开发Python网络爬虫应用,爬取链家新房楼盘信息保存到mongodb中,并分析相关数据
2023-12-28 16:46:13
爬取代码
import requests
import time
from lxml import html
from pymongo import MongoClient
import random
BASEURL = 'https://cq.fang.lianjia.com/loupan/'
# 获取某市区域的所有链接
def get_areas(url):
print('获取区县列表')
# 设置请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
# 获取请求页面数据
res = requests.get(url, headers=headers)
content = html.fromstring(res.text)
# 获取区县名称文本
areas = content.xpath('//div[@class="filter-by-area-container"]/ul[@class="district-wrapper"]/li/text()')
# 区县太多,只设置主城九区
areas = ['江北', '渝北', '渝中', '沙坪坝', '九龙坡', '南岸', '大渡口', '巴南', '北碚']
# areas = ['大足', '武隆区', '石柱', '涪陵', '綦江','长寿', '江津', '合川', '南川', '璧山', '铜梁', '潼南', '万州', '梁平', '云阳', '黔江', '双桥 ', '永川', '丰都', '秀山土家族苗族自治县', '忠县', '巫山县', '荣昌区', '奉节县', '开州区', '垫江县', '酉阳土家族苗族自治县', '彭水苗族土家族自治县', '巫溪县', '城口县']
print(areas)
# 获取区县名称拼写
areas_link = content.xpath('//div[@class="filter-by-area-container"]/ul[@class="district-wrapper"]/li/@data-district-spell')
# 区县太多,只设置主城九区
areas_link = ['jiangbei', 'yubei', 'yuzhong', 'shapingba', 'jiulongpo', 'nanan', 'dadukou', 'banan', 'beibei']
# areas_link = ['dazu', 'wulongqu', 'shizhu', 'fuling', 'qijiang', 'changshou1', 'jiangjing', 'hechuang', 'nanchuang', 'bishan', 'tongliang', 'tongnan', 'wanzhou', 'liangping', 'yunyang', 'qianjiang', 'shuangqiao1', 'yongchuan', 'fengdu1', 'xiushantujiazumiaozuzizhixian', 'zhongxian', 'wushanxian1', 'rongchangqu', 'fengjiexian', 'kaizhouqu', 'dianjiangxian', 'youyangtujiazumiaozuzizhixian', 'pengshuimiaozutujiazuzizhixian', 'wuxixian', 'chengkouxian']
# print(areas_link)
if not areas:
