C++——C++11(1)
时至今日,C++标准已经到了C++23,但是你要说哪一次提出的标准最经
典,那C++11一定会被人提及,C++11带来了数量可观的变化,其中包
含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得
C++11更像是从C++98/03中孕育出的一种新语言。所以对于学习C++的人
来说,认识C++11中部分的新特性是必要的。而今天由我来浅显的介绍其
中的部分特性。
1. 列表初始化
在C语言中我们对结构体和数组的初始化会像下面这么写:

而在C++中我们初始化一个对象的时候也会使用上面结构体那样的方式来初始化对象,但是在C++中我们更趋向使用STL容器来存储对象,而不是简单的一个数组了,而C语言中这种初始化数组的方法有很好,所以C++11中采用了这种方法,并且对花括号的初始化进行了天翻地覆的改造,你会看到下面这样的情况:

使得一切对象都可以使用花括号初始化,向上面这种对单体对象的初始化则只是根据构造函数对应的参数个数决定比如变量k、j、paa中的元素,它们的参数都是固定的,我们进行更改的话编译器会报错。但是下面这种情况呢?

我们上面说了对一个单体对象的初始化受它的构造函数影响,这里怎么不会呢?难道vector和list都写了三个参数和六个参数的构造函数吗?显然不是的。而这就是列表初始化。
对于部分容器的初始化来说,等号右边的话括号里的内容会变成一个这样的对象:

它的底层也很简单,只不过是两个指针来只想这一串内容。它的成员函数也很简单:

而像vector、list这些容器里也都写好了关于initializer_list对象的构造函数:
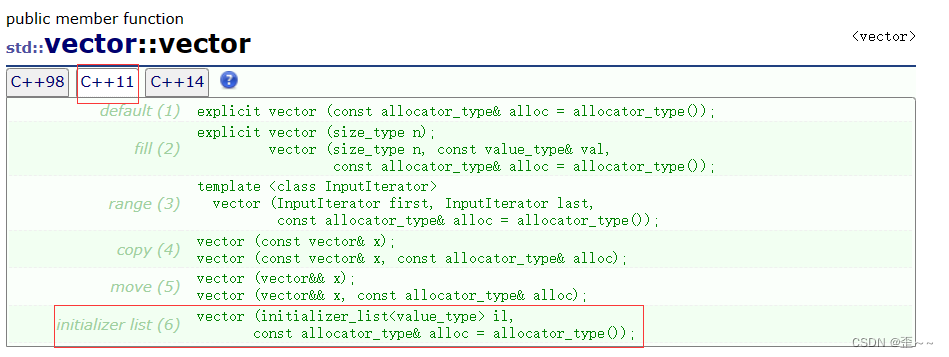
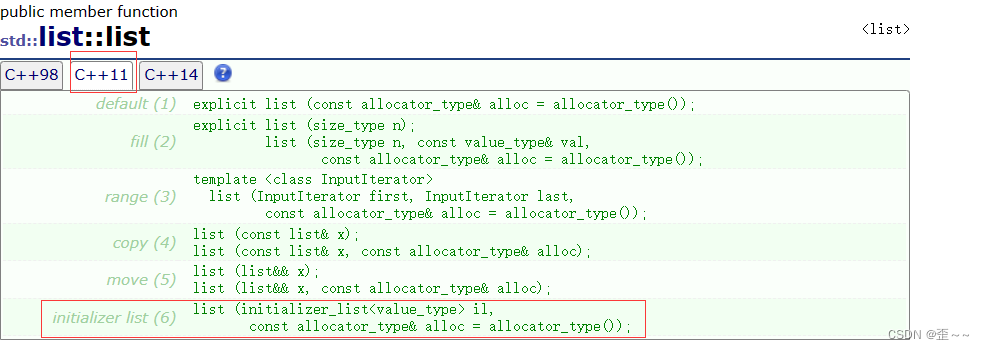
才能支持上面那样vector和list的初始化。而假如像我们自己尝试写一个list的时候也可以写这样的一个构造函数来帮我们实现这样的功能:
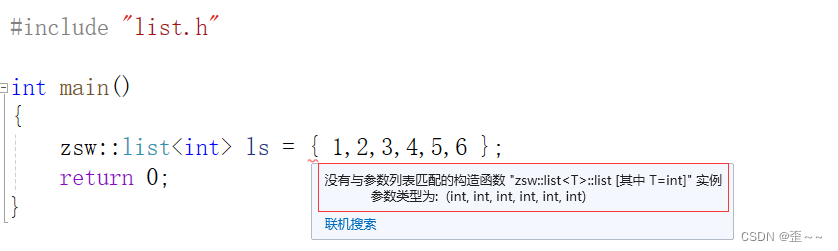
可以看到我们这样直接写是不行的,在我们自己实现的list中写一个关于initializer_list对象的构造就可以了:

这样就可以了:

需要在这里注意的是:
1.多参数对象的花括号构造实际上是先将花括号的内容构造出一个临时对象,然后再拷贝
构造给等式左面的对象,但是编译器直接优化成直接构造了。
2.vector的列表初始化跟多参数对象初始化的隐式类型转换还是不一样的
2.右值引用
a. 左值与右值
我们来再次认识一下什么是左值,什么是右值。单从字面意思来说,右值左值就是等号右面和等号左面的值,但是肯定不会这么简单,就像位操作中的左右移一样,左移就是往左移,右移就是往右移吗?也不一定,在计算机中左右移是看计算机的存储方式的,而左右值也一样,不能单纯的用左右来区分左值右值。常见的左值我们一般很容易分辨,下面我来介绍一些常见的右值:

还是无法判别的时候,可以取地址的就是左值,不可以的就是右值。
2. 什么是右值引用?
我们倒是学过一个引用,但哪个是左值引用,左值引用可不可以直接引用右值呢?答案是不可以,因为右值是具有常性的值,而我们要使用一个正常的引用变量给它起别名等于是权限的放大。
而可以这样来书写:

那么在C++11就出现了对右值的引用:

左值引用不能直接给右值起别名,那么右值引用可以直接给左值起别名吗?那当然也是不可以的,但是可以是用其他方式来实现:

其中的move把变量i的“属性”(这个属性不详细述说)发生了改变,导致i成为了右值。但是需要注意:
其中被move执行的变量只会在当前行被修改属性,其他行是不会改变的
c. 右值引用的意义
一个东西被提出来肯定是有他的道理,那具体右值引用有什么意义,继续往下看。
在C++中有了左值引用后,我们实现了函数传参传引用,函数返回引用(赋值重载等等),但是其中的函数返回左值引用,那是需要被返回的对象出了函数作用域之后依然存在。要不然就会造成内存的越界访问。那么在这种情况下,就会导致很尴尬的情况发生:
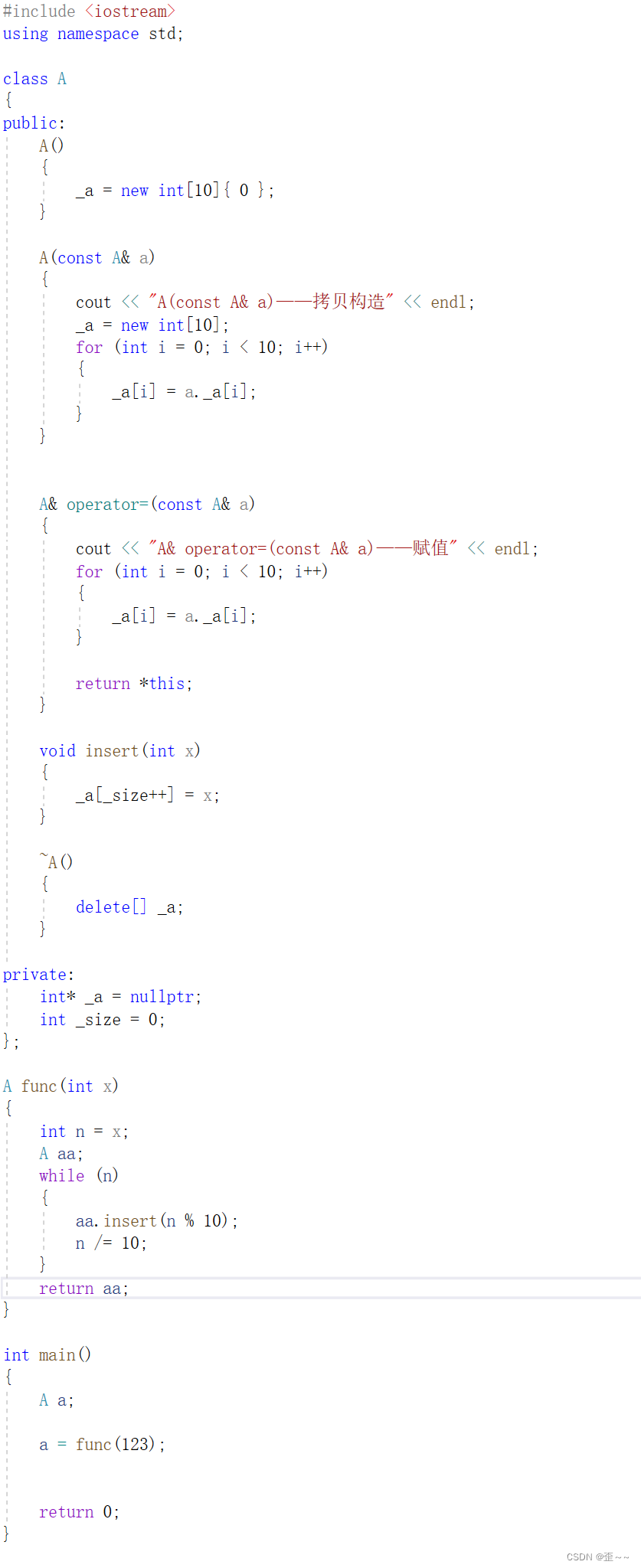
让我来阐述一下上面的代码,类A中有一个int的指针,我将它设置成指向固定十个int的数组,而上面的函数我只是将一个int的每一位给拆分到这个数组中的一个函数。(只是为了能够说明要讲述的东西,所以举的例子的实现不会很严谨)
当我们运行之后:
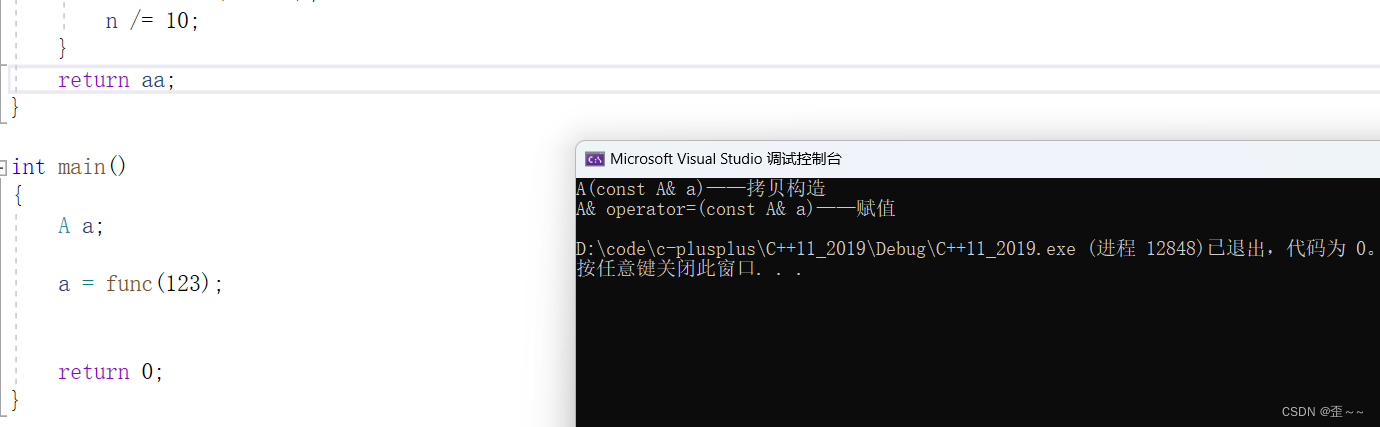
在这里要注意:
我使用的是VS2019,VS2022会将这里直接优化成构造,但是这里的问题是确实存在的。
当我运行代码之后,发现它进行了一次拷贝构造和赋值,而这其中函数中的aa是一个存在于func中的局部变量,我们进行的是值返回所以在return的时候会使用拷贝构造构造出一个临时对象,然后再是用这个临时对象赋值给main函数里的变量a。
又要注意了:
这里有人可能会问,这里不也是被大多数编译器优化成直接构造吗?这个认识显然是混淆了。
正确的认识是:大多数编译器会将拷贝构造+构造直接优化成拷贝构造。这里是拷贝构造+赋值,所以不会有优
化的现象,新一点的编译器才会。
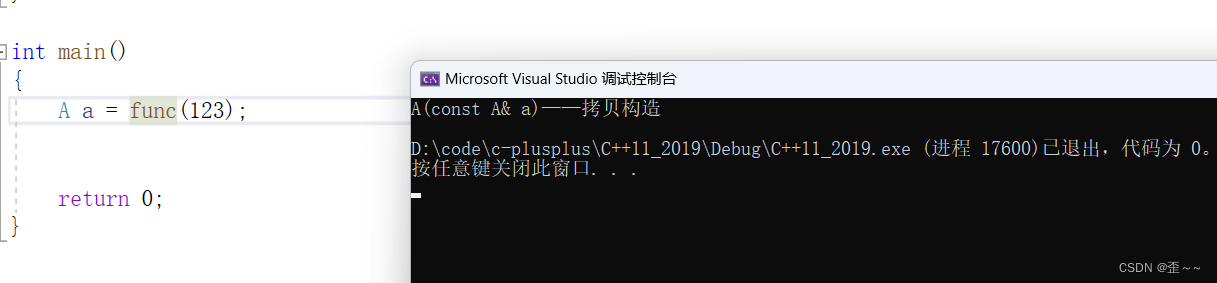
这样才会优化。
回归正题,那么我们发现,他进行了两次深拷贝,这种现象从比较严谨的角度来说是比较浪费的,因为我们需要的就是func函数中的aa变量中开辟空间中的那部分内容,但是我们硬生生又开辟了两个同样大小的空间才能达到让a获得aa的内容,这么看来光是空间就浪费了三倍。所以有没有一种办法解决这种现象让aa中的内容直接给了a呢?这种情况下,左值引用就无法解决,因为aa在函数中,在函数结束时,它的销毁是必然的。所以就出现了右值引用。
那么,如何使用右值引用解决这个问题呢?
返回右值引用吗?这种是行不通的,因为我们已经说了,aa的销毁是必然的。
全局变量?更不行了,全局变量的使用是有风险的,不能随意使用全局变量。
这里就提出了移动构造和移动赋值的方法:
移动赋值重载
我们知道上面两次深拷贝的实现大致是如下图:
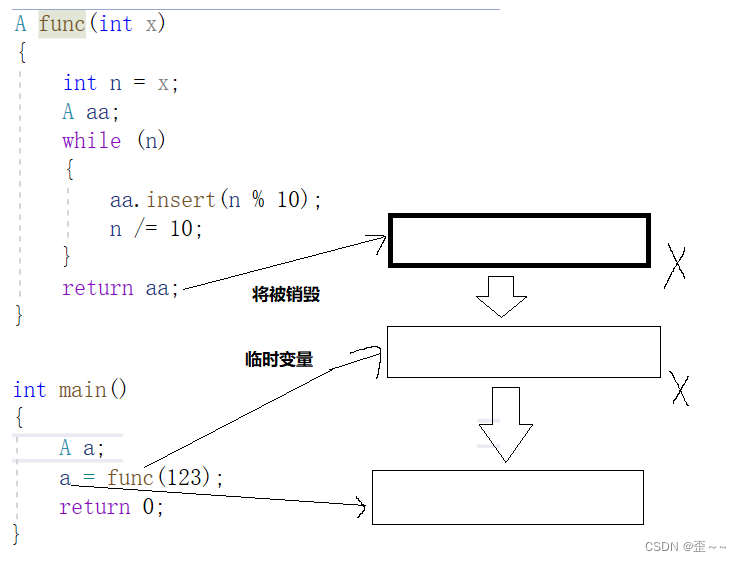
其中,临时变量具有常性它是一个右值,而且它被使用完就销毁了,那能不能将它的内容给了我们的a呢?我们来看看A类的赋值重载:
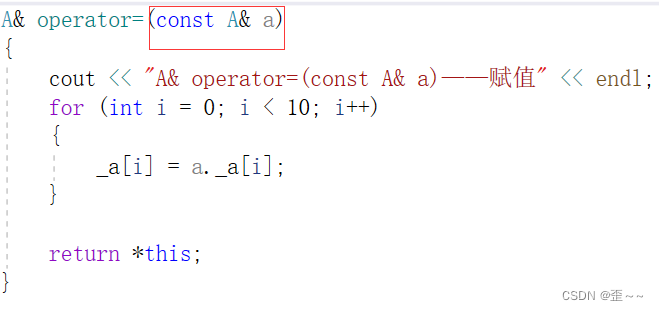
发现他是一个左值引用,但是加了一个const之后使得他也能实现右值的赋值重载,在C++泛型编程的思想中,秉持着有现成的用现成的,没有现成的用将就的。所以这里的临时变量就传给了左值引用的赋值重载函数,那我们写一个右值引用的会怎么样呢?
我们的写法如下:

再次执行代码:
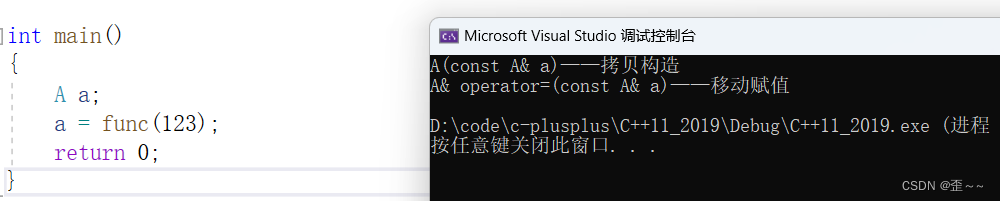
可以看到我们,的移动赋值,并没有深拷贝,而是只交换了两者的指针,大大提高了效率。
移动拷贝构造
那在拷贝构造的过程中,aa中的资源我们可不可以拿过来呢?为了提升效率,我们一般把即将被销毁的的自定义类型定义为“将亡值”,内置类型定义为纯右值。
将亡值(rvalue reference)通常是指一个即将被销毁(死亡)的临时对象,它可以通过移动语义来提高程序性能。
将亡值可以用 && 符号表示。
纯右值(prvalue,pure rvalue)是指没有任何名称、生存期或地址的表达式,例如常量、字面量或返回右值的函
数调用。一般来说,纯右值可以作为将亡值出现。将亡值和纯右值在 C++ 中都可以被称为右值(rvalue),但它
们之间存在区别。
将亡值是一个具有名称和可用类型的右值引用,而纯右值没有这些特性。这种分类可以让程序员更好地控制和优化
程序的性能。
所以,被return时候的aa就是一个将亡值,那就是右值。
实现移动拷贝构造:

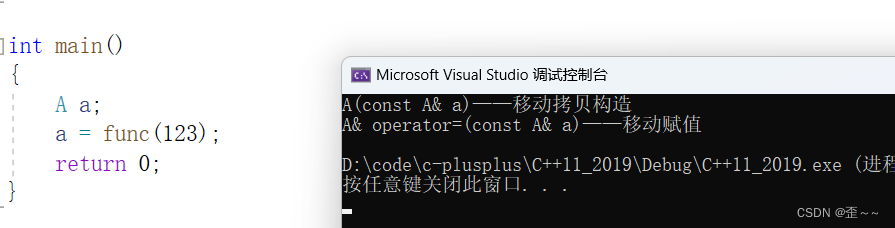
这样就通过右值引用来大大提高了效率,当然这里还有一个重要的知识,那就是这两个函数是移动语义的一部分,它们与移动语义紧密相关。
基于这样的情况,我们可以写出这样的代码来提升效率:
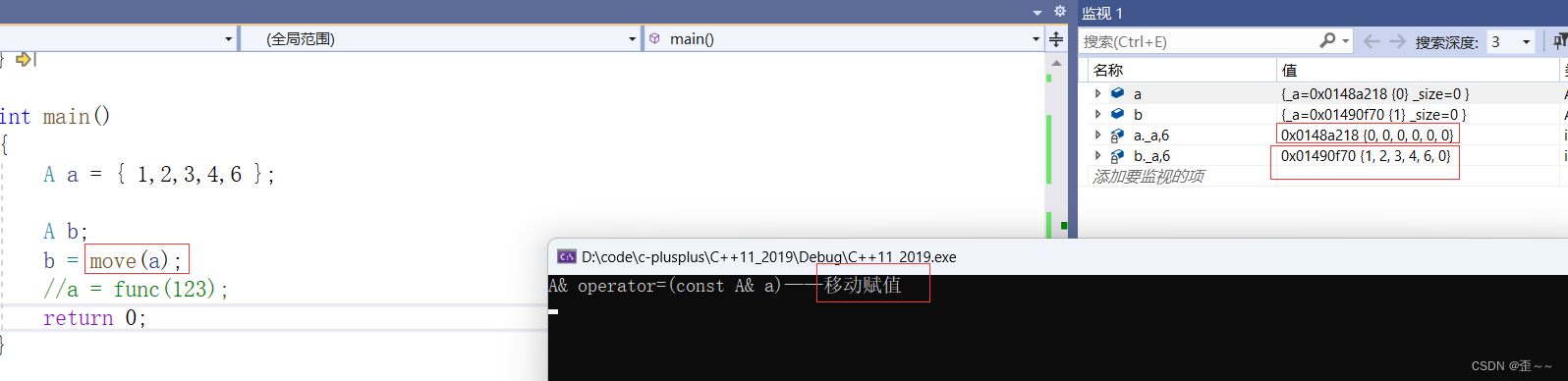
可以看出这种适用于a已经是一个废弃的值。所以使用的时候要谨慎。而STL中也使用了各种右值引用的版本。


