python爬取中南林绩点
1.当我们进入vpn网站的时候会有安全隐私提示我们要让程序可以自己点击,使进入到登录页面
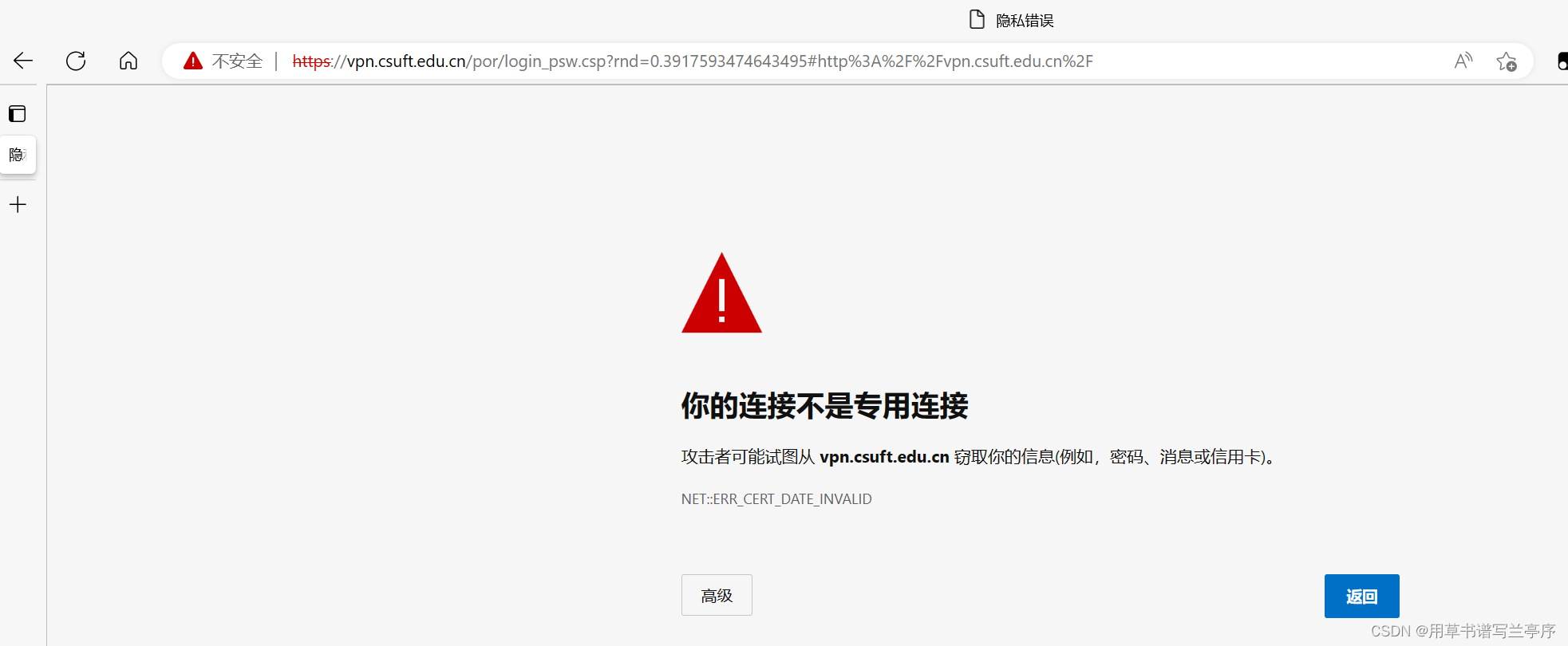
2.查看高级按钮的定位信息,我们可以通过id属性定位

#点击安全设置
browser.find_element(By.ID,"details-button").click()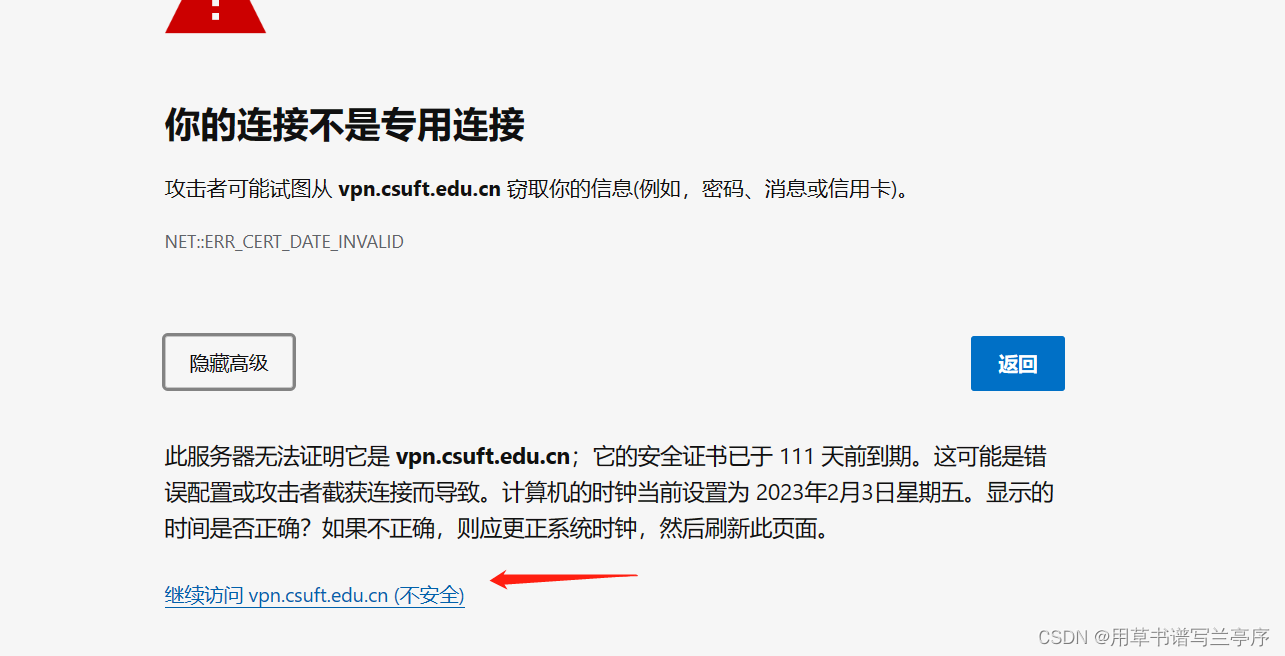
3.我们需要点击继续访问也是可以用id属性来定位

browser.find_element(By.ID,"proceed-link").click()4.现在我们就进入到了vpn的登录界面我们现在要做的就是第一步定位到用户名密码输入框,第二步输入用户名和密码,第三步定位到登录按钮并且点击click
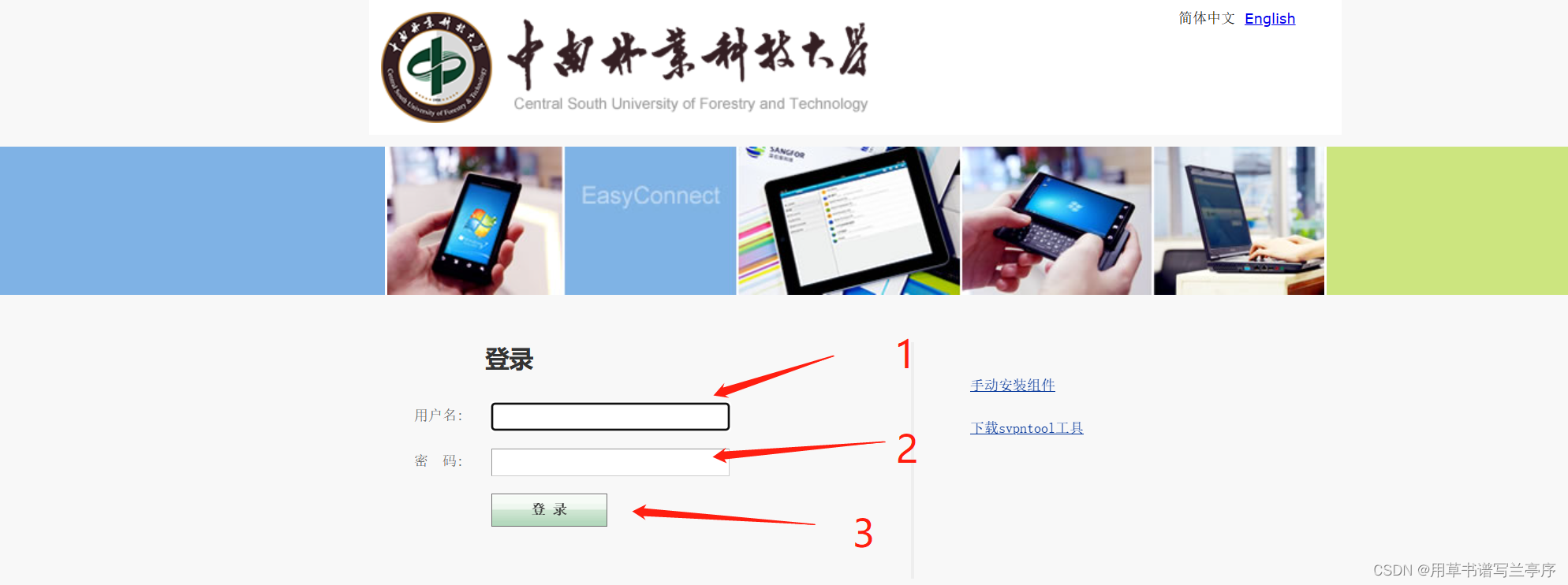
我们通过检查元素可以找到输入框的源码,我们就可以通过id或者是name属性进行定位,然后用send_keys进行输入

![]()
# #定位到账号密码输入框并且输入账号密码
browser.find_element(By.ID,"svpn_name").send_keys("20212832")
browser.find_element(By.ID,"svpn_password").send_keys("wsndqd857857")我们同样也可以按照id来定位到登录按钮并且点击
