【史上最本质】序列模型:RNN、双向 RNN、LSTM、GRU、Seq-to-Seq、束搜索
序列模型:RNN、双向 RNN、LSTM、GRU、Seq-to-Seq、束搜索
?
序列模型是啥
普通的神经网络模型不适合处理序列数据。
- 数据集每个样本长度不一样
- 不能关联文本不同位置特征
- 计算量大问题
序列模型相比普通模型更适合处理具有时序性质的数据,主要解决以下问题:
-
建模时序关系:序列模型能够捕捉序列数据中的时序关系和上下文信息,通过考虑数据点之间的依赖关系,更准确地预测和生成序列。
-
处理变长序列:序列模型能够处理变长序列,即序列长度不固定的情况。相比普通模型需要固定长度的输入,序列模型更适合处理语音、文本等长度可变的数据。
-
模型内存储信息:序列模型通常具有记忆机制,能够存储和更新之前的状态,使得模型能够处理长期依赖关系,从而更好地理解和预测序列数据。
-
应对上下文依赖:序列模型能够捕捉上下文依赖,即当前数据点的输出受到之前数据点的影响。相比普通模型,序列模型能够更好地捕捉数据之间的关联性,适用于语音识别、机器翻译等任务。
总之,序列模型相对于普通模型更适合处理具有时序性质的数据,能够更好地捕捉序列中的时序关系和上下文信息,从而提高模型的性能和效果。
RNN 结构
序列模型有很多,比如 RNN。
在传统神经网络的基础上引入了循环连接,能够通过记忆过去的信息来处理当前的输入,从而能够处理变长序列数据、捕捉序列数据中的上下文关系。

输入:并不是一整句输入,而是一个一个词的输入
RNN的计算可以简单地描述为以下几个步骤:
-
第1次处理:将第一个词作为输入传递给RNN,并根据权重参数计算隐藏状态和输出。
-
第2次处理:将第二个词作为输入传递给RNN,同时使用前一个时间步的隐藏状态计算当前时间步的隐藏状态和输出。
-
第3次处理:将第三个词作为输入传递给RNN,同时使用前一个时间步的隐藏状态计算当前时间步的隐藏状态和输出。
-
第4次处理:将第四个词作为输入传递给RNN,同时使用前一个时间步的隐藏状态计算当前时间步的隐藏状态和输出。
-
第5次处理:将第五个词作为输入传递给RNN,同时使用前一个时间步的隐藏状态计算当前时间步的隐藏状态和输出。
将前一个时间步的输出,作为后一个时间步的输入,RNN能够逐渐积累和传递信息。
从而对整个序列进行建模和预测。
这样,RNN能够捕捉到序列数据中的上下文关系和时序信息。
双向 RNN
但 RNN 这种结构也有局限。
ta只依赖前面输入的单词,而没有看后面的单词。
但有些句子,后面的单词会直接反转整个句子的意思。
- 我不是个好父亲,不是个好丈夫,不是个好儿子,但那又怎样呢?我是个小仙女呀。
- 我每天都坚持做仰卧起坐,晚上一个仰卧,早上一个起坐
- 无论最后我们疏远到什么样子,一个红包就能回到最初
或者有些句子,不通过后面的词,无非判断是人名,还是物名:
- 胃,你能不能别疼了?第一我不叫胃,我叫楚雨荨!
双向 RNN 结构:

分为前向、反向:
- 前向:从左到右计算一组激活值,是当前步之前的激活值叠加
- 反向:从右到左计算一组激活值,是当前步之后的激活值叠加
- 预测值:获取整个句子的所有时间步激活值
双向 RNN 准确性提高了,但必须等整个句子输入完全才可以预测。
长短期记忆递归神经网络 LSTM
RNN 在处理长序列时,由于梯度消失或梯度爆炸的问题,确实可能导致随着时间的推移,之前的输入对当前步的影响逐渐减弱。
这是由于在反向传播过程中,梯度信息的传递过程中出现的问题导致的。
这样的问题限制了传统RNN在捕捉长期依赖关系方面的能力。
- RNN 的设计机制,让越晚的输入对当前步的影越大,越早的输入影响越小,但在长序列关联关系处理的不好
LSTM 的思想就是,划重点,保留长序列中重要信息,遗忘不重要的
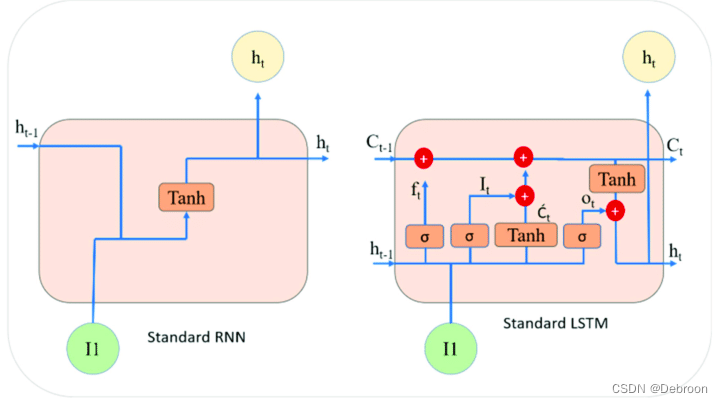
LSTM 通过引入了记忆单元和门控机制来解决这个问题。
- 记忆单元可以记住长期的信息
- 并通过门控机制来控制信息的流动
门控机制可以选择性地保留和遗忘信息,从而更好地控制梯度的流动,避免梯度消失或梯度爆炸的问题。