print("主站页面未获取成功,请手动查看页面是否需要人机验证!")
return
# 遍历获取所有区县的链接
for i in range(0, len(areas)):
area = areas[i]
area_link = areas_link[i]
# print(area_link)
link = url+area_link
print("当前区县:",area," ",link)
get_pages(area, link)
#通过获取某一区域的页数,来拼接某一页的链接
def get_pages(area, area_link):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36'}
res = requests.get(area_link, headers=headers)
content = html.fromstring(res.text)
#链家新房页面统计每个区域的楼盘个数
try:
count = int(content.xpath('//div[@class ="page-box"]/@data-total-count')[0])
except:
print(count)
#转换成页面,获取每个页面的楼盘信息
if count%10 :
pages = count//10+1
else:
pages = count//10
print("这个区域有" + str(pages) + "页")
for page in range(1, pages+1):
url = area_link+'/pg' + str(page)
print("开始抓取第" + str(page) +"页的信息")
get_house_info(area, url)
#获取某一区域某一页的详细房租信息
def get_house_info(area, url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36'}
time.sleep(1+2*random.random()) # 间隔随机1-3秒避免访问太密集触发反扒机制
try:
# 获取页面信息
print(url)
res = requests.get(url, headers=headers)
content = html.fromstring(res.text)
data = [] # 构造一个列表存放当前页面所有楼盘详情
for i in range(10): # 每页有10条楼盘信息
try:
# 获取楼盘详情:
#获取编号
project_id = content.xpath("//ul[@class='resblock-list-wrapper']/li/@data-project-name")[i]
