探索统计学:Python中的Statsmodels库统计推断
写在开头
统计推断是数据科学中的一个核心领域,它通过从样本中提取信息来对整个总体进行推断。在实际的数据分析中,我们常常需要了解样本的特征,并基于这些样本推断总体的性质。这正是统计学的魅力所在。在本文中,我们将深入研究统计推断的各个方面,着重介绍在Python中应用广泛的Statsmodels库。
1.参数估计与假设检验
1.1 参数估计的基本概念
参数估计是统计学中的一个关键概念,它涉及从样本数据中估计总体参数的值。在数据分析中,参数估计是了解和推断总体特征的基础,对于做出可靠的统计推断和预测是至关重要的。
1.1.1 什么是参数?
在统计学中,参数是总体的特征值,它可以是总体均值、总体标准差、总体比例等。参数是我们希望了解和推断的数量,但通常情况下,我们无法直接观察到总体,只能通过样本来进行估计。
1.1.2 参数估计的目的
参数估计的目的是通过样本数据推断总体参数的值。通过对样本数据的分析,我们希望获得对总体参数的良好估计,以便更好地了解总体的性质。参数估计通常与置信区间和假设检验等方法一起使用,提供对估计的不确定性的度量。
1.1.3 数据分析中的应用
-
预测性分析
- 在数据分析中,我们常常需要根据样本数据对未来事件进行预测。参数估计是建立预测模型的基础,通过估计模型的参数,我们可以进行未来值的预测,例如销售量、用户行为等。
-
A/B 测试
- A/B 测试是一种常见的实验设计方法,用于比较两个或多个变体的效果。参数估计在 A/B 测试中广泛应用,例如估计不同变体的平均值、点击率等参数,以便比较它们的性能。
-
质量控制
- 在制造业或生产过程中,参数估计用于估计产品的平均质量、标准差等参数。根绝这些参数,监控和改进生产过程,确保产品质量的稳定性。
-
医学研究
- 在医学研究中,参数估计用于估计治疗效果、患病率等参数。这对于制定临床决策、评估医疗干预的有效性至关重要。
1.2 使用Statsmodels进行参数估计和假设检验
Statsmodels库为参数估计和假设检验提供了丰富的工具。我们将探讨如何使用Statsmodels进行参数估计,并通过假设检验验证我们的推断。
当使用Statsmodels进行参数估计和假设检验时,通常会涉及线性回归模型。我将提供一个简单的场景,使用Python代码演示如何使用Statsmodels进行线性回归、参数估计和假设检验。下面将使用包含学生的学习时间和考试成绩的数据信息。
import pandas as pd
import statsmodels.api as sm
# 创建虚构的数据集
data = {
'StudyHours': [5, 8, 3, 7, 2, 6, 4, 9, 1, 8],
'ExamScore': [65, 80, 50, 75, 45, 70, 55, 85, 40, 78]
}
df = pd.DataFrame(data)
# 添加截距项
df['Intercept'] = 1
# 定义自变量和因变量
X = df[['Intercept', 'StudyHours']]
y = df['ExamScore']
# 创建线性回归模型
model = sm.OLS(y, X)
# 拟合模型
results = model.fit()
# 打印模型摘要
print(results.summary())
运行上述代码后,结果如下:
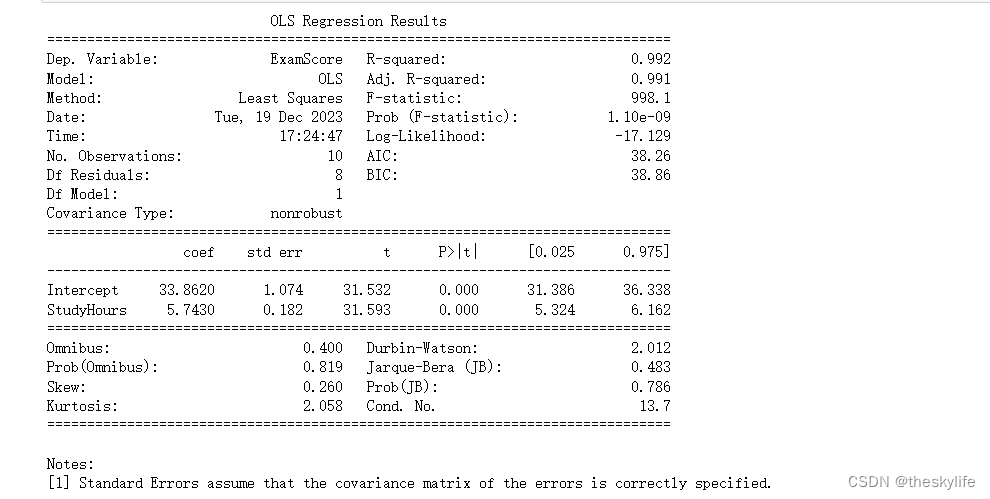
在上述输出的模型摘要中,我们特别关注以下几个部分:
-
coef(系数):
