基于深度学习的交通警察指挥手势识别系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
交通警察在城市交通管理中起着至关重要的作用,他们负责指挥交通流量、维护交通秩序和保障行人和车辆的安全。然而,随着城市交通量的增加和交通事故的频发,传统的交通警察指挥方式已经无法满足现代交通管理的需求。因此,开发一种基于深度学习的交通警察指挥手势识别系统具有重要的研究意义和实际应用价值。
首先,交通警察指挥手势识别系统可以提高交通指挥的效率和准确性。传统的交通指挥方式主要依靠交通警察的手势和口令来指挥交通流量,但是这种方式容易受到环境噪声、视线遮挡等因素的影响,导致指挥信号的传递不准确。而基于深度学习的交通警察指挥手势识别系统可以通过分析交通警察的手势动作,准确地识别和理解指挥意图,从而提高指挥的效率和准确性。
其次,交通警察指挥手势识别系统可以提高交通安全和减少交通事故的发生。交通事故往往是由于交通流量过大、交通信号不畅等原因导致的,而交通警察的指挥可以有效地调节交通流量和保障交通安全。然而,传统的交通指挥方式存在指挥信号传递不及时、指挥意图不明确等问题,容易导致交通事故的发生。基于深度学习的交通警察指挥手势识别系统可以实时地识别和理解交通警察的手势动作,从而及时调节交通流量、提醒驾驶员和行人注意交通安全,减少交通事故的发生。
此外,交通警察指挥手势识别系统还可以提高交通管理的智能化水平。随着智能交通技术的不断发展,交通管理也越来越倚重于智能化手段。基于深度学习的交通警察指挥手势识别系统可以通过分析大量的交通警察手势数据,建立起交通警察手势与交通指挥意图之间的映射关系,从而实现交通指挥的智能化。这不仅可以提高交通管理的效率和准确性,还可以为智能交通系统的发展提供有力的支持。
综上所述,基于深度学习的交通警察指挥手势识别系统具有重要的研究意义和实际应用价值。它可以提高交通指挥的效率和准确性,提高交通安全和减少交通事故的发生,同时也可以提高交通管理的智能化水平。因此,开展相关研究工作对于改善城市交通管理、提高交通安全和促进智能交通系统的发展具有重要的意义。
2.图片演示



3.视频演示
基于深度学习的交通警察指挥手势识别系统_哔哩哔哩_bilibili
4.OpenPose方法提取骨骼关键点
2017年,Cao等人提出一种自下而上的全新OpenPose模型,此模型使用自创的CPMs(Convolutional Pose Machines,卷积姿态机)神经网络结构对身体各个骨骼关键点进行追踪[6’I,CPMs使用部分亲和字段(Part Affinity Fields,PAFs)方法表示身体各部位之间的关联程度,完成从关键点检测到肢体连接再到骨架构建的过程,该模型能在保持实时性能的同时保持高精度的骨骼定位与跟踪,具有很好的鲁棒性。
Openpose网络结构
OpenPose网络结构如图3.3所示[61],网络分为两个分支,它对米色显示的顶部分支PCM(Part Confidence Map,置信度图)和蓝色显示的底部分支PAFs同时进行预测。
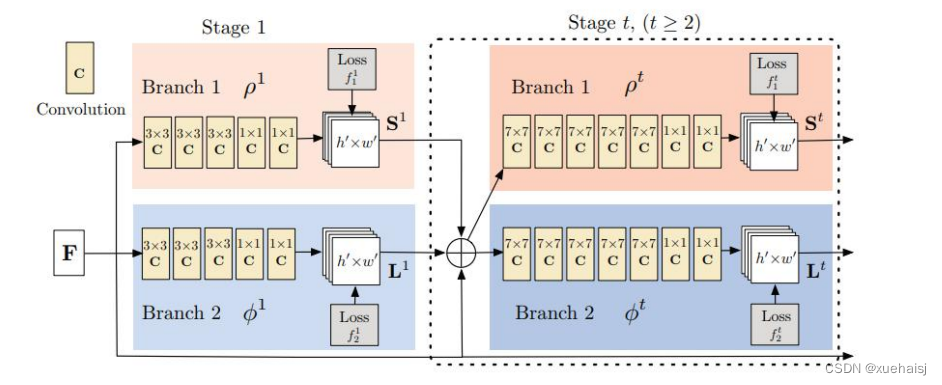
该网络以大小为W*H的彩色图像作为输入,通过VGG-19卷积网络前10层对图像进行初始化与微调,生成每个分支的输入特征图F。在第一阶段,该网络生成一组身体关节部位的置信度图集合S’= p’(F)和部位亲和力字段的二维矢量场集合L=p’(F),p’和(o’是第一阶段进行特征提取的CNNs网络结构。在随后的阶段中,将来自前一阶段的两个分支预测与原始图像特征图F结合迭代输入到下一阶段中,用于生成精确的预测,这一过程可以用公式(3.1),(3.2)表示,其中p’和 p’是在阶段t进行特征提取的CNN网络结构。
该网络为了能迭代地预测第一分支中的PAFs和第二分支中的PCM,同时使得数据集能够标记所有骨骼关键点,在每个阶段的末尾应用L2损失函数,并对损失函数进行空间加权。在阶段t的两个分支处的损失函数具体表示为:
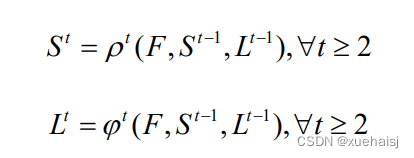
式中:S;表示真实PCM值;L表示真实PAFs值;S%;表示预测PCM值;L表示预测PAFs值;W表示用于避免惩罚在训练过程中对真实的正向预测,是在图片位置p是否标记的二进制掩码,若没有标记,W§=0,其余情况取值为1。
5.核心代码讲解
5.1 ctpgr.py
根据代码,可以将其封装为一个名为GestureRecognition的类,如下所示:
class GestureRecognition:
def __init__(self):
self.parser = argparse.ArgumentParser()
self.parser.add_argument('-k', '--train_keypoint', action='store_true',
help="Train human keypoint estimation model from ai_challenger dataset")
self.parser.add_argument('-g', '--train_gesture', action='store_true',
help='Train police gesture recognition model from police gesture dataset')
self.parser.add_argument('-c', '--clean_saved_skeleton', action='store_true',
