pytorch基础(十一)-标准化
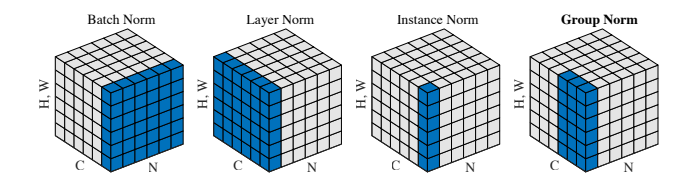
Batch Normalization
原理
假设一个batch的数据shape为(B,L,C)(batchs_size,数据长度,通道数)
或者一个batch的数据shape为(B,H,W,C)(batchs_size,数据高度,数据长度,通道数)
BN就是针对每个维度,将batch_size个样本进行标准化-->(1,L,C)
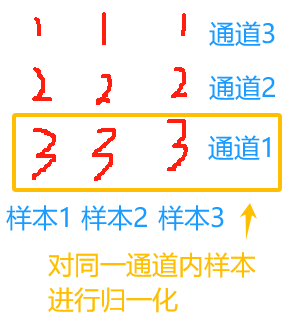
把数据标准化为均值为0,方差为1
将数据集中在0附近,可以有效的防止梯度消失
可以使用更大的学习率,加快模型收敛
不严格要求权值初始化
不严格要求dropout
不严格要求正则化
为什么要增加和
这两个网络学习的参数?
这么做的目的是增加模型的容纳能力,?那怎么样增加模型的容纳能力呢?
例如:
当,?
则
通过学习可以使标准化后的结果存在多种映射,根据权重和偏置的实际需求进行映射,不只存在标准化后的一种均值为0,方差为1的结果
pytorch
nn.BatchNorm1d(num_features)
nn.BatchNorm2d(num_features)
nn.BatchNorm3d(num_features)
一般情况下最重要的参数为num_features,即输入的通道数
其他参数:
eps:1e-5? # 分母的修正项,极小值
momentum:指数加权平均估计当前mean/var
affine:是否需要affine transform
track_running_stata:训练状态/测试状态(训练状态下均值和方差需要重新估计,测试状态下直接使用前一mini_batch的均值和方差)
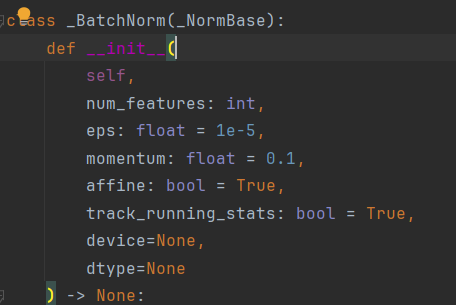
debug的源码为:
class _NormBase(Module):
"""Common base of _InstanceNorm and _BatchNorm"""
_version = 2
__constants__ = ["track_running_stats", "momentum", "eps", "num_features", "affine"]
num_features: int
eps: float
momentum: float
affine: bool
track_running_stats: bool
# WARNING: weight and bias purposely not defined here.
# See https://github.com/pytorch/pytorch/issues/39670
def __init__(
self,
num_features: int,
eps: float = 1e-5,
momentum: float = 0.1,
affine: bool = True,
track_running_stats: bool = True,
device=None,
dtype=None
) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
if self.affine:
self.weight = Parameter(torch.empty(num_features, **factory_kwargs))
self.bias = Parameter(torch.empty(num_features, **factory_kwargs))
else:
self.register_parameter("weight", None)
self.register_parameter("bias", None)
if self.track_running_stats:
self.register_buffer('running_mean', torch.zeros(num_features, **factory_kwargs))
self.register_buffer('running_var', torch.ones(num_features, **factory_kwargs))
self.running_mean: Optional[Tensor]
self.running_var: Optional[Tensor]
self.register_buffer('num_batches_tracked',
torch.tensor(0, dtype=torch.long,
**{k: v for k, v in factory_kwargs.items() if k != 'dtype'}))
self.num_batches_tracked: Optional[Tensor]
else:
self.register_buffer("running_mean", None)
self.register_buffer("running_var", None)
self.register_buffer("num_batches_tracked", None)
self.reset_parameters()
主要属性:?
running_mean:均值?running_mean=(1-momentum)*pre_running_mean+momentum*mean_t
running_var:方差?running_mean=(1-momentum)*pre_running_var+momentum*var_t
weight:affine transform中的
bias:affine transform中的
Layer?Normalization
原理
LN的使用条件:
1.batch_size太小,一个batch只有一两个数据
2.输入数据为变长数据,也就是不同样本输入到网络后的神经元数不同
可能会造成了对于某一通道的batch_size个样本归一化时,可能出现一个样本有数据,另一个样本没有数据的情况
LN:不再对针对某一通道的batch_size个样本进行归一化,而是对单个样本的所有通道进行归一化

nn.LayerNorm
nn.LayerNorm(标准化层的特征形状, eps=1e-05, elementwise_affine=True)?
ln = nn.LayerNorm([3, 4])
output = ln(feature_maps_bs)
print(ln.weight.shape)![]()
输入的特征形状为[3,4],输出的ln层权重的形状也是[3,4],这代表什么呢?
代表每个样本的每个特征都有自己的
1607.06450.pdf)中,作者提出了一种类似与 (arxiv.org)?
Instance Normalization
原理
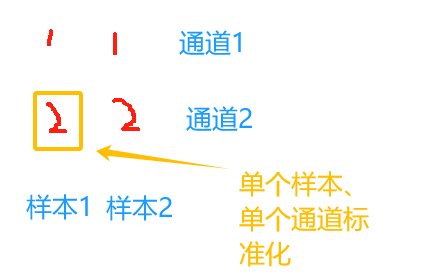
IN:对单个样本单个通道进行标准化
?
nn.InstanceNorm2d?
nn.InstanceNorm2d( num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)?
Group Normalization
原理
在batch_size比较小的模型中,BN估计的值不准
没有办法增加batch里的样本数,就增加每个样本对应的通道数
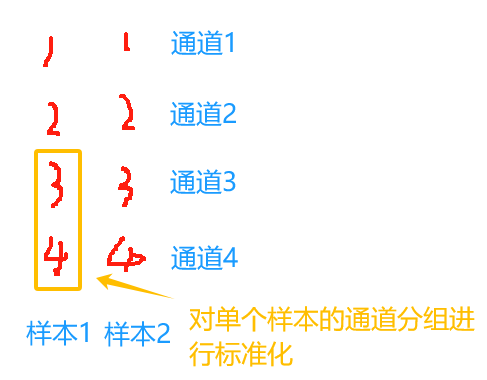
nn.GroupNorm
nn.GroupNorm( num_groups, num_channels, eps=1e-05, affine=True)
Group Normalization (thecvf.com)?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!