protobuf 学习笔记
2024-01-08 13:04:05
protobuf 学习笔记
1. protobuf 的定义
protobuf是一种用于序列化结构数据的工具,实现数据的存储与交换,与编程语言和开发平台无关。
-
序列化:将结构数据或者对象转换成能够用于存储和传输的格式。
-
反序列化:在其他的计算环境中,将序列化后的数据还原为结构数据和对象。
下面是一个简单的使用示例:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_page = 3; [default=10] //设置默认值
}
其中后面的数字编号表示;二进制格式中识别各个字段的,一旦开始使用就不能再改变,[1,15]之内的标识号在编码的时候会占用一个字节,之后的[16,2047]会占用两个字节
1.1 指定字段规则:
- required: 表示该字段必须
- optional: 可选项,表示该字段必须有0个或者1个值(不超过一个)
- repeated: 可重复值,相当于List 基本数值类型的repeated的字段并没有被尽可能地高效编码。在新的代码中,用户应该使用特殊选项[packed=true]来保证更高效的编码。如:
注意:在proto3中没有这些选项
repeated int32 samples = 4 [packed=true];
2. protobuf 的优缺点
2.1、优点
- 性能高效:与XML相比,protobuf更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
- 语言无关、平台无关:protobuf支持Java、C++、Python 等多种语言,支持多个平台。
- 扩展性、兼容性强:只需要使用protobuf对结构数据进行一次描述,即可从各种数据流中读取结构数据,更新数据结构时不会破坏原有的程序。
2.2、缺点
- 不适合用来对基于文本的标记文档(如 HTML)建模。
- 自解释性较差,数据存储格式为二进制,需要通过proto文件才能了解到内部的数据结构。
3. protobuf 的使用流程
3.1 protoc编译器
使用proto文件定义好结构数据后,可以使用protoc编译器生成结构数据的源代码,这些源代码提供了读写结构数据的接口,从而能够构造、初始化、读取、序列化、反序列化结构数据。使用以下命令生成相应的接口代码:
// $SRC_DIR: .proto所在的源目录
// --cpp_out: 生成C++代码
// $DST_DIR: 生成代码的目标目录
// xxx.proto: 要针对哪个proto文件生成接口代码
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto
编译完成后将会生成一个xxx.pb.h和xxx.pb.cpp文件,会提供类似SerializeToOstream()、set_name()、name()等方法。
4. protobuf 的应用场景
- 压缩效率高:服务器间的海量数据传输与通信,可以节省磁盘和带宽,protobuf适合处理大数据集中的单个小消息,但并不适合处理单个的大消息。
- 解析速度快:可以提高服务器的吞吐能力。
5. protobuf 与 json 和 XML 的对比
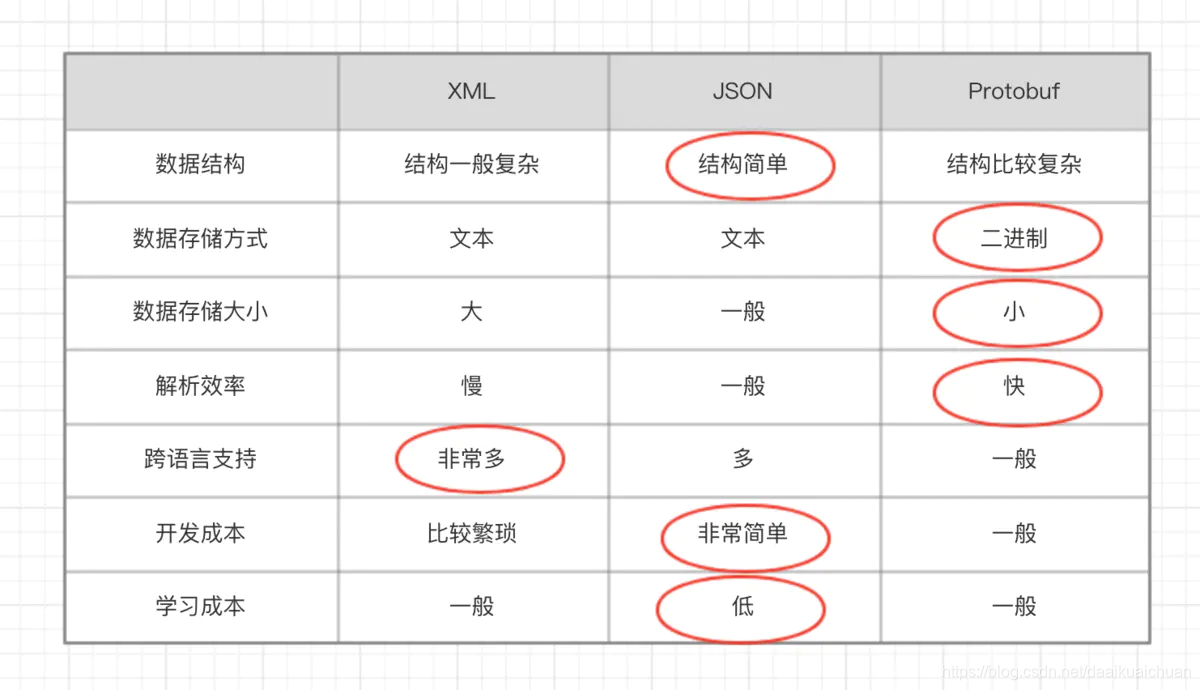
-
XML、JSON、protobuf都具有数据结构化和数据序列化的能力。
-
XML、JSON更注重数据结构化,关注可读性和语义表达能力;protobuf 更注重数据序列化,关注效率、空间、速度,可读性较差,语义表达能力不足。
-
protobuf的应用场景更为明确,XML、JSON的应用场景更为丰富。
文章来源:https://blog.csdn.net/weixin_46645965/article/details/135453923
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!