print(project_id,end=',')
#详情页url
detail_url = BASEURL+"p_"+project_id
print(detail_url,end=',')
# 获取标题
title = content.xpath("//ul[@class='resblock-list-wrapper']/li/a/@title")[i]
print(title,end=',')
# 获取详细小区信息
detail_area= content.xpath("//ul[@class='resblock-list-wrapper']/li//div[@class='resblock-location']/span[2]/text()")[i]
print(detail_area,end=',')
# 获取详细地址
detail_place = content.xpath("//ul[@class='resblock-list-wrapper']/li//div[@class='resblock-location']/a/text()")[i]
print(detail_place,end=',')
# 获取小区类型
type = content.xpath("//ul[@class='resblock-list-wrapper']/li//div[@class='resblock-name']/span[1]/text()")[i]
print(type,end=',')
sale_status = content.xpath("//ul[@class='resblock-list-wrapper']/li//div[@class='resblock-name']/span[2]/text()")[i]
print(sale_status,end=',')
# 获取面积
try:
square = content.xpath("//ul[@class='resblock-list-wrapper']/li//div[@class='resblock-area']/span/text()")[i]
except:
square = ""
print(square,end=',')
# 获取价格
price = content.xpath("//ul[@class='resblock-list-wrapper']/li//div[@class='main-price']/span[1]/text()")[i]
#价格待定的楼盘设置price为0
if price=='价格待定':
price = None
else:
price = int(price)
print(price,end=',')
#获取标签tag
tag = content.xpath("/html/body/div[3]/ul[2]/li[{}]/div/div[5]/span/text()".format(i+1))
print(tag,end='\n')
except:
break
doc = {
"project_id":project_id,
"detail_url":detail_url,
"area":area,
"title":title,
