基于opencv和tensorflow实现人脸识别项目源码+可执行文件,采用python中的tkinter库做可视化
项目名称:
基于OpenCv和tensorflow的人脸识别
完整代码下载地址:基于OpenCv和tensorflow的人脸识别
环境配置:
- Python
- tensorflow2
- OpenCv
categories: 人工智能
description: Opencv是一个开源的的跨平台计算机视觉库,内部实现了图像处理和计算机视觉方面的很多通用算法,对于python而言,在引用opencv库的时候需要写为import cv2。其中,cv2是opencv的C++命名空间名称,使用它来表示调用的是C++开发的opencv的接口
实验环境:python 3.10 + opencv 4.7.0 + tensorflow 2.10
建议使用 anaconda配置相同环境
更新日志:
demo1版本:
2023/6/7 19:00:00:需要分别执行三个文件,face_catch.py, face_train.py, face_apply.py
demo2版本:
2023/6/12 12:00:00:直接运行ui.py文件即可,修复了一些问题,增添几个功能,主要新增给项目一个UI界面,并优化了实际运行的操作



背景
人脸识别步骤
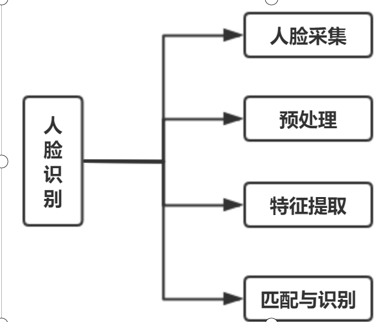
人脸采集
采集人脸图片的方法多种多样,可以直接从网上下载数据集,可以从视频中提取图片,还可以从摄像头实时的采集图片。
人脸检测方法
人脸检测在实际中主要用于人脸识别的预处理,即在图像中准确标定出人脸的位置和大小。人脸图像中包含的模式特征十分丰富,如直方图特征、颜色特征、模板特征、结构特征及Haar特征等。人脸检测就是把这其中有用的信息挑出来,并利用这些特征实现人脸检测。
人脸图像预处理
对于人脸的图像预处理是基于人脸检测结果,对图像进行处理并最终服务于特征提取的过程。系统获取的原始图像由于受到各种条件的限制和随机 干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。对于人脸图像而言,其预处理过程主要包括人脸图像的光线补 偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等。
人脸特征提取
人脸识别系统可使用的特征通常分为视觉特征、像素统计特征、人脸图像变换系数特征、人脸图像代数 特征等。人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。人脸特征提取的方法归纳起来分为两大 类:一种是基于知识的表征方法;另外一种是基于代数特征或统计学习的表征方法。
匹配与识别
提取的人脸图像的特征数据与数据库中存储的特征模板进行搜索匹配,通过设定一个阈值,当相似度超过这一阈值,则把匹配得到的结果输 出。人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:一类是确认,是一对一 进行图像比较的过程,另一类是辨认,是一对多进行图像匹配对比的过程。
关于OpenCv
Opencv是一个开源的的跨平台计算机视觉库,内部实现了图像处理和计算机视觉方面的很多通用算法,对于python而言,在引用opencv库的时候需要写为import cv2。其中,cv2是opencv的C++命名空间名称,使用它来表示调用的是C++开发的opencv的接口
目前人脸识别有很多较为成熟的方法,这里调用OpenCv库,而OpenCV又提供了三种人脸识别方法,分别是LBPH方法、EigenFishfaces方法、Fisherfaces方法。本文采用的是LBPH(Local Binary Patterns Histogram,局部二值模式直方图)方法。在OpenCV中,可以用函数cv2.face.LBPHFaceRecognizer_create()生成LBPH识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
CascadeClassifier,是Opencv中做人脸检测的时候的一个级联分类器。并且既可以使用Haar,也可以使用LBP特征。其中Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。
程序设计
人脸识别算法:

1.录入人脸

1.1数据源准备与采集
# 加载haar人脸识别分类器
classfier = cv2.CascadeClassifier("./haarcascade_frontalface_alt2.xml")
# 视频来源,这里选择使用摄像头
cap = cv2.VideoCapture(camera_idx)
#循环读取到每一帧
while cap.isOpened():
ok, frame = cap.read()
if not ok:
break
1.2识别器收集
# 将当前桢图像转换成灰度图像,便于分类器识别
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#通过detectMultiScale函数对人脸进行识别
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
# 将当前帧保存为图片
img_name = '%s/%d.jpg' % (path_name, num)
cv2.imwrite(img_name, image)
1.3收集过程
提前定义好准备收集的图片个数,捕获每一帧的识别出的人脸图片,当捕获图片数量到达时就退出循环,最后在定义保存的路径
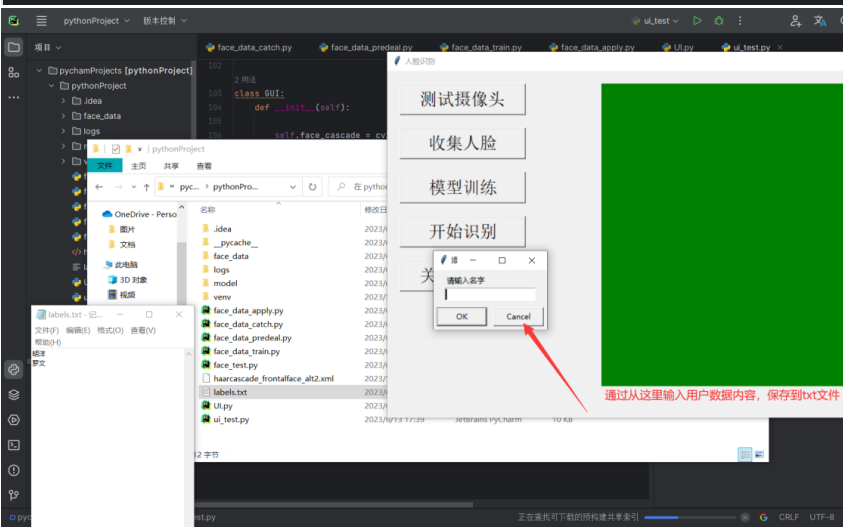
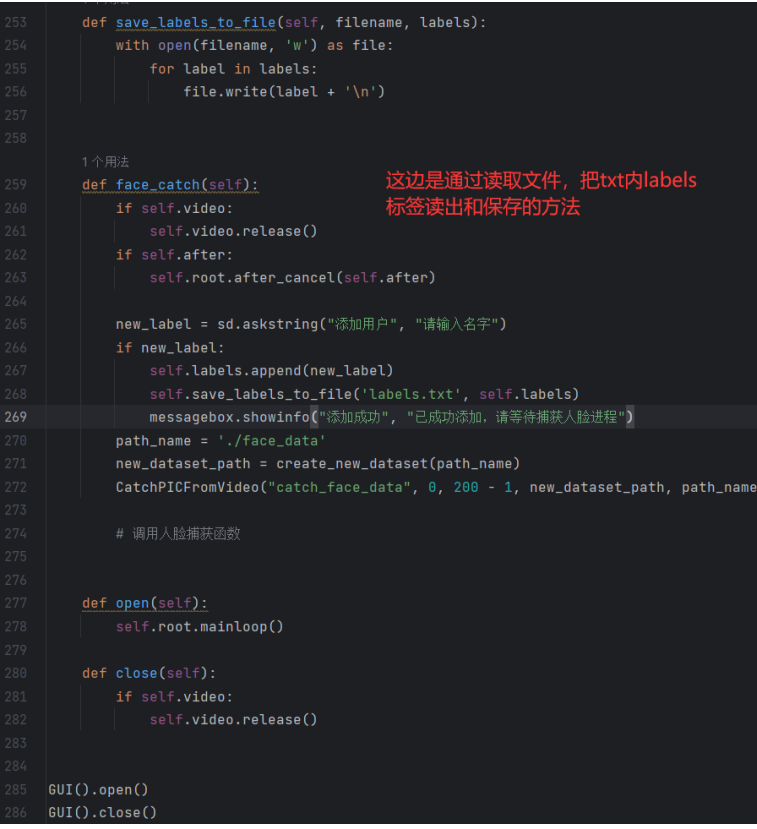
这边是demo2更新后的方法:
#这是后续demo2版本指定路径的方法,不再自己去定义每个人的名称了,统一划分一个userX类名
def create_new_dataset(path_name):
i = 1
while True:
new_path = os.path.join(path_name, f'user{i}')
if not os.path.exists(new_path):
os.makedirs(new_path)
break
i += 1
return new_path
2.模型训练