![]()
#点击登录登录按钮
browser.find_element(By.ID,"logButton").click()5.找到我们学校的教务管理系统点击,发现跳到了另一个网站,此时我们只要让selenium再次进入教务管路系统的网站即可,因为现在已经挂上了vpn
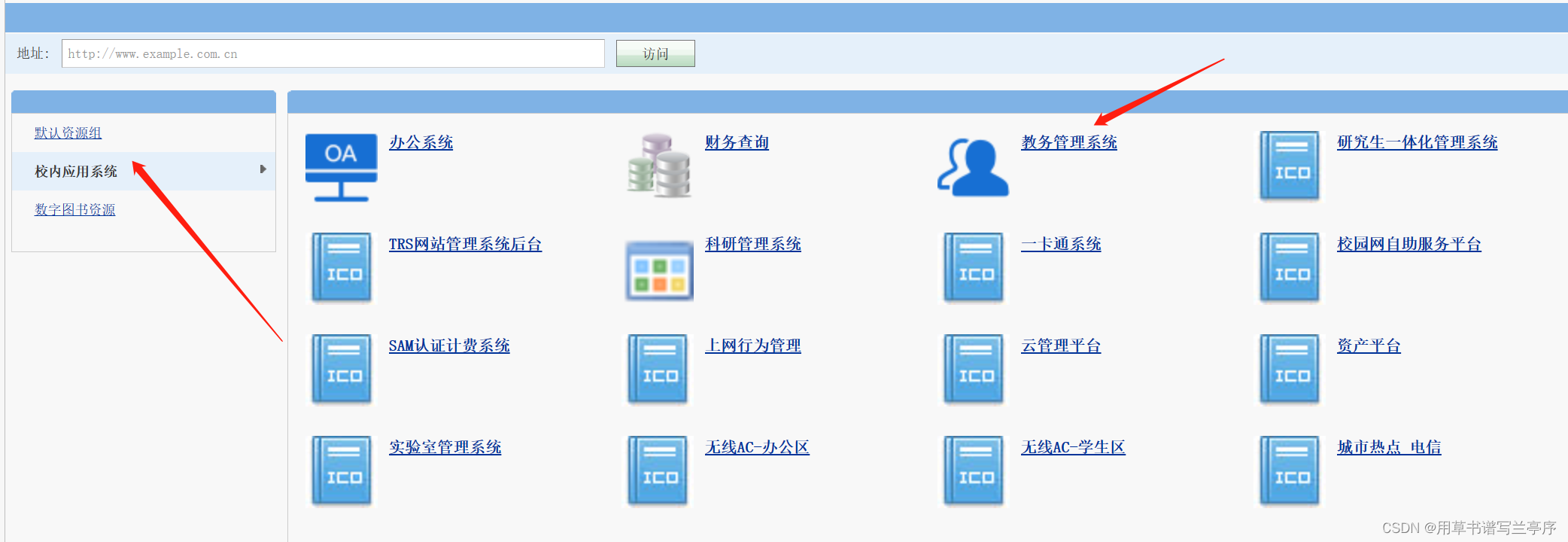
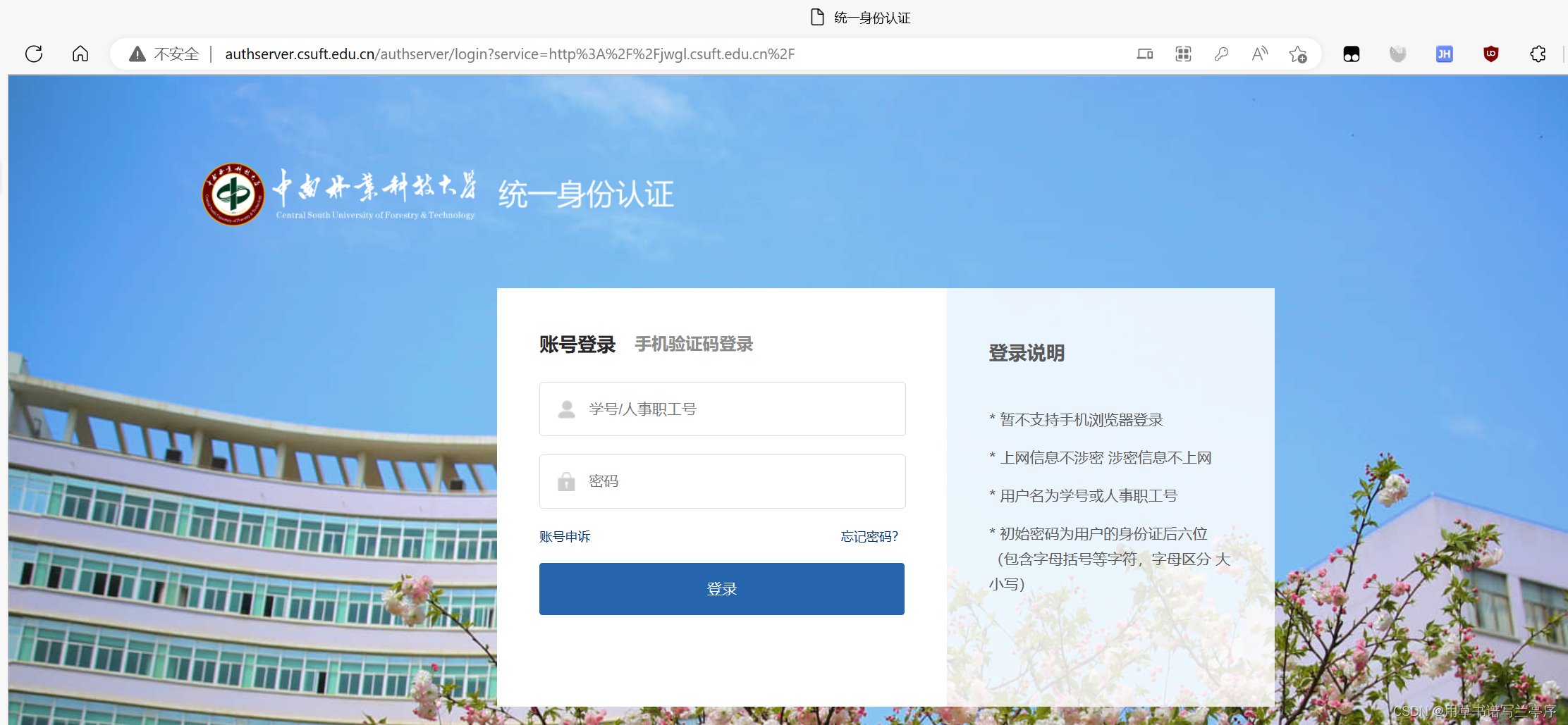
6.登录教务管理系统,登录的操作这里就不再演示了过程和登录vpn的过程是一样的就省略了。
#跳转到学校教务系统首页
browser.get('http://authserver.csuft.edu.cn/authserver/login?service=http%3A%2F%2Fjwgl.csuft.edu.cn%2F')
#输入自己在教务系统的账号密码,并且点击登录
username =input('请输入您的账号')
browser.find_element(By.ID,"username").send_keys(username)
password =input('请输入您的密码')
browser.find_element(By.ID,"password").send_keys(password)
