文件搜索项目知识介绍
项目背景
需求上:因为Windows的文件搜索工具搜索速度十分的慢;让大家苦不堪言;是否能利用以前学习的知识实现这样子的一个功能呢?
项目优点:
1:搜索速度相近于世面众多文件搜索工具;文件大小只需13.4MB
2:灵动搜索;能支持文件名字拼音进行搜索;只需会读即可搜索
3:能自主灵活改动;能随时根据自己和体验人员的需求进行扩展和升级。
4:无广告、无会员、更新的选择权在于用户;不自主占用过多内存
SQLite介绍
SQLite、驱动包下载

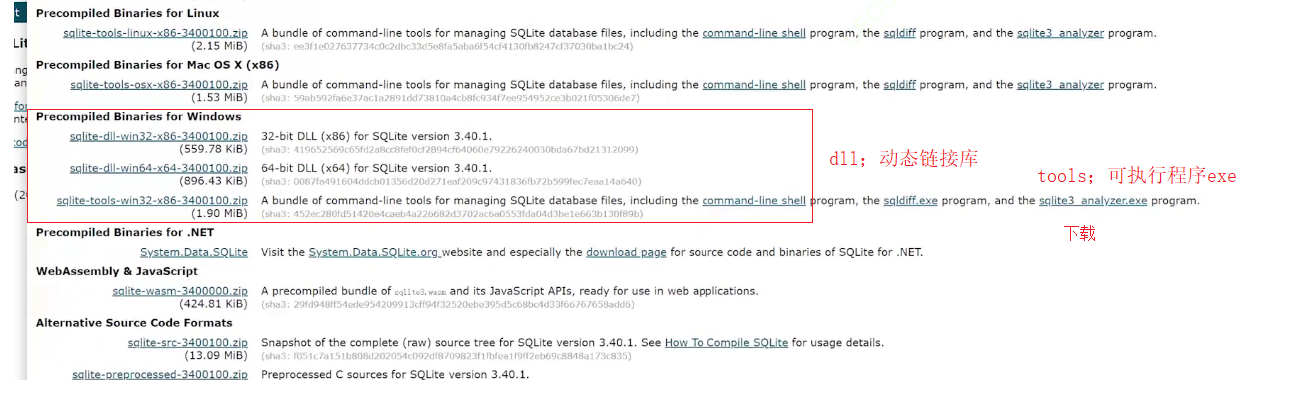
解压后三个文件:我们只取sqlite3.exe即可
SQLite使用
双击打开:它会提升连接到一个临时内存数据库;使用.open FILENAME重新打开一个永久数据库
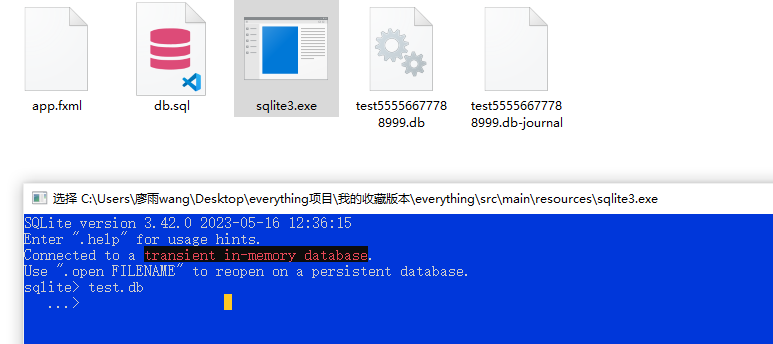
我们回到exe文件里:shift+右键空白处
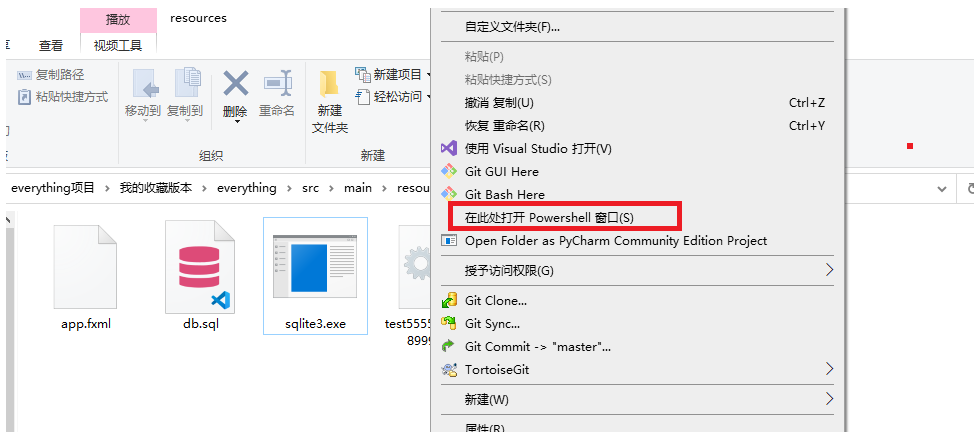

SQLite和MySQL区别
1:它不是客户端服务器结构;直接就是一个可执行程序;数据库直接文件的方式表示
2:操作大同小异;但是极个别不一样;SQLite是不需要create database/use /drop database/show databases……
所以我们要删除、显示数据库直接去文件里操作即可
3:SQLite轻量;一个数据库只有1M左右;给别人使用总不可能给别人带个几百MB的MySQL
4:sqlite中并不需要选中表;直接操作即可因为我们增删查改都会带上表名;它会去匹配是哪个表的;这个非常符合我们在用户电脑中我的带上的数据库文件创建表然后就能直接使用。要显示知道数据库有哪些表:.tables (MySQL里的show table不适合用)
5:SQLite插入数据会锁整个表;读和读之间无竞争;写和读、写和写有竞争。MySQL默认隔离级别是可重复读;使用MVCC和锁机制保证的隔离性;读和读之间使用共享锁不会锁竞争;写使用排它锁会发生竞争。插入数据时使用行级锁。