2.1读取数据集
现在创建一个face_data_predeal.py专门写一个子程序对图像进行预处理(处理图片大小、设置标签等都在这里完成)
通过读取存放数据集的文件,读取到每一张图片,并把图片和图片名称添加到列表中
def read_path(path_name):
for dir_item in os.listdir(path_name):
# 从初始路径开始叠加,合并成可识别的操作路径
full_path = os.path.abspath(os.path.join(path_name, dir_item))
if os.path.isdir(full_path): # 如果是文件夹,继续递归调用
read_path(full_path)
else: # 文件
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
images.append(image)
labels.append(path_name)
return images, labels
2.2图片预处理
图片预处理我写得有点乱又在子程序上写一点,有在构建模型前处理处理一点,总体来说,无论对于这种实时录入的图片来说,还是规定图片来说还是先用老模板处理一部分,比如:规定图片大小后计算好图片尺寸进行修改这种,灰度图这种,图像归一化这种,标注数据这种,在后续甚至可以用keras接口来图像增强加强数据,主要头疼的是使用每个函数要给数据进行格式转化才能使用
在图片处理也可以给图像增加边界,是图片长、宽等长,cv2.BORDER_CONSTANT指定边界颜色由value指定
# 将图片大小设置为64*64
IMAGE_SIZE = 64
# 按照指定图像大小调整尺寸
def resize_image(image, height=IMAGE_SIZE, width=IMAGE_SIZE):
top, bottom, left, right = (0, 0, 0, 0)
# 获取图像尺寸
h, w, _ = image.shape
# 对于长宽不相等的图片,找到最长的一边
longest_edge = max(h, w)
# 计算短边需要增加多少像素宽度使其与长边等长
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass
2.3构建模型
接下来就是构建模型了,由于tensorflow2简化了大量参数,所以对于一般简单的CNN模型就好写了,主要还是使用每个层的参数可以需要调整一下,因为可能会出现过拟合的情况,这样只能换一个模型或者调整一下数据集了
因为是人脸识别所以对于这种多分类问题就直接使用softmax激活函数就行,后续的编译模型的损失函数选择交叉熵函数,主要数据类型问题,看清自己的数据集是onehot编码还是整数编码类型
模型我使用的是调用函数api的形式,交替使用vaild策略和same策略的卷积层方式,这样使模型逐渐减小特征图的尺寸,从而在更高层次的特征表示中捕获更广阔的感受野),然后2层池化层再压缩图片减少训练资源,使用Dropout正则化让部分神经元失活,避免过拟合,最后flaten铺平图片,Dense层构建全连接
class CNN(tf.keras.Model):
# 模型初始化
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[3, 3], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu, # 激活函数
)
self.conv2 = tf.keras.layers.Conv2D(filters=32, kernel_size=[3, 3], activation=tf.nn.relu)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2])
