自己动手写编译器:使用 GoLex 实现 c 语言的词法解析
对编译器设计和开发而言,表明你能有效入门的证明就是你能做出一个针对 C 语言的编译器。完成了 C 语言编译器,你在编译原理领域里算是写出了第一个 hello world 程序。于是为了确认我们开发的 GoLex 功能完善,我们看看它是否能对 C 语言的语法有准确的解。
首先我们修改一处正则表达式解析的 bug,在 RegParser.go 中的term 函数做如下修改:
...
else {
/*
匹配 "." 本质上是匹配字符集,集合里面包含所有除了\r, \n 之外的ASCII字符
*/
start.edge = CCL
if r.lexReader.Match(ANY) {
for i := 0; i < ASCII_CHAR_NUM; i++ {
if i != int('\r') && i != int('\n') {
start.bitset[string(i)] = true
}
}
//bug here
//越过 '.'
r.lexReader.Advance()
...
如果上面代码不修改,我们解析表达式"(.)"时就会陷入死循环。另外在 LexReader 的 Advance 函数也需要做 bug 修改,修改如下:
func (l *LexReader) Advance() TOKEN {
...
if l.inquoted || sawEsc {
l.currentToken = L
//bug here
//当读取到反斜杠时代码会进入 esc()函数,在里面我们已经越过了反斜杠后面的字符,因此这里代码会导致我们越过反斜杠后面两个字符
//if sawEsc {
// //越过 / 后面的字符
// l.currentInput = l.currentInput[1:]
//}
} else {
l.currentToken = l.tokenMap[l.Lexeme]
}
...
}
另外在 nfa_interpretion.go 中的EpsilonClosure做如下 bug 修改:
func EpsilonClosure(input []*NFA) *EpsilonResult {
...
if node.edge == EPSILON {
//bug here
/*
result.results 是当前 epsilon 集合,应该判断它是否包含了给定节点,而不是在输入的 input
中判断,因为 node 就来自于 input 最后的节点
*/
if node.next != nil && stackContains(result.results, node.next) == false {
input = append(input, node.next)
}
//bug here
if node.next2 != nil && stackContains(result.results, node.next2) == false {
input = append(input, node.next2)
}
...
}
上面我们注释掉了部分代码,注释掉的原因在代码注释中也给了说明。另外还有一个 bug 在 CLex的 input.c 的 ii_advance()中,修改如下:
int ii_advance() {
...
//bug here,
int c = *Next;
Next++;
return c;
}
接着我们看看如何设置 input.lex 的内容,首先我们看模板文件的头部内容:
%{
/*
C 语言语法解析,yyout.h 用于定义字符串标签值,search.h 定义关键字表的查询接口
*/
#include "yyout.h"
#include "search.h"
%}
在模板文件的头部我们包含了两个头文件,yyout.h 主要用于定义一系列枚举值,分别对应 C 语言代码中字符串的标签,例如 ID, STRING 等,search.h 定义在关键字表中进行二分查找的函数定义,我们分别看看这些文件的内容。
在 CLex 工程中创建 yyout.h,其内容如下所示:
//
// Created by MAC on 2023/11/30.
//
#ifndef UNTITLED_YYOUT_H
#define UNTITLED_YYOUT_H
/* token value lexeme */
#define _EOI 0 /*输入结束标志*/
#define NAME 1 /*变量名 int a;*/
#define STRING 2 /*字符串常量 char* c="abc";*/
#define ICON 3 /*整型常量或字符串常量 1,2,3 'a', 'b', 'c';*/
#define FCON 4 /*浮点数常量*/
#define PLUS 5 /* + */
#define MINUS 6 /* - */
#define START 7 /* * */
#define AND 8 /* & */
#define QUEST 9 /* ? */
#define COLON 10 /* ? */
#define ANDAND 11 /* && */
#define OROR 12 /* || */
#define RELOP 13 /* > >= < <= */
#define EQUOP 14 /* == != */
#define DIVOP 15 /* / % */
#define OR 16 /* | */
#define XOR 17 /* ^ */
#define SHIFTOP 18 /* >> << */
#define INCOP 19 /* ++ -- */
#define UNOP 20 /* ! ~ */
#define STRUCTOP 21 /* . -> */
#define TYPE 22 /* int float char long ...*/
#define CLASS 23 /* extern static typedef ...*/
#define STRUCT 24 /* struct union */
#define RETURN 25 /* return */
#define GOTO 26 /* goto */
#define IF 27 /* if */
#define ELSE 28 /* else */
#define SWITCH 29 /* switch */
#define BREAK 30 /* break */
#define CONTINUE 31 /* continue */
#define WHILE 32 /* while */
#define DO 33 /* do */
#define FOR 34 /* for */
#define DEFAULT 35 /* default */
#define CASE 36 /* case */
#define SIZEOF 37 /* sizeof */
#define LP 38 /* ( 左括号 */
#define RP 39 /* ) 右括号 */
#define LC 40 /* { 左大括号 */
#define RC 41 /* } 右大括号 */
#define LB 42 /* [ 左中括号 */
#define RB 43 /* } 右中括号 */
#define COMMA 44 /* , */
#define SEMI 45 /* ; */
#define EQUAL 46 /* = */
#define ASSIGNOP 47 /* += -= */
#endif //UNTITLED_YYOUT_H
添加 search.h,并设置内容如下:
//
// Created by MAC on 2023/11/30.