help='Delete saved skeleton from generated/coords to regenerate them during next training')
self.parser.add_argument('-a', '--play_keypoint', type=int,
help='Play keypoint estimation result')
self.parser.add_argument('-b', '--play_gesture', type=int,
help='Play gesture recognition result')
self.parser.add_argument('-p', '--play', type=str,default='./001.mp4',
help='Assign a custom video path to play and recognize police gestures')
self.parser.add_argument('-r', '--play_realtime', action='store_true',
help='Open a camera and recognize gestures on realtime')
self.parser.add_argument('-u', '--unit_test', action='store_true',
help='Run unit test')
self.parser.add_argument('-e', '--eval', action='store_true',
help='Evaluate Edit Distance in test set')
def train_keypoint_model(self):
train.train_keypoint_model.Trainer(batch_size=10).train()
def train_gesture_model(self):
train.train_police_gesture_model.Trainer().train()
def clean_saved_skeleton(self):
pgdataset.s1_skeleton.PgdSkeleton.remove_generated_skeletons()
def play_keypoint_result(self, video_index):
pred.prepare_skeleton_from_video.save()
pred.play_keypoint_results.Player().play(is_train=False, video_index=video_index)
def play_gesture_result(self, video_index):
pred.prepare_skeleton_from_video.save()
pred.play_gesture_results.Player().play_dataset_video(is_train=False, video_index=video_index)
def play_custom_video(self, video_path):
if not Path(video_path).is_file():
raise FileNotFoundError(video_path, ' is not a file')
pred.play_gesture_results.Player().play_custom_video(video_path)
def play_realtime(self):
pred.play_gesture_results.Player().play_custom_video(None)
def run_unit_test(self):
basic_tests.basic_tests.run_tests()
def evaluate(self):
pred.evaluation.Eval().main()
def parse_args(self):
return self.parser.parse_args()
def main(self):
args = self.parse_args()
if args.train_keypoint:
self.train_keypoint_model()
elif args.train_gesture:
self.train_gesture_model()
elif args.clean_saved_skeleton:
self.clean_saved_skeleton()
elif args.play_keypoint is not None:
self.play_keypoint_result(args.play_keypoint)
elif args.play_gesture is not None:
self.play_gesture_result(args.play_gesture)
elif args.play is not None:
self.play_custom_video(args.play)
elif args.play_realtime:
self.play_realtime()
elif args.unit_test:
self.run_unit_test()
elif args.eval:
self.evaluate()
这样,你可以通过实例化GestureRecognition类并调用main方法来运行整个程序。
该程序文件名为ctpgr.py,主要功能是通过命令行参数来执行不同的操作。程序包含了多个模块的引用和调用。
