Python学习笔记(六):函数的多返回值、函数的多种参数使用形式、匿名函数、文件的读取操作、文件的写入 、文件的追加
目录
一、函数的多返回值
#演示使用多个变量,接收多个返回值
deftest_return():
return1,"hello",True
x,y,z=test_return()
print(x)
print(y)
print(z)
结果为
1
hello
True
通过return返回多个值,用逗号隔开,可以用多个变量去接受他
注意对位,第一个变量接收第一个值,第二个变量接收第二个值。
二、函数的多种参数使用形式
2.1位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数
defuser_info(name,age,gender):
print(f'您的名字是{name},年龄是{age},性别是{gender}')
user_info('TOM',20,'男')
注意:传递的参数和定义的参数的顺序及个数必须一致
2.2关键字参数
关键字参数:函数调用时通过“键=值”形式传递参数.
作用: 可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求.
defuser_info(name,age,gender):
print(f'您的名字是{name},年龄是{age},性别是{gender}')
#关键字传参
user_info(name='TOM',age=20,gender='男')
#可以不按照固定顺序
user_info(age=20,gender='男',name='TOM')
#可以和位置参数混合使用,位置参数必须在前面,且匹配参数顺序
user_info('TOM',age=20,gender='男')注意:
?????? 函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
2.3缺省参数
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
作用: 当调用函数时没有传递参数, 就会使用默认是用缺省参数对应的值.
注意:
?????? 函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值,设置默认值统一放在最后面
defuser_info(name,age,gender='男'):
print(f'您的名字是{name},年龄是{age},性别是{gender}')
user_info('小明',34)
user_info('小明',34,'女')2.4不定长参数
不定长参数:不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
作用: 当调用函数时不确定参数个数时, 可以使用不定长参数
2.4.1位置传递
defuser_info(*args):
print(args)
#('TOM')
user_info('TOM')
#('TOM',18)
user_info('TOM',18)注意:
????? 传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
2.4.2关键字传递
defuser_info(**kwargs):
print(kwargs)
#{'name':'TOM','age':18,'id':110}
user_info(name='TOM',age=18,id=110)
注意:
????? 参数是“键=值”形式的形式的情况下, 所有的“键=值”都会被kwargs接受, 同时会根据“键=值”组成字典.
三、匿名函数
3.1 函数作为参数传递

函数compute,作为参数,传入了test_func函数中使用。
test_func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
compute函数接收2个数字对其进行计算,compute函数作为参数,传递给了test_func函数使用
最终,在test_func函数内部,由传入的compute函数,完成了对数字的计算操作
所以,这是一种,计算逻辑的传递,而非数据的传递。
就像上述代码那样,不仅仅是相加,相见、相除、等任何逻辑都可以自行定义并作为函数传入。
总结:
1. 函数本身是可以作为参数,传入另一个函数中进行使用的。
2. 将函数传入的作用在于:传入计算逻辑,而非传入数据。
3.2lambda匿名函数
3.2 函数的定义
def关键字,可以定义带有名称的函数
lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。
无名称的匿名函数,只可临时使用一次。
3.3 匿名函数定义语法:
lambda 传入参数:函数体(一行代码)
lambda 是关键字,表示定义匿名函数
传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
通过def关键字,定义一个函数,并传入。
deftest_func(compute):
result=compute(11,12)
print(result)
defcompute(x,y):
returnx+y
test_func(compute) #结果:23也可以通过lambda关键字,传入一个一次性使用的lambda匿名函数
deftest_func(compute):
result=compute(11,13)
print(result)
test_func(lambdax,y:x+y) #结果:24使用def和使用lambda,定义的函数功能完全一致,只是lambda关键字定义的函数是匿名的,无法二次使用
四、文件的读取操作
4.1 open()打开函数
在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下
open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
mode常用的三种基础访问模式

4.2 read()方法:
文件对象.read(num)num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
4.3 readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
f=open('python.txt')
content=f.readlines()
#['helloworld\n','abcdefg\n','aaa\n','bbb\n','ccc']
print(content)
#关闭文件
f.close()
4.4 readline()方法:一次读取一行内容
f=open('python.txt')
content=f.readline()
print(f'第一行:{content}')
content=f.readline()
print(f'第二行:{content}')
#关闭文件
f.close()
4.5 for循环读取文件行
forlineinopen("python.txt","r"):
print(line)
#每一个line临时变量,就记录了文件的一行数据
4.6 close() 关闭文件对象
f=open("python.txt","r")
f.close()
#最后通过close,关闭文件对象,也就是关闭对文件的占用
#如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用。
4.7 with open 语法
withopen("python.txt","r")asf:
f.readlines()
#通过在withopen的语句块中对文件进行操作
#可以在操作完成后自动关闭close文件,避免遗忘掉close方法
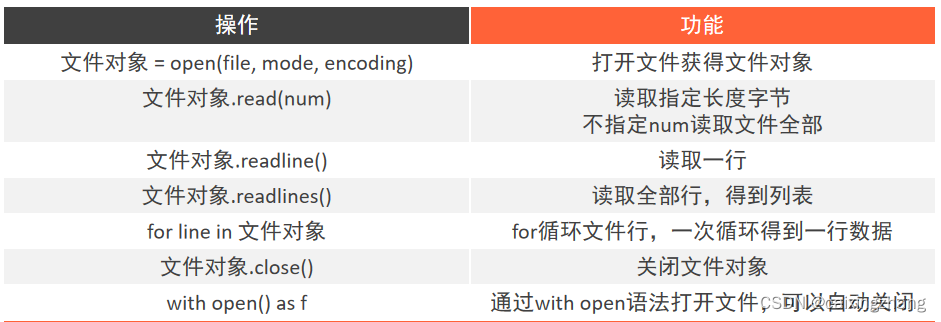
操作汇总?
