云原生向量计算引擎 PieCloudVector:为大模型提供独特记忆
拓数派大模型数据计算系统(PieDataComputingSystem,缩写:πDataCS)在10月24日程序员节「大模型数据计算系统」2023拓数派年度技术论坛正式发布。πDataCS 以云原生技术重构数据存储和计算,「一份存储,多引擎数据计算」,让 AI 模型更大更快,全面升级大数据系统至大模型时代。除云原生虚拟数仓 PieCloudDB,πDataCS 支持的第二款计算引擎:云原生向量计算引擎 PieCloudVector 也正式发布。PieCloudVector 支持海量向量数据存储、向量数据高效查询,助力多模态大模型 AI 应用。
AI 将引领下一波全球 GDP 的增长。根据麦肯锡2023年6月报告,生成式 AI(基于大模型)每年会为全球 GDP 贡献约2.6至4.4万亿美元,相当于英国2021年 GDP 总值(3.1万亿美元)。高盛也在其2023年4月报告中指出,生成式 AI 可以为全球 GDP 贡献7%的增长。大模型的迅速崛起让生成式 AI 基于大模型的应用也在不断创新,而应用对大规模向量数据的处理、相似性搜索等需求的增加,也促进了向量数据库的进一步发展。
拓数派自研的向量云原生计算引擎 PieCloudVector,作为 πDataCS 第二款计算引擎,是大模型时代的分析型数据库升维,目标是助力多模态大模型 AI 应用,进一步实现海量向量数据存储与高效查询。 PieCloudVector 支持和配合大模型的 Embeddings,帮助基础模型在场景 AI 的快速适配和二次开发。
1 大模型与向量
随着数据的爆炸式增长和计算能力的提升,大模型成为了处理复杂问题和分析海量数据的重要工具。大模型指的是拥有庞大参数规模、高复杂度和强大学习能力的机器学习模型。 这些模型通常由数百万甚至数十亿个参数组成,通过对大规模数据进行训练来获取知识和推理能力。大模型的出现使得在各种领域中的任务,如自然语言处理、图像识别、语音识别和推荐系统等取得了显著的突破。
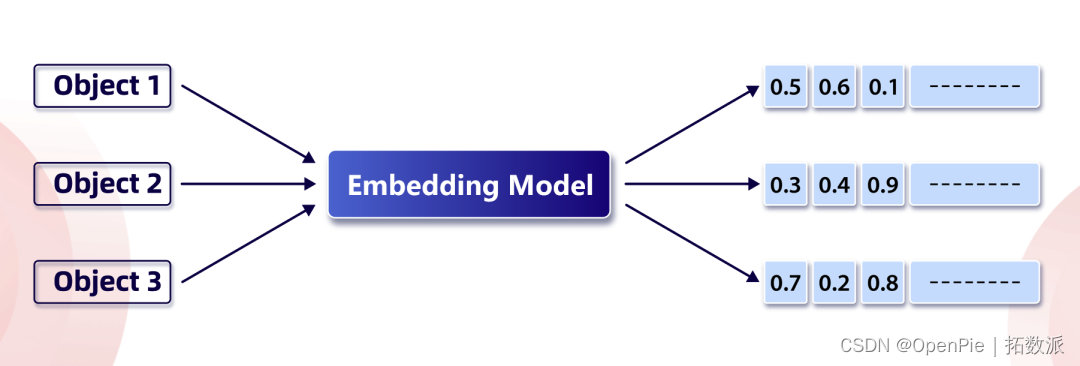
特征的向量化表示
在数学和计算机科学中,向量是具有大小和方向的量。向量用一组浮点数表示一组“特征”,这个特征是从真实物体(猫、花等)的二进制表示(文本、图片、音频、视频等)中提取出来的(如上图所示),一般由大模型提取。通过将真实物体转化为向量表示,可以在向量空间中进行计算和比较,例如计算相似度、聚类分析、分类任务等。向量表示也为构建推荐系统、情感分析、信息检索等任务提供了基础。