可以自行去查看。
万能模板和完美转发
出现了右值引用后,就出现了一个新的现象:
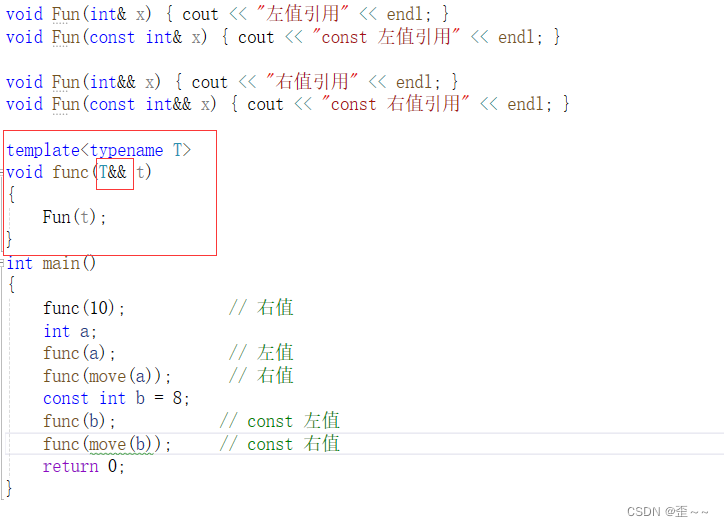
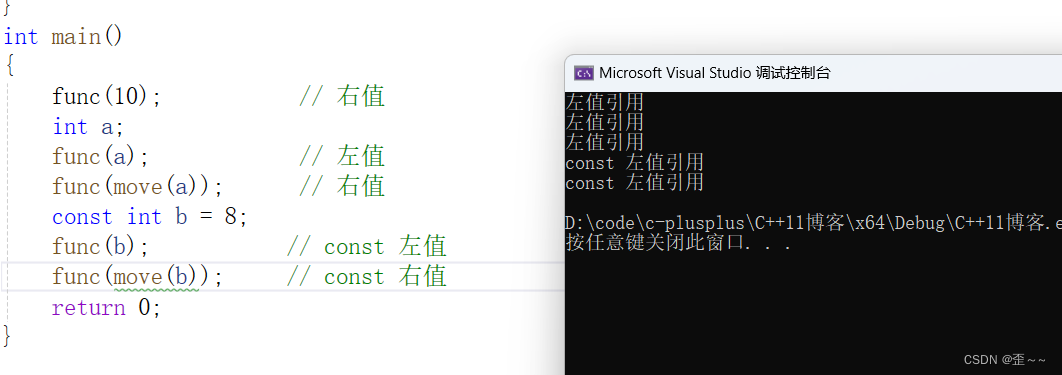
首先我们看到不可思议的一幕,我们能理解上面的func函数是一个模板函数,并且函数模板参数是右值引用,但是我们看到变量a、b(虽然又有const,但他是常变量),也能能传过去并执行,const也能。其实这里应该是做了特殊处理,当模板和右值引用结合后,他就是一个万能模板了,意思是可以接收任何类型(和属性)的参数。
但是还有一幕,那就是为什么输出结果都是左值引用或者const左值引用啊?
这里就需要注意一点:
关于右值引用传参需要注意,只有当它传过去的时候是作为右值传送,但是当在被传到的函数体中使用这个
参数的时候,他就失去了右值属性而变成一个左值。
所以当我们传送到func函数中调用Fun函数的时候,不管你t是以什么属性过来的,在Fun中就都是左值了。那有没有办法让它一直保持原有的属性呢?那就是完美转发。
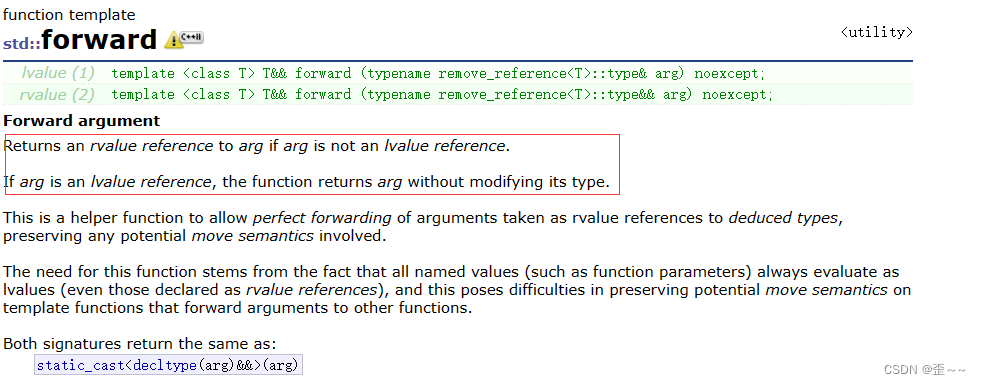
看上面的意思:
如果这个值是右值引用类型的话就返回右值引用,如果是左值引用不就返回左值引用。总之就是保留原有属性
那么我们的代码:
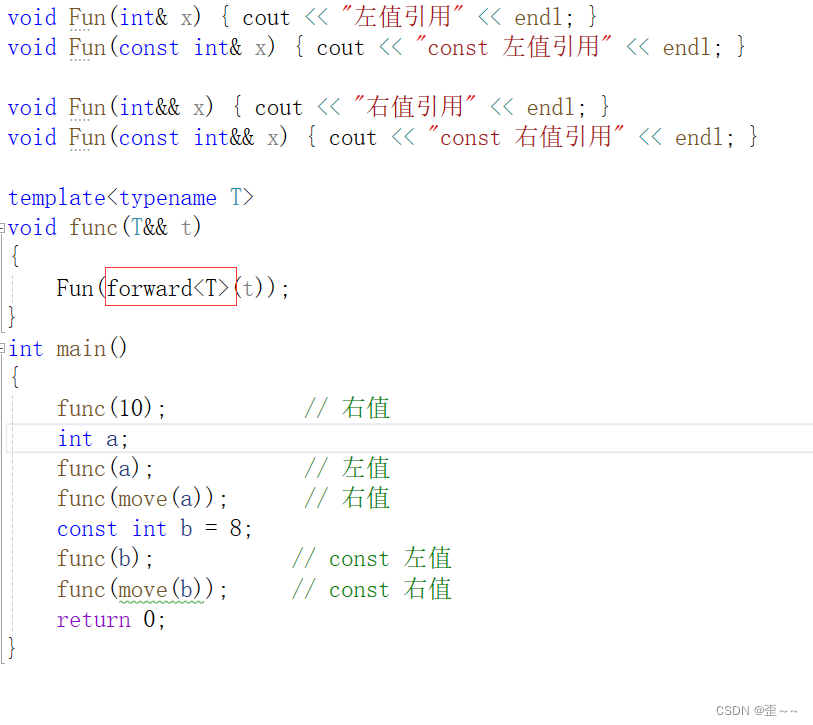
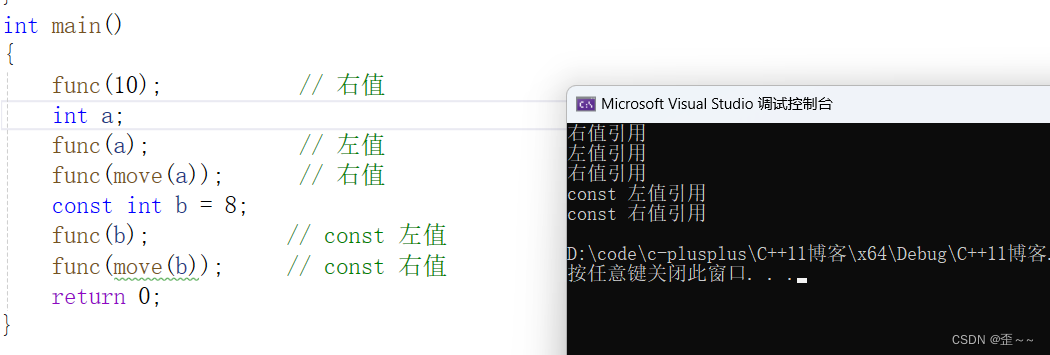
简单的示例说明
有什么用呢?可以看下面这个例子:
前面我们说了,STL中使用了右值引用的版本,那就意味着构造,赋值重载都使用了。
我们也在自己实现的string和list中简单使用一下右值引用:
先看我写的一部分代码:
首先是string中:

这其中我写了移动构造和移动赋值。
其次是list:
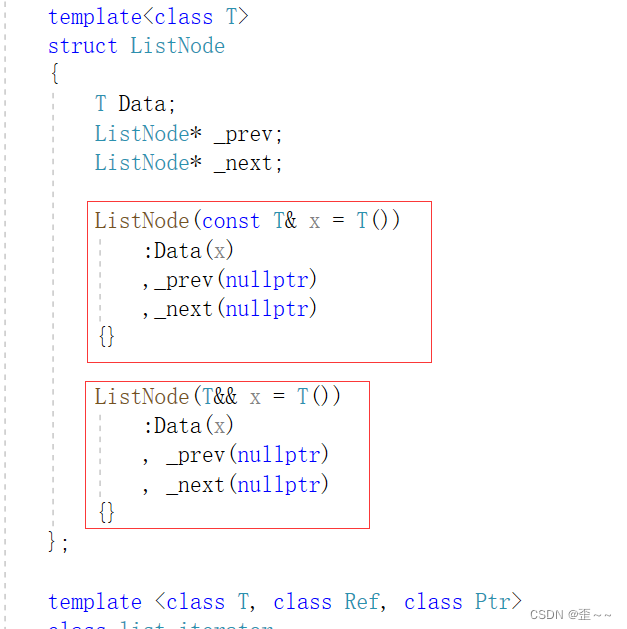
list中节点左值和右值不同的构造方式。

然后是list的各种右值引用版本。
然后我们跑这样一段代码:

运行结果:
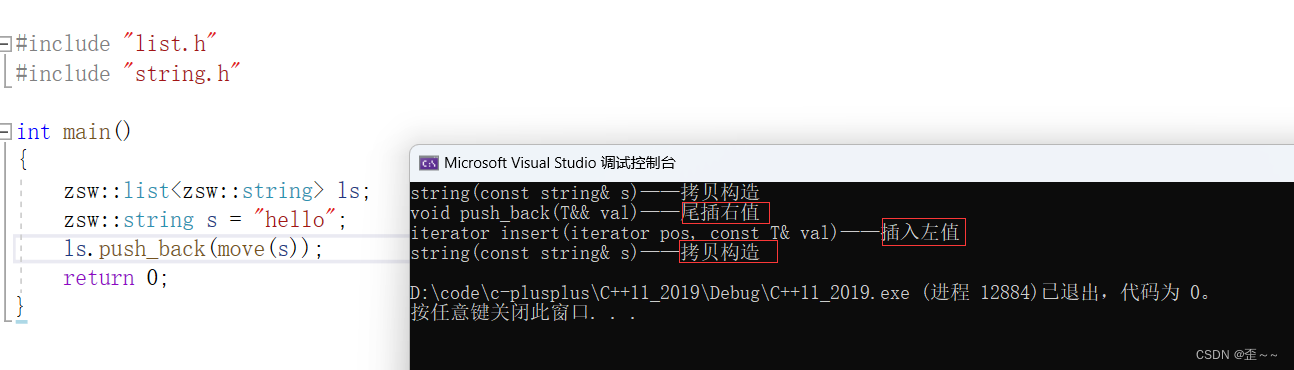
首先这里string对象s的初始化是构造+拷贝构造优化成直接拷贝构造,这没问题
然后我使用move改变s的属性,变成插入右值,这也没问题。
我的尾插右值封装的是插入右值函数(我认为是),但是他调用的是插入左值函数。
并且,在插入函数中,如果插入数据是右值的话应该调用的是我的右值节点创建,既然是右值节点创建就应该调用string中的移动拷贝构造。而这里调用的是拷贝构造。
综上,有两处是错误的,那么原因是什么呢?上面已经说过了:关于右值引用传参需要注意,只有当它传过去的时候是作为右值传送,但是当在被传到的函数体中使用这个参数的时候,他就失去了右值属性而变成一个左值。
所以我们在这里就应该一直在这条路上维护数据的右值属性,那么有两种方法:
第一种:这条路上的参数使用move移动语义
第二种:这条路上的参数使用完美转发。
我是用第二种,也推荐第二种:


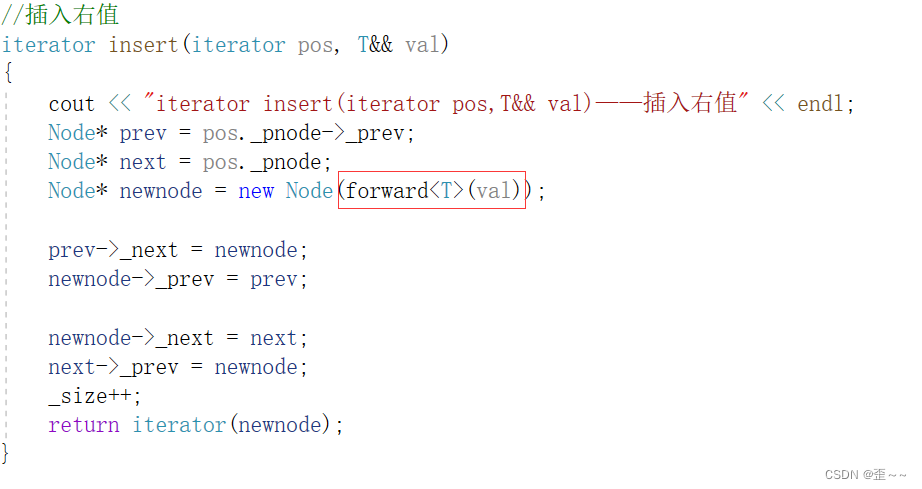
再次运行:
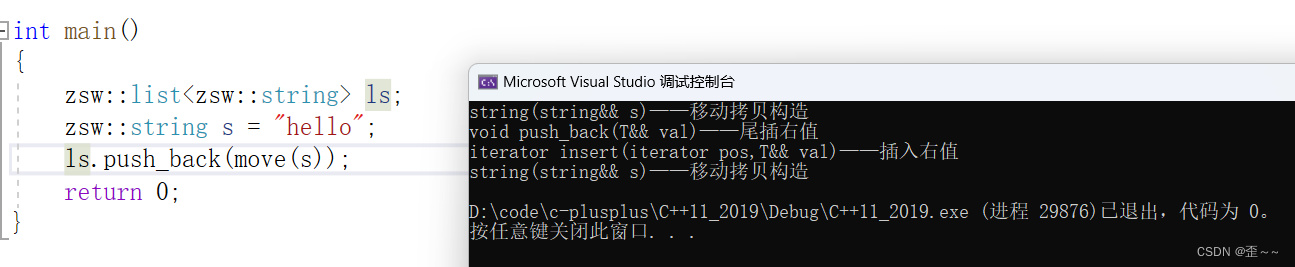
这其中第一行的拷贝构造变成了移动拷贝构造,应该是编译器优化的缘故,并不是语法。
注意:
forward是一个模板类,一定要带上模板参数!!!
(我好几次忘带,编译不通过。。)
3.默认成员函数
a. 新增默认成员函数
在之前C++中的默认成员函数只有六个,而之后又添加了两个:
那就是移动构造和移动拷贝,这两个函数的特性和前面六个不太一样:
1.如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载
中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,
对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是
否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
2.如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值
重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造
函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个
成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默
认移动赋值跟上面移动构造完全类似)
3.如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
上面说的很多,但是我们在实际编写代码的过程中在类中析构、构造、赋值重载都不写的情况太少了,这导致根本不会有默认的移动拷贝和移动赋值生成,所以作为了解即可。
b. default/delete的新意义
强制生成默认函数的关键字default:
??C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使用default关键字显示指定移动构造生成。
禁止生成默认函数的关键字delete:
??如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且只声明补丁已,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
4. 可变参数模板
a. 可变参数模板
在C语言中我们曾对可变参数有着简单的了解:

