CNN、LeNet、AlexNet基于MNIST数据集进行训练和测试,并可视化对比结果
2023-12-13 07:35:18
完成内容:
- 构建
CNN并基于MNIST数据集进行训练和测试 - 构建
LeNet并基于MNIST数据集进行训练和测试 - 构建
AlexNet并基于MNIST数据集进行训练和测试 - 对比了不同网络在
MNIST数据集上训练的效果
准备工作
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
from matplotlib import pyplot as plt
import pandas as pd
from math import pi
下载数据,加载data_loader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'device:{device}')
batch_size = 256
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 加载数据(本步建议挂梯子)
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
# 加载data_loader
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
results = []
定义CNN和LeNet通用的训练函数和测试函数
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(train_loader)
def test(model, test_loader, criterion, device):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
return accuracy
构建CNN并基于MNIST数据集进行训练和测试
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.classifier = nn.Linear(16 * 14 * 14, 10)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# 展示网络内部结构
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in CNN().features:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
网络结构:
Conv2d output shape: torch.Size([1, 16, 28, 28])
ReLU output shape: torch.Size([1, 16, 28, 28])
MaxPool2d output shape: torch.Size([1, 16, 14, 14])
# 初始化CNN,优化器,损失函数
model = CNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
result = []
# 训练网络
num_epochs = 5
for epoch in tqdm(range(num_epochs), desc="training", unit="epoch"):
train_loss = train(model, train_loader, criterion, optimizer, device)
test_acc = test(model, test_loader, criterion, device)
result.append(test_acc)
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {train_loss:.4f}, Test Accuracy: {test_acc:.4f}')
results.append(result)
results
LeNet-MNIST
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(), # (1, 6, 28, 28)
nn.AvgPool2d(kernel_size=2, stride=2), # (1, 6, 14, 14)
nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(), # (1, 16, 10, 10)
nn.AvgPool2d(kernel_size=2, stride=2), # (1, 16, 5, 5)
nn.Flatten(), # (1, 400)
nn.Linear(16 * 5 * 5, 120), nn.ReLU(), # (1, 120)
nn.Linear(120, 84), nn.ReLU(), # (1, 84)
nn.Linear(84, 10) # (1, 10)
)
def forward(self, x):
x = self.features(x)
return x
# 展示LeNet网络内部结构
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in LeNet().features:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
# 网络结构:
Conv2d output shape: torch.Size([1, 6, 28, 28])
ReLU output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
ReLU output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
ReLU output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
ReLU output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
# 初始化CNN,优化器,损失函数
model = LeNet().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
result = []
# 训练模型
num_epochs = 5
for epoch in tqdm(range(num_epochs), desc="training", unit="epoch"):
train_loss = train(model, train_loader, criterion, optimizer, device)