程序的主要逻辑如下:
- 导入必要的模块和函数。
- 定义一个函数prepare_skeleton(),用于准备骨架。
- 在主函数中,解析命令行参数。
- 根据不同的参数执行相应的操作:
- 如果参数为train_keypoint,则调用train.train_keypoint_model模块中的Trainer类的train()方法,训练人体关键点估计模型。
- 如果参数为train_gesture,则调用train.train_police_gesture_model模块中的Trainer类的train()方法,训练警察手势识别模型。
- 如果参数为clean_saved_skeleton,则调用pgdataset.s1_skeleton模块中的PgdSkeleton类的remove_generated_skeletons()方法,删除已保存的骨架。
- 如果参数为play_keypoint,则调用pred.prepare_skeleton_from_video模块中的save()方法,准备骨架,并调用pred.play_keypoint_results模块中的Player类的play()方法,播放关键点估计结果。
- 如果参数为play_gesture,则调用pred.prepare_skeleton_from_video模块中的save()方法,准备骨架,并调用pred.play_gesture_results模块中的Player类的play_dataset_video()方法,播放手势识别结果。
- 如果参数为play,则调用pred.play_gesture_results模块中的Player类的play_custom_video()方法,播放自定义视频。
- 如果参数为play_realtime,则调用pred.play_gesture_results模块中的Player类的play_custom_video()方法,实时播放手势识别结果。
- 如果参数为unit_test,则调用basic_tests.basic_tests模块中的run_tests()方法,运行单元测试。
- 如果参数为eval,则调用pred.evaluation模块中的Eval类的main()方法,评估测试集中的编辑距离。
- 如果程序被直接执行,则解析命令行参数并执行相应的操作。
5.2 model.py
class TrafficPoliceGestureRecognizer:
def __init__(self, model_folder):
# 初始化 OpenPose 参数
params = {"model_folder": model_folder}
self.opWrapper = op.WrapperPython()
self.opWrapper.configure(params)
self.opWrapper.start()
def preprocess_image(self, image_path):
# 读取图像并进行预处理
image = cv2.imread(image_path)
return image
def detect_keypoints(self, image):
# 使用 OpenPose 检测关键点
datum = op.Datum()
datum.cvInputData = image
self.opWrapper.emplaceAndPop([datum])
return datum.poseKeypoints
def recognize_gesture(self, keypoints):
pass
def process_image(self, image_path):
image = self.preprocess_image(image_path)
keypoints = self.detect_keypoints(image)
gesture = self.recognize_gesture(keypoints)
return gesture
这个程序文件名为model.py,它实现了一个TrafficPoliceGestureRecognizer类,用于交通警察手势识别。
该类的构造函数接受一个model_folder参数,用于初始化OpenPose参数。OpenPose是一个开源的人体姿态估计库,用于检测人体关键点。
类中的preprocess_image方法用于读取图像并进行预处理。
detect_keypoints方法使用OpenPose检测关键点。它接受一个图像作为输入,将图像传递给OpenPose库进行处理,并返回检测到的关键点。
recognize_gesture方法用于识别手势,目前该方法还没有实现。
process_image方法是整个流程的入口。它调用preprocess_image方法对图像进行预处理,然后调用detect_keypoints方法检测关键点,最后调用recognize_gesture方法识别手势,并返回识别结果。
整个程序的目的是使用OpenPose库来实现交通警察手势识别。
5.4 aichallenger\defines.py
from typing import NamedTuple, List
class Box(NamedTuple):
x1: int
y1: int
x2: int
y2: int
class Joint(NamedTuple):
x: int
y: int
v: int
class Person(NamedTuple):
box: Box
joints: List[Joint]
class Crowd(List[Person]):