6:SQLite是没有int类型;但是它为了兼容其它数据库;使用支持我们写int;它内部自动进行转换成Integer;但是你要想使用自增主键就必须使用Integer
JDBC搭配SQLite
JDBC原理-创建连接
本质都是通过 Connection 对象才能连接到相应的数据库;获取建立连接有两种方式如下:
1:DriverManager;驱动管理;早期的jdbc版本你是需要显示加载驱动程序Class.forName(“com.mysql.jdbc.Driver”);4.0以后的版本引入了自动驱动程序加载机制后;你直接创建连接即可
Class.forName("com.mysql.jdbc.Driver");//加载驱动程序
DriverManager.getConnection("jdbc:mysql://localhost:3306/test&user=root&password=root&useUnicode=true&characterEncoding=UTF-8");
//或者
String url = "jdbc:mysql://localhost:3306/mydatabase";
String username = "user";
String password = "password";
Connection connection = DriverManager.getConnection(url, username, password);
2:DataSoure;可以被视为一个数据源池,其中包含了预先创建的Connection对象,应用程序可以从中获取连接对象并使用。
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/liao?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("111111");
两者的区别:
1:相当于一个是直接创建 Connection 对象就需要设置相关连接信息。而另一个是它内部帮你创建好;你通过DataSoure设置相应的连接信息:dataSource.setURL(“jdbc:mysql://127.0.0.1:3306/liao?characterEncoding=utf8&useSSL=false”);。本质都是在设置Connection对象。
2:DataSource是这些Connection对象是它帮你创建好存在那里;你只需要通过dataSource设置相应信息;然后通过这个dataSource对象获取这个连接即可。相当于一个懒汉模式;一个饿汉模式。
3: Connection.close时候;虽然都是断开连接;释放资源;DataSource是把Connection还给这个连接池;就是说我现在用完了;现在你其它人可以复用这个连接了
JDBC原理-关闭连接
使用完成connection、Resultset、statement对象都需要回收
public static void close(Connection connection, Statement statement, ResultSet resultSet) {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
添加和发送SQL
Statement对象主要是将SQL语句发送到数据库中;通常使用的是PreparedStatement;PreparedStatement是Statemen子类
如何获取这个对象:
//建表特殊一点
connection=数据源对象.getConnection();
statement=connection.createStatement();
//
String sql="insert into file_meta values(null,?,?,?,?,?,?,?)";
preparedStatement=connection.prepareStatement(sql);