StudyHours的系数表示每增加一个学习小时,考试成绩平均增加的分数,上图中为5.74分。 -
p-value(p值): 表示假设检验的结果。在这里,我们关注
StudyHours的p值,它表示与考试成绩之间的关系是否显著,上图中为0.000,远小于0.05。 -
系数解释:
- 截距(Intercept):截距表示当学习时间为0小时时,预测的考试成绩,在本例中为38.86。
StudyHours的系数:表示每增加一个学习小时,考试成绩平均增加的分数,在本例中为5.74。
-
假设检验:
- 零假设(H0): 学习时间与考试成绩之间没有显著关系(系数为零)。
- 备择假设(H1): 学习时间与考试成绩之间存在显著关系(系数不为零)。
通过观察模型摘要中 StudyHours 系数的p值,如果p值小于显著性水平(通常选择0.05),我们拒绝零假设,接受备择假设。在实际场景中,我们可能会使用这个模型来预测学生的考试成绩,了解学习时间对成绩的影响,并且可以根据假设检验的结果来评估这种影响是否显著。
2.置信区间与假设检验
2.1 置信区间的含义
置信区间(Confidence Interval, CI)提供了对参数估计的不确定性的一种度量。在统计学中,我们往往希望通过置信区间来评估我们对总体参数的估计的可信程度。它提供了一个范围,我们可以合理地认为这个范围包含了真实的未知参数值。置信区间通常与假设检验一同使用,有助于我们对参数估计的不确定性有更全面的认识。
下面详细解释置信区间的一些知识
-
点估计与区间估计:
- 点估计: 是对参数进行单一值的估计,例如平均值、回归系数等。
- 区间估计: 是对参数估计提供一个区间,用来表示我们相信真实参数值可能存在的范围。
-
置信水平:
- 置信水平是一个概率,通常以百分比形式表示,例如95%置信水平。
- 95%置信水平的含义是,如果我们在不同的样本中重复抽样,并计算置信区间,那么大约95%的区间将包含真实的未知参数。
-
置信区间的解释:
- 如果我们计算出一个95%置信区间为 [a, b],这并不是说真实参数值有95%的概率在 [a, b] 之间。
- 正确的解释是,在多次抽样中,我们期望有95%的样本会产生包含真实参数的置信区间。
-
置信区间的宽度:
-
置信区间的宽度反映了对参数估计的不确定性。较宽的置信区间表示对参数估计不太确定,较窄的置信区间表示估计相对稳定。
-
举个栗子,假设我们计算出一个95%置信区间为 [10, 20],这意味着在多次抽样中,我们期望95%的置信区间将包含真实的未知参数。并不是说真实参数值有95%的概率在 [10, 20] 之间。
-
-
与假设检验的关系:
- 置信区间和假设检验是相关的。如果置信区间包含零,那么相应的假设检验可能不拒绝零假设;如果不包含零,可能拒绝零假设。
总体而言,置信区间提供了一种更全面的估计方法,相比于点估计,它更能反映参数估计的不确定性。在解释置信区间时,关键是理解它不提供某个确定值,而是提供了一个范围,我们对真实参数值在这个范围内有一定信心。
2.2 利用Statsmodels进行置信区间估计和假设检验
Statsmodels库为置信区间估计和假设检验提供了直观且易于使用的接口。
假设我们有一份关于一组工程项目的数据集,其中包含了项目的成本和两个潜在的影响因素:工程规模(ProjectSize)和工程复杂度(ProjectComplexity)。我们想要通过多元线性回归分析来估计成本,并计算出成本对这两个因素的回归系数的置信区间。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!