browser.find_element(By.XPATH,"/html/body/div/div[2]/div[2]/div[1]/div[3]/div[1]/form/p[5]/button").click()7.这个地方当我们进入到成绩查询页面的时候我自己再弄的时候最开始就是简单的把网页的源代码爬取下来了,但是在自己看的时候发现到了找不到关于表格的html代码使用我就去看了网络,看表格是怎么样加载出来的。
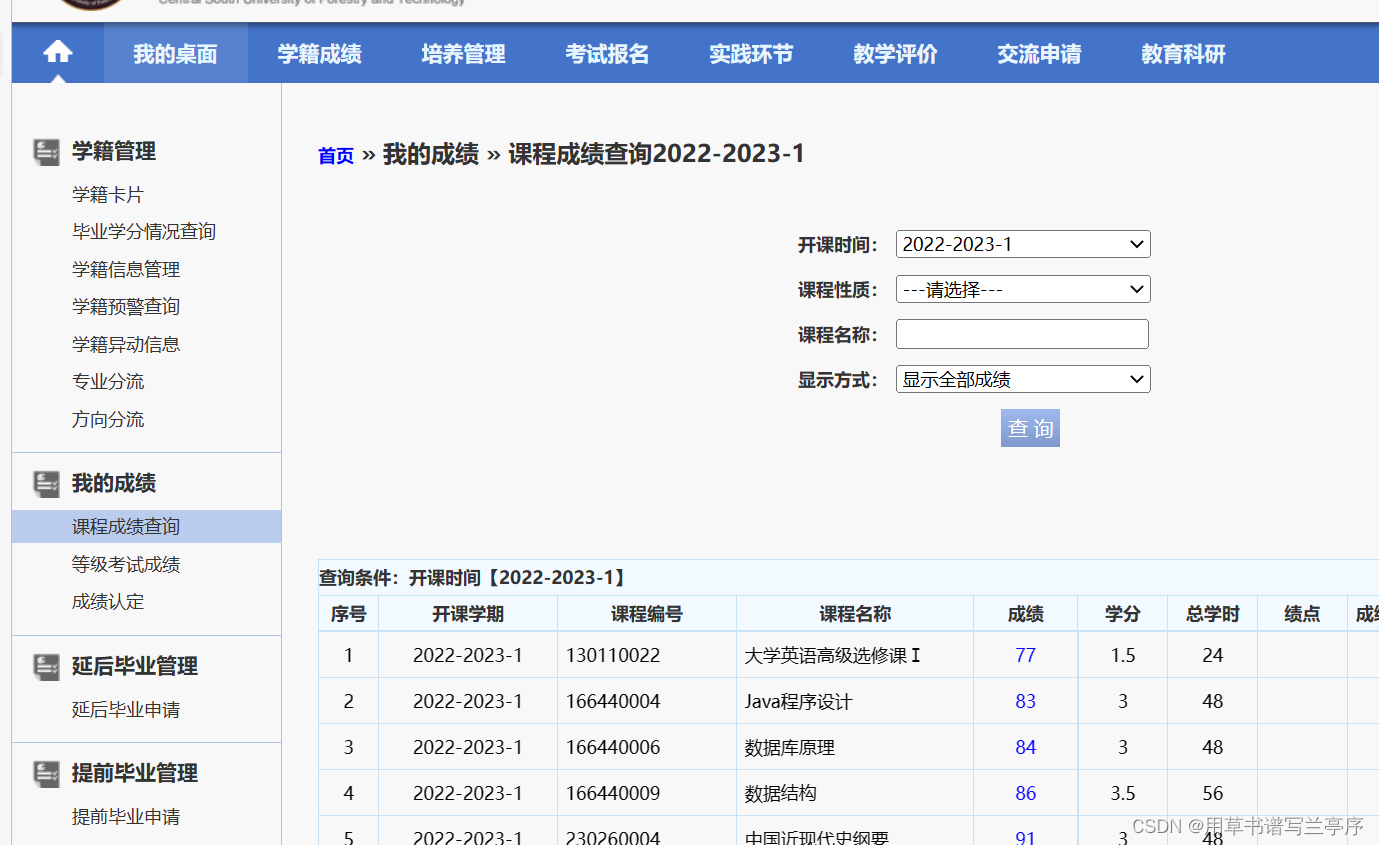
发现成绩是又这个请求获取到的,而且可以观察到请求后面的参数实际上就是我们的学期,所以在我使用的时候查看成绩就只要把kksj=后面的通过输入就可以找到不同学期的成绩了。
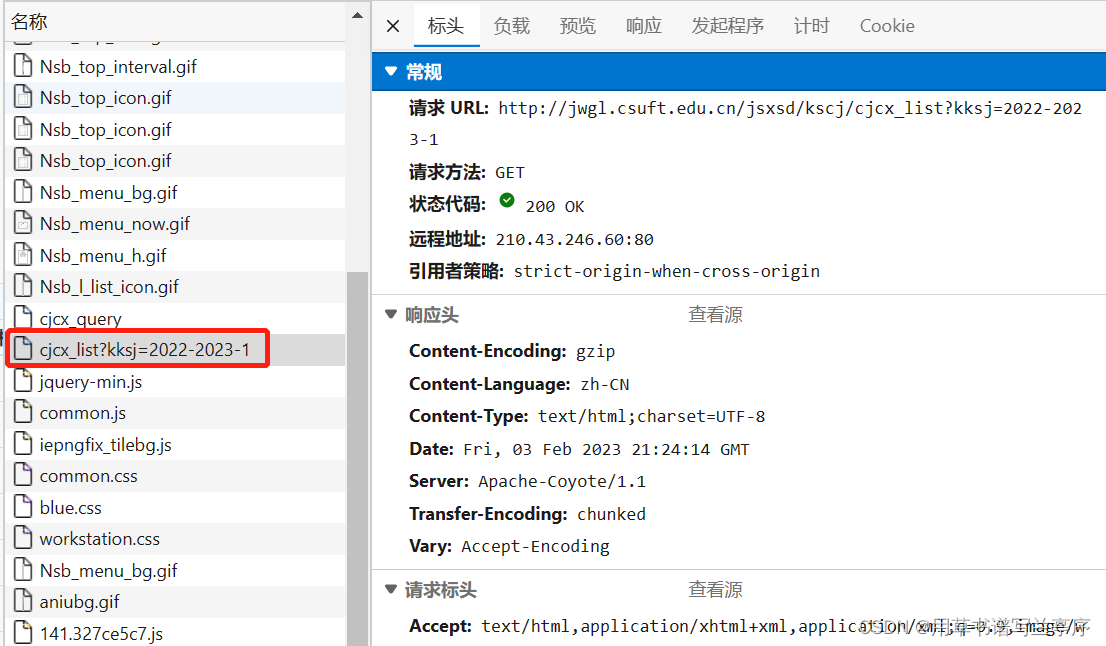
双击红框进入页面
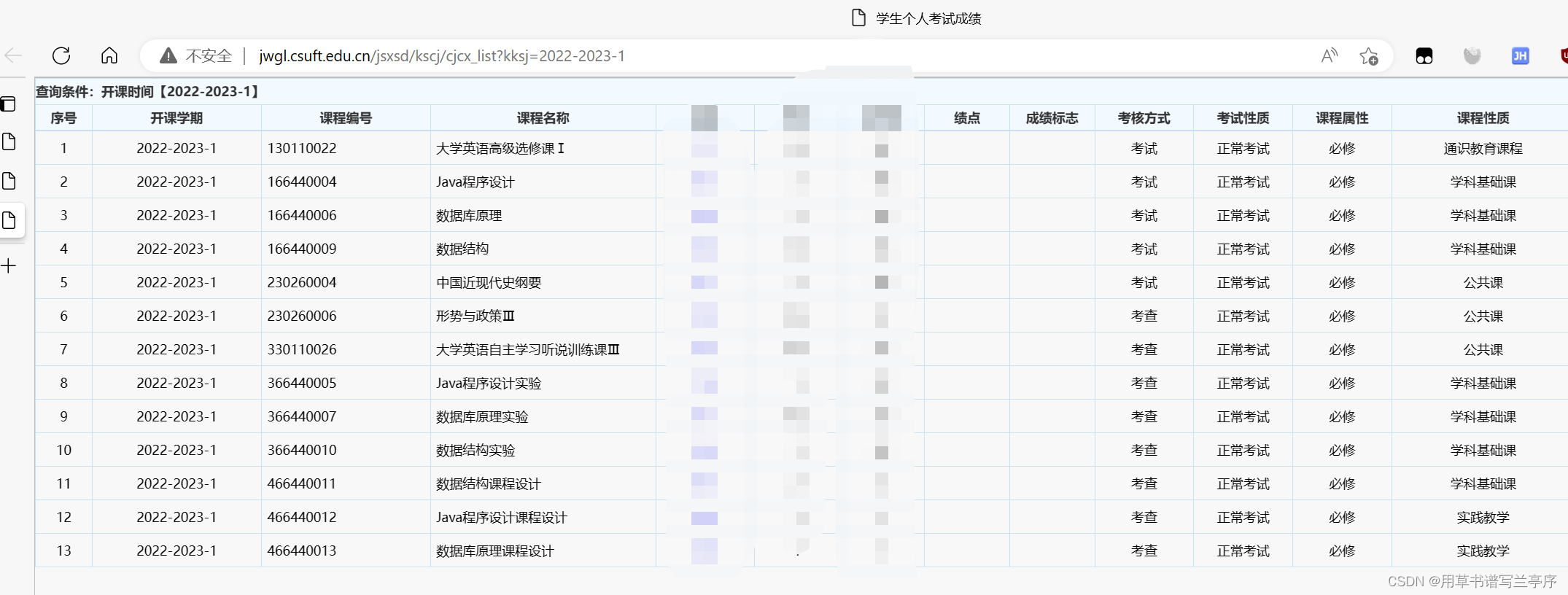
所以我们只需要得到这个界面的html代码就可以了
term=input("请输入你要查找的学期:格式如2022-2023-1\n")
#跳转到你要搜索的学期成绩
browser.get("http://jwgl.csuft.edu.cn/jsxsd/kscj/cjcx_list?kksj=%s" %term)
#获取学期成绩的html代码
html=browser.page_source8.通过正则表达式还有beautifulsoup来获取数据
for循环里面的soup.find(class_="Nsb_pw Nsb_pw2").find_all("tr"),先找到class属性为Nsb_pw Nsb_pw2,然后再找到每行的信息