2 什么是向量数据库
向量数据库是一种专门用于存储和管理向量数据的数据库系统,可以对向量提供高效的存储、索引和查询功能。
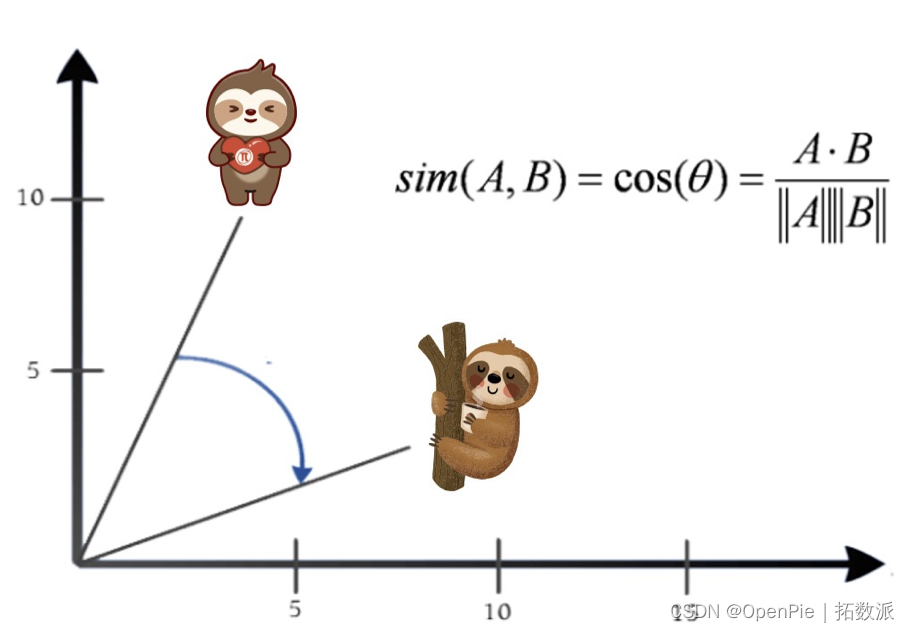
计算向量的余弦相似度
在向量搜索中,可以使用不同的距离度量(如欧式距离、余弦相似度、曼哈顿距离等)来计算两个向量之间的距离。距离越近表示这两个向量越相似。如下图,“派派”与“树獭”的距离度量则可通过余弦相似度来计算,来判断其相似程度。
传统数据库更擅长精确匹配,在浮点数的存储和处理能力都较为欠缺,无法高效地处理向量数据。为了能够高效存储和查询向量数据,向量数据库应运而生。
向量数据库能够满足存储和处理向量数据的特定需求,能够高效的将存储向量和原始实体(文字/图像/语音),并将它们关联起来。从而得以提供高效的相似度搜索、大规模数据管理、复杂向量计算和实时推荐等功能,帮助用户更好地利用和分析向量数据,助力大模型应用。
拓数派认为,一款优秀的向量数据库除了应当具备高效的向量存储和相似性搜索功能,还需满足事务的 ACID 保证和用户权限控制, 在确保对向量数据的插入、更新和删除操作能够正确执行,保证并发访问时数据的一致性的同时,为用户提供稳定、可靠且安全的服务,适用于各种数据管理和应用场景。这也是 PieCloudVector 的设计思路。
3 云原生向量计算引擎 PieCloudVector
拓数派团队在对比了 pgvector,pgembedding 等多种开源实现和性能后,并没有选择这类开源实现方式,而是完全独立自研了 PieCloudVector 以使其满足用户的使用场景。PieCloudVector 具备高效存储和检索向量数据、相似性搜索、向量索引、向量聚类和分类、高性能并行计算、强大可扩展性和容错性等特性。
3.1 PieCloudVector 架构
在架构的设计上,拓数派团队利用其在打造 πDataCS 的第一款计算引擎云原生虚拟数仓 PieCloudDB 时,在 eMPP(elastic MPP)与分布式架构领域积累的经验与优势,打造了向量计算引擎 PieCloudVector 的 eMPP 分布式架构。如下图所示,PieCloudVector 每个 Executor 对应一个 PieCloudVector 实例,从而实现高性能、可伸缩性和可靠性的向量存储和相似性搜索服务。而被转化的向量表示将被存储在 πDataCS 统一的存储引擎「简墨」中。
