Flink之迟到的数据
2023-12-14 23:30:30
迟到数据的处理
- 推迟水位线推进:
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2)) - 设置窗口延迟关闭:
.allowedLateness(Time.seconds(3)) - 使用侧流接收迟到的数据:
.sideOutputLateData(lateData)
public class Flink12_LateDataCorrect {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> ds = env.socketTextStream("hadoop102", 8888)
.map(
line -> {
String[] fields = line.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2)) // 水位线延迟2秒
.withTimestampAssigner(
(event, ts) -> event.getTs()
)
);
ds.print("input");
OutputTag<WordCountWithTs> lateOutputTag = new OutputTag<>("late", Types.POJO(WordCountWithTs.class));
//new OutputTag<WordCount>("late"){}
SingleOutputStreamOperator<UrlViewCount> urlViewCountDs = ds.map(
event -> new WordCountWithTs(event.getUrl(), 1 , event.getTs())
).keyBy(
WordCountWithTs::getWord
).window(
TumblingEventTimeWindows.of(Time.seconds(10))
).allowedLateness(Time.seconds(5)) // 窗口延迟5秒关闭
.sideOutputLateData(lateOutputTag) // 捕获到侧输出流
.aggregate(
new AggregateFunction<WordCountWithTs, UrlViewCount, UrlViewCount>() {
@Override
public UrlViewCount createAccumulator() {
return new UrlViewCount();
}
@Override
public UrlViewCount add(WordCountWithTs value, UrlViewCount accumulator) {
accumulator.setCount((accumulator.getCount() == null ? 0L : accumulator.getCount()) + value.getCount());
return accumulator;
}
@Override
public UrlViewCount getResult(UrlViewCount accumulator) {
return accumulator;
}
@Override
public UrlViewCount merge(UrlViewCount a, UrlViewCount b) {
return null;
}
}
,
new ProcessWindowFunction<UrlViewCount, UrlViewCount, String, TimeWindow>() {
@Override
public void process(String key, ProcessWindowFunction<UrlViewCount, UrlViewCount, String, TimeWindow>.Context context, Iterable<UrlViewCount> elements, Collector<UrlViewCount> out) throws Exception {
UrlViewCount urlViewCount = elements.iterator().next();
//补充url
urlViewCount.setUrl(key);
//补充窗口信息
urlViewCount.setWindowStart(context.window().getStart());
urlViewCount.setWindowEnd(context.window().getEnd());
// 写出
out.collect(urlViewCount);
}
}
);
urlViewCountDs.print("window") ;
//TODO 将窗口的计算结果写出到Mysql的表中, 有则更新,无则插入
/*
窗口触发计算输出的结果,该部分数据写出到mysql表中执行插入操作,
后续迟到的数据,如果窗口进行了延迟, 窗口还能正常对数据进行计算, 该部分数据写出到mysql执行更新操作。
建表语句:
CREATE TABLE `url_view_count` (
`url` VARCHAR(100) NOT NULL ,
`cnt` BIGINT NOT NULL,
`window_start` BIGINT NOT NULL,
`window_end` BIGINT NOT NULL,
PRIMARY KEY (url, window_start, window_end ) -- 联合主键
) ENGINE=INNODB DEFAULT CHARSET=utf8
*/
SinkFunction<UrlViewCount> jdbcSink = JdbcSink.<UrlViewCount>sink(
"replace into url_view_count(url, cnt ,window_start ,window_end) value (?,?,?,?)",
new JdbcStatementBuilder<UrlViewCount>() {
@Override
public void accept(PreparedStatement preparedStatement, UrlViewCount urlViewCount) throws SQLException {
preparedStatement.setString(1, urlViewCount.getUrl());
preparedStatement.setLong(2, urlViewCount.getCount());
preparedStatement.setLong(3, urlViewCount.getWindowStart());
preparedStatement.setLong(4, urlViewCount.getWindowEnd());
}
},
JdbcExecutionOptions.builder()
.withBatchSize(2)
.withMaxRetries(3)
.withBatchIntervalMs(1000L)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUrl("jdbc:mysql://hadoop102:3306/test")
.withUsername("root")
.withPassword("000000")
.build()
);
urlViewCountDs.addSink(jdbcSink) ;
//捕获侧输出流
SideOutputDataStream<WordCountWithTs> lateData = urlViewCountDs.getSideOutput(lateOutputTag);
lateData.print("late");
//TODO 将侧输出流中的数据,写出到mysql中的表中,需要对mysql中已经存在的数据进行修正
//转换结构 WordCountWithTs => UrlViewCount
//调用flink计算窗口的方式, 基于当前数据的时间计算对应的窗口
SingleOutputStreamOperator<UrlViewCount> mapDs = lateData.map(
wordCountWithTs -> {
Long windowStart = TimeWindow.getWindowStartWithOffset(wordCountWithTs.getTs()/*数据时间*/, 0L/*偏移*/, 10000L/*窗口大小*/);