这个对象有什么好处:
好处1: 预编译;执行之前,会先将SQL语句预编译,并缓存编译后的执行计划。这样可以提高性能,尤其是需要多次执行相同或类似的SQL语句时。
好处2:支持使用占位符(?)来表示参数,然后通过调用setXXX()方法为占位符设置具体的参数值。更安全(能防SQL注入)、数据和SQL分开更好阅读
好处3:对于重复执行相同的SQL语句(如批量插入),由于预编译的存在,性能通常比Statement更好。就是它会在MySQL这些数据库服务器缓存的执行计划和结果。
如何真正将sql发送:
executeQuery() 方法执行后返回Resultset单个结果集的,通常用于select语句。如何遍历这个结果集:
while (resultSet.next()) {
String name=resultSet.getString("name");
}
executeUpdate()方法返回值是一个整数,指示受影响的行数,通常用于update、insert、delete;create创建表也是用这个提交的;语句
JDBC-事务开启和提交
connection.setAutoCommit(false);//开启事务;先关闭自动提交的功能
String sql="insert into file_meta values(null,"123")";
preparedStatement=connection.prepareStatement(sql);
String sql2="insert into file_meta values(null,"234")";
preparedStatement=connection.prepareStatement(sql2);
preparedStatement.addBatch();//在这里累计
//执行SQL;
preparedStatement.executeBatch();
//执行完提交事务;使用commit提交事务
connection.commit();