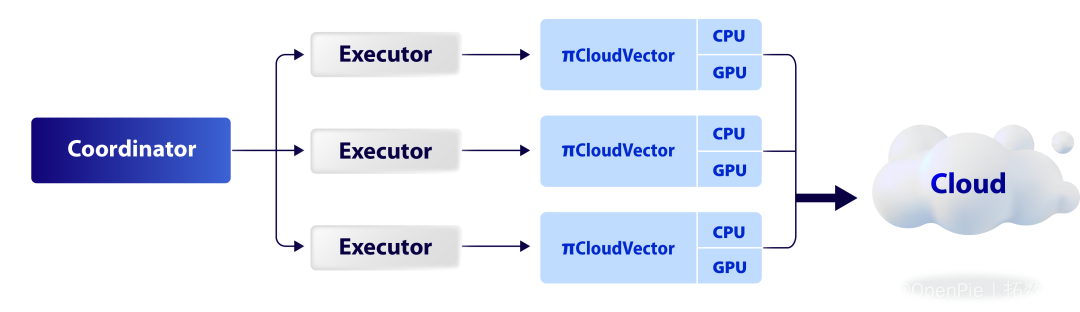
PieCloudVector 的 eMPP 分布式架构
用户只需一个客户端即可使用任何语言进行相似搜索。有了 PieCloudVector 的帮助,用户不仅可以存储、管理原始数据所对应的向量,也可调用 PieCloudVector 相关工具进行模糊搜索,与全局搜索相比牺牲部分精度实现毫秒级搜索,进一步提升查询效率。
3.2 PieCloudVector 功能
PieCloudVector 可以提供精确搜索和模糊搜索两种搜索模式。 目前,PieCloudVector 为用户提供以下功能:
- 支持近似向量搜索 KNN-ANN
- 支持主流的 ANN 算法,如 IVFFlat 和 HNSW 等
- 支持向量压缩(PQ)
- 并行+分布式
- SIMD/GPU 加速
- 支持 Langchain 框架
接下来,我们将对其中前两个功能进行详细介绍:
3.2.1 近似搜索 KNN-ANN
K-Nearest Neighbor(K 最近邻,KNN)是向量搜索的基本问题之一。该问题在已有的 N 个向量中找出与给定向量距离最近的 K 个向量。通过 K 最近邻算法,可以实现像相似图片检索、相关新闻推荐、用户画像匹配等应用。它允许根据向量之间的距离或相似度快速找到与给定向量最相似的向量,从而提供了高效的相似性搜索和推荐服务。
但随着数据量的逐渐增大,精确查询需要将输入的向量与每一条记录进行比对,计算成本将成倍增长。为了解决这个问题,PieCloudDB 建立向量索引来提前获取数据间的大致关系,加速查询效率。PieCloudVector 引入Approximate Nearest Neighbor(近似最近邻,ANN)算法来建立向量索引。通过 ANN,PieCloudVector 能够节省全局搜索的时间,牺牲部分精度以加速查询速度,进一步提升查询效率,实现毫秒级查询速度,做到模糊查询。
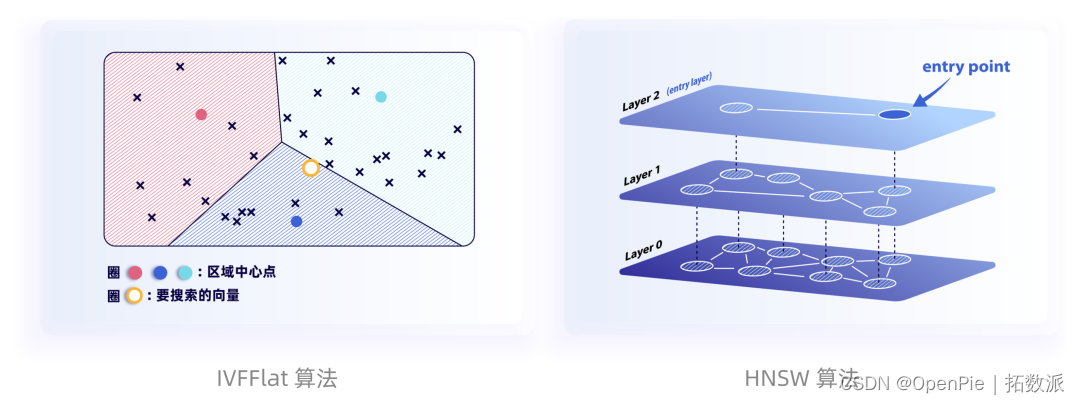
PieCloudVector 在建立向量索引时提供多种 ANN 算法, 包括最为流行的 IVFFlat(Inverted File with Flat)算法 HNSW(Hierarchical Navigable Small World)算法,用户可根据数据的特性来选择:
- IVFFlat 算法(左图): 基于倒排文件的向量索引算法。它将向量数据提前进行分组,并为每个组建立一个倒排索引。在模糊查询时,IVFFlat 算法会检索与目标向量相近的组中包含的数据,从而加快搜索速度并降低内存消耗。然而,由于使用了分组,IVFFlat 算法的精确度一般相对较低。
- HNSW 算法(右图): 基于层级导航的向量索引算法。它通过在数据之间建立“关系网”来构建索引结构。这个过程需要耗费一定的时间和内存资源。但是,HNSW 算法的精确度通常优于 IVFFlat 算法。它能够更好地捕捉数据之间的局部结构和相似性,并支持高效的近似搜索。
3.2.2 向量压缩
向量相似性搜索在处理大规模数据时需要大量的内存来支撑。例如,对于包含1百万个稠密向量的索引来说,通常需要几 GB 的内存来存储。高维数据使内存使用问题更加严重,因为随着维度的增加,向量表示空间变得极其庞大,需要更多的内存来存储。
为了解决这个内存压力问题,向量压缩(Product Quantization,PQ)是一种常见方法。 它能够将高维向量压缩,从而显著减少内存的占用。通过将每个向量分割成若干子空间,并对每个子空间进行量化,PQ 可以将原始的高维向量转换为多个低维码本(codebook),从而降低内存需求。
使用 PQ 后,存储索引所需的内存可以减少高达97%, 使 PieCloudVector 在处理大规模数据集时更有效地管理内存,并加快相似性搜索的速度。此外,PQ 还能提升最近邻搜索的速度,通常能够使搜索速度提高 5.5倍。另外,将PQ 与倒排文件(Inverted File,IVF)结合形成的 IVF+PQ 复合索引,在不影响搜索准确性的情况下,进一步提升搜索速度16.5倍。与未使用量化索引相比,总体搜索速度可提高92倍。
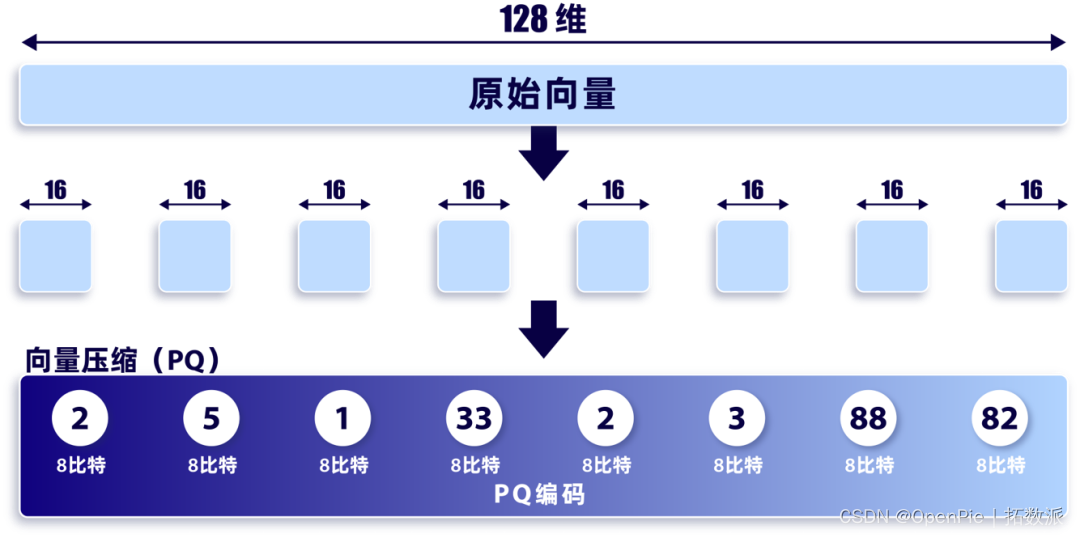
向量压缩(Product Quantization)
4 PieCloudVector 典型应用场景
根据向量的实际使用流程,PieCloudVector 的应用场景大致可以分为四层,分别对应实际使用向量的过程中不同的场景。
4.1 准备数据与切分(图像、文本、音频等)
在这一层,涉及到数据的准备和切分。例如,在图像、文本、音频等形式。需要对原始数据进行预处理、清洗和特征提取,以得到适合后续处理的向量表示。这一步骤通常是为了将原始数据转化为可供创建嵌入(embeddings)的输入。
4.2 创建 Embeddings