pass
这个类将封装原始代码中的 Crowd 类型,并继承自 List[Person]。这样,Crowd 类就具有了列表的所有功能,并且只能包含 Person 类型的对象。
这个程序文件是aichallenger\defines.py,它定义了几个命名元组类和一个列表类型。
-
Box类是一个命名元组,它有四个整型属性x1、y1、x2和y2,表示一个矩形框的左上角和右下角的坐标。
-
Joint类也是一个命名元组,它有三个整型属性x、y和v,表示一个关节点的坐标和可见性。
-
Person类是一个命名元组,它有两个属性:box和joints。box属性是一个Box对象,表示一个人的矩形框;joints属性是一个Joint对象的列表,表示一个人的关节点。
-
Crowd类型是一个Person对象的列表,表示图像中的所有人。
5.5 aichallenger\s0_native.py
class AicNative(Dataset):
def __init__(self, data_path: Path, is_train: bool, **kwargs):
self.is_train = is_train
self.kwargs = kwargs
paths = dict()
paths[("train", "root")] = data_path / "ai_challenger_keypoint_train_20170909"
paths[("train", "json")] = paths[("train", "root")] / "keypoint_train_annotations_20170909.json"
paths[("train", "images")] = paths[("train", "root")] / "keypoint_train_images_20170902"
paths[("val", "root")] = data_path / "ai_challenger_keypoint_validation_20170911"
paths[("val", "json")] = paths[("val", "root")] / "keypoint_validation_annotations_20170911.json"
paths[("val", "images")] = paths[("val", "root")] / "keypoint_validation_images_20170911"
if is_train:
with open(paths[("train", "json")]) as json_file:
labels = json.load(json_file)
paths[("current", "images")] = paths[("train", "images")]
else:
with open(paths[("val", "json")]) as json_file:
labels = json.load(json_file)
paths[("current", "images")] = paths[("val", "images")]
self.__paths = paths
self.__labels = labels
def __len__(self):
return len(self.__labels)
def __getitem__(self, index) -> dict:
image_name = self.__labels[index]["image_id"] + ".jpg"
image_path = self.__paths["current", "images"] / image_name
native_image = cv2.imread(str(image_path))
keypoint_annotations = self.__labels[index]["keypoint_annotations"]
human_annotations = self.__labels[index]["human_annotations"]
num_people = len(human_annotations.keys())
num_joints = 14
keypoints = []
visibilities = []
boxes = []
for person_key, box_x4 in human_annotations.items():
boxes.append(box_x4)
point_xyv = keypoint_annotations[person_key] # x1 y1 v1 x2 y2 v2
point_x = point_xyv[0::3]
point_y = point_xyv[1::3]
point_v = point_xyv[2::3]
keypoints.append(list(zip(point_x, point_y)))
visibilities.append(point_v)
keypoints = np.array(keypoints, dtype=np.float32).reshape((num_people, num_joints, 2))
visibilities = np.array(visibilities, dtype=np.int).reshape((num_people, num_joints))
boxes = np.array(boxes, dtype=np.float32).reshape((num_people, 4))