使用你得try catch包裹一下;出现异常回滚 connection.rollback(); 最后finally释放资源
打包.exe文件
对于学习来说兴趣是最好的老师;能把一个程序给身边的亲朋好友使用;这无疑能给我们提供很大的学习动力。想要别人能成功的使用你的程序;两种常见手段
第一种:web项目部署云服务器上;别人能通过网络使用你的程序
第二种:把你的程序打包成一个.exe可执行文件给别人使用
需要将依赖的资源一起打包成 JAR 文件,可以使用 Maven 插件来实现。常见的 Maven 插件是 maven-assembly-plugin 和 maven-shade-plugin。使用 maven-assembly-plugin如下:
1:添加配置
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2:
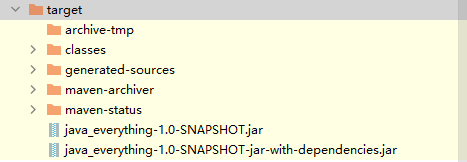
java_everything-1.0-SNAPSHOT.jar:只包含了项目自身的编译输出(类文件)和资源文件。不包含任何依赖项或第三方库,也叫"瘦"JAR。
java_everything-1.0-SNAPSHOT-jar-with-dependencies.jar:这个 JAR 包是使用 maven-assembly-plugin 插件创建的,它将项目及其所有的依赖项一起打包到一个单独的可执行 JAR 文件中,也叫"胖"JAR。
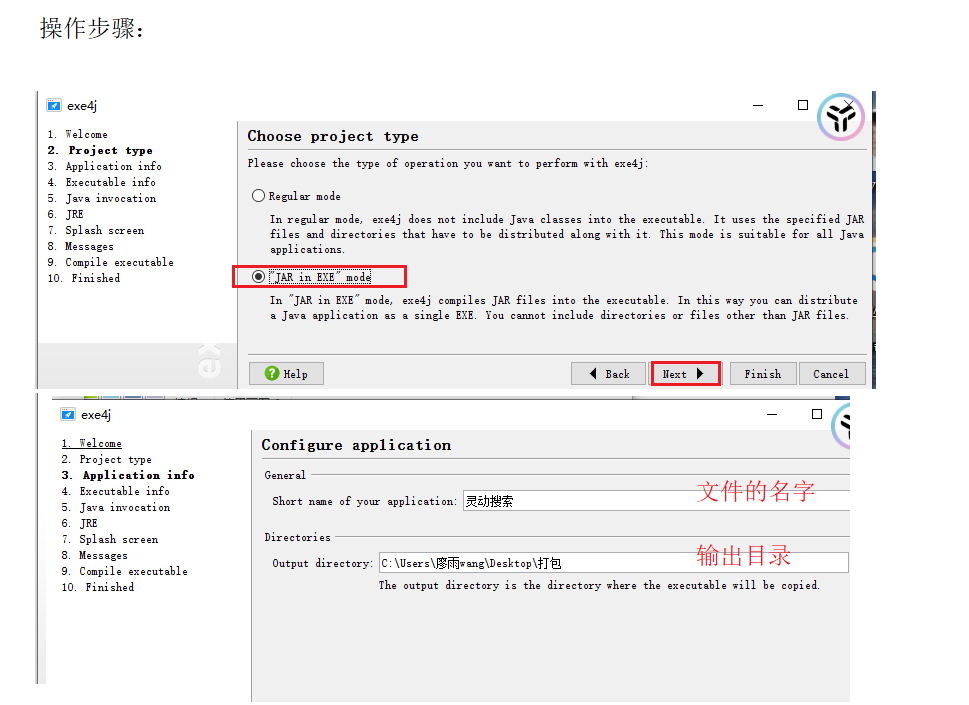
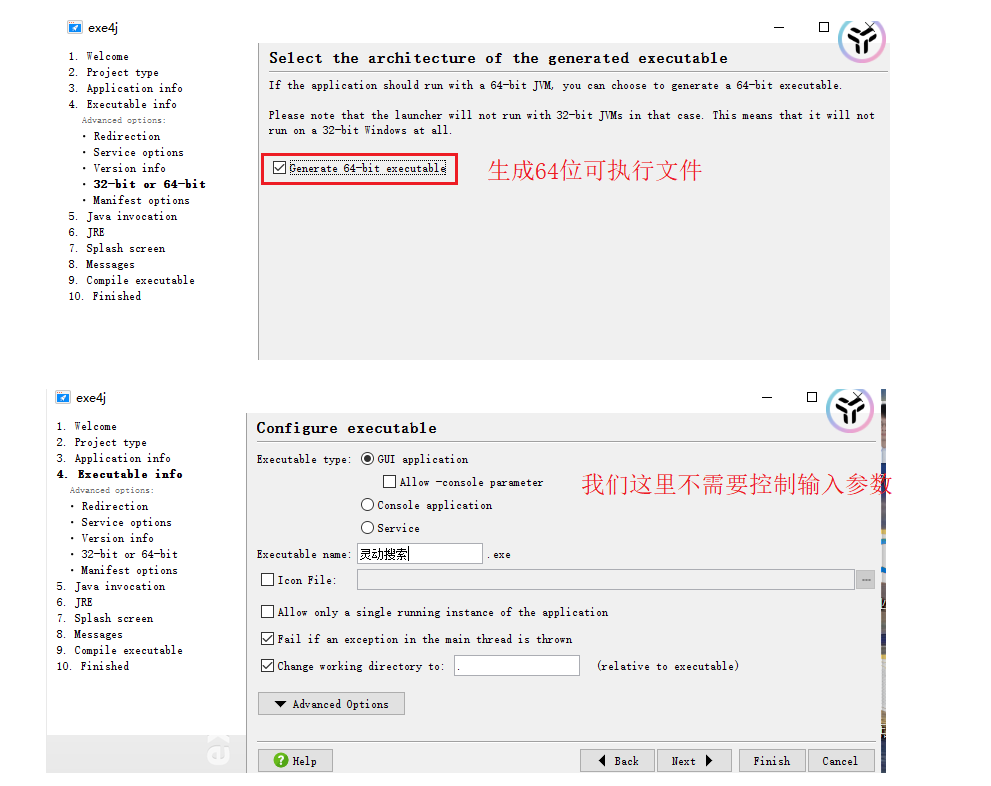
3:打包成.exe文件
需要用exe4j软件:操作步骤如下
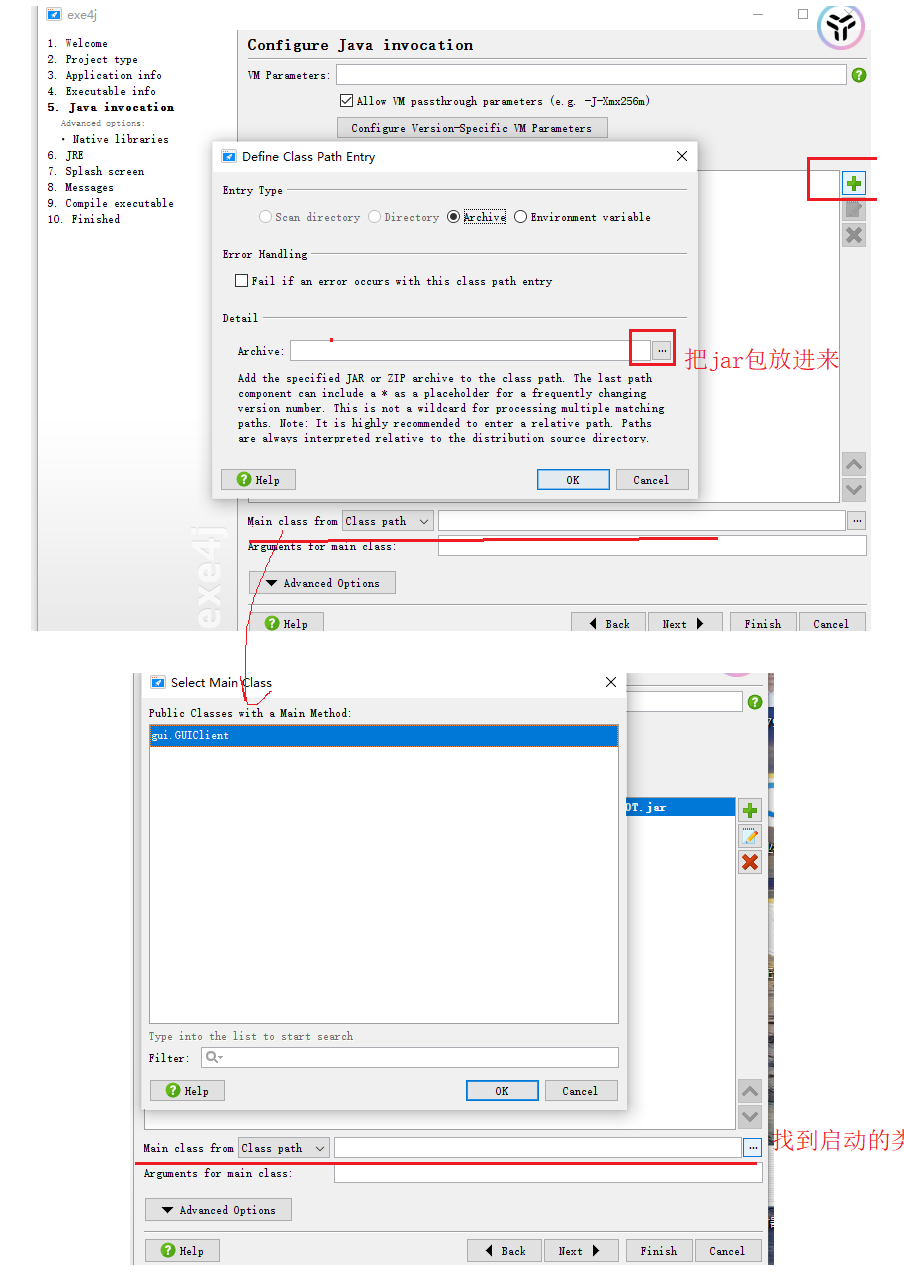
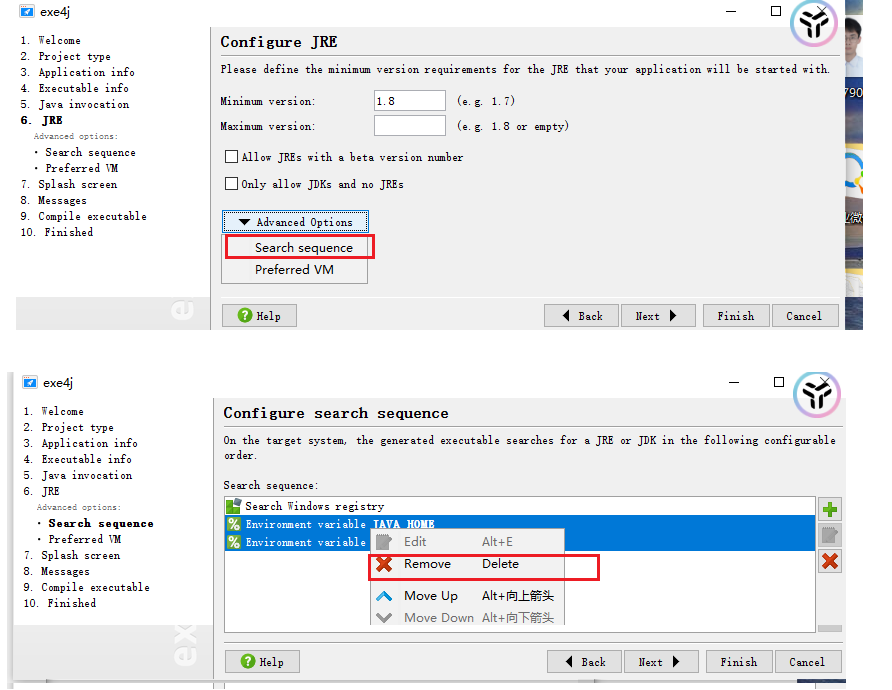
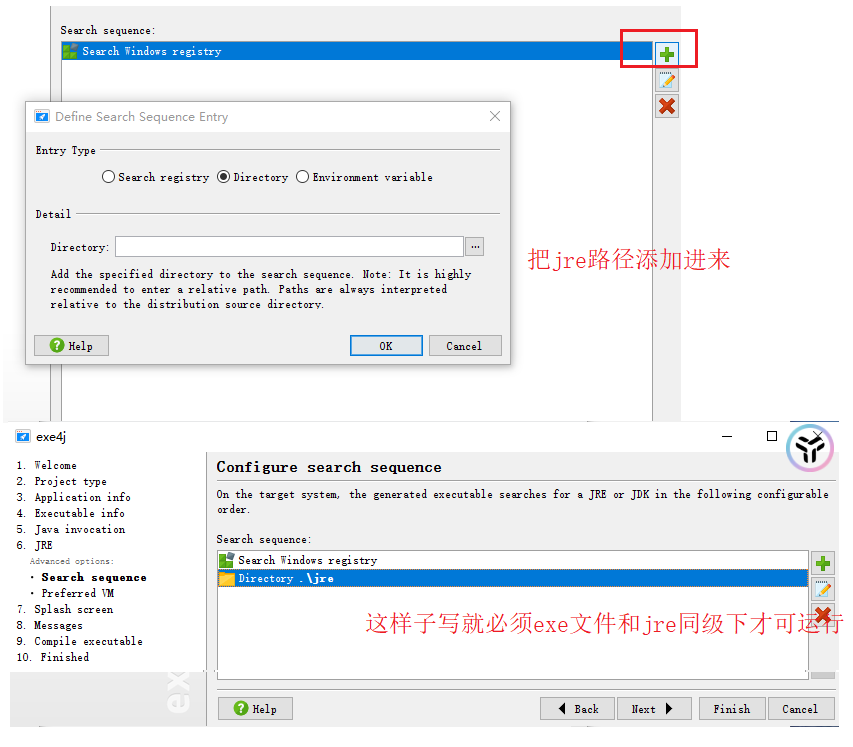
