SQL优化-深入了解SQL处理流程原理(Server层与存储引擎交互、数据管理结构)
做SQL优化的前提就必须要清楚当一个SQL被发送到Mysql时,它的处理流程。下面通过一个SQL优化分析过程来详细了解Mysql对SQL执行流程原理。
1、Mysql架构
在上篇文章中已经做了简单架构介绍,Mysql架构分为两个大的组件:Server层、存储层
Mysql服务层主要工作为连接器、查询缓存、解析器、优化器、执行计划、执行器等
存储引擎层: 存储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互。
可以看出来Mysql架构中Server层和存储引擎层是完全解耦独立运行的组件,所以MySQL存储引擎是插件式的,即可以选择不同的引擎使用,甚至可以自己写一个。
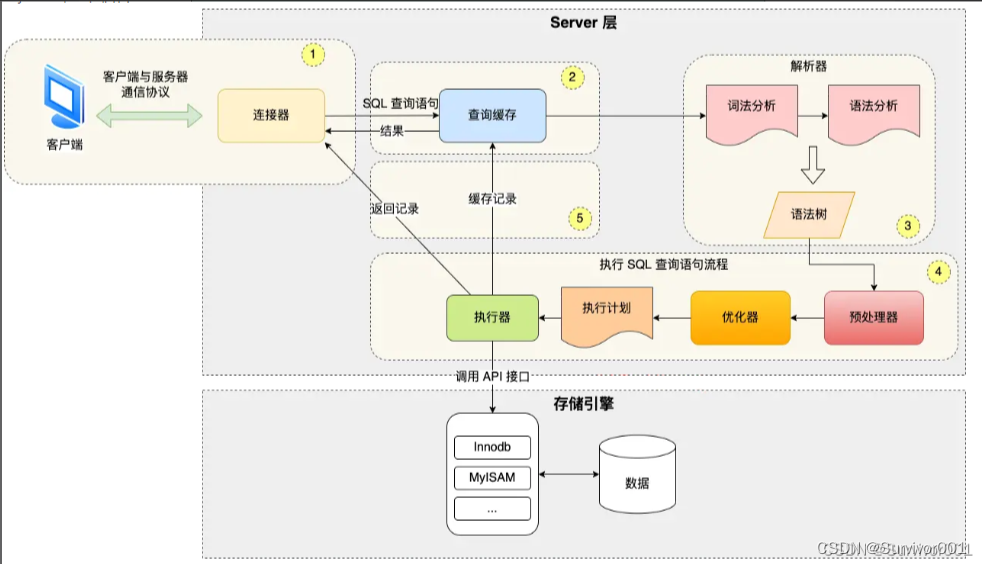
服务器中的查询执行引擎(执行器)通过接口与存储引擎进行通信。
简单的说,存储引擎本身是一个比较单纯的服务组件,它只负责与硬件交互,进行数据的读取和存储工作,而这一切的读写行为都是按照Server层提供执行计划来实施。
2、SQL执行流程分析
通过一个SQL优化来了解下详细流程:
select * from project where tenantsid=286478108025408 and name = '测试专案20219999' and sales_code ='psm02';

根据表结构和SQL可以得到相关分析资讯,借此来深入了解执行流程:
- 1、这个SQL会使用到index_01索引,因为不满足最左原则所以只会使用到tenantsid栏位。
- 2、因为name条件也是存在于索引index_01中的,Mysql5.7之后支持了索引下推优化,所以这块会使用到ICP,来进行优化。
- 3、sales_code ='psm02'是非索引栏位的附加条件,使用不到索引,那就需要进行数据过滤。
- 4、select * 所以需要回表操作
流程步骤:
1、Sever层通过连接器接收到SQL请求后,优先查看缓存是否由满足条件的数据,没有则继续..
2、通过解析器分析,生成语法树? .... 优化器(不关注,不说了)
3、Sever层最终会生成一个执行计划,执行器就根据执行计划来调用存储引擎进行交互。
执行计划:

可以看出来,执行计划中几乎已经将整个的执行过程交代的很清楚,后续就是单纯的按照执行计划来交互执行:

- Server层会调用存储引擎API,告诉它根据tenantsid栏位查询project的index_01索引树,同时别忘记了查询完了使用index_condtion进行过滤......说白了就是给出执行计划让它按计划整
- 存储引擎首先根据索引条件tenantsid,去索引树index_01进行数据检索,获取到满足条件的索引数据页,获取到第一条记录。
- 然后检查index_condition是否有需要过滤的条件,这里通过name条件进行过滤(ICP关键)。于是对这一条纪律进行name过滤,是否满足name='***' ,如果不满足,舍弃这条纪律,进行下一条记录查找。
- 如果满足name条件,发现当前索引树栏位不能满足需要的栏位used_columns,于是根据id进行回表查询,得到需要的栏位资讯
- 将这条数据返回给Sever层。需要注意的是,到此是第一个记录的处理流程,所以需要清楚的是server层和存储层是一条一条数据处理交互的,相当于一个loop。
- Sever层拿到该数据后,再检查是否有附加条件需要过滤attached_condition,这里需要根据sales_code 过滤
- sever层完成过滤后将该数据返回给客户端。(所以这就是为什么我们在客户端做大数据量查询时,手动停止查询后,只返回一部分数据过来原因)
上面交互流程涉及到了索引查询、ICP、回表、数据过滤等过程,当然Mysql远不止这些流程。
3、SQL优化
现在清楚了当前SQL的执行流程,我们可以知道:
1、ICP原理:server层在生成执行计划时,会将不能通过索引查询,但是可以利用索引结果进行过滤出的条件下推到存储引擎进行数据过滤,这样可以进一步过滤掉数据,减少后续回表的操作。一般使用到了索引下推可以通过执行计划extra查看,如果有use_index_condition表示进行了索引下推。

2、回表原理:因为索引树中叶子节点数据不能满足需要的栏位,所以需要通过主键ID,到主键索引中查询,这是IO操作,所以要尽量的减少这样的回表操作。
3、数据过滤:通过执行索引无法直接过滤的条件,server层会对其进行再次过滤操作,一般在执行计划中extra中存在using where表示需要进一步数据过滤行为。
4、索引覆盖:因为索引查询结果不能涵盖需要的栏位,所以才需要回表操作回去到需要的栏位信息,如果二级索引已经包含了需要的栏位,这里就不需要回表查询。
分析了执行计划,也了解了原理,接下来优化就变得简单了,
- 调整索引字段顺序,满足最左原则,这里可以将索引调整为(tenantsid,name,code)
- 减少回表:这里不要使用select * ,可以根据需求将需要的栏位进行select,比如select? tenantsid, name ... 如果回表量比较大,这里就可以考虑进行索引覆盖。
- 对attached_condition 建立索引:因为sales_code没有建立索引,才会导致需要额外的过滤操作,所以将当前字段,添加到index_01中,需要注意的是(tenantsid,name,sales_code,code) 索引查询,(tenantsid,name,code,sales_code) 索引下推
调整索引为index02(tenantsid,name,sales_code,code)?
select??tenantsid,name from project where tenantsid=286478108025408 and name = '测试专案20219999' and sales_code ='psm02';


可以看出来查询成本从702降到了1.2
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!