【Hadoop】HDFS设计思想
2023-12-18 07:55:03
HDFS设计思想
-
首先需要明确HDFS部署在集群之上。
-
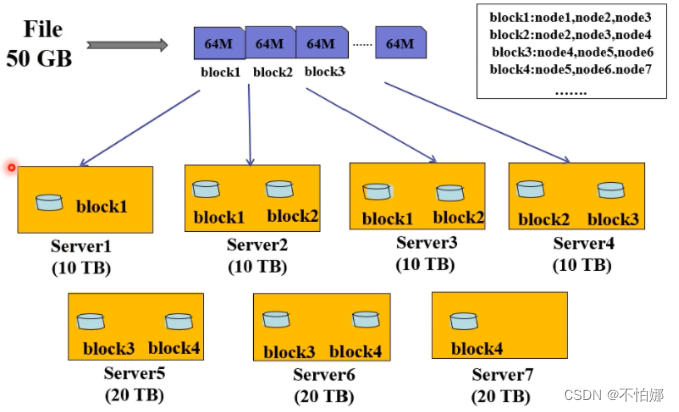
假设有一个50G的文件,在HDFS中分布式的存储这个文件,首先需要将50G文件分成多个数据块,块的大小可以设置,比如128M。数据块以多副本的行式存储在各个节点上 ,再使用一个文件把哪个数据块存储在哪些节点上的映射关系存储起来。有了这样的映射关系,用户读取文件的时候就会很容易读取到。
-
数据块大小可以在配置文件中hdfs-default.xml中进行修改。如下:
<property> <name>dfs.blocksize</name> <value>134217728</value> <description>默认块大小,以字节为单位。可以使用以下后缀(不区分大小写):k,m,g,t,p,e以重新指定大小(例如128k, 512m, 1g等)</description> </property> <property> <name>dfs.namenode.fs-limits.min-block-size</name> <value>1048576</value> <description>以字节为单位的最小块大小,由Namenode在创建时强制执行时间。这可以防止意外创建带有小块的文件可以降级的大小(以及许多块)的性能。</description> </property> <property> <name>dfs.namenode.fs-limits.max-blocks-per-file</name> <value>1048576</value> <description>每个文件的最大块数,由写入时的Namenode执行。这可以防止创建会降低性能的超大文件</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> <description>HDFS中的NameNode会记录文件的各个块都存放在哪个dataNode上,这些信息一般也称为元信息(MetaInfo) 。元信息的存储位置一般由dfs.namenode.name.dir来指定</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> <description>而datanode是真实存储文件块的节点,块在datanode的位置一般由dfs.datanode.data.dir来指定</description> </property>
为什么HDFS上的块为什么远远大与传统文件系统?
我们所熟悉的普通文件系统的一个块一般只有几千字节,可以看出,HDFS在块的大小的设计上明显要大于普通文件系统。HDFS这么做的原因,是为了最小化寻址开销。HDFS寻址开销不仅包括磁盘寻道开销,还包括数据块的定位开销。当客户端需要访问一个文件时,首先从namenode名称节点获得组成这个文件的数据块的位置列表,然后根据位置列表获取实际存储各个数据块的数据节点的位置,最后datanode数据节点根据数据块信息在本地文件系统中找到对应的文件,并把数据返回给客户端。设计一个比较大的块,可以把上述寻址开销分摊到较多的数据中,降低了单位寻址的开销。因此,HDFS在文件块大小的设置上要远远大于普通文件系统,以期在处理大规模文件时能够获得更好地性能。当然,块的大小也不宜设置过大,因为,通常MapReduce中的Map任务一次只处理一个块中的数据,如果启动的任务太少,就会降低作业并行处理速度。
文章来源:https://blog.csdn.net/m0_60511809/article/details/135014321
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!