在这一层,将通过适当的算法或模型将数据转化为向量表示。这向量表示反映了数据的特征和语义信息。例如,可以使用卷积神经网络(CNN)、循环神经网络(RNN)、Transformer 等模型来生成图像、文本或音频的嵌入表示。
4.3 存储向量
在这一层,将创建的向量表示存储起来,以便后续的向量搜索。PieCloudVector 支持分布式向量存储,可弹性扩展存储资源,并通过向量压缩减少内存的占用。
4.4 向量搜索(Vector Search)
在这一层,基于已存储的向量进行相似性搜索。PieCloudVector 提供高效的向量搜索功能,通过 KNN、ANN 等向量搜索算法,支持 L2 distance, Inner Product,以及 Cosine Distance 向量距离度量方式,能够快速找到与给定查询向量最相似的向量。这种向量搜索功能广泛应用于相似图片检索、相关新闻推荐、用户画像匹配等场景。
下图是 PieCloudVector 在一款知识库系统的应用流程架构,共包括从文本切分到应用程序返回答案给用户六个步骤。该知识库系统利用 PieCloudVector 来支持知识库系统中的语义搜索和答案检索功能。它将文本转化为向量表示,并通过向量相似性搜索来找到相关的答案。这种架构能够高效地处理大规模的文本数据集,并提供准确的答案回复给用户。
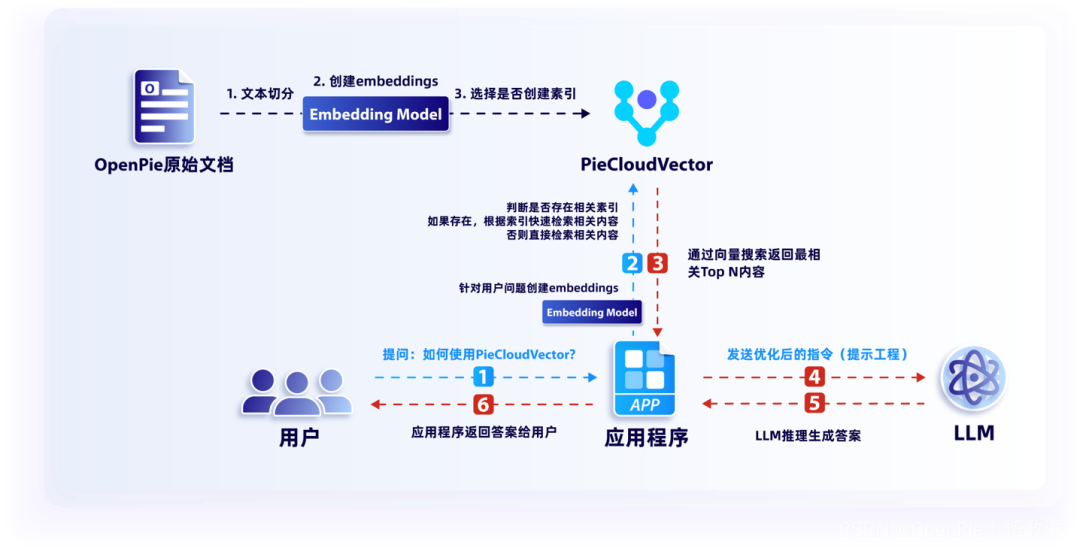
知识库系统的应用流程架构
在未来,PieCloudVector 将继续不断迭代和发展,为大模型提供独特的记忆和支持。随着生成式 AI 和大模型的不断演进,PieCloudVector 将更加深入地融合向量数据库的优势,并与其他技术和算法进行紧密集成。
PieCloudVector 将持续改进其存储、索引和查询能力,以应对越来越复杂和庞大的向量数据。 它将探索新的量化算法、近似搜索方法和并行计算策略,以提高查询效率和准确性。
同时,PieCloudVector 将致力于与不同领域的应用场景相结合,并将逐步扩展支持多模态数据的处理和分析能力,提供更全面、灵活的解决方案。
参考资料:
- 大模型数据计算系统——理论
- 大模型数据计算系统——实现
- The Economic Potential of Generative AI: The Next Productivity Frontier
- Generative AI Cloud Raise Global GDP by 7%

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!