【扩散模型】6、Classifier-Free Diffusion Guidance | 无需显示分类器指导也能获得很好的生成效果

论文:Classifier-Free Diffusion Guidance
代码:暂无
出处:NIPS 2021 workshop(短版本论文)
一、背景
在此之前,classifier guidance (diffusion model beats GAN)模型使用类别引导的方法在 FID score 上首次超越了 BigGAN-deep 和 VQ-VAE-2。类别引导的方法就是使用额外训练的分类器来提升扩散模型生成样本的质量,在使用类别引导扩散模型生成之前,扩散模型很难生成类似于 BigGAN 或 Glow 生成的那种 low temperature 的样本,这里 low temperature 就是和训练数据的分布非常接近的样本,更清晰且逼真。而且,如果不使用分类器指导,而是仅仅减少在扩散模型中加入的高斯噪声,并不能很好的解决这个问题。

分类器引导是一种混合了扩散模型分数估计与分类器概率输入梯度的方法。通过改变分类器梯度的强度,可以在 Inception 得分和 FID 得分(两种评价生成模型性能的指标)之间进行权衡,就像调整 BigGAN 中截断参数一样。
然而,作者想要探索是否可以在不使用任何分类器的情况下实现类似效果。因为,使用分类器引导会使扩散模型训练流程复杂化,它需要额外训练一个用于处理噪声数据的分类器,并且在采样过程中将分数估计与该分类器梯度混合。
所以作者提出了无需任何依赖于特定目标或者任务设定的 classifier-free guidance 方法。
二、方法
“无分类器引导”(Classifier-free guidance)是一种在扩散模型中使用的方法,它可以在不需要分类器的情况下提供与分类器引导相同的效果。具体来说,这种方法涉及训练两个模型:一个无条件的去噪扩散模型pθ(z),和一个有条件模型 pθ(z|c)。
-
无条件去噪扩散模型:这个模型通过评分估计器θ(zλ)进行参数化。对于该模型,我们可以简单地为类标识符 c 输入一个空标记?来预测得分,即 θ(zλ) = θ(zλ, c = ?)。
-
有条件模型:这个模型通过θ(zλ, c)进行参数化。
这两个模型都用同一神经网络进行参数化,并且同时训练。共同训练是通过随机将 c 设置为具有某些概率 puncond 的无条件类标识符?实现的。虽然也可以选择独立训练每个单独的模型,但联合训练更简单、不会复杂化训练流程,并且不会增加总体参数数量。
采样过程则使用了有条件和无条件得分估计值之间的线性组合。这意味着生成新数据时会考虑到两者之间平衡关系。
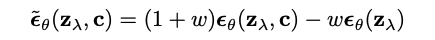


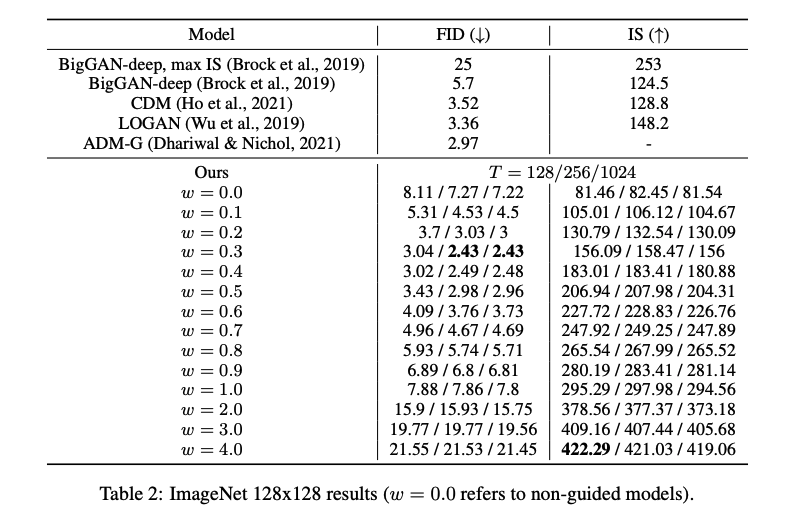
三、效果

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!