestJcES::getName, "红");
// 类似 select * from test_jc group by productTags
String filedName = "productTags";
query.groupBy(filedName);
// 是否统计hits的数据总数 设置为0 则不统计 数据量大的时候聚合速度会更快一些
//query.size(0);
SearchResponse searchResponse = testJcESMapper.search(query);
//7. 获取命中对象 SearchHits
SearchHits hits = searchResponse.getHits();
//7.1 获取总记录数 如果 query.size(0) 则这里值就为0
Long total= hits.getTotalHits().value;
System.out.println("被聚合的数据总条数:"+total);
// aggregations 对象
Aggregations aggregations = searchResponse.getAggregations();
//将aggregations 转化为map
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//通过key获取 filedName+"Terms" 对象 使用Aggregation的子类接收 buckets属性在Terms接口中体现
// Aggregation goods_brands1 = aggregationMap.get(filedName+"Terms");
Terms resultTerms =(Terms) aggregationMap.get(filedName+"Terms");
//获取buckets 数组集合
List<? extends Terms.Bucket> buckets = resultTerms.getBuckets();
Map<String,Object>map=new HashMap<>();
//遍历buckets key 属性名,doc_count 统计聚合数
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKey());
System.out.println(bucket.getDocCount());
map.put(bucket.getKeyAsString(),bucket.getDocCount());
}
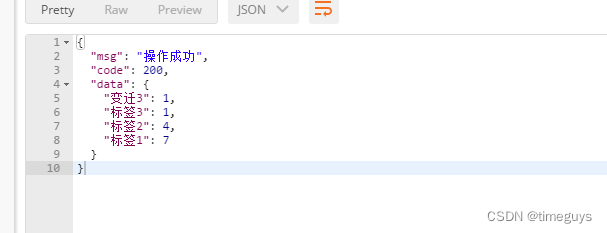
聚合效果:
es聚合强大的地方在于,会把属性为数组拆分元素进行聚合统计,一般来说,普通统计用到这里就完全足够了。
PS 另外附赠elasticsearch通用聚合方法:
可
/**
* [描述]
*/
private List<Map<String,Object>> commonGroup3(TestJcES search , String fieldName) {
// 创建一个布尔查询来组合多个条件
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if (StringUtils.isNotBlank(search.getName())) {
boolQuery.should(QueryBuilders.multiMatchQuery(search.getName(), "name"));
}
if(search.getProductTags() != null){
boolQuery.should(QueryBuilders.matchQuery("productTags",
search.getProductTags()));
}
return commonGroupByBoolQuery(fieldName, boolQuery,"test_jc");
}
/**
* 根据布尔查询创建一个过滤聚合,并返回基于指定字段的聚合结果
* @param fieldName 指定的字段名
* @param boolQuery 基于该布尔查询创建过滤聚合
* @param indexName 索引名称
* @return 基于指定字段的聚合结果列表,每个结果包含字段名和计数
*/
private List<Map<String, Object>> commonGroupByBoolQuery(String fieldName, BoolQueryBuilder boolQuery
,String indexName) {
// 创建一个过滤聚合,基于布尔查询
FilterAggregationBuilder filterAgg = AggregationBuilders.filter("filtered_agg", boolQuery);
// 在过滤后的文档上创建其他聚合
TermsAggregationBuilder termsAgg = AggregationBuilders.terms("agg_field")
.field(fieldName);
// 将聚合添加到过滤聚合中
filterAgg.subAggregation(termsAgg);
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 添加聚合到搜索源构建器
sourceBuilder.aggregation(filterAgg);
searchRequest.source(sourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 获取聚合结果
Filter filteredAggregation = searchResponse.getAggregations().get("filtered_agg");
Terms yourFieldAggregation = filteredAggregation.getAggregations().get("agg_field");
return yourFieldAggregation.getBuckets().stream()
.map(item -> {
Map<String, Object> map = new HashMap<>(2);
map.put("name", item.getKeyAsString());
map.put("count", item.getDocCount());
return map;
})
.collect(Collectors.toList());
} catch (IOException e) {
e.printStackTrace();
}
return List.of();
}
另附easy-es官网地址:
https://www.easy-es.cn/pages/ce1922/#%E5%B8%B8%E8%A7%84%E8%81%9A%E5%90%88
部分es教程博客:
https://blog.csdn.net/weixin_46115287/article/details/120974337
文章来源:https://blog.csdn.net/Timeguys/article/details/135130967
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!