self.dropout1 = tf.keras.layers.Dropout(rate=0.5)
self.conv3 = tf.keras.layers.Conv2D(filters=64, kernel_size=[3, 3], activation=tf.nn.relu, padding='same')
self.conv4 = tf.keras.layers.Conv2D(filters=64, kernel_size=[3, 3], activation=tf.nn.relu)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2])
self.dropout2 = tf.keras.layers.Dropout(rate=0.5)
self.flaten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=512, activation=tf.nn.relu)
self.dropout3 = tf.keras.layers.Dropout(rate=0.25)
self.dense2 = tf.keras.layers.Dense(units=10)
# 模型输出
def call(self, inputs):
x = self.conv1(inputs)
x = self.conv2(x)
x = self.pool1(x)
# x = self.dropout1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
# x = self.dropout2(x)
x = self.flaten(x)
x = self.dense1(x)
# x = self.dropout3(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
2.4编译模型
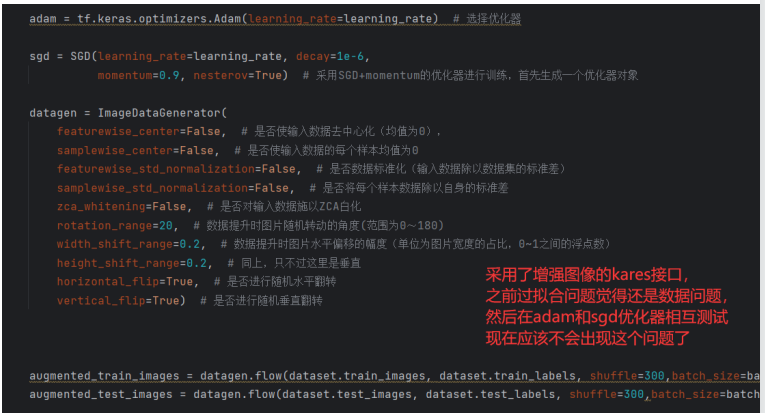
在编译模型选择适合的优化器,Adam和MSGD作为当今最优秀的两种深度学习优化器,分别在效率和精度上有着各自的优势,
Adam在训练集上的准确率较高,MSGD在测试集上的准确率较高,Adam的速度更快,但MSGD能够得到好的效果,学习率一般都是0.01或者0.001,训练20次,分批处理32次就行了
后续可以使用tensorboard可视化查看模型,安装好tensorboard模块后直接使用callbacks函数就行,然后设置好路径,在写训练fit的时候补上callbacks就行
adam = tf.keras.optimizers.Adam(learning_rate=learning_rate) # 选择优化器
sgd = SGD(learning_rate=learning_rate, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
train_ds=tf.data.Dataset.from_tensor_slices((dataset.train_images,dataset.train_labels)).shuffle(300).batch(
batch)
test_ds = tf.data.Dataset.from_tensor_slices((dataset.test_images,dataset.test_labels)).shuffle(300).batch(
batch)
model.compile(optimizer=adam, loss='sparse_categorical_crossentropy', metrics=['acc'])
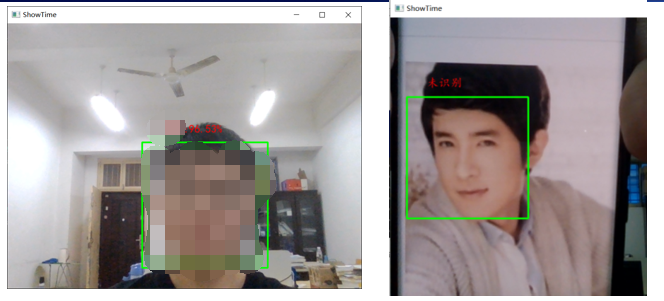
3.识别人脸