"detail_area":detail_area,
"detail_place":detail_place,
"type":type,
"sale_status":sale_status,
"square":square,
"price":price,
"tag":tag
}
data.append(doc)
save_data(data) #保存到mongodb中,该方法框架已写好,需要自己实现细节
print('continue the next page...')
except:
print(res.text)
print(url)
print('详情页面未获取成功,请手动查看页面是否需要人机验证!')
time.sleep(30)
def save_data(data=None,host="127.0.0.1",port=27017,db_name="lianjia",col_name="loupan"):
'''
将解析到的楼盘详情数据存储到MongoDB数据库中
:param data: 楼盘详情数据
:param host: mongodb服务器地址
:param port: mongodb服务端口
:param db_name: mongodb数据库名称
:param col_name: mongodb数据集合名称
:return:
'''
#1.创建连接数据库对象
#2.连接数据库
#3.连接集合并实现插入
pass
def main():
print('开始!')
# 重庆主站URL
url = 'https://cq.fang.lianjia.com/loupan/'
# 访问主站URL获取区县信息
get_areas(url)
if __name__ == '__main__':
main()
分析数据
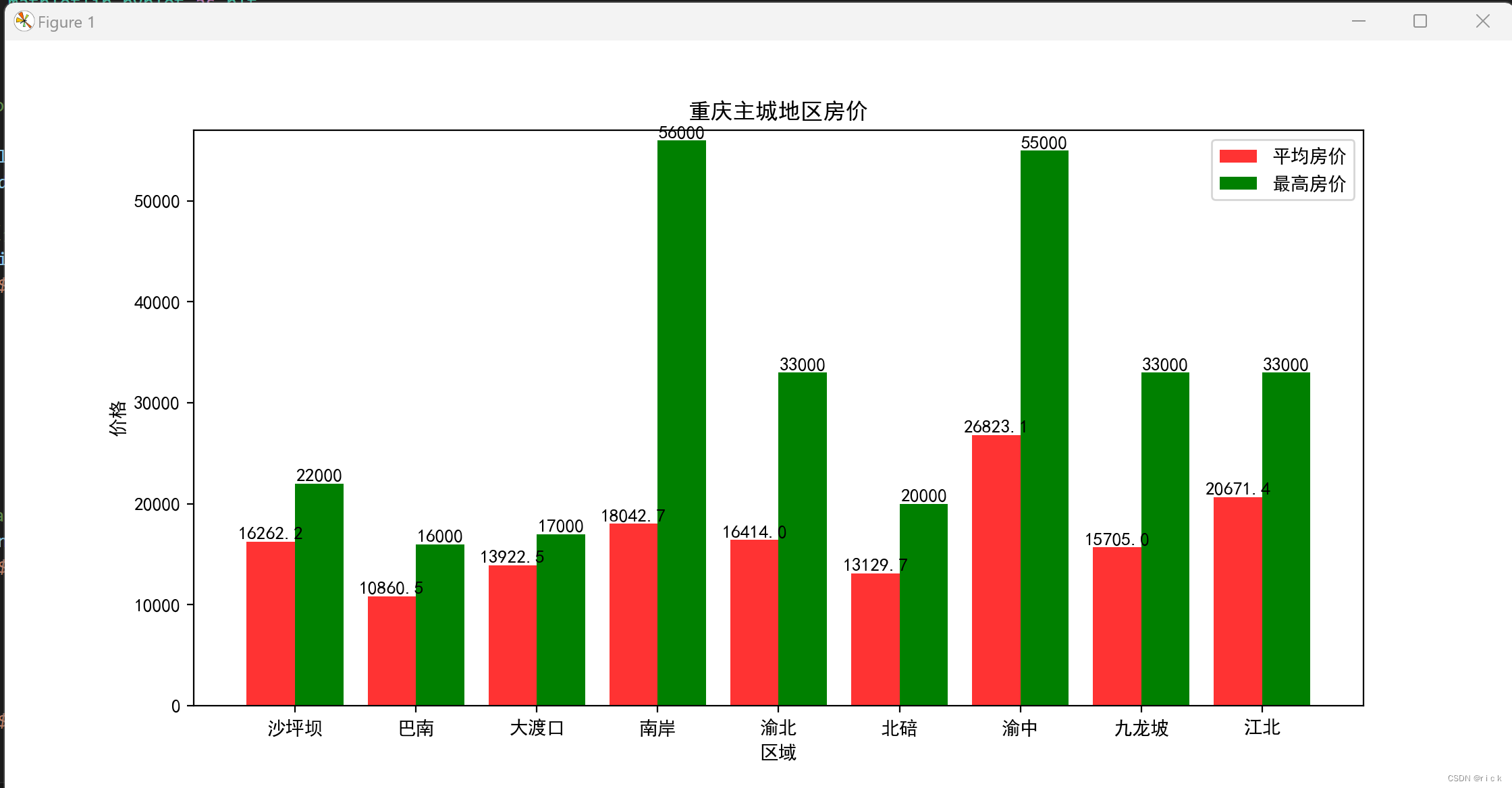
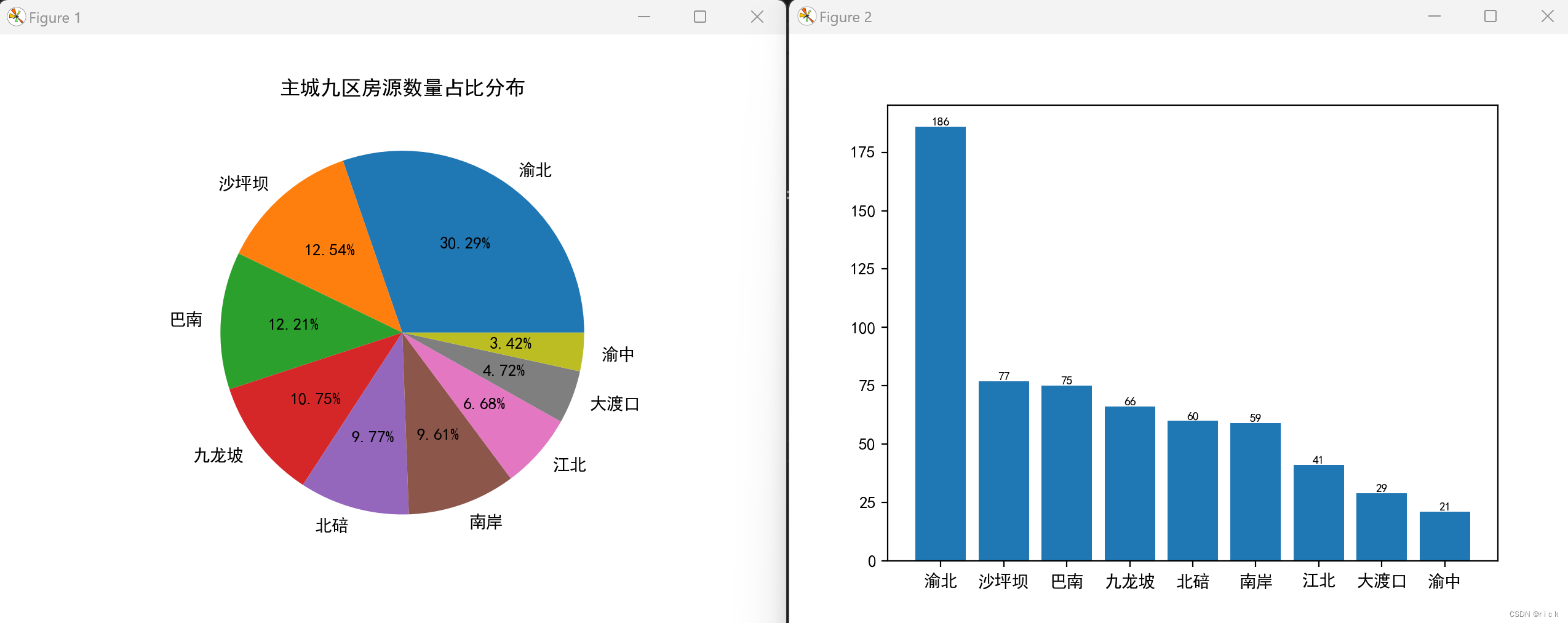
- 分析各个区新楼盘的平均价格、房屋占比情况等等
问题
- 问题一
没有相应的包,截图省略
解决方案:通过pip安装下面三个包即可
pip install requests
pip install lxml
pip install pymongo
- 问题二
count = int(content.xpath(‘//div[@class =“page-box”]/@data-total-count’)[0])
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^
IndexError: list index out of range
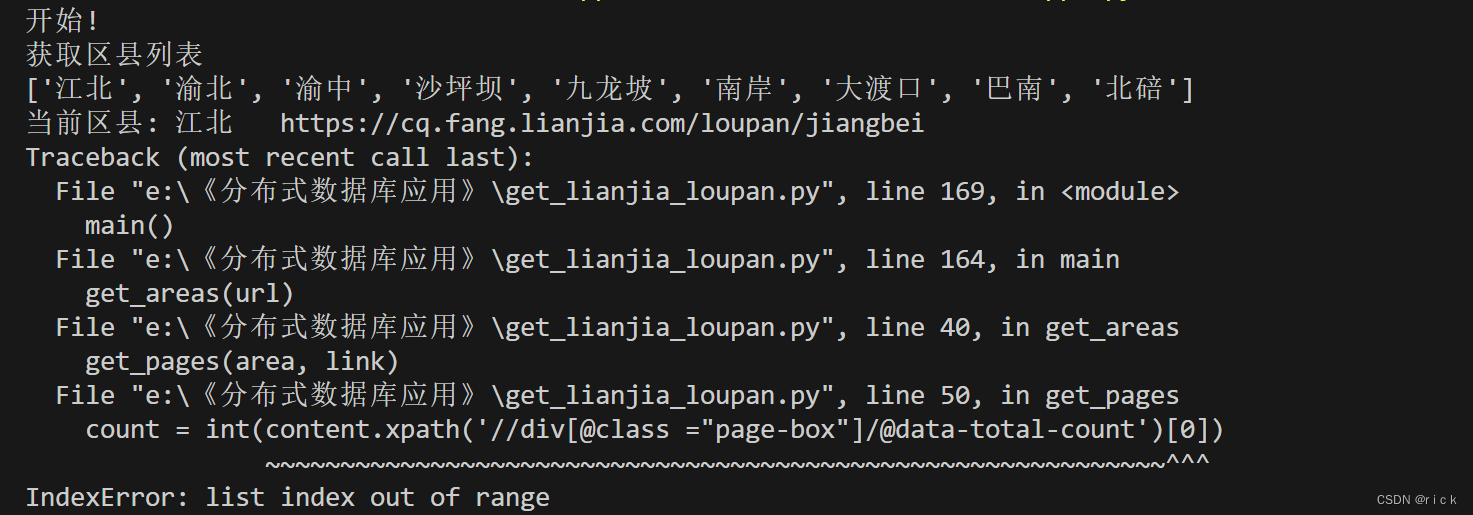
解决办法:打开对应的网页(https://cq.fang.lianjia.com/loupan/jiangbei)进行人机验证即可。这里是因为拿不到data-total-count值报错

文章来源:https://blog.csdn.net/xiaoren886/article/details/135267694
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!