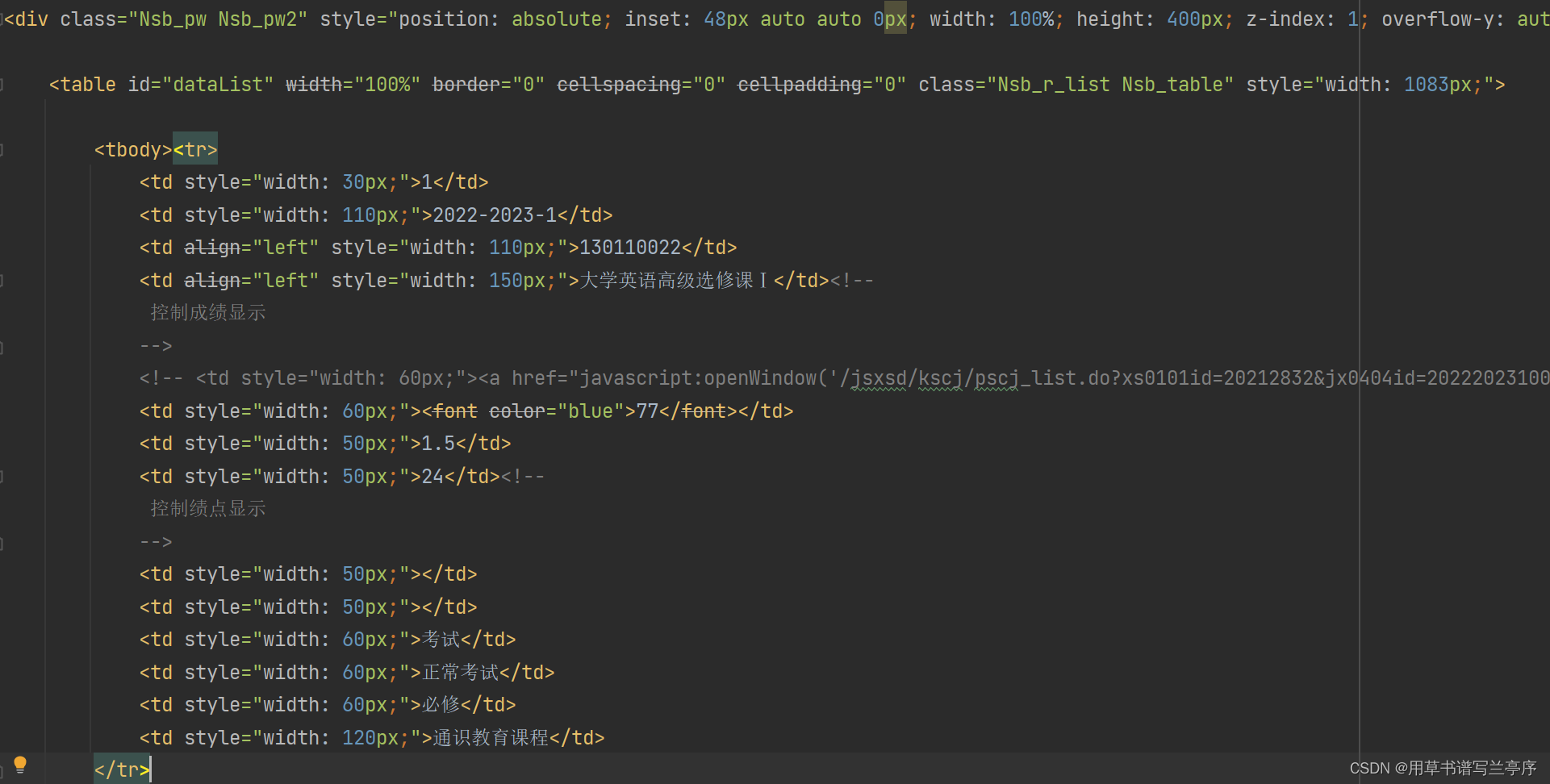
soup = BeautifulSoup(html, "html.parser")
for item in soup.find(class_="Nsb_pw Nsb_pw2").find_all("tr"):
item=str(item)
nature = re.findall(findnature, item)[4] #是必修还是公修
x=re.findall(findscore, item)[0] #得到成绩
y=re.findall(findcredit, item)[0] #得到学分
# print(nature)
if nature == "必修" and x.isdigit()==True: #如果不是必修就步存入列表,还要判断成绩是不是数字,因为有一个成绩是良
score.append(x)
credit.append(y)正则表达式这个要根据你拿到的数据进行分析,然后自己更具需求来写正则表达式
findscore =re.compile(r'<font color="blue">(.*?)</font></a></td>')
findcredit =re.compile(r'<td style="width: 50px;.*">(.*?)</td>')