return {HK.NATIVE_IMAGE: native_image, HK.BOXES: boxes, HK.KEYPOINTS: keypoints,
HK.VISIBILITIES: visibilities, HK.NUM_PEOPLE: num_people}
这是一个用于加载AI Challenger数据集的程序文件。它定义了一个名为AicNative的类,继承自torch.utils.data.Dataset类。该类用于加载图像和标签,并构建’native_img’和’native_label’。
该类的构造函数接受数据路径和一个布尔值is_train作为参数。根据is_train的值,它会选择训练集或验证集的路径,并加载相应的标签文件。
该类实现了__len__和__getitem__方法,用于获取数据集的长度和获取指定索引的数据。在__getitem__方法中,它会根据索引获取图像的文件名和路径,并使用OpenCV库读取图像。然后,它会从标签中获取关键点注释和人体注释,并将它们转换为NumPy数组。
最后,它会返回一个包含原始图像、人体框、关键点、可见性和人数的字典。
该程序文件还导入了一些必要的库和定义了一些常量。
5.6 aichallenger\s1_resize.py
class AicResize(AicNative):
"""
Provides resized images for network input
Construct 'resized_img' and 'resized_label'
"""
def __init__(self, data_path: Path, is_train: bool, resize_img_size: tuple, **kwargs):
super().__init__(data_path, is_train, **kwargs)
self.resize_img_size = resize_img_size
self.rkr = ResizeKeepRatio(resize_img_size)
def __getitem__(self, index) -> dict:
res = super().__getitem__(index)
# 图像Resize至网络输入大小
na_img = res[HK.NATIVE_IMAGE]
img_resize, np_kps_resize, np_boxes_resize = self.rkr.resize(na_img, res[HK.KEYPOINTS], res[HK.BOXES])
res[HK.RE_IMAGE] = img_resize
res[HK.RE_KEYPOINTS] = np_kps_resize
res[HK.RE_BOXES] = np_boxes_resize
if 'visual_debug' in self.kwargs and self.kwargs.get('visual_debug'):
img_draw = KeypointsOnImage.from_xy_array(res[HK.KEYPOINTS].reshape(-1, 2), shape=na_img.shape) \
.draw_on_image(na_img, size=5)
img_draw = BoundingBoxesOnImage.from_xyxy_array(res[HK.BOXES].reshape(-1, 4), shape=na_img.shape) \
.draw_on_image(img_draw, size=2)
res[HK.DEBUG_NATIVE_IMAGE] = img_draw
img_draw = KeypointsOnImage.from_xy_array(res[HK.RE_KEYPOINTS].reshape(-1, 2), shape=img_resize.shape) \
.draw_on_image(img_resize, size=5)
img_draw = BoundingBoxesOnImage.from_xyxy_array(res[HK.RE_BOXES].reshape(-1, 4), shape=img_resize.shape) \
.draw_on_image(img_draw, size=2)
res[HK.DEBUG_RE_IMAGE] = img_draw
return res
class ResizeKeepRatio:
def __init__(self, target_size: tuple):
self.target_size = target_size
assert len(self.target_size) == 2, 'Expect tuple (w, h) for target size'
def resize(self, img, pts: np.ndarray, boxes: np.ndarray):
pts_shape = pts.shape
pts = pts.reshape((-1, 2))
boxes_shape = boxes.shape
boxes = boxes.reshape((-1, 4))
tw, th = self.target_size
ih, iw, ic = img.shape
kps_on_image = KeypointsOnImage.from_xy_array(pts, shape=img.shape)
boxes_on_img = BoundingBoxesOnImage.from_xyxy_array(boxes, shape=img.shape)