//
#ifndef UNTITLED_SEARCH_H
#define UNTITLED_SEARCH_H
/**
在关键字表中进行折半查找
*/
extern char* bsearch(char* key, char* base, int nel, int elsize, int (*compare)());
#endif //UNTITLED_SEARCH_H
后面我们会对 bsearch 函数的实现逻辑进行详细说明,下面我们接着模板文件中一些正则表达式的宏定义
%{
/*
C 语言语法解析,yyout.h 用于定义字符串标签值,search.h 定义关键字表的查询接口
*/
#include "yyout.h"
#inlucde "search.h"
#include <stdio.h>
#include <stdarg.h>
void handle_comment();
void yyerror(char* fmt, ...);
%}
let [_a-zA-z]
alnum [_a-zA-Z0-9]
h [0-9a-fA-F]
o [0-7]
d [0-9]
suffix [UulL]
white [\x00-\s]
%%
上面定义中 let 表示的是字符,它包括了下横杆,alnum 是字符和数字的组合,也包括下横杆,h 对应 16 进制数,o 对应 8 进制数,suffix 对应整形数后缀,white 把 ascii 中 0 到空格这段区间中的字符全看作空格。
下面我们看 c 语言对应正则表达式的定义
"/*" {handle_comment();}
\"(\\.|[^\"])*\" {printf("this is a string: %s\n", yytext); /*return STRING*/;}
\"(\\.|[^\"])*[\r\m] yyerror("Adding missing \" to string constant\n")
第一个正则表达式就是匹配字符串"/*“,在 c 语言中他意味着进入到注释部分,一旦遇到这两个字符,我们就调用 handle_comment()函数进行处理。上面有一个不好理解的表达式那就是\ " * \.| [ ^ \ " ] ) * \ " 这里需要注意,其中的反斜杠作用是转义,” 表示这里的双引号就是一个普通字符,他不代表正则表达式中的特殊符号。这个表达是匹配 c 语言中的字符串常量,例如:
char* ptr = "hello world!";
上面代码中,hello world 字符串就可以匹配我们上面定义的表达式。也就是当我们一旦遇到一个双引号开始时,我们就进入字符串识别阶段,直到我们遇到第二个双引号为止。从第一个双引号开始,所有不是双引号的字符我们都需要把它作为字符串的字符来看待,这也是[ ^ " ]这个表达式的作用。需要注意的是我们还特意匹配 \ \ . ,这里第一个反斜杆是转义字符,也就是在第一个双引号后,所有反斜杠加一个字符的组合都当做一个特定字符来识别,例如:
char* ptr = "hello \n world!";