findnature =re.compile(r'<td style="width: 60px;.*">(.*?)</td>')9.绩点和平均绩点算法
#平均绩点=(学分/总学分*分数)累加=(学分*分数)累加/总学分
while i<len(credit):
credits+=float(credit[i])
gdp+=float(score[i])*float(credit[i])
i+=1
gdp=gdp/credits
# 绩点=(分数-60)÷10+1 分数>=60
Gradepoint=(gdp-60)/10完整代码如下所示:
# -*- coding = utf-8 -*-
# @Time : 2023/1/18 23:06
# @Author : 罗添煦
# @software
from selenium import webdriver
from selenium.webdriver.common.by import By
import re
from bs4 import BeautifulSoup
import time
browser = webdriver.Edge()
#跳转到中南林业科技大学的vpn地址
browser.get('https://vpn.csuft.edu.cn/por/login_psw.csp?rnd=0.3917593474643495#http%3A%2F%2Fvpn.csuft.edu.cn%2F')
#点击安全设置
browser.find_element(By.ID,"details-button").click()
browser.find_element(By.ID,"proceed-link").click()
# #定位到账号密码输入框并且输入账号密码
browser.find_element(By.ID,"svpn_name").send_keys("20212832")
browser.find_element(By.ID,"svpn_password").send_keys("wsndqd857857")
#点击登录登录按钮
browser.find_element(By.ID,"logButton").click()
#睡眠七秒保证可以连上vpn,速度太快了直接跳转的话可能没有挂上vpn
time.sleep(7)
#跳转到学校教务系统首页
browser.get('http://authserver.csuft.edu.cn/authserver/login?service=http%3A%2F%2Fjwgl.csuft.edu.cn%2F')
#输入自己在教务系统的账号密码,并且点击登录
username =input('请输入您的账号')
browser.find_element(By.ID,"username").send_keys(username)
password =input('请输入您的密码')
browser.find_element(By.ID,"password").send_keys(password)