识别人脸就比较简单了,model.load_weights直接读取后模型,把图片通过模型model.face_predict处理后进行对比验证,注意要提一点,识别的时候还是要用一下haar’分类器,其实就是通过特征对比的方式进行验证
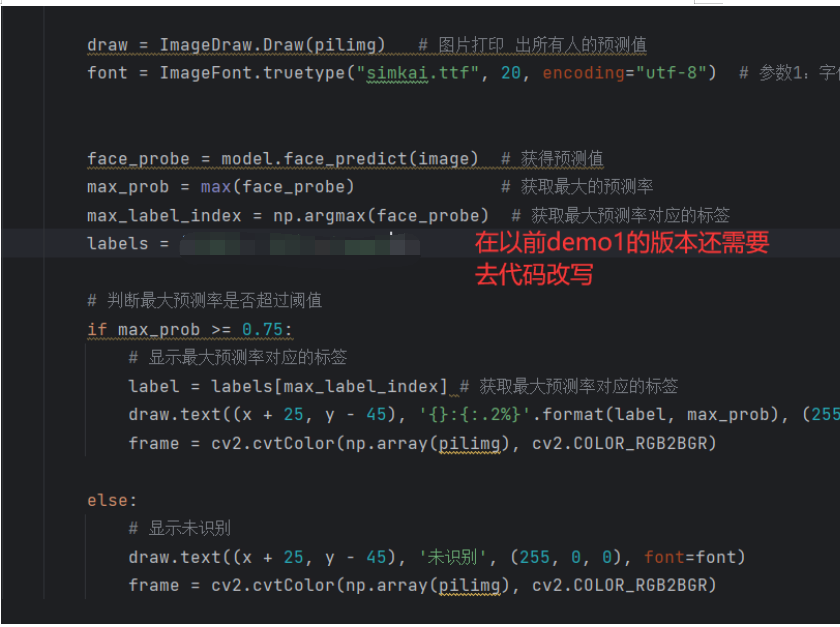
使用cvtColor因为cv2和PIL中颜色的hex码的储存顺序不同,Image.fromarray把图片格式换成pil格式,ImageDraw.Draw把预测值显示在图片上,truetype设置字体大小,face_probe获得预测值,max_prob获取最大的预测率,max_label_index获取最大预测率对应的标签,再设置用户的标签
最后通过阈值判断验证对应的标签,frame = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)把pil格式再换回来cv中的rgb显示处理完成
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pilimg = Image.fromarray(frame)
draw = ImageDraw.Draw(pilimg)
font = ImageFont.truetype(20, encoding="utf-8")
face_probe = model.face_predict(image) # 获得预测值
max_prob = max(face_probe) # 获取最大的预测率
max_label_index = np.argmax(face_probe) # 获取最大预测率对应的标签
labels = ['user1', 'user2','user3']
# 判断最大预测率是否超过阈值
if max_prob >= 0.75:
# 显示最大预测率对应的标签
label = labels[max_label_index] # 获取最大预测率对应的标签
draw.text((x + 25, y - 45), '{}:{:.2%}'.format(label, max_prob), (255, 0, 0), font=font)
frame = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
else:
# 显示未识别
draw.text((x + 25, y - 45), '未识别', (255, 0, 0), font=font)
frame = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
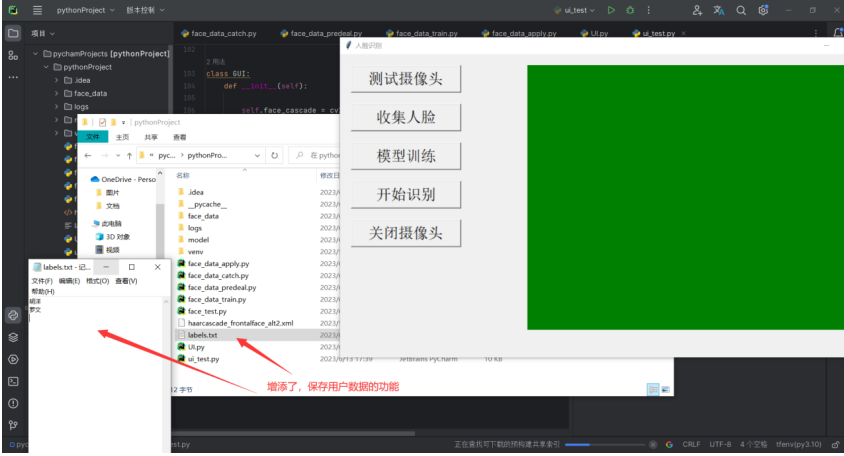
GUI设计:
程序采用python中的tkinter库做可视化,优点是占用资源小、轻量化、方便。
- 首先创建一个窗口命名为root然后设置其大小和标题等属性。
- 然后分别创建几个按钮,并设置响应函数和提示字符,放置在root内部。
- 然后设置一个label类型的控件用于动态的展示摄像头的内容(将摄像头显示嵌入到控件中)。具体方法:创建video_loop()函数,在函数内访问全局的变量img,img是从摄像头读取到的图像数据。然后把img显示在label内。
使用root.after方法,在给定时间后调用函数一次,实现固定时间刷新控件,从而达到实时显示摄像头画面在GUI中的效果。
root.after(1, video_loop)
# 这句的意思是一秒以后执行video_loop函数
# 因为这一句是写在video_loop函数中的所以每过一秒函数执行一次。
运行测试
说明
测试环境:python 3.10 + opencv 4.7.0 + tensorflow 2.10
需要的包:

录入人脸
通过tensorboard模块进行可视化训练出来的模型的准确率和损失函数的直观图绿色为测试集的结果灰色为训练集的结果

这是训练模型过程每次训练的结果,其中最后一次训练损失降到了0.0733,精确度提升到了0.9738(明显过拟合了。。。。)

每一层的信息如下:

人脸识别
 完整代码下载地址:基于OpenCv和tensorflow的人脸识别
完整代码下载地址:基于OpenCv和tensorflow的人脸识别
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!