在我们以前对模板的认识,他能有类型模板参数和非类型模板参数,但是它的参数的个数是确定的,而在而在C++11中模板和可变参数又产生了新的化学反应:
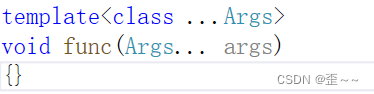
看起来是一个很怪的写法。话不多说先来展示它的用法:
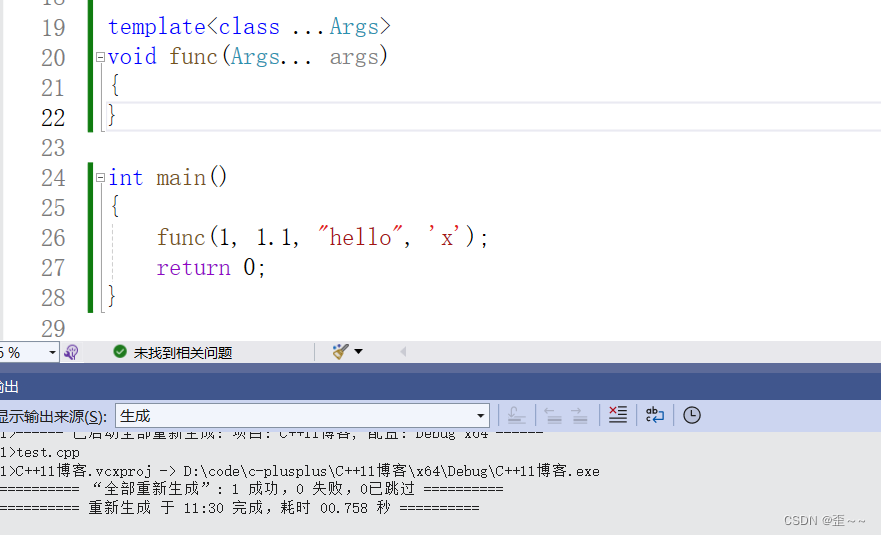
我们看到他能够编译通过,那说明变量args中存储着这四个值,怎么拿到这四个值呢?有两种方法:
通过递归推演来拿到其中的各个值

关于递归推演还是比较好理解的,实际上编译器会做特殊处理把参数包中的参数一个个给了t,要注意…Args和args…的使用正确使用方式
通过逗号表达式拿到其中的各个参数
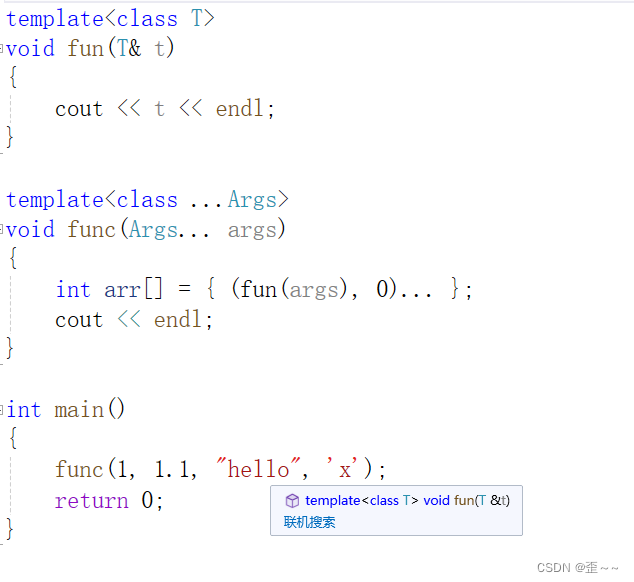
要初始化arr,强行让解析参数包,参数包有一个参数,fun就依次推演生成几个。关于这种用法记住就行。
b. STL容器中的empalce相关接口函数
我们可以看到C++11中出现了一个新的东西:

它实际用起来跟普通的插入差不多:
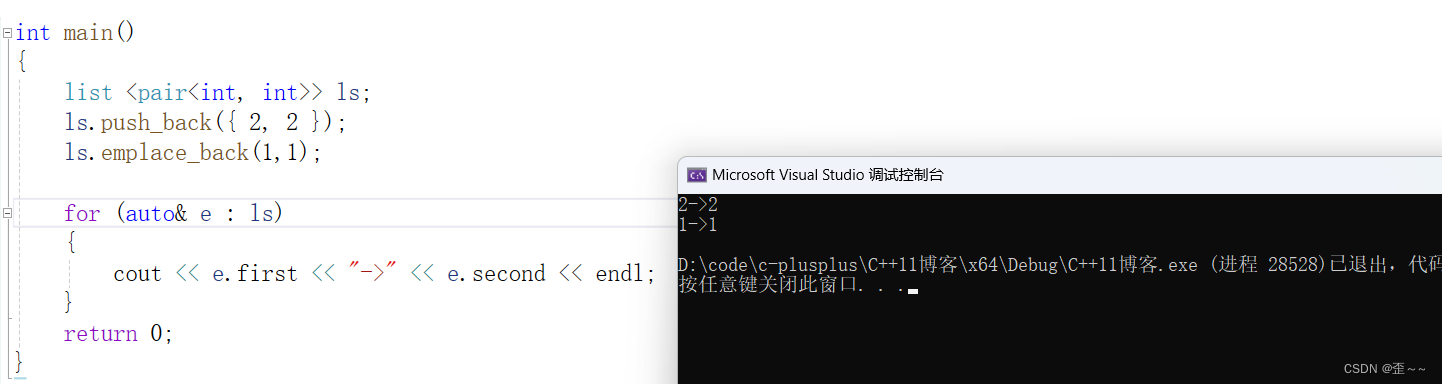
但是我们看到还是有所不同,在使用普通的尾插时,我们是花括号传参,代表传的是一个根据pair构造函数传的一个初始化的列表。但是下面的emplace_back则是直接传了两个参数,这里的原因就是emplace_back使用了可变参数模板:

我们也来实现一下他这个东西:


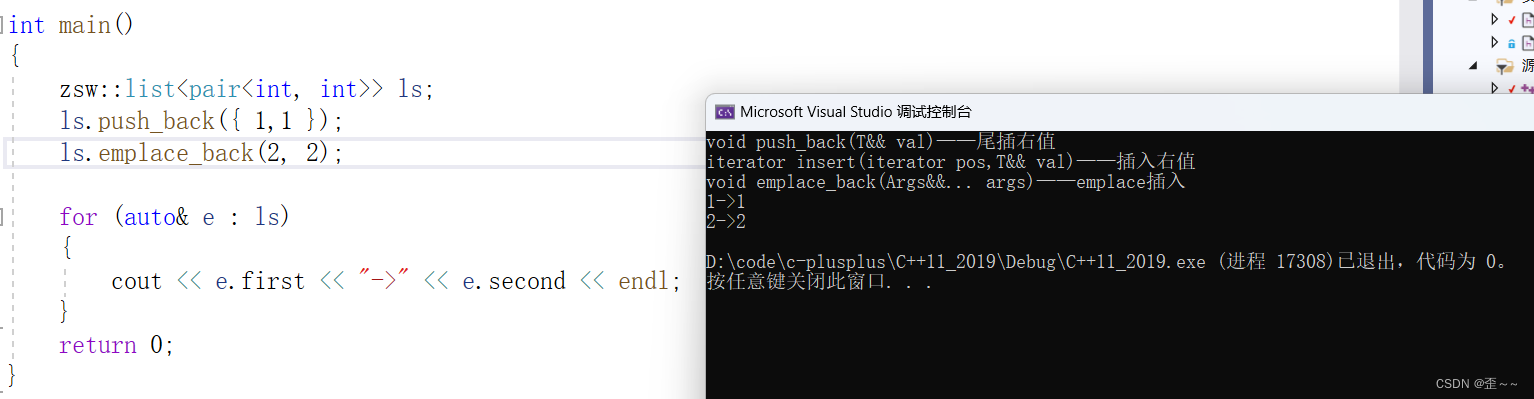
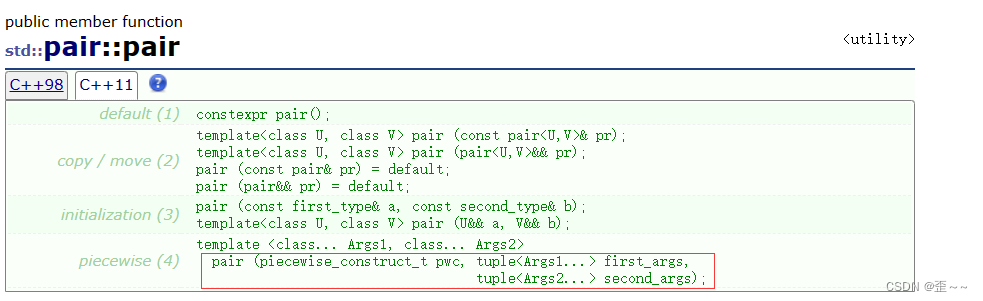
我们看到为什么上面的节点没有拆分args还能初始化呢?当然是pair里就已经有了啊:
5. Lambda表达式
a. 引入
以前我们要对一个vector(例子)里的内容进行排序我们会这么写:
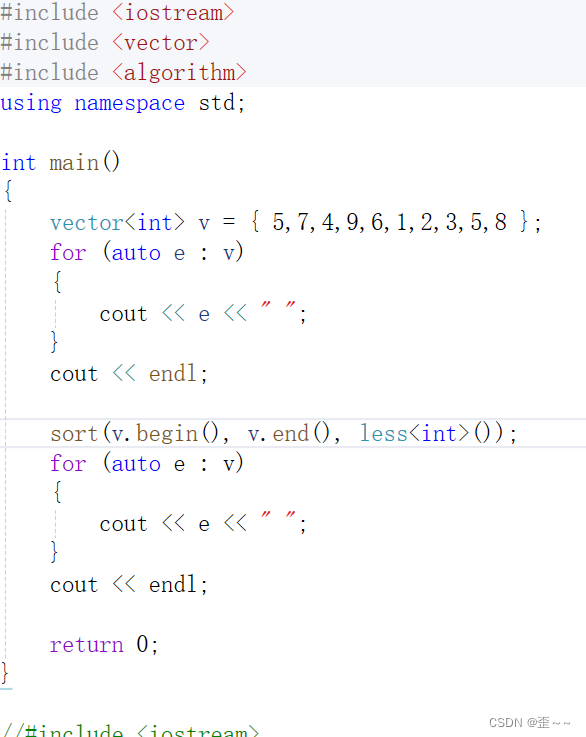
但是我们要排的是这样子的元素呢?
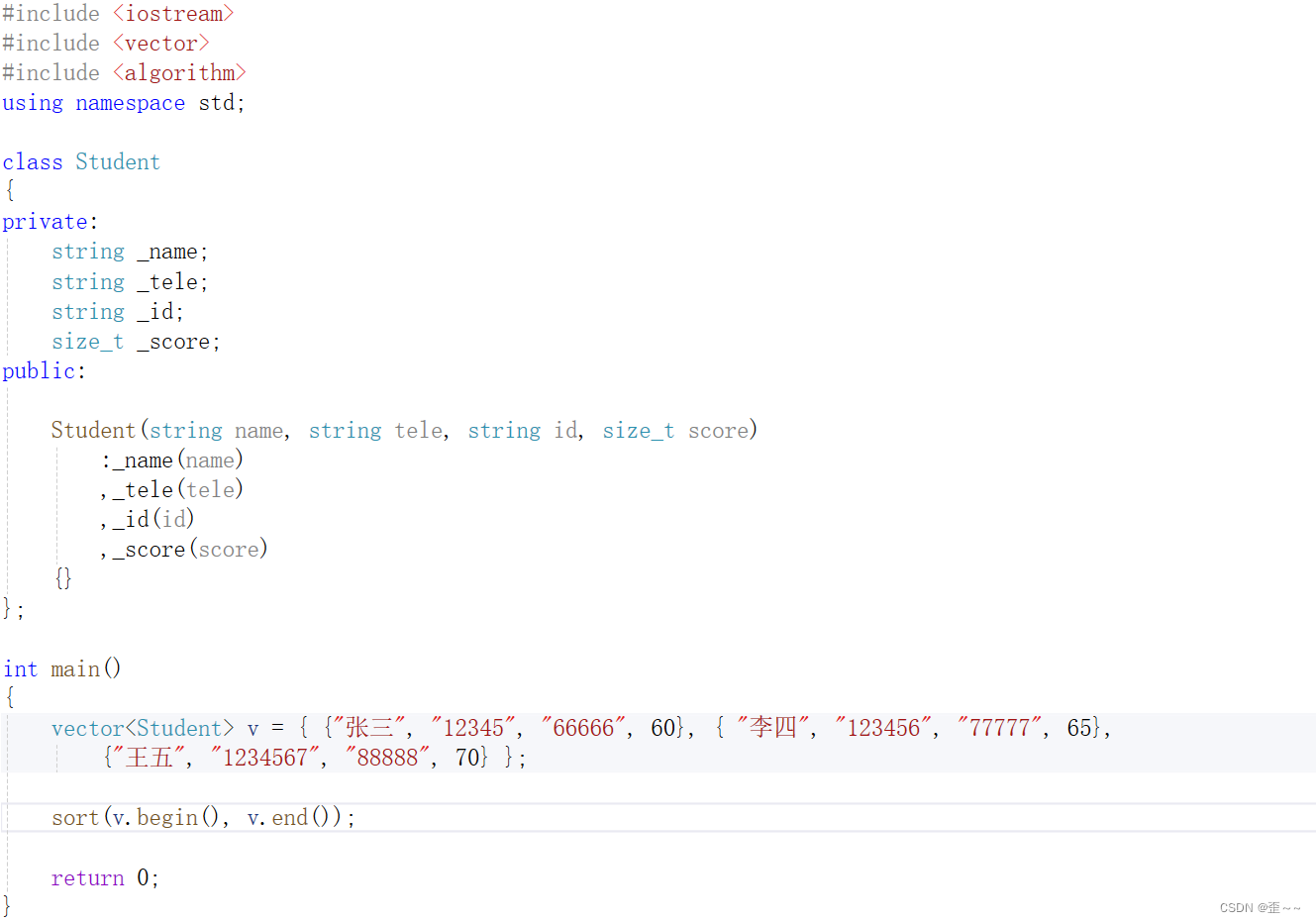
那显然,对于自定义的类,要将他们进行排序,就得有不同的比较规则,那么不同的比较规则又会有许多的仿函数来让我们写,就比如上面我们要分别根据四个成员为依据来一次排序,那我们会这样:
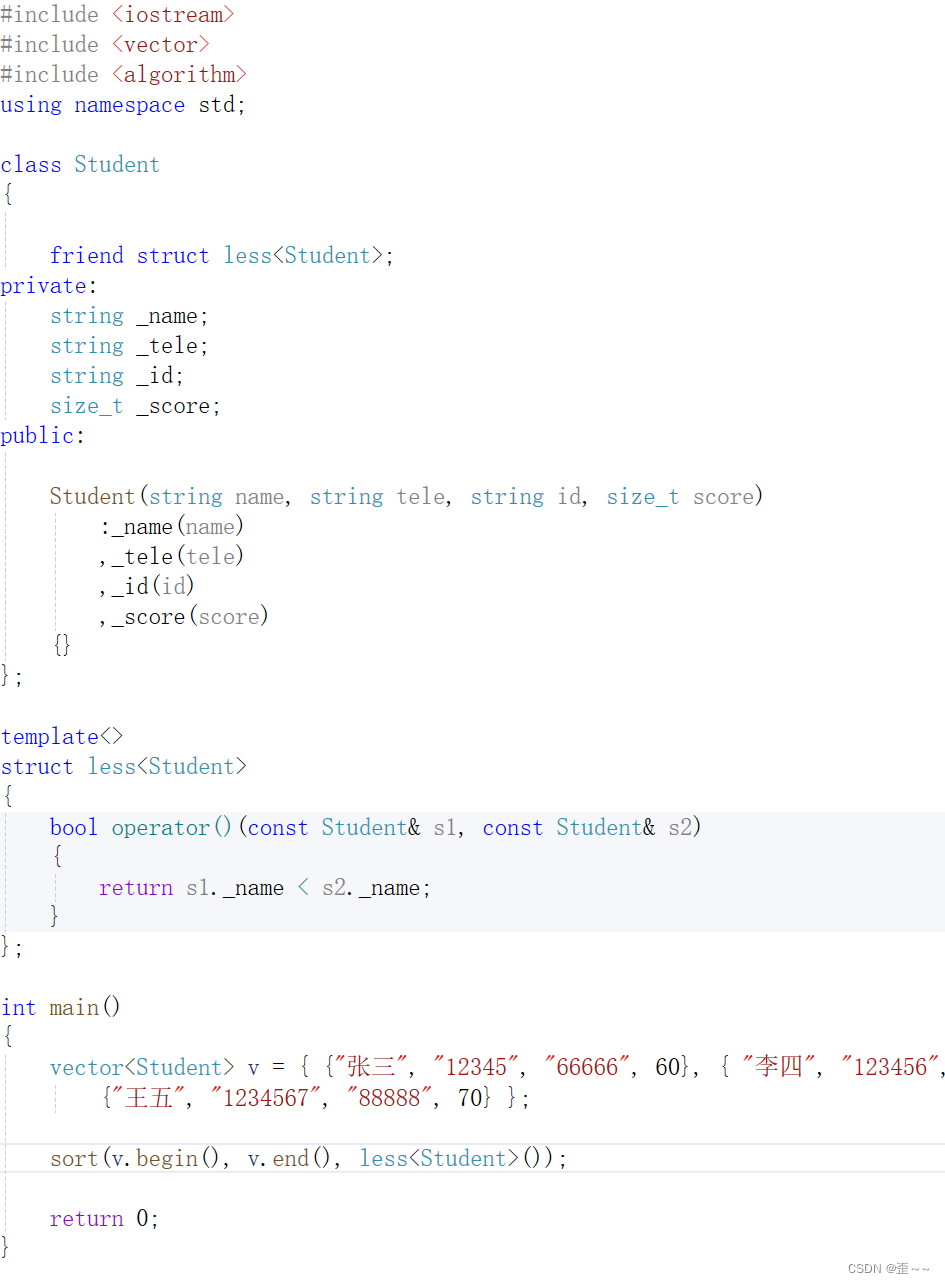


