1.1 理解大数据(2)
小肥柴的Hadoop之旅 1.1 理解大数据(2)
目录
1.1 理解大数据
1.1.3 大数据概述
step_0 大数据定义
【《大数据算法设计分析》】:
通常来讲大数据(Big Data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
对这段定义的理解重点在加粗的两处:
(1)“一定时间范围内”:这半句话其实揭示了一个事实,即很多大数据问题不是无法求解,而是无法在有限时间内高效的求解! ==> 若非要上升到理论视角,那就是NP问题的讨论。
(2)“信息资产”:之所以那么多公司、机构和研究者投入精力去做大数据方向的理论研究和工程实践,不就是因为需要熔炼这些数据去获取价值嘛?说白了还是太史公的那句话:“天下熙熙皆为利来…”,因此大家在学习大数据相关知识和技术的时候,有必要多问自己一句:“这个技术/工具/知识能够帮助我在处理大数据的时候产生价值吗?”,方便及时止损。
step_1 大数据特性(4V),老生常谈的话题,有兴趣的话自己可以去翻看一下相关文献资料。
<1> Volume(大量)
<2> Velocity(高速)
<3> Variety(多样)
<4> Value(低价值密度)
step_2 几个需要提前理解概念(与数据库相关)
<1> 联机事务处理OLTP(On-Line Transaction Processing)
<2> 联机分析处理OLAP(On-Line Analytical Processing)
<3> 数据仓库DW(Data Warehouse)
<4> ETL(Extral——抽取,Transform——清洗转换,Load——加载)
此处我们给出几个学习链接([1]~[7])供大家自学,仅需要记住:
(1)OLTP 是传统的关系型数据库的主要应用,事务处理,效率优先。
(2)OLAP 主要针对于数据的分析汇总操作,是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
(3)数据仓库 是为数据分析准备的“预制菜”存放地,为更高层次的数据分析提供原料。
(4)数据仓库的主要工作可以简单概括为:针对具体业务的建模和对应模型的ETL实现。
(5)以上概念的提出和对应业务的软件实现其实是业务需要的结果,是一个逐渐演进的过程。
【注】建议大家去看看微信公众号“特大号”对数据仓库的理解,通俗易懂的漫画,我比较喜欢里面的猫猫,我们借用一下人家描述ETL的图,侵删。
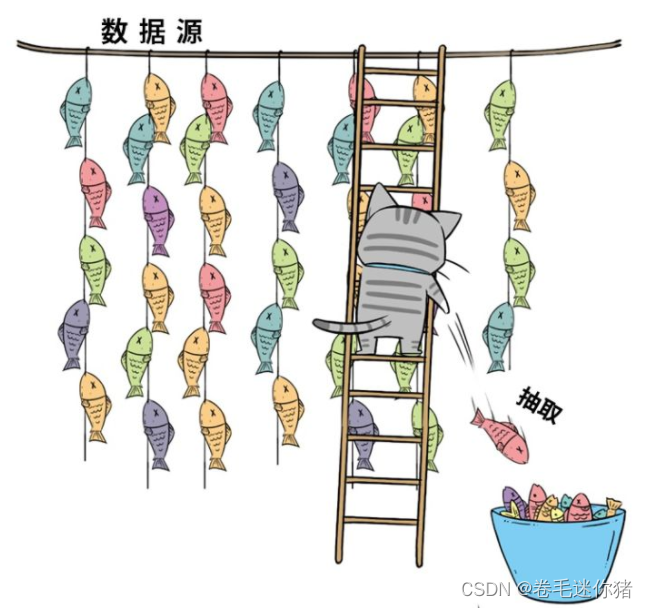

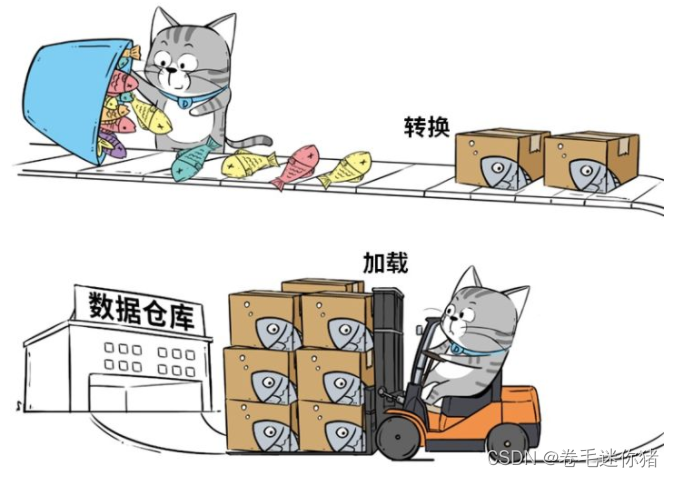
1.1.4 更多思考
最后有问题需要大家自己去寻找答案:
【Q1】数据仓库、数据湖、湖仓一体,究竟有什么区别?