Long windowEnd = windowStart + 10000L;
return new UrlViewCount(wordCountWithTs.getWord(), 1L, windowStart, windowEnd);
}
);
// 写出到mysql中
SinkFunction<UrlViewCount> lateJdbcSink = JdbcSink.<UrlViewCount>sink(
"insert into url_view_count (url ,cnt , window_start ,window_end) values(?,?,?,?) on duplicate key update cnt = VALUES(cnt) + cnt ",
new JdbcStatementBuilder<UrlViewCount>() {
@Override
public void accept(PreparedStatement preparedStatement, UrlViewCount urlViewCount) throws SQLException {
preparedStatement.setString(1, urlViewCount.getUrl());
preparedStatement.setLong(2, urlViewCount.getCount());
preparedStatement.setLong(3, urlViewCount.getWindowStart());
preparedStatement.setLong(4, urlViewCount.getWindowEnd());
}
},
JdbcExecutionOptions.builder()
.withBatchSize(2)
.withMaxRetries(3)
.withBatchIntervalMs(1000L)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUrl("jdbc:mysql://hadoop102:3306/test")
.withUsername("root")
.withPassword("000000")
.build()
);
mapDs.addSink(lateJdbcSink) ;
try {
env.execute();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
withIdleness关键字
解决某条流长时间没有数据,不能推进水位线,导致下游窗口的窗口无法正常计算。
public class Flink12_WithIdleness {
public static void main(String[] args) {
//1.创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//默认是最大并行度
env.setParallelism(1);
SingleOutputStreamOperator<Event> ds1 = env.socketTextStream("hadoop102", 8888)
.map(
line -> {
String[] words = line.split(" ");
return new Event(words[0].trim(), words[1].trim(), Long.valueOf(words[2].trim()));
}
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(
(event, ts) -> event.getTs()
)
//如果超过10秒钟不发送数据,就不等待该数据源的水位线
.withIdleness(Duration.ofSeconds(10))
);
ds1.print("input1");
SingleOutputStreamOperator<Event> ds2 = env.socketTextStream("hadoop102", 9999)
.map(
line -> {
String[] words = line.split(" ");
return new Event(words[0].trim(), words[1].trim(), Long.valueOf(words[2].trim()));
}
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(
(event, ts) -> event.getTs()
)
//如果超过10秒钟不发送数据,就不等待该数据源的水位线
// .withIdleness(Duration.ofSeconds(10))
);
ds2.print("input2");
ds1.union(ds2)
.map(event->new WordCount(event.getUrl(),1))
.keyBy(WordCount::getWord)
.window(
TumblingEventTimeWindows.of(Time.seconds(10))
).sum("count")
.print("window");
try {
env.execute();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
基于时间的合流
窗口联结Window Join
WindowJoin: 在同一个窗口内的相同key的数据才能join成功。
orderDs.join( detailDs )
.where( OrderEvent::getOrderId ) // 第一条流用于join的key
.equalTo( OrderDetailEvent::getOrderId) // 第二条流用于join的key
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(
new JoinFunction<OrderEvent, OrderDetailEvent, String>() {
@Override
public String join(OrderEvent first, OrderDetailEvent second) throws Exception {
// 处理join成功的数据
return first + " -- " + second ;
}
}
).print("windowJoin");
时间联结intervalJoin
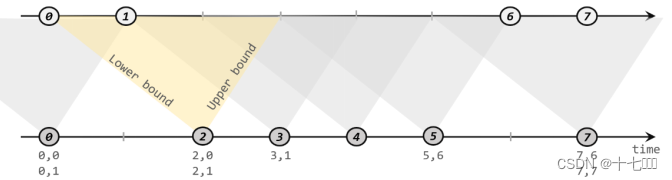
IntervalJoin : 以一条流中数据的时间为基准, 设定上界和下界, 形成一个时间范围, 另外一条流中相同key的数据如果能落到对应的时间范围内, 即可join成功。
核心代码:
orderDs.keyBy(
OrderEvent::getOrderId
).intervalJoin(
detailDs.keyBy( OrderDetailEvent::getOrderId)
).between(
Time.seconds(-2) , Time.seconds(2)
)
//.upperBoundExclusive() 排除上边界值
//.lowerBoundExclusive() 排除下边界值
.process(
new ProcessJoinFunction<OrderEvent, OrderDetailEvent, String>() {
@Override
public void processElement(OrderEvent left, OrderDetailEvent right, ProcessJoinFunction<OrderEvent, OrderDetailEvent, String>.Context ctx, Collector<String> out) throws Exception {
//处理join成功的数据
out.collect( left + " -- " + right );
}
}
).print("IntervalJoin");
文章来源:https://blog.csdn.net/qq_44273739/article/details/134921738
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!