这里我只写一个。每个比较依据,都得重写一次仿函数,太费事了,而此时,隔壁的python有一个好东西我们值得借鉴一手,那就是Lambda表达式,但是与python中的不一样,C++中的当然是得跟C++中语言特性有关联:
那我们再次对上面排序做一下修改:

这就是Lambda表达式。
b. 简单认识
Lambda表达式主要有以下部分组成:
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement
}
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获
到的变量。
捕捉列表和mutable我们先忽略,那他看起来是不是就和一个函数一样啊:
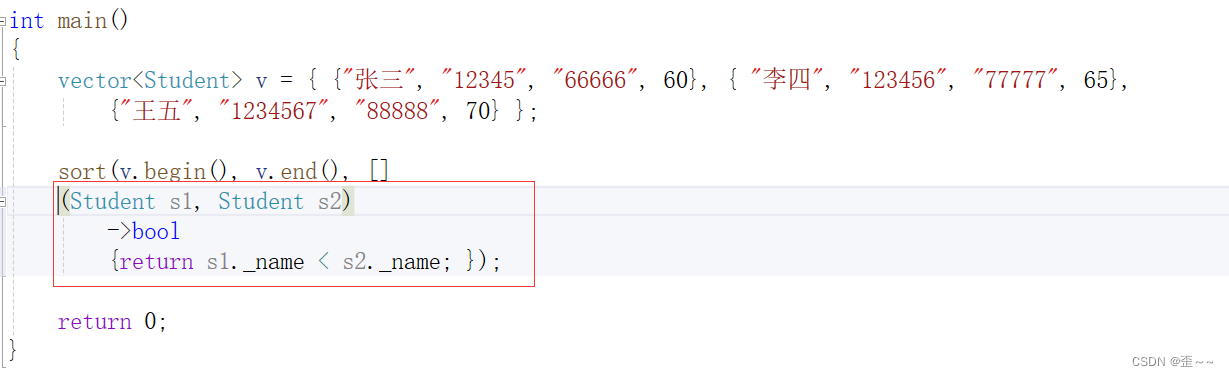
只不过写起来有点不一样,那我们现在再来认识一下捕捉列表和mutable是什么?
c. 捕捉列表
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:
a. 父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉
其他所有变量[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉
其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何
非此作用域或者非局部变量都会导致编译报错。
mutable
我们先写一个简单的表达式:

可以看到,x和y是不允许被修改的,而且这里有一点小问题,我们等会儿一起说。
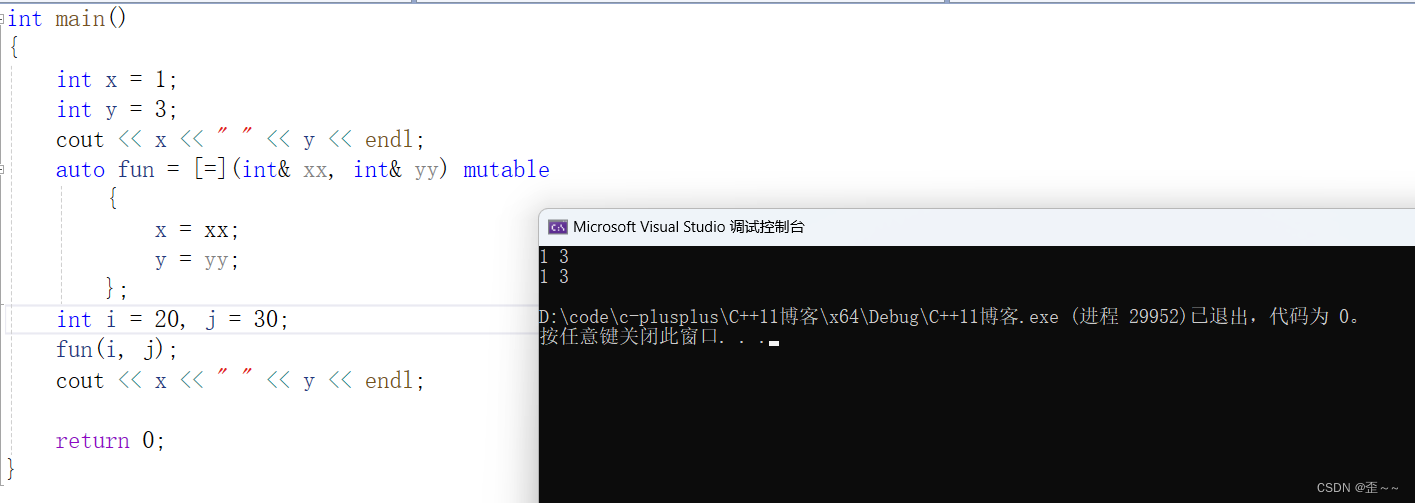
现在可以修改了,但是为什么实际没有修改啊?
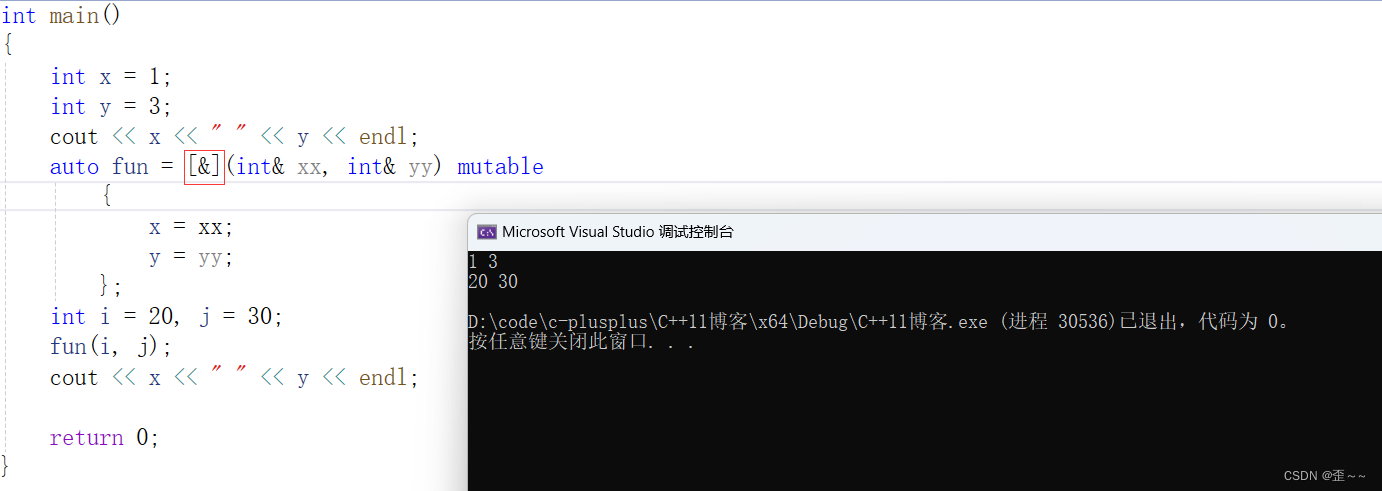
现在又修改了。我们首先是可以看到的是当我们捕捉父作用域的参数的时候,在表达式内部其实是默认不允许我们修改捕捉到的变量的值的,所以这时候我们就可以使用mutable来改变这种性质,就可以修改了。
Lambda表达式的一些小知识点
1). 类型
首先我们看到这么一句:
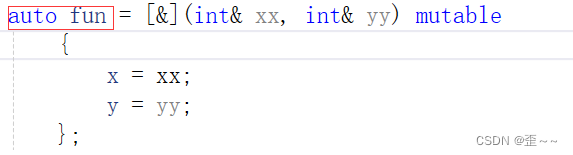
Lambda是可以给一个变量的,那我们看看这个变量的的类型是什么:
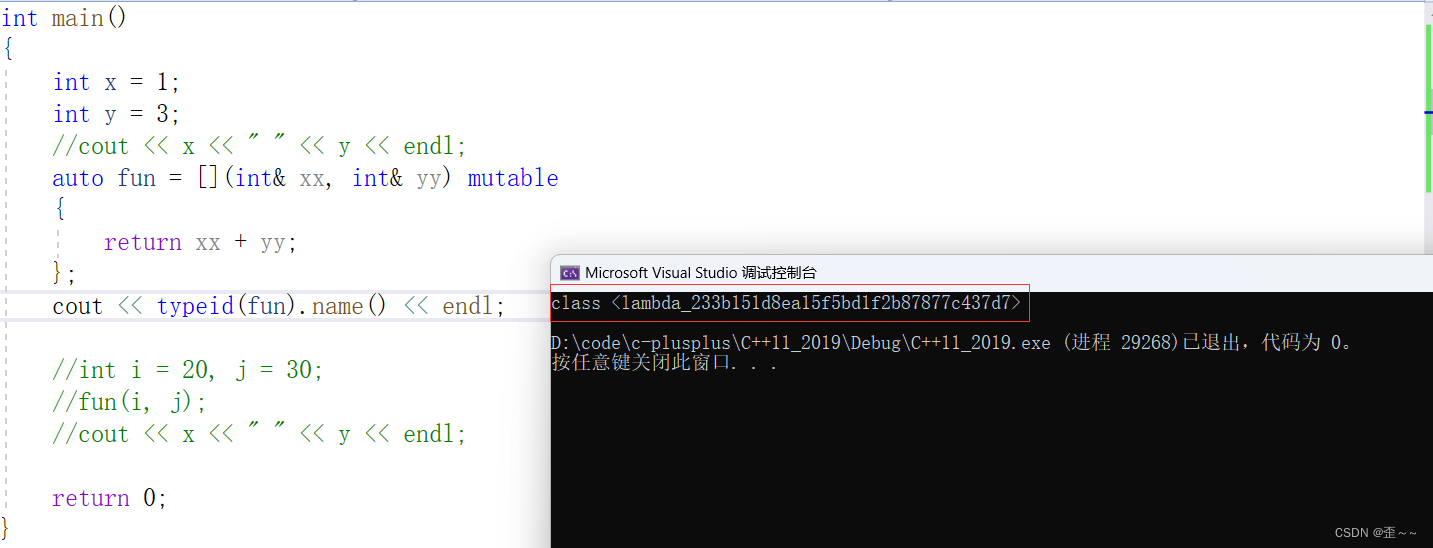
这是在VS2019中的命名,我们看到它是一串乱码,这个乱码其实是uuid: link。
而在VS2022中它的命名是这样:
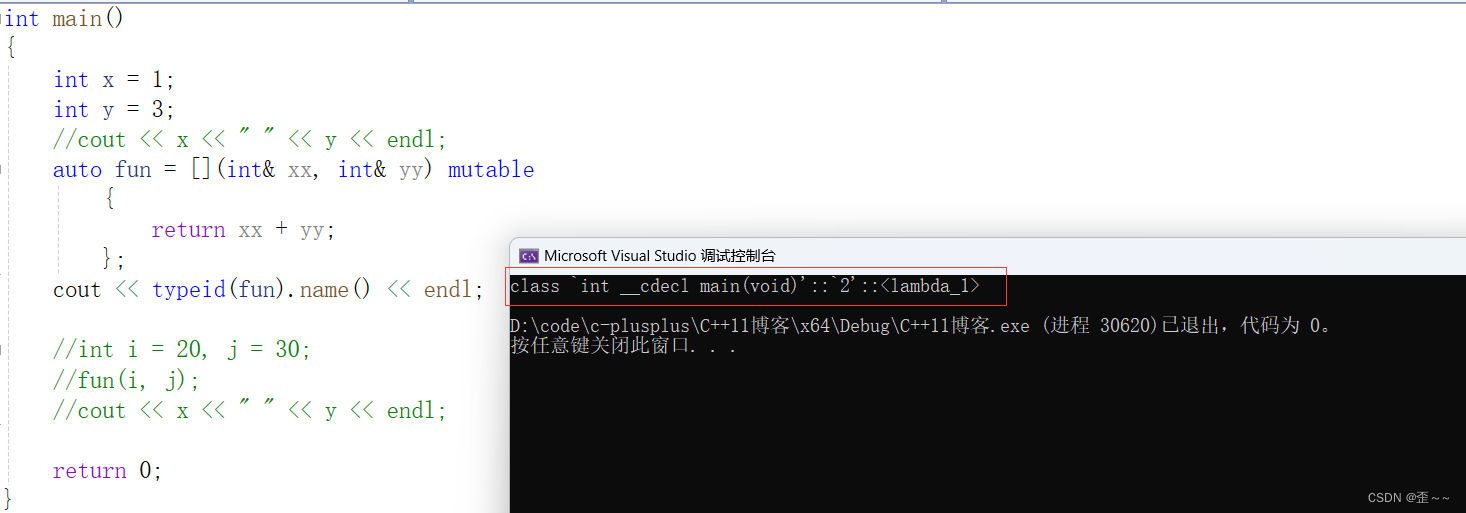
但是不管怎么样,它都是一个类,在C++中Lambda表达式的本质其实也是仿函数
2). 要注意的点
那还有一点:为什么这么做没有修改啊?
按照经验来说,这里其实是传值了,被捕捉到的x和y变量和外面的x和y已经没关系了:
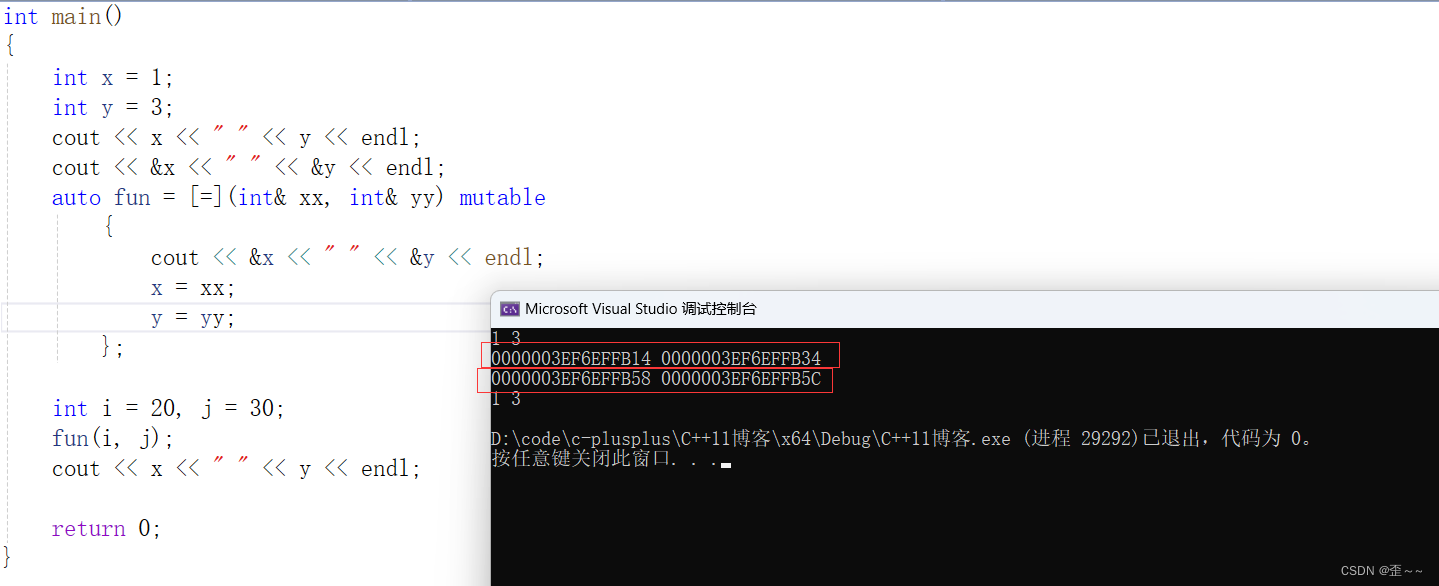
那第二次修改后能修改成功了,那自然也是传引用了:
其实:

当我们捕捉引用的时候,不需要加mutable就可以修改捕捉的参数了,这是编译器做的特殊处理。
3). 本质
至于为什么说C++中Lambda表达式本质上就是仿函数那看下面这段代码:
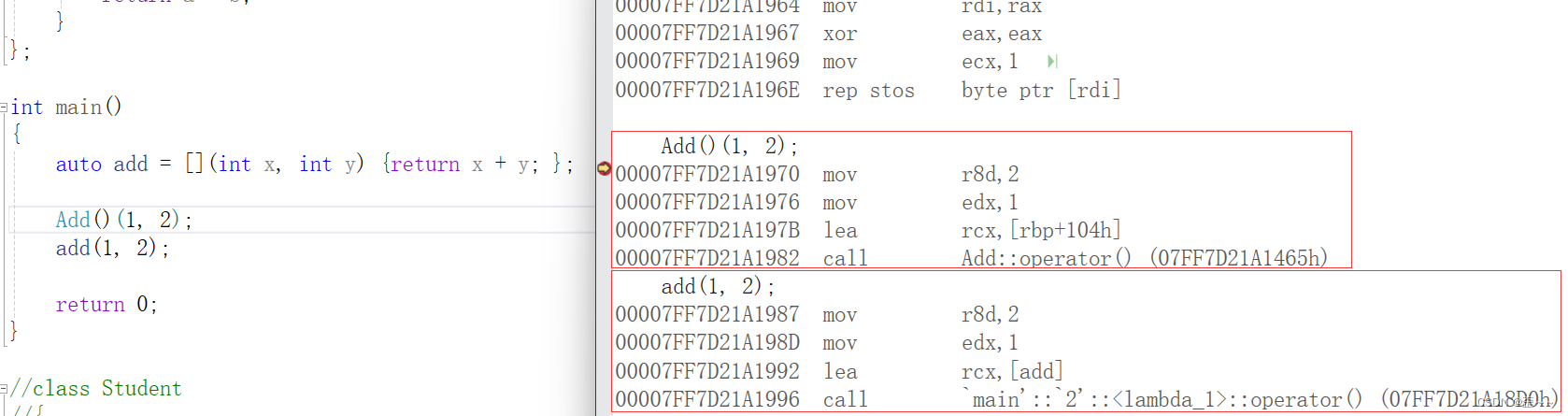
不能说没有关系吧,简直是一模一样。都是重载()而已。
4). 类中的Lambda
还有在类中的Lambda是怎么样的:
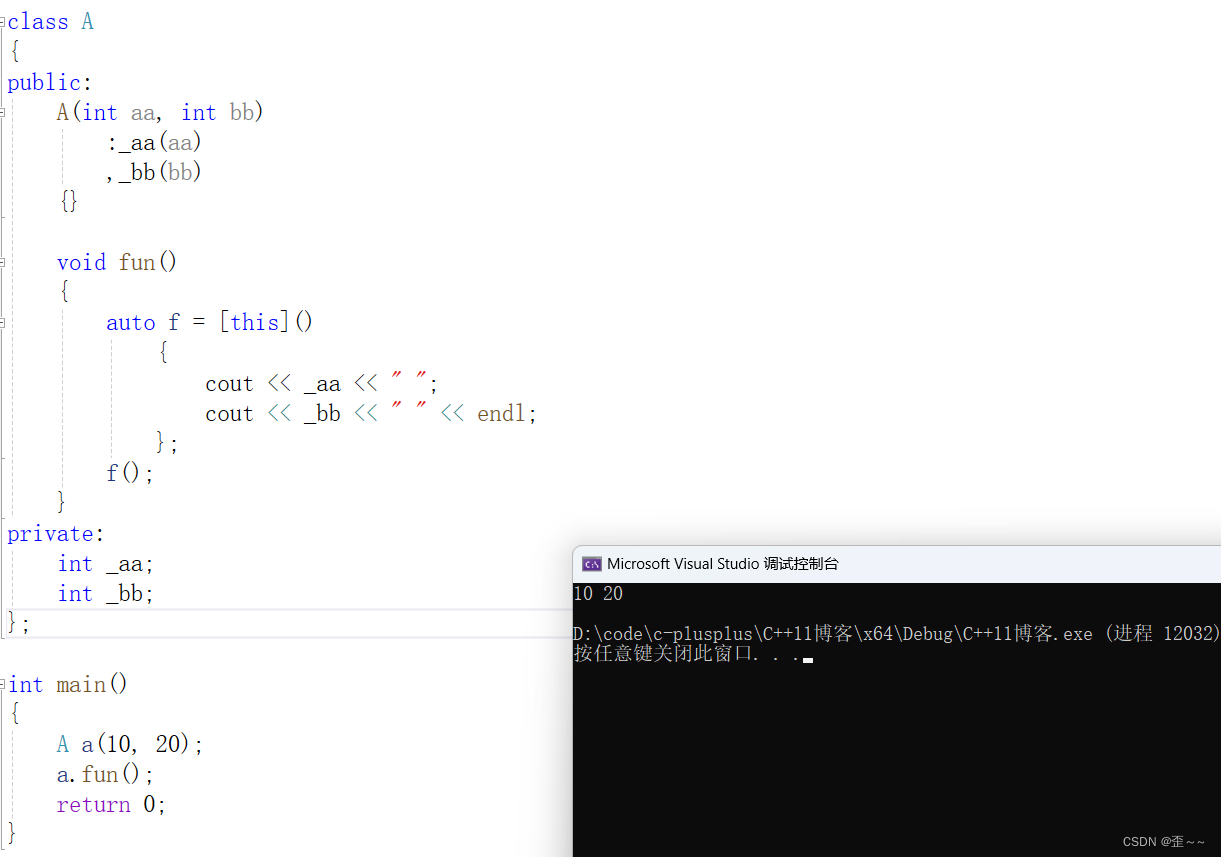
很正常,其实也可以这样:
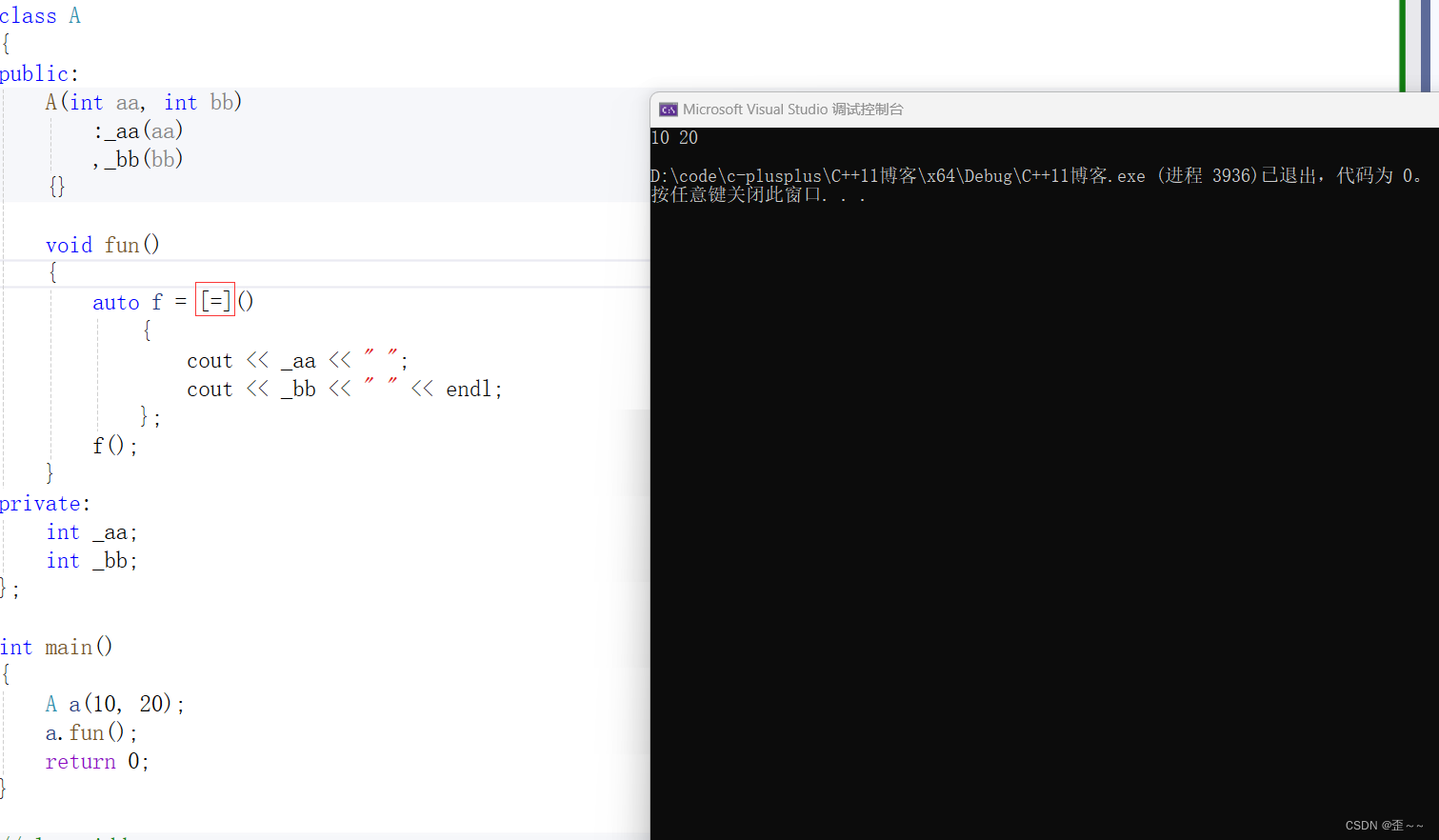
还有这个:但是和上面还是有区别的
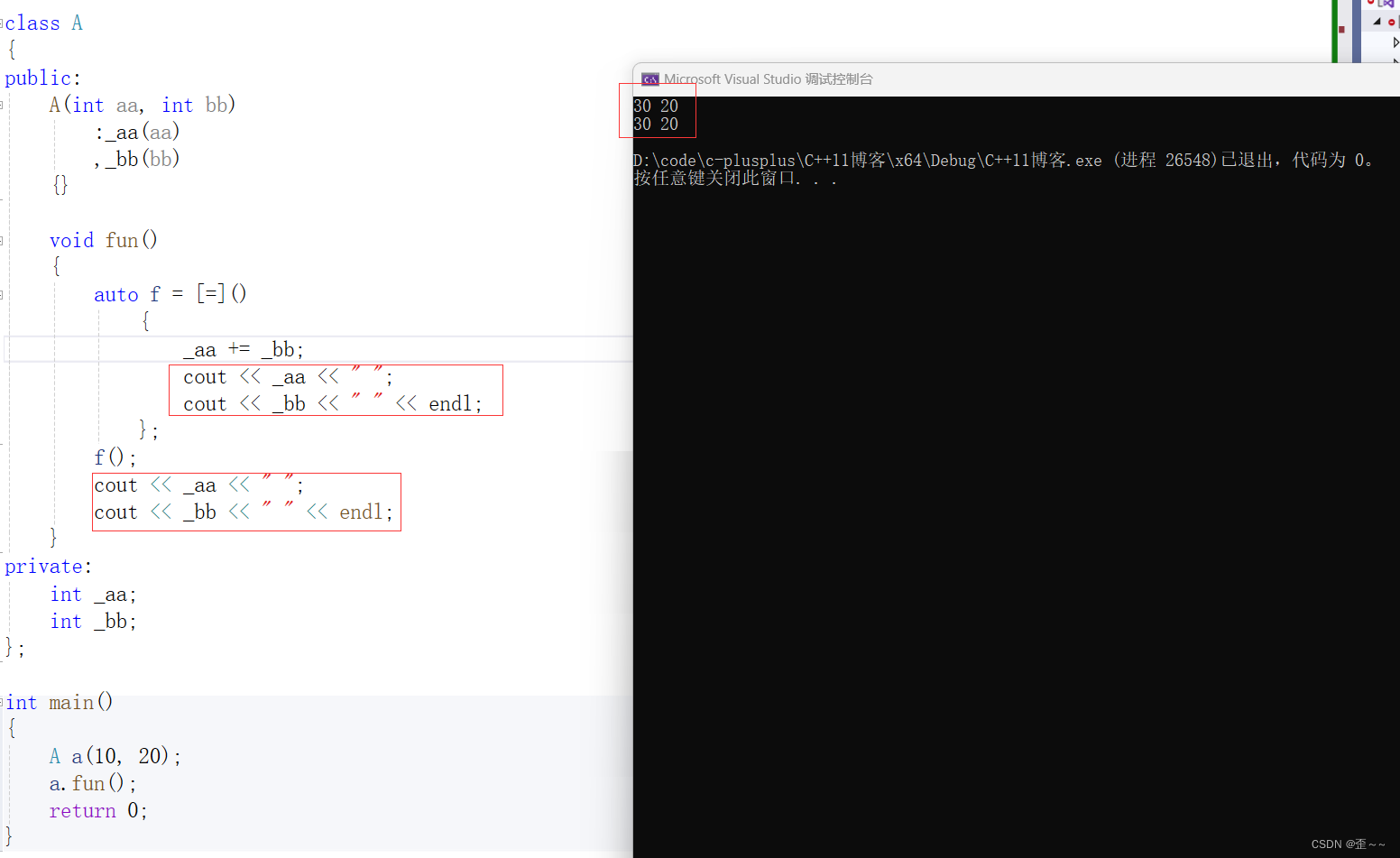
有人可能就犯迷糊了,不是刚上面说了捕捉列表传值修改不了原数值吗?这就是混淆了,这里是捕捉的_aa和_bb吗?其实捕捉的是this指针,这里能直接使用_aa和_bb,的原因是编译器又做了特殊处理让它变得跟在成员函数中那么用一样。
6. 包装器
a. 引入
到现在,我们通过对象调用函数的方式已经有有三种了:函数指针,仿函数,Lambda表达式。
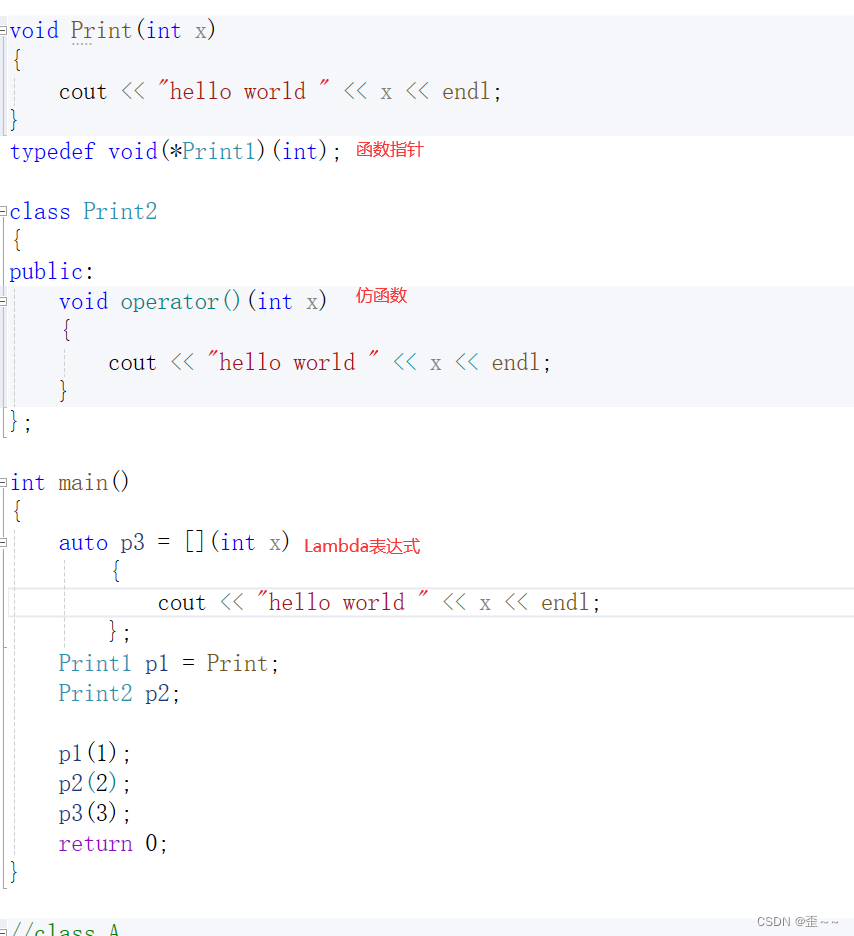
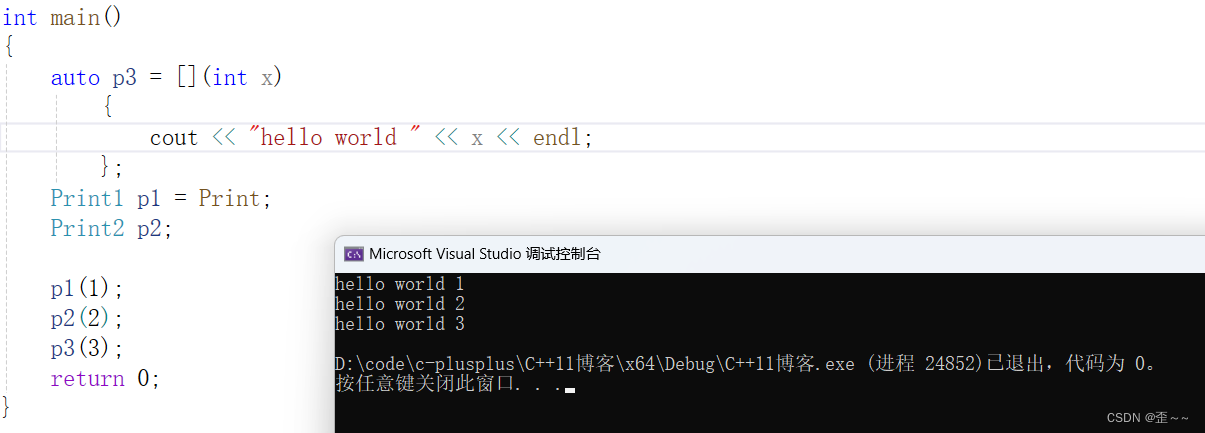
他们都有着属于自己的特点,以及不同时代语言的特点。所以在历史的开发过程(C/C++)中,那么一定会刚开始是函数指针,然后是仿函数,再是Lambda表达式。那么这样的代码流在市面上,导致了代码和接口的使用有了差异性,所以函数包装器(function包装器)就应运而生,它是一个类模板(使用了可变参数列表)
b. 使用
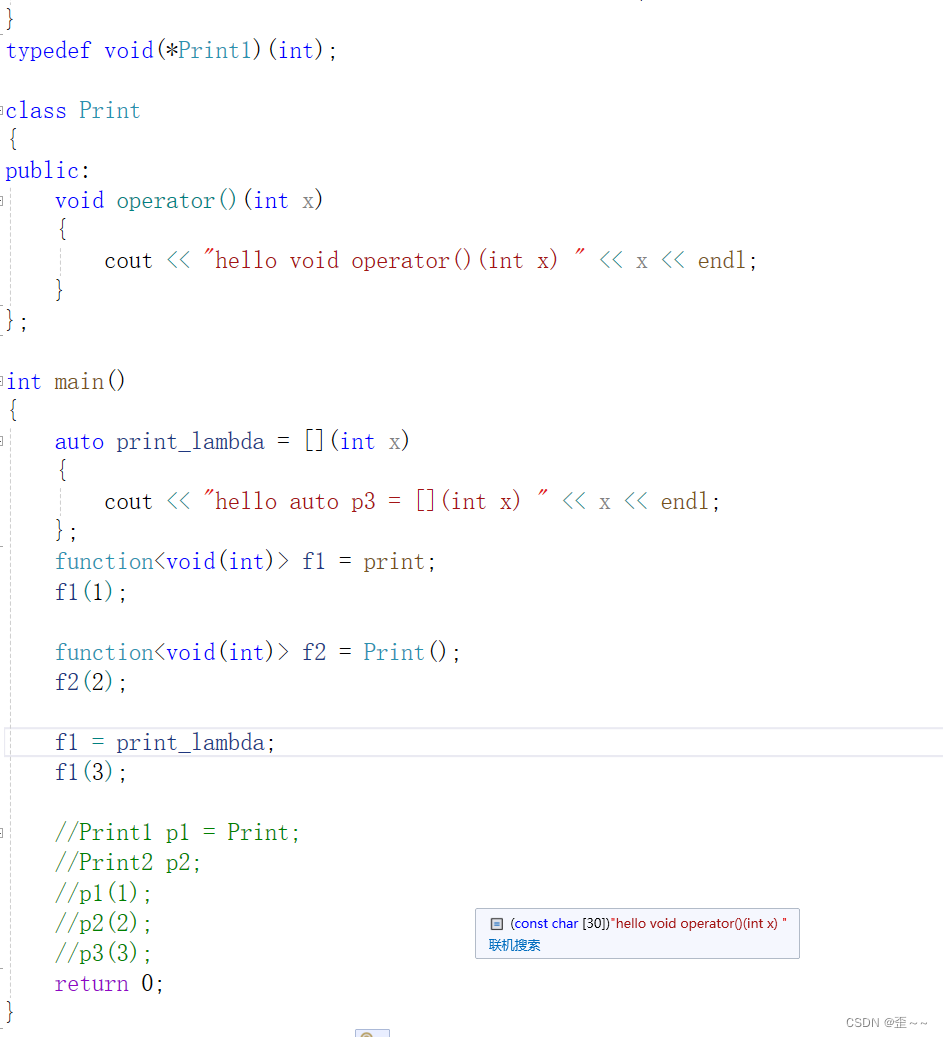
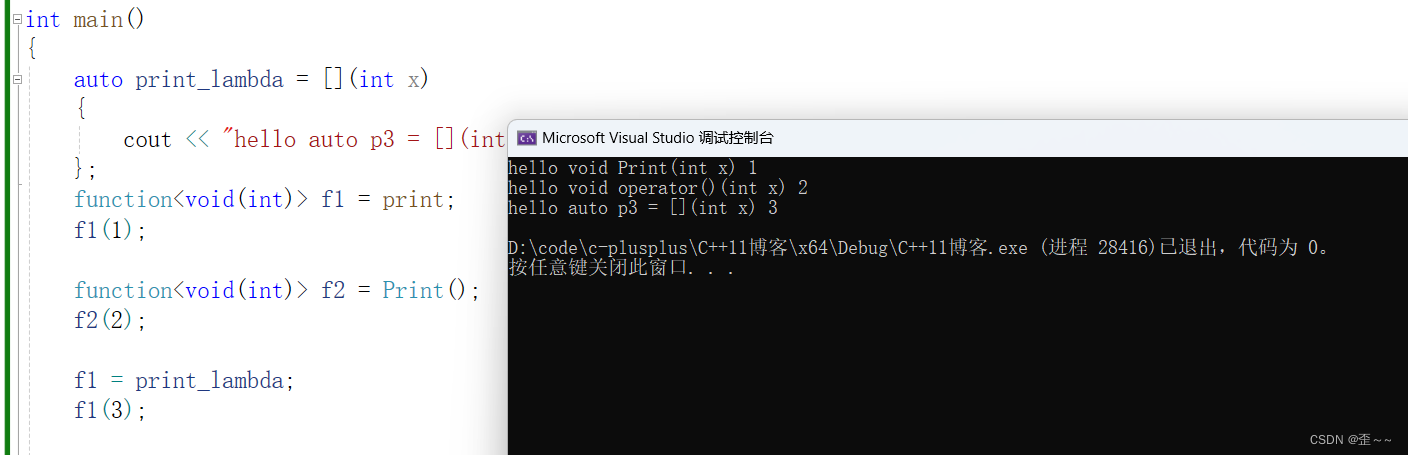
// 类模板原型如下
template <class T> function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;
模板参数说明:
Ret: 被调用函数的返回类型
Args…:被调用函数的形参
c. 场景
那上面实际有什么用呢?我最近想自己写一个植物大战僵尸,其中关于植物的创建就是用了这个知识:


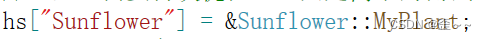

我们看到运用多态和包装器的知识我们可以写出这样的代码(虽然不用包装器也可以)。而且这里也有了一个新知识:
成员函数比较特殊,要加一个类域和&
d. bind
bind是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象
(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一
般而言,我们用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,
返回一个接收M个(M可以大于N,但这么做没什么意义)参数的新函数。同时,
使用std::bind函数还可以实现参数顺序调整等操作。
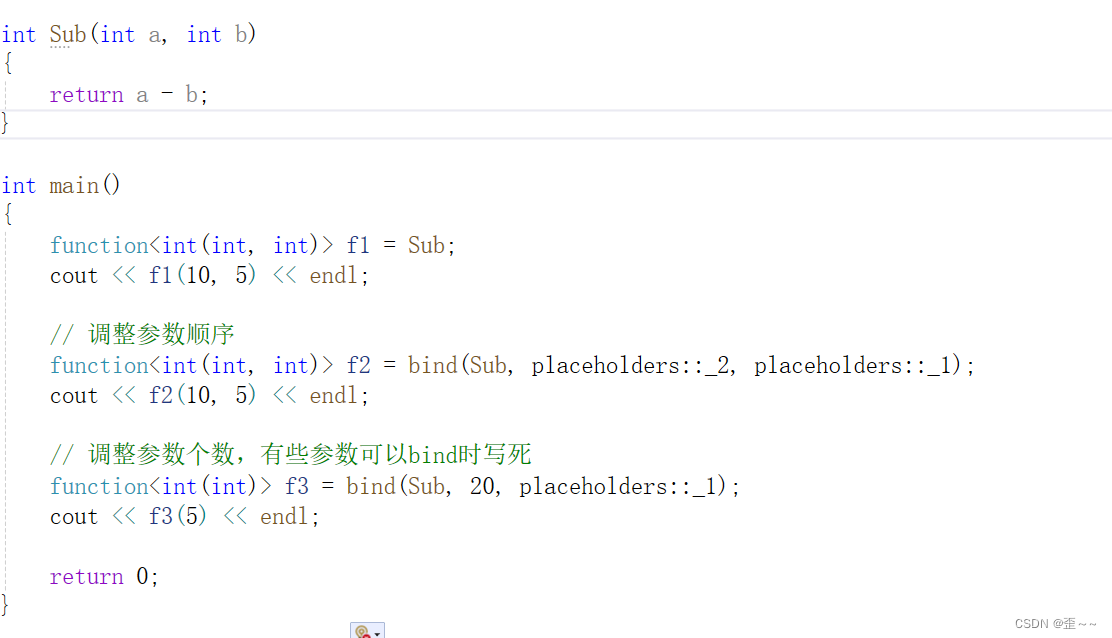
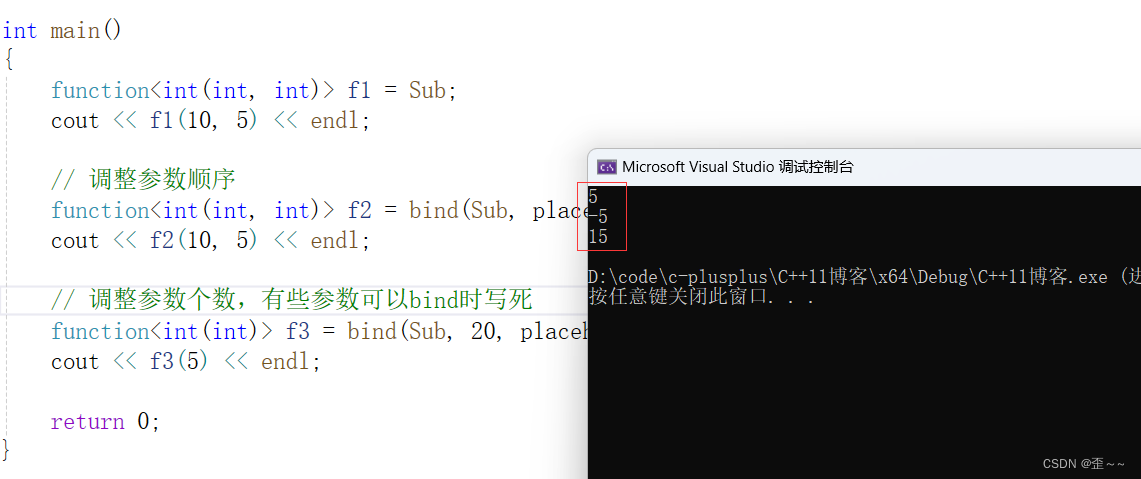
这种一般是用在网络部分(知识盲区了。。),其中的接口有很多参数,但是部分参数在一些场景中都是一个值,或者不同的人写出来的接口中参数顺序不太一样,就可以使用这个来修改,让自己使用更方便。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!