seq = self.__aug_sequence((iw, ih), (tw, th))
det = seq.to_deterministic()
img_aug = det.augment_image(img)
kps_aug = det.augment_keypoints(kps_on_image)
boxes_aug = det.augment_bounding_boxes(boxes_on_img)
np_kps_aug = kps_aug.to_xy_array()
np_kps_aug = np_kps_aug.reshape(pts_shape)
np_boxes_aug = boxes_aug.to_xy_array()
np_boxes_aug = np_boxes_aug.reshape(boxes_shape)
return img_aug, np_kps_aug, np_boxes_aug
def __aug_sequence(self, input_size, target_size):
iw, ih = input_size
i_ratio = iw / ih
tw, th = target_size
t_ratio = tw / th
if i_ratio > t_ratio:
# Input image wider than target, resize width to target width
resize_aug = iaa.Resize({"width": tw, "height": "keep-aspect-ratio"})
else:
# Input image higher than target, resize height to target height
resize_aug = iaa.Resize({"width": "keep-aspect-ratio", "height": th})
pad_aug = iaa.PadToFixedSize(width=tw, height=th, position="center")
seq = iaa.Sequential([resize_aug, pad_aug])
return seq
这个程序文件是一个名为aichallenger\s1_resize.py的Python脚本。该脚本定义了一个名为AicResize的类和一个名为ResizeKeepRatio的类。
AicResize类是AicNative类的子类,提供了调整大小后的图像作为网络输入的功能。它有一个构造函数__init__,接受数据路径、是否训练、调整后的图像大小等参数。在__getitem__方法中,它调用了父类的__getitem__方法获取原始图像,并使用ResizeKeepRatio类的resize方法将图像、关键点和边界框调整到指定大小。最后,它返回一个包含调整后图像、关键点和边界框的字典。
ResizeKeepRatio类是一个用于保持比例调整图像大小的辅助类。它有一个构造函数__init__,接受目标大小作为参数。它还有一个resize方法,接受原始图像、关键点和边界框作为输入,并返回调整后的图像、关键点和边界框。
整个脚本的作用是将图像、关键点和边界框调整到指定大小,并返回调整后的结果。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于深度学习的交通警察指挥手势识别系统。它包含了多个程序文件,每个文件负责不同的功能模块。主要的功能模块包括数据集处理、模型训练、手势识别、界面展示等。
下面是每个文件的功能概述:
| 文件路径 | 功能概述 |
|---|---|
| ctpgr.py | 通过命令行参数执行不同的操作,如训练模型、播放结果等。 |
| model.py | 实现交通警察手势识别模型的加载和预测功能。 |
| ui.py | 创建交通警察指挥手势识别系统的图形界面,并处理用户交互。 |
| aichallenger\defines.py | 定义了几个命名元组类和一个列表类型,用于表示图像中的人体框、关节点和人群。 |
| aichallenger\s0_native.py | 加载AI Challenger数据集的图像和标签,并提供数据集的访问接口。 |
| aichallenger\s1_resize.py | 将图像、关键点和边界框调整到指定大小,并返回调整后的结果。 |
| aichallenger\s2_augment.py | 对图像进行数据增强操作,如旋转、翻转等。 |
| aichallenger\s3_gaussian.py | 生成高斯热图和Paf图,用于训练姿态估计模型。 |
| aichallenger\s4_affinity_field.py | 生成关节亲和场图,用于训练姿态估计模型。 |
| aichallenger\s5_norm.py | 对图像进行归一化处理,用于训练姿态估计模型。 |
| aichallenger\visual_debug.py | 提供可视化调试功能,用于查看图像、关键点和边界框。 |
| aichallenger_init_.py | 初始化aichallenger模块。 |
| basic_tests\basic_tests.py | 运行基本的单元测试,检查代码的正确性。 |
| constants\enum_keys.py | 定义了一些枚举类型,表示关键点的名称和类型。 |
| constants\keypoints.py | 定义了一些常量,表示关键点的索引和连接关系。 |