注意上面代码中\n 代表一个字符,也就是换行符,而不是两个字符。表达式\ " ( \ \ . | [ ^ \ " ] ) *[\r\m]字符串中所有字符必须在同一行,字符串中不能用回车或换行来分成两行。另外在上面模板代码中我们增加了一个输出错误的函数 yyerror,我们将其实现在模板函数中,该函数本质是对 printf的封装,只不过它输出到标准错误输出,其实也是控制台,同时它使用了 c 语言的可变长参数机制,这样我们能给他输入任意多个参数,其实现我们在下面给出。我们采用增量开发的方式,先看看 GoLex 是否能正确处理当前的模板内容,首先我们先给出当前整个模板内容:
%{
/*
C 语言语法解析,yyout.h 用于定义字符串标签值,search.h 定义关键字表的查询接口
*/
#include "yyout.h"
#include "search.h"
void handle_comment();
%}
let [_a-zA-z]
alnum [_a-zA-Z0-9]
h [0-9a-fA-F]
o [0-7]
d [0-9]
suffix [UulL]
white [\x00-\s]
%%
"/*" {handle_comment();}
\"*\\.|[^\"])*\" return STRING;
\"(\\.|[^\"])*[\r\n] yyerror("Adding missing \" to string constant\n")
%%
void handle_comment() {
int i;
while (i = ii_input()) {
if (i < 0)
ii_flushbuf(); //放弃当前识别的字符串
else if (i == '*' && ii_lookahead(1) == '/') {
//识别到注释末尾
printf("at the end of comment...");
ii_input();
break;
}
}
if (i == 0) {
yyerror("End of file in comment\n");
}
}
void main() {
ii_newfile("/Users/my/Documents/CLex/input.txt");
yylex();
}
需要注意 handle_comment 函数的实现,他将所有出现在/* 之后的字符全部丢弃,直到它遇到
* /为止。我们运行 GoLex 然后将生成的 lex.yy.c 中内容拷贝到 CLex 中的 main.c 看看运行情况。在 CLex 的 input.txt 文件中,我们设置用于测试正则表达式的内容:
/*this is a c comment*/
"this is a c string that contains \s \t and \" "
"this is a error c comment
完成上面工作后,我们编译 CLex 看看其运行结果:
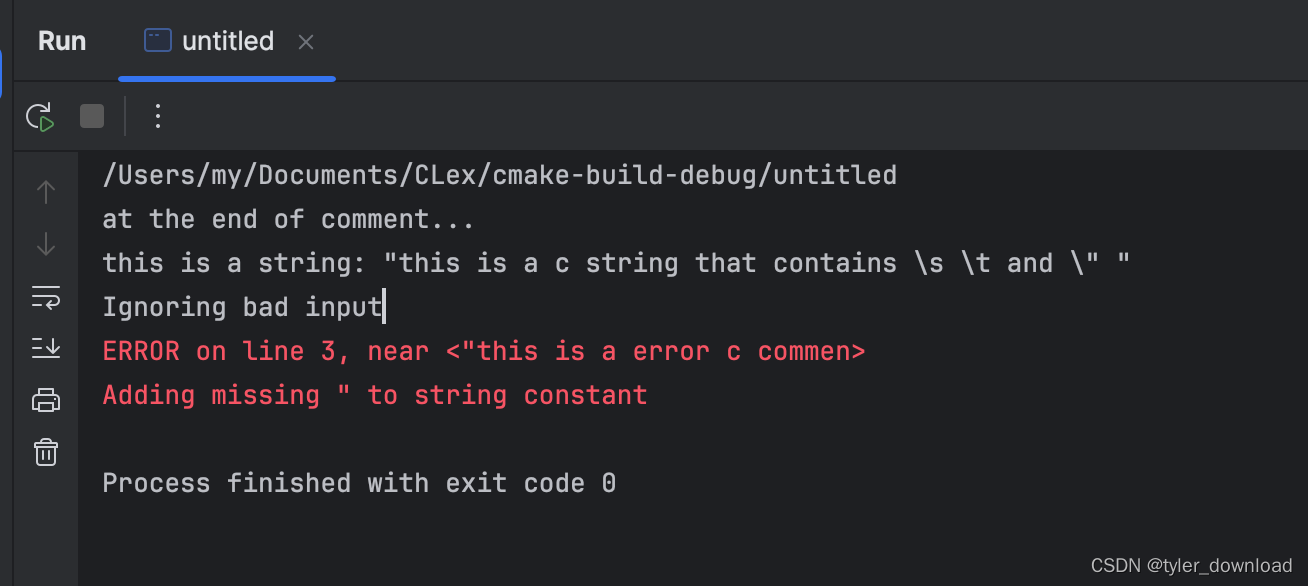
从上面结果看给定正则表达式的识别结果与预期一致。我们继续在模板文件中添加新的表达式然后看看识别效果是否正确,添加的新表达式如下:
'.'|
'\\.'|
'\\{o}({o}{0}?)?'