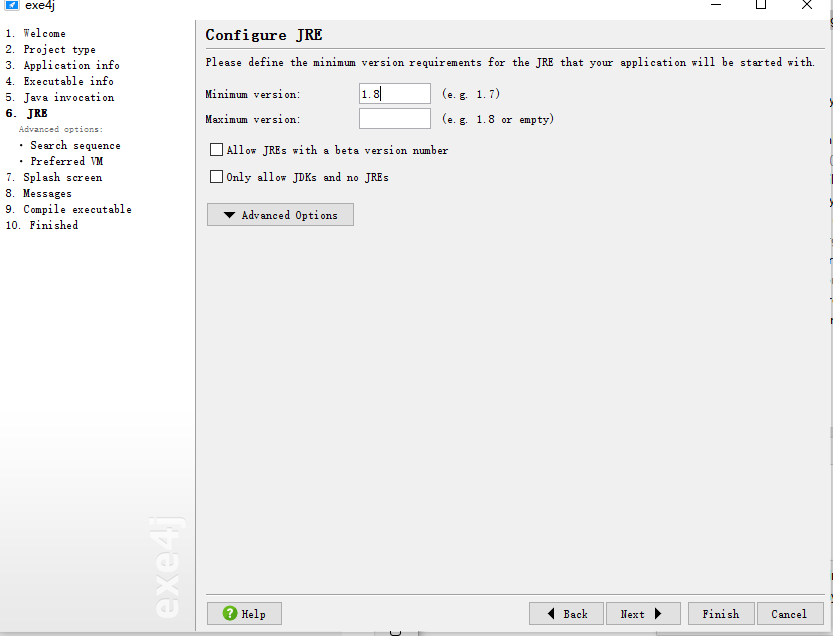
4:测试效果
先让我们本地Java环境失效看看能否执行
jre一定得是在同级下;因为打包时配置的是同级目录下;否则会出现
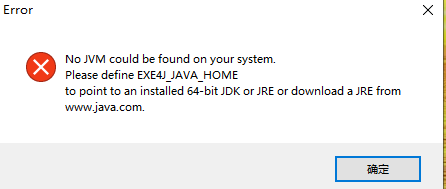
线程池线程数量问题

这里涉及一个问题:使用线程池添加任务;那么线程池的数量应该多少合适?
解决上述问题,可以采用测试的方法来验证适合的线程池数量,并使用计时方法来测量执行时间。但是会有指令重排序问题;解决这个问题;通过线程之间通信;等添加任务完成再通知它结束计时。但是我怎么知道线程池什么时候执行结束呢?
方法1:
threadPool.getTaskCount() != threadPool.getCompletedTaskCount();//统计已执行的任务和总任务比较。但是不准确;因为任务是一直在变化和添加;所以你需要写轮询的方式去判断。也可能我只想判断当前这个任务的三个线程是否执行完;中途别人又添加任务了;那就不精准了。
方法2:
ExecutorService executor=Executors.newFixedThreadPool(10);
FutureTask<Integer> task=new FutureTask(()->{
//任务
return -1;
});
executor.submit(task);
int result=task.get();//这个方法就能等待所有任务执行完毕并返回结果
方法3:特殊场景;可以使用计数器的方式;因为给线程池添加任务是内存进行非常快;而真正执行更新数据操作硬盘是相对非常慢。所以我们每向线程池添加一个任务就计数器++;线程池执行完一个任务就计数器–。但是这又有一个问题;使用普通计数器会原子性问题。这里能通过使用原子类解决问题。
简化后代码:
public class FileManager {
Object object=new Object();
private AtomicInteger taskCount = new AtomicInteger(0);//计数器
public void scanAll(File basePath) {
System.out.println("[FileManager] scanAll 开始!");
long beg = System.currentTimeMillis();
scanAllByThreadPool(basePath);
try {
synchronized (object){
object.wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("[FileManager] scanAll 结束! 执行时间: " + (end - beg) + " ms");
}
private static ExecutorService executorService = Executors.newFixedThreadPool(100);
private void scanAllByThreadPool(File basePath) {
// 计数器自增
taskCount.getAndIncrement(); // taskCount++
// 扫描操作, 放到线程池里完成.
executorService.submit(new Runnable() {
@Override
public void run() {
try {
scan(basePath);//执行任务
} finally {//写在这里防止中间出问题--失败而永远计数器达不到0
taskCount.getAndDecrement(); // taskCount--
if (taskCount.get() == 0) {
// 如果计数器为 0 ; 通知主线程结束计时了.
synchronized (object){
object.notify();
}
}
}
}
});
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!