test_acc = test(model, test_loader, criterion, device)
result.append(test_acc)
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {train_loss:.4f}, Test Accuracy: {test_acc:.4f}')
results.append(result)
results
AlexNet-MNIST
# 定义AlexNet
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 重新加载数据
transform = transforms.Compose([
transforms.Resize((227, 227)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 初始化AlexNet、优化器、损失函数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
alexnet = AlexNet(num_classes=10).to(device)
optimizer = optim.Adam(alexnet.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
result = []
# 训练
num_epochs = 5
for epoch in tqdm(range(num_epochs), desc="training", unit="epoch"):
alexnet.train()
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = alexnet(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 测试
alexnet.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = alexnet(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
result.append(accuracy)
print(f"Accuracy on test set: {accuracy * 100:.2f}%")
results.append(result)
结果分析
# Set data
df = pd.DataFrame(results)
columns = ['epoch1', 'epoch2', 'epoch3', 'epoch4', 'epoch5']
df.columns = columns
df['Network'] = ['CNN','LeNet', 'AlexNet']
print(df)
# ------- PART 1: Create background
# number of variable
categories=list(df)[:-1]
N = len(categories)
# What will be the angle of each axis in the plot? (we divide the plot / number of variable)
angles = [n / float(N) * 2 * pi for n in range(N)]
angles += angles[:1]
# Initialise the spider plot
ax = plt.subplot(111, polar=True)
# If you want the first axis to be on top:
ax.set_theta_offset(pi / 2)
ax.set_theta_direction(-1)
# Draw one axe per variable + add labels
plt.xticks(angles[:-1], categories)
# Draw ylabels
ax.set_rlabel_position(0)
plt.yticks([0.925,0.95,0.975], ["0.925","0.95","0.975"], color="grey", size=7)
plt.ylim(0.9,1)
# ------- PART 2: Add plots
# Plot each individual = each line of the data
# Ind1
values=df.loc[0].drop('Network').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="CNN")
ax.fill(angles, values, 'b', alpha=0.1)
# Ind2
values=df.loc[1].drop('Network').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="LeNet")
ax.fill(angles, values, 'r', alpha=0.1)
# Ind3
values=df.loc[2].drop('Network').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="AlexNet")
ax.fill(angles, values, 'g', alpha=0.1)
# Add legend
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
# Show the graph
plt.show()
epoch1 epoch2 epoch3 epoch4 epoch5 Network
0 0.9629 0.9764 0.9818 0.9823 0.9826 CNN
1 0.9461 0.9706 0.9781 0.9810 0.9869 LeNet
2 0.9844 0.9865 0.9887 0.9855 0.9900 AlexNet
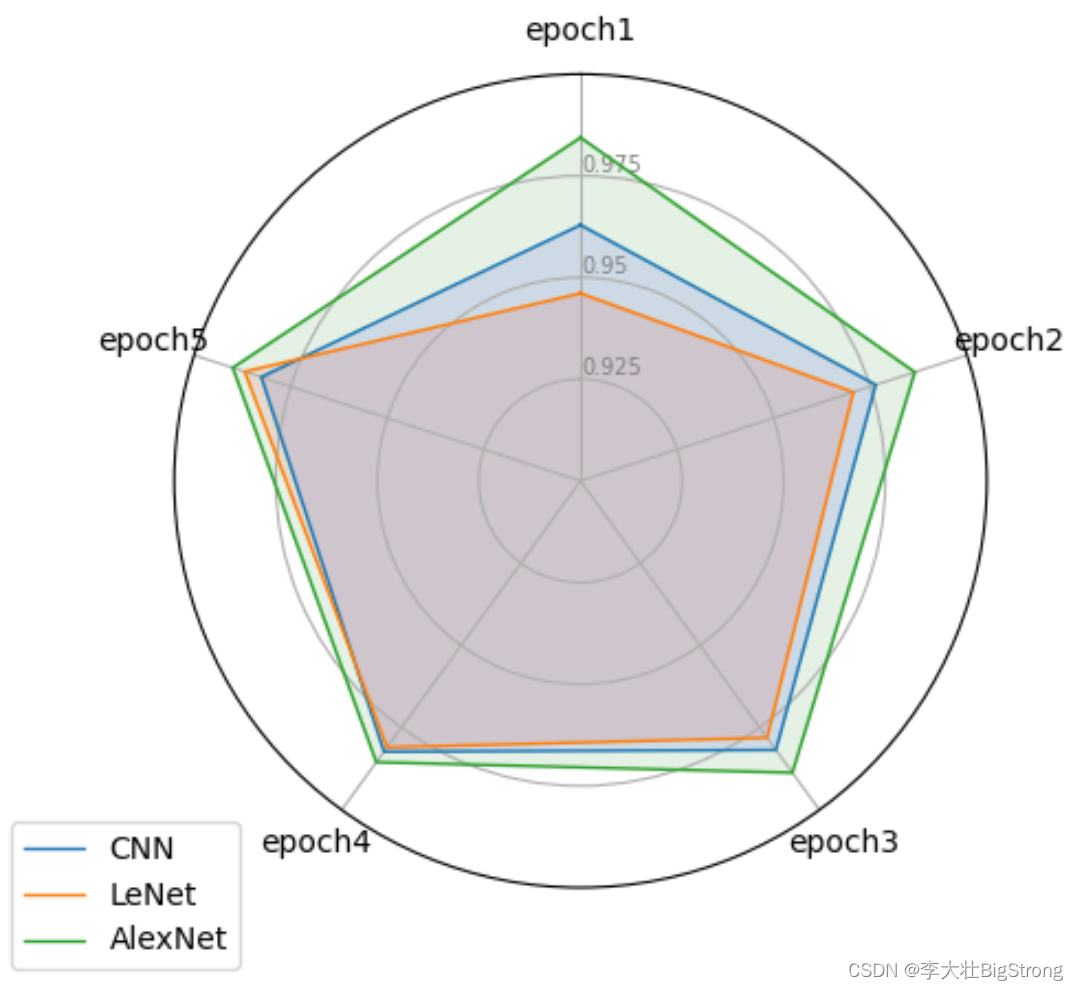
总体而言:
AlexNet效果更好,但Alex网络更复杂,计算开销更大;
CNN网络最简单,计算开销最小,效果也较好;
LeNet效果不如预期,按理来说LeNet网络更复杂,相较于CNN拟合效果应更好,但实际效果有偏差,怀疑是epoch较少,5个epoch不足以收敛
文章来源:https://blog.csdn.net/qq_46747888/article/details/134942676
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!