'\\x{h}({h}{h}?)?'|
'0{o}*{suffix}?'|
0x{h}+{suffix}?|
[1-9]{d}*{suffix}? return ICON;
在上面表达式中匹配如下代码的等号右边部分:
int a = 'a'; //匹配'.'
int b = '\t'; //匹配 '\\.'
int c = '\123'; //匹配 \\{o}({o}{o}?)?
int d = '\x123'; //匹配 '\\x{h}({h}{h}?)?'
int e = 012L; //匹配 0{o}{suffix}?
int f = 0x123L; //匹配 0x{h}+{suffix}?
int g = 123L; //匹配 [1-9]{d}*{suffix}?
可以看到上面数值都对应 c 语言中整型的定义。我们看看 c 语言浮点数的定义:
({d}+|{d}+\.{d}*|{d}*\.{d}+)([eE][-+]?{d}+)?[fF]? return FCON;
上面表达式匹配例子如下:
float a = 1f;
float b = 3.14;
float c = 314e-10; //3.14
完成上面内容后运行 GoLex 生成 lex.yy.c,将其内容拷贝到 CLex 的 main.c,并在 CLex 中的 input.txt 添加如下字符串来进行测试:
'a'
'b'
'\t'
'\f'
'\123'
012
0123L
0x123
0x123L
123
123L
3.14
123.456
1e3
123e+3
123.456e+3
1e-3
123.456e-4f
最后我们编译并运行 CLex后所得结果如下:
at the end of comment...
this is a string: "this is a c string that contains \s \t and \" "
find ICON: 'a'
find ICON: 'b'
find ICON: '\t'
find ICON: '\f'
find ICON: '\123'
find ICON: 012
find ICON: 0123L
find ICON: 0x123
find ICON: 0x123L
find ICON: 123
find ICON: 123L
find FCON: 3.14
find FCON: 123.456
find FCON: 1e3
find FCON: 123e+3
find FCON: 123.456e+3
find FCON: 1e-3
find FCON: 123.456e-4f
ERROR on line 4, near <"this is a error c comment
>
Adding missing " to string constant
接着我们增加对 c 语言操作符的词法解析,在input.lex 中添加如下内容:
"(" {printf("it is LP\n"); /*return LP;*/}
")" {printf("it is RP\n"); /*return RP;*/}
"{" {printf("it is LC\n"); /*return LC;*/}
"}" {printf("it is RC\n"); /*return RC;*/}
"[" {printf("it is LB\n"); /*return LB;*/}
"]" {printf("it is RB\n"); /*return RB;*/}
"->"|
"." {printf("struct operator:%s\n", yytext); /*return STRUCTOP;*/}
"++"|
"--" {printf("INCOP: %s\n", yytext); /*return INCOP;*/}
"*" {printf("START OP\n"); /*return START;*/}
[~!] {printf("UNOP:%s\n", yytext); /*return UNOP;*/}
"*" {printf("START OP\n"); /*return START;*/}
[/%] {printf("DIVOP: %s\n", yytext); /*return DIVOP;*/}
"+" {printf("PLUS\n"); /*return PLUS;*/}
"-" {printf("MINUS\n"); /*return MINUS;*/}
<<|>> {printf("SHIFTOP: %s\n",yytext); /*return SHIFTOP;*/}
[<>]=? {printf("RELOP: %s\n", yytext); /*return RELOP;*/}
[!=]= {printf("EQUOP: %s\n", yytext); /*return EQUOP;*/}
[*/%+-&|^]=|
(<<|>>)= {printf("ASSIGN OP: %s\n", yytext); /*return ASSIGNOP;*/}
"=" {printf("EQUAL: %s\n", yytext); /*return EQUAL;*/}
"&" {printf("AND: %s\n", yytext); /*return AND;*/}
"^" {printf("XOR: %s\n", yytext); /*return XOR;*/}
"|" {printf("OR: %s\n", yytext); /*return OR;*/}
"&&" {printf("ANDAND: %s\n", yytext); /*return ANDAND;*/}
"||" {printf("OROR: %s\n", yytext); /*return OROR;*/}
"?" {printf("QUEST: %s\n", yytext); /*return QUEST;*/}
":" {printf("COLON: %s\n", yytext); /*return COLON;*/}
"," {printf("COMMA: %s\n", yytext); /*return COMMA;*/}
";" {printf("SEMI: %s\n", yytext); /*return SEMI;*/}
然后执行 GoLex,生成新的 lex.yy.c,将其拷贝到 CLex 的 main.c 中,同时在 CLex 的 input.txt 中添加如下用于测试的新内容:
(
)
{
}
[
]
->
.