三个门控机制包括遗忘门、输入门和输出门,负责决定哪些信息需要保留、丢弃或输出:
- 遗忘门:决定了前一个记忆状态中哪些信息需要忘记,去掉一些不重要的
- 输入门:决定了当前输入中哪些信息需要被记忆,添加一些新的重要信息
- 输出门:决定了记忆单元中哪些信息需要输出
如果输入门全部关闭(激活值为0),遗忘门、输出门全部打开,本时间步等于上一步,绕过本步,把上一步传给下一步,很像残差连接。
这样就可以把前面的激活值传递到后面去,避免梯度消失或梯度爆炸的问题。
因此,LSTM相对于传统的 RNN 在处理长序列数据时表现更优秀,尤其在涉及到长期依赖关系的任务中,如机器翻译、语言建模等。
门控循环单元 GRU
GRU 是 LTSM 的简化版,LSTM 复杂但灵活,GRU 更轻量。

GRU 将 LSTM 三个门,简化为 2 个(重置门、更新门)。
- 重置门:从上一步中复制多少信息
- 更新门:从上一步隐藏状态中更新多少信息
编码器-解码器 Seq-to-Seq
编码器-解码器:将输入数据转换为另一种输出数据。
实现可能是这样:
- 英文转中文:一个 RNN 后,再接一个 RNN
- 文字转图像:一个 RNN 后,再接一个 CNN
为什么要这样?
输入数据转换为另一种输出数据,他们之间存在一个概率关系。
那能不能直接找到一个函数描述: y = f ( x ) y=f(x) y=f(x)
但发现不知道函数映射具体是什么样的, f f f 找不到,因为 x 、 y x、y x、y 不固定,输入输出长度都不相等。
可以先把输入数据 x 转为中间数据 z,再把 z 输出映射到 y 上,就实现了 x 到 y 映射。
?
举个例子,我们要将一张图片中的物体识别出来,并给出物体的类别。这个任务的输入是一张图片,输出是物体的类别标签。
如果我们直接将图片像素作为输入,并尝试找到一个函数 y = f ( x ) y = f(x) y=f(x) 来将像素映射为类别标签,会非常困难,因为图片的像素值是一个二维数组,无法直接映射为类别标签。
为了解决这个问题,我们可以先将图片经过一个卷积神经网络(CNN)转换为中间特征表示 z z z,这个中间特征可以捕捉到图片中的重要信息。
然后,我们可以将 z z z 作为输入,通过一个全连接层将其映射到类别标签 y y y 上,从而实现图片到类别标签的映射。
通过引入中间状态或中间数据,我们可以更好地处理输入和输出之间的关系,解决输入输出长度不固定的问题,并且能够更好地捕捉到输入数据的重要特征。
?
编码器:把不定长的输入,变成定长的上下文变量
解码器:解码上下文变量,生成输出序列
Beam Search 束搜索:选择最佳翻译结果
解码器会根据编码器生成的变量来一个一个时间步生成每个单词,如果词表有1000单词,就会生成1000单词对应的概率。
从这1000个概率中选出一个作为当前时间步的输出,那怎么保证每次是最佳结果呢?
第一反应,肯定是选概率最大的。
最大概率是有什么问题吗?
最大概率仅仅考虑了当前时间步的概率分布,而忽略了整个序列的全局信息。
大部分时候,最大概率的选择会导致整个序列的不连贯或者不合理。
这是因为生成序列的概率分布通常是一个复杂的非凸函数,存在多个局部最大值。
因此,仅仅依靠最大概率可能会陷入局部最优解,而无法得到整个序列的最佳结果。
为了解决这个问题,常用的方法是使用集束搜索(beam search)算法。
集束搜索会在每个时间步保留多个候选结果,然后根据一定的规则进行扩展和剪枝,最终选出整个序列概率最大的结果作为最佳结果。
通过保留多个候选结果,集束搜索能够充分利用全局信息,从而获得更好的结果。
但ta的问题也很明显,同时生成多个序列计算量太大。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!