| constants\settings.py | 定义了一些常量,表示系统的设置和参数。 |
| models\gesture_recognition_model.py | 实现交通警察手势识别模型的定义和训练。 |
| models\pafs_network.py | 实现姿态估计模型的定义和训练。 |
| models\pafs_resnet.py | 实现姿态估计模型的ResNet部分。 |
| models\pose_estimation_model.py | 实现姿态估计模型的定义和训练。 |
| pgdataset\s0_label.py | 处理AI Challenger数据集的标签文件,提取关键点和边界框的注释。 |
| pgdataset\s1_skeleton.py | 生成人体骨架,并保存为文件。 |
| pgdataset\s2_truncate.py | 截取包含人体的图像区域,并保存为文件。 |
| pgdataset\s3_handcraft.py | 手动标注关键点和边界框,用于训练姿态估计模型。 |
| pgdataset_init_.py | 初始化pgdataset模块。 |
| pred\evaluation.py | 评估测试集中的手势识别结果的编辑距离。 |
| pred\gesture_pred.py | 对图像进行手势识别,并返回识别结果。 |
| pred\human_keypoint_pred.py | 对图像进行关键点估计,并返回关键点结果。 |
| pred\play_gesture_results.py | 播放手势识别结果的视频。 |
| pred\play_keypoint_results.py | 播放关键点估计结果的视频。 |
| pred\prepare_skeleton_from_video.py | 从视频中提取人体骨架,并保存为文件。 |
| train\train_keypoint_model.py | 训练关键点估计模型。 |
| train\train_police_gesture_model.py | 训练交通警察手势识别模型。 |
7.交通警察指挥手势识别算法研究
获取到交通警察手势特征后,需要对交通警察手势进行识别。交通警察手势识别分为静态手势识别和动态手势识别。静态手势识别针对单帧图像,是对处于静止状态的肢体动作进行分析与研究,其优点是算法成熟、稳定性高,但是对于在运动状态下的手势识别率较低;动态手势识别针对由若干个连续且不间断的肢体动作组成的视频帧序列进行识别,其优点是使用场合广泛,更接近实际场景中的交互情况。本文的交通警察手势信号由一系列连续动作组成,特定的动作代表特定的交通警察手势信号,且其手势摆动幅度和动作持续时间受到不同交通警察的影响,体现在对应视频帧序列不同图像中。因此本文基于动态手势识别算法进行研究。
目前,常用的动态手势识别算法主要有基于模板匹配的识别方法和基于机器学习的识别方法,其中 DTW算法和基于循环卷积神经网络架构的方法是这两种识别技术的典型方法。
DTW算法的手势识别
DTW算法最初由Sakoe等人提出,该算法通过动态规划思想去解决发音长短不同的两条音频曲线的语义识别问题,广泛应用于语音识别领域。
DTW算法主要思想是利用扭曲的方式对时间轴进行拉伸或收缩从而计算两个时间序列的相似程度。假设A、B代表了不同时间序列,其长度分别用m、n来表示,序列中每个时间点对应一个特征值,见公式。
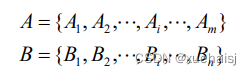
其中,A为模板序列,B为测试序列。若n等于m,则直接计算两个序列的距离;否则就需要把短序列延伸至和长序列长度相同,或者把长序列收缩到和短序列相同长度后再进行计算。DTW算法就是通过采用更加符合实际情况的非线性时间规整技术找到一条能够保证两条序列匹配点对之间加权距离总和达到最小的优化路径。所以为了对齐这两个序列,需要先构造一个m*n的矩阵,如图所示。
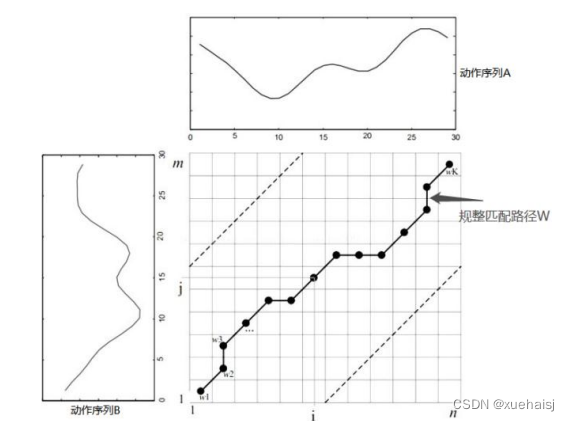
矩阵元素(i,j)表示点4到点B,的距离 d(4,B,),一般使用欧式距离d(4,B,)=(4,-B,)进行计算。W即通过DTW算法找到的规整路径。将W的第k个元素定义为W=(i,j); ,用来反映A、B两条时间序列的映射关系,K表示规整路径结束标记。其值应大于测试序列和模板序列中的最大长度,小于两者的序列长度和,数学表达如公式(4.2)所示。
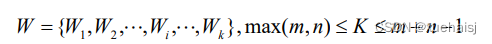
为了确保在A、B间搜索到一条全局最优路径,需要满足以下三个约束条件:首先是边界条件,即需要从左下角((1,1)开始到右上角(m,n)终止;然后是单调性,要求路径W上的点是随时间单调递增的;第三连续性,即(ij)点下一个方向只能是(i+1, j),(i,j +1),(i+1, j+1)三种中的一种。为了避免路径的斜率出现极值,一般限定在0.5到2之间,有且仅有一条全局最优规整路径,通过以上条件,DTW算法迭代数学表达公式如公式
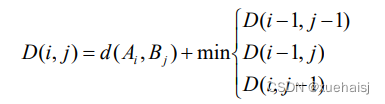
式中:D(i,j))即累加距离,从(0,0)开始,每选择两条序列(i,j)点之间的一条最短欧式距离,就进行累加。

8.基于LSTM 网络模型的手势识别