browser.find_element(By.XPATH,"/html/body/div/div[2]/div[2]/div[1]/div[3]/div[1]/form/p[5]/button").click()
term=input("请输入你要查找的学期:格式如2022-2023-1\n")
#跳转到你要搜索的学期成绩
browser.get("http://jwgl.csuft.edu.cn/jsxsd/kscj/cjcx_list?kksj=%s" %term)
time.sleep(5)
#获取学期成绩的html代码
html=browser.page_source
findscore =re.compile(r'<font color="blue">(.*?)</font></a></td>')
findcredit =re.compile(r'<td style="width: 50px;.*">(.*?)</td>')
findnature =re.compile(r'<td style="width: 60px;.*">(.*?)</td>')
soup = BeautifulSoup(html, "html.parser")
score=[]
credit=[]
credits=0
gdp=0
i=0
# print(soup.find(class_="Nsb_pw Nsb_pw2").find_all("tr"))
# print(len(soup.find(class_="Nsb_pw Nsb_pw2").find_all("tr")))
for item in soup.find(class_="Nsb_pw Nsb_pw2").find_all("tr"):
item=str(item)
nature = re.findall(findnature, item)[4]
x=re.findall(findscore, item)[0]
y=re.findall(findcredit, item)[0]
# print(nature)
if nature == "必修" and x.isdigit()==True:
score.append(x)
credit.append(y)
# print(score)
# print(credit)
while i<len(credit):
credits+=float(credit[i])
gdp+=float(score[i])*float(credit[i])
i+=1
# print(gdp)
# print(credits)
gdp=gdp/credits
# 绩点=(分数-60)÷10+1 分数>=60
Gradepoint=(gdp-60)/10+1
print("您本学期的平均绩点为"+str(gdp))
print("您本学期的绩点为"+str(Gradepoint))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!