++
--
/
%
+
-
<<
>>
<
>
<=
>=
!=
==
*=
/=
+=
-=
&=
|=
^=
<<=
>>=
=
^
|
&&
||
?
:
,
;
然后我们执行 CLex 对添加的新字符串进行解析,最后所得结果如下:
t is LP
it is RP
it is LC
it is RC
it is LB
it is RB
struct operator:->
struct operator:.
INCOP: ++
INCOP: --
DIVOP: /
DIVOP: %
PLUS
MINUS
SHIFTOP: <<
SHIFTOP: >>
RELOP: <
RELOP: >
RELOP: <=
RELOP: >=
EQUOP: !=
EQUOP: ==
ASSIGN OP: *=
ASSIGN OP: /=
ASSIGN OP: +=
MINUS
EQUAL: =
AND: &
EQUAL: =
ASSIGN OP: |=
ASSIGN OP: ^=
ASSIGN OP: <<=
ASSIGN OP: >>=
EQUAL: =
XOR: ^
OR: |
ANDAND: &&
OROR: ||
QUEST: ?
COLON: :
COMMA: ,
SEMI: ;
最后我们还需要完成关键字识别,在 c 语言中有很多特定的字符串有专门的作用,他们不能用于做变量名,例如 int, float, struct 等,当词法解析遇到这些特定字符串时,需要将他们作为保留字或关键字,而不能将他们识别为变量名,因此我们的做法是首先识别出当前字符串,然后再将他们到关键字表中进行查询,看看所识别的字符串是否属于保留字或关键字,由此我们继续对 GoLex 中的 input.lex 做如下添加:
{let}{alnum}* {return id_or_keyword(yytext);}
. {yyerror("Illegal character<%s>\n", yytext);}
%%
//用于表示关键字表中的一个字段
typedef struct {
char* name;
int val;
} KWORD;
KWORD Ktab[] = {
{"auto", CLASS},
{"break", BREAK},
{"case", CASE},
{"char", TYPE},
{"continue", CONTINUE},
{"default", DEFAULT},
{"do", DO},
{"double", TYPE},
{"else", ELSE},
{"extern", CLASS},
{"float", TYPE},
{"for", FOR},
{"goto", GOTO},
{"if", IF},
{"int", TYPE},
{"long", TYPE},
{"register", CLASS},
{"return", RETURN},
{"short", TYPE},
{"sizeof", SIZEOF},
{"static", CLASS},
{"struct", STRUCT},
{"switch", SWITCH},
{"typedef", CLASS},
{"union", STRUCT},
{"unsigned", TYPE},
{"void", TYPE},
{"while", WHILE}
};
int cmp(KWORD*a, KWORD* b) {
return strcmp(a->name, b->name);
}
int id_or_keyword(char* lex) {
KWORD* p;
KWORD dummy;
dummy.name = lex;
p = (KWORD*)bsearch(&dummy, Ktab, sizeof(Ktab)/sizeof(KWORD), sizeof(KWORD),cmp);
if (p) {
printf("find keyword: %s\n", yytext);
return p->val;
}
printf("find variable :%s\n", yytext);
return NAME;
}
{let}{alnum}* 表示变量名必须以下划线或字母开头,后面可以跟着字母或数字。结构体KWORD用于定义关键字表中的一个字段,KTab 用来定义 c 语言的关键字,这里需要特别注意,那就是 KTab 中每个条目中的字符串是升序排列,也就是"auto"<“break”<…<“while”,这种安排是为了后面我们能在该表中进行折半查找。当解析到一个字符串他满足变量名的规则时,id_or_keyword就会被调用,他将当前识别的字符串在 KTab 表中查找,如果能找到对应条目,说明当前字符串是 c 语言的关键字,要不然就是普通变量名,这次修改后代码运行的效果请在 B 站搜索 coding迪斯尼,查看调试演示过程,本文代码下载地址:
链接: https://pan.baidu.com/s/1ekBNQ94ajhswWVQSBIVZ7g 提取码: wsir
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!