【Q2】在《Hadoop权威指南》的P5(第一章 初识Hadoop)有一个观点 “大数据胜于好算法”

但是后来“吴恩达表示AI要转向小数据”,2023年大模型概念又出现了…请问咱们应该如何看待以上观点?
【浅显回答】大数据本身的价值含量不高,所以在使用前需要“提纯”,而高质量的数据集才是真正对分析和预测有益的。
【Q3】大数据计算的挑战和研究的问题有哪些?(偏理论向的问题,摘自《大数据算法设计分析》)
【A3】大数据计算面临的4个子问题:
(1)具有求解给定问题的高可用数据吗?
(2)若高可用数据存在,给定问题是可以计算的吗?
(3)若给定问题可以计算,那此问题的计算难吗?即:需要判定是否能在期望时间内求出问题的解?
(4)以上条件满足时,应该如何求解问题?即:合理设计求解给定问题的算法?
这些子问题的对应回答如下:
(1)大数据计算和应用亟需建立大数据可用性理论和相关算法。
(2)传统计算复杂性理论不适用于大数据计算。
<1> 计算模型是大数据计算复杂性理论的基础,现有传统模型不能基准刻画大数据计算:
i) 无法描述亚时间线性算法。
ii) 不能描述I/O复杂性和通信复杂性。
<2> 大量大数据问的计算复杂性问题未能有效解决。
i) 如何判定计算问题的难易?
ii) 如何判定难解问题是否可近似求解?
iii) 如何判断问题是否可并行求解?
iv) 问题的复杂性分类?空间计算复杂性? …
(3)传统的多项式时间算法不适于求解大数据计算问题。
<1>多项式算法执行时间长。
<2>数据密集型计算问题(e.g. 数据查询/挖掘/分析)具有多项式时间或者更高的计算复杂性。
(4)传统计算技术难以满足大数据计算需求:
<1> 传统高性能计算机系统是基于计算密集型计算需求设计的,不适用于分布式计算(不好蹭并行计算)。
<2> 云计算系统存在网络通信瓶颈(包括有线和无线的计算机网络和通信网络)。
<3> 需要面向大数据计算提供合适的计算软件框架。 ==> 这点工业界远远走在学术界前面。
综合以上描述,给出大数据研究的科学问题:
(1)建立能够准确描述大数据的计算模型。
(2)分析大数据计算问题空间的计算复杂性结构。
(3)确定大数据计算问题的固有复杂性。
(4)探索求解大数据计算问题的算法设计方法学。
(5)设计与分析求解大数据计算问题的高效算法。 => 有限资源做更多的事情,小马拉大车
(6)探索面向应用的大数据计算理论与方法。 => 交叉领域的应用
(7)探索大数据获取的理论与技术。 => 无价值数据最小化和有价值数据最大化,获取高可用数据
(8)探索大数据存储的理论与方法。 => 分布式存储,分布式数据库(体量/效率/安全/性能/能耗)
(9)探索大数据可用性的理论和方法。 => 评估、自动修复、近似计算
(10)研究支持大数据计算的计算机软硬件系统。 => 各种框架、生态和工具软件
参考文献和资料
[1] OLTP、OLAP介绍
[2] OLAP和OLTP的区别是什么?
[3] 数据库 与 数据仓库的本质区别是什么?(一)
[4] 数据库 与 数据仓库的本质区别是什么?(二)
[5] 秒懂数仓的前世今生:DBMS、DW、OLTP、OLAP到底是啥?(上篇)
[6] 秒懂数仓的前世今生:DBMS、DW、OLTP、OLAP到底是啥?(下篇)
[7] 数据仓库、数据湖、湖仓一体,究竟有什么区别?
[8] Small Data Challenges in Big Data Era: A Survey of Recent Progress on Unsupervised and Semi-Supervised Methods, Guo-Jun Qi, Senior Member, IEEE, and Jiebo Luo, Fellow, IEEE.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!