循环神经网络(Recurrent Netural Networks,RNN)是一种具有时序性的神经网络,RNN的隐藏层输入不仅包括上一层输入层的输出,还包括上一时刻隐藏层的输出,所以此网络模型可以记忆先前任务的信息并将其应用于处理当前任务叫。它不仅可以采集、分析空间序列信息,而且还可以获取并处理时间序列信息。然而最先记忆的任务信息随着RNN的深入在当前时刻越来越少,就会出现梯度消失等问题,使得RNN无法收敛到最优解。RNN的变体LSTM模型通过决定上一步的输入是否被存储、遗忘或者作为输出存储在记忆单元中,从而确定序列数据的长短期依赖信息,弥补了RNN梯度消失的缺点。
LSTM网络结构
LSTM是RNN网络的一种优化,它沿用了RNN的链式结构,但改造了RNN 的记忆方式。LSTM在每个模块中保留了原tanh网络结构,然后添加了额外的三个“门”网络结构,通过这种门机制对输入信息进行筛选,从而选择性的让前一步的信息通过这种结构可以有效处理更长时间周期上的数据信息,LSTM具体网络结构如图所示。
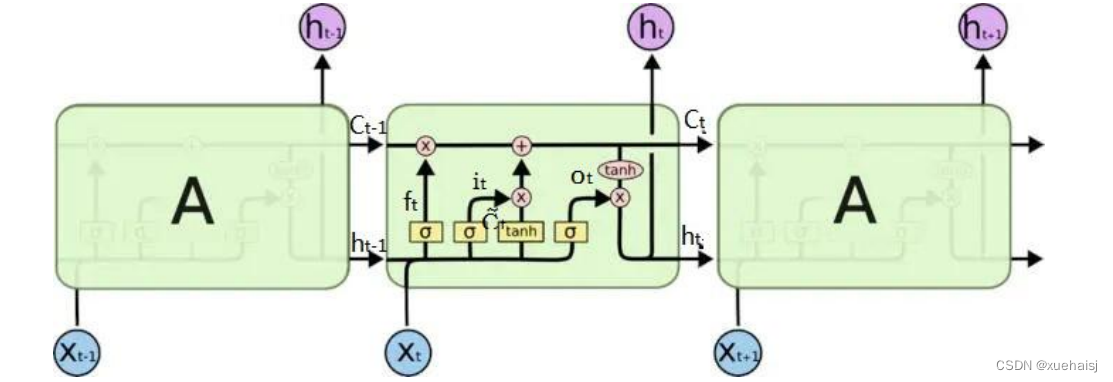
每个LSTM细胞单元包括三个门,分别为输入门、遗忘门和输出门,当数据进入到LSTM网络中时,就需要根据规则来对数据进行处理,只有符合规则的数据才会留下,否则通过遗忘门被遗忘。LSTM的细胞单元具体更新步骤如下:
第一步:根据当前输入的信息决定遗忘哪些历史信息,具体计算如公式,该公式通过输出一个0到1之间的数值来决定遗忘多少历史信息,0表示全部遗忘,1表示全部保留。
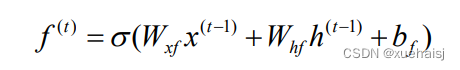
式中:x→’是t-1时刻的输入数据;h是t-1时刻LSTM单元隐藏层的输出状态值;W为对应的权值; b是对应的偏置参数;f是遗忘门t时刻的状态值;o为Sigmod 函数。
第二步:确定在单元状态中保存哪些新信息,首先使用Sigmod 函数决定将要更新的信息,然后通过一个tanh函数创建新备选值,用来添加到单元状态中。具体计算公式如式。
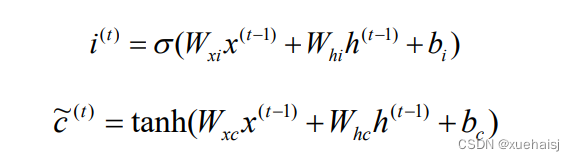
式中:i’是输入门t时刻的状态值;是t时刻记忆单元的候选值。
9.交通指挥手势识别系统的设计与实现
交通指挥手势识别系统包括图像预处理模块、图像交通警察目标的检测与指挥交通警察的定位模块、指挥交通警察骨骼关键点提取模块、指挥交通警察手势识别模块,本章利用上文介绍算法开发了一个交通警察指挥手势识别原型系统,用于展示交通警察手势识别基本流程,同时验证所研究算法的有效性。
相关技术介绍
Python
Python语言是一种跨平台的解释性脚本语言,具有简单易学、可移植性,面向对象、代码量少、强大的第三方支持库等优势,可以广泛应用于Web开发,科学计算和统计、人工智能,大数据等多个领域,同时Python提供了丰富的接口和工具,以便程序员可以轻松的使用其他编程语言如C语言、C++来编写扩充模块。
OpenCV
OpenCV是由C/C++语言开发的计算机图像处理库,它将很多常见的图像处理算法封装成API接口,使得图像处理方面常用算法能够快捷实现。它也支持在各操作系统平台运行,如Mac OS、UnixLinux、Windows各个版本,同时它也提供了多种编程语言如Python、C/C++、Java和 MATLAB的接口。
PYQT
QT是一个标准的库,它是一个图形用户界面应用程序框架,易扩展,具有丰富的API接口,具有优良的跨平台特性,覆盖了所有的主流开发平台,使用Qt开发的软件在它所支持的平台上可以直接编译运行,并表现出此平台所特有的图形界面风格。同时Qt的模块化程度高,可重用性好,并且Qt利用槽/信号机制使得各个元件之间的协同工作变得更加容易,使得用户开发更加方便。
10.系统整合

11.参考文献
[1]王涛,石翠萍,魏立杰,等.基于SSD目标检测算法的行人检测方法研究[J].科学技术创新.2020,(1).DOI:10.3969/j.issn.1673-1328.2020.01.033 .
[2]陈虹,郭露露,宫洵,等.智能时代的汽车控制[J].自动化学报.2020,(7).DOI:10.16383/j.aas.c190329 .
[3]李铭,郑苏生,姚磊岳.基于HOG+SVM实现对任意物体的检测[J].现代信息科技.2019,(24).
[4]沈寒蕾,张虎,张耀峰,等.基于长短期记忆模型的入室盗窃犯罪预测研究[J].统计与信息论坛.2019,(11).
[5]李若灵.上海市高速公路在免费通行节假日的运行特征分析[J].上海公路.2019,(2).DOI:10.3969/j.issn.1007-0109.2019.02.028 .
[6]张备伟,吴琦,刘光徽.基于DTW的交警指挥手势识别方法[J].计算机应用研究.2017,(11).DOI:10.3969/j.issn.1001-3695.2017.11.066 .
[7]李东洁,李洋洋,杨柳.GL-RBF优化的数据手套手势识别算法[J].哈尔滨理工大学学报.2017,(4).DOI:10.15938/j.jhust.2017.04.002 .
[8]刘杰,黄进,韩冬奇,等.模板匹配的三维手势识别算法[J].计算机辅助设计与图形学学报.2016,(8).DOI:10.3969/j.issn.1003-9775.2016.08.019 .
[9]杨学文,冯志全,黄忠柱,等.结合手势主方向和类-Hausdorff距离的手势识别[J].计算机辅助设计与图形学学报.2016,(1).DOI:10.3969/j.issn.1003-9775.2016.01.010 .
[10]赵思蕊,吴亚东,杨文超,等.基于3D骨架的交警指挥姿势动作识别仿真[J].计算机仿真.2016,(9).DOI:10.3969/j.issn.1006-9348.2016.09.090 .
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!