练习:
通过Windows的文本编辑器软件,将如下内容,复制并保存到:word.txt,文件可以存储在任意位置
itheima itcast python
itheima python itcast
beijing shanghai itheima
shenzhen guangzhou itheima
wuhan hangzhou itheima
zhengzhou bigdata itheima
通过文件读取操作,读取此文件,统计itheima单词出现的次数
#打开文件,以读取模式打开
f=open("D:/word.txt","r",encoding="UTF-8")
#方法1:读取全部内容,通过字符串count方法统计itheima单词数量
content=f.read()
count=content.count("itheima")
print(f"itheima在文件中出现了:{count}次")
#方法2:读取内容,一行一行读取
#判断单词出现次数并积累
count=0#使用count变量来累计itheima出现的次数
forlineinf:
line=line.strip()#通过strip去除开头和结尾的空格以及换行符
words=line.split("")
forwordinwords:
ifword=="itheima":
count+=1#如果单词是itheima,进行数量的累加加1
print(f"itheima在文件中出现了:{count}次")
#关闭文件
f.close()
五、文件的写入?
#1.打开文件
f=open('python.txt','w')
#2.文件写入
f.write('helloworld') #写入内存
#3.内容刷新
f.flush() #将内存中积攒的内容,写入到硬盘的文件中
注意:
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
写操作注意:
文件如果不存在,使用”w”模式,会创建新文件
文件如果存在,使用”w”模式,会将原有内容清空
close方法,内置了flush的功能
六、文件的追加
#1.打开文件,通过a模式打开即可,写法和前面一样
f=open('python.txt','a')
#2.文件写入
f.write('helloworld') #写入内存
#3.内容刷新
f.flush() #将内存中积攒的内容,写入到硬盘的文件中
注意:
a模式,文件不存在会创建文件
a模式,文件存在会在最后,追加写入文件
可以使用”\n”来写出换行符
练习:
需求:有一份账单文件,记录了消费收入的具体记录,内容如下:
name,date,money,type,remarks
周杰轮,2022-01-01,100000,消费,正式
周杰轮,2022-01-02,300000,收入,正式
周杰轮,2022-01-03,100000,消费,测试
林俊节,2022-01-01,300000,收入,正式
林俊节,2022-01-02,100000,消费,测试
林俊节,2022-01-03,100000,消费,正式
林俊节,2022-01-04,100000,消费,测试
林俊节,2022-01-05,500000,收入,正式
张学油,2022-01-01,100000,消费,正式
张学油,2022-01-02,500000,收入,正式
张学油,2022-01-03,900000,收入,测试
王力鸿,2022-01-01,500000,消费,正式
王力鸿,2022-01-02,300000,消费,测试
王力鸿,2022-01-03,950000,收入,正式
刘德滑,2022-01-01,300000,消费,测试
刘德滑,2022-01-02,100000,消费,正式
刘德滑,2022-01-03,300000,消费,正式
可以将先内容复制并保存为 bill.txt文件
我们现在要做的就是:
读取文件
将文件写出到bill.txt.bak文件作为备份
同时,将文件内标记为测试的数据行丢弃
实现思路:
open和r模式打开一个文件对象,并读取文件
open和w模式打开另一个文件对象,用于文件写出
for循环内容,判断是否是测试不是测试就write写出,是测试就continue跳过
将2个文件对象均close()
#打开文件并得到文件对象:准备读取
fr=open("D:/zzz.txt","r",encoding="UTF-8")
#打开文件得到文件对象,准备写入
fw=open("D:/zzz.txt.bak","w",encoding="UTF-8")
#for循环读取文件
forlineinfr:
line=line.strip()#通过strip()开头和结尾的空格以及回车换行符去掉
#判断内容,将满足的内容写出
ifline.split(",")[4]=="测试":
continue#continue进入下一次循环,这一次后面的内容就跳过了
#将内容写出去
fw.write(line)
#由于前面对内容进行了strip()的操作,所以要手动的写出换行符
fw.write("\n")
#close2个文件对象
fr.close()
fw.close()#写出文件调用close()会自动flush()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!