项目日志使用
?微信公众号转载,关注微信公众号掌握更多技术动态

---------------------------------------------------------------
一、日志框架简介
1.什么是日志
一个完整的项目,日志是必不可少的。程序从开发、测试、维护、运行等环节,都需要向控制台或文件等位置输出大量信息,这些信息的输出,在很多时候是使用System.out.pringln()无法完成的。
日志信息根据记录内容和用途不同分为调试日志、运行日志、异常日志等。
2.日志的作用
- 记录系统和接口的使用情况,比如请求日志
- 记录和分析用户的行为,比如网站访问日志
- 调试程序,和控制台的作用类似,但是控制台中的内容并不会保存到文件中,而日志可以长期保存。
- 问题追踪,辅助排查和定位线上问题
- 通过分析日志还能够优化代码逻辑、提升系统性能、稳定性等。
- 状态监控:通过日志分析,可以监控系统的运行状态。
3.日志框架比较
(1)日志接口(slf4j)?
slf4j是对所有日志框架制定的一种规范、标准、接口,并不是一个框架的具体的实现,因为接口并不能独立使用,需要和具体的日志框架实现配合使用(如log4j、logback)
//提供了避免字符串拼接的语法 LOGGER.debug("Hello?{}",?name);
(2)日志实现(log4j、logback、log4j2)
①log4j是apache实现的一个开源日志组件,现今已不再进行维护
②logback同样是由log4j的作者设计完成的,拥有更好的特性,用来取代log4j的一个日志框架,是slf4j的原生实现
③Log4j2是log4j 1.x和logback的改进版,采用了一些新技术(无锁异步、等等),使得日志的吞吐量、性能比log4j 1.x提高10倍,并解决了一些死锁的bug,而且配置更加简单灵活。
(3)需要日志接口的原因
接口用于定制规范,可以有多个实现,使用时是面向接口的(导入的包都是slf4j的包而不是具体某个日志框架中的包),即直接和接口交互,不直接使用实现,所以可以任意的更换实现而不用更改代码中的日志相关代码。
比如:slf4j定义了一套日志接口,项目中使用的日志框架是logback,开发中调用的所有接口都是slf4j的,不直接使用logback,调用是 自己的工程调用slf4j的接口,slf4j的接口去调用logback的实现,可以看到整个过程应用程序并没有直接使用logback,当项目需要更换更加优秀的日志框架时(如log4j2)只需要引入Log4j2的jar和Log4j2对应的配置文件即可,完全不用更改Java代码中的日志相关的代码logger.info(“xxx”),也不用修改日志相关的类的导入的包(import org.slf4j.Logger;?import org.slf4j.LoggerFactory;)
使用日志接口便于更换为其他日志框架。log4j、logback、log4j2都是一种日志具体实现框架,所以既可以单独使用也可以结合slf4j一起搭配使用)
4.日志记录演变
- 无日志
- 引入日志类库
- 日志分级:将不同级别的日志输出到不同的文件
- 按类隔离:将不同类的日志输出到不同文件
- 日志上报与集中式管理
二、log4j2基础示例
- Log4j 2的异步记录日志在一定程度上提供更好的吞吐量,但是一旦队列已满,appender线程需要等待,这个时候就需要设置等待策略,AsyncAppender是依赖于消费者最序列最后的消费者,会持续等待。至于异步性能图可以看下官方提供的吞吐量比较图,差异很明显。
- 因为AsyncAppender是采用Disruptor,通过环形队列无阻塞队列作为缓冲,多生产者多线程的竞争是通过CAS实现,无锁化实现,可以降低极端大的日志量时候的延迟尖峰,Disruptor?可是号称一个线程里每秒处理600万订单的高性能队列。
1.导入jar包
<dependencies>?? ????<dependency>?? ????????<groupId>org.apache.logging.log4j</groupId>?? ????????<artifactId>log4j-api</artifactId>?? ????????<version>2.5</version>?? ????</dependency>?? ????<dependency>?? ????????<groupId>org.apache.logging.log4j</groupId>?? ????????<artifactId>log4j-core</artifactId>?? ????????<version>2.5</version>?? ????</dependency>?? <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.5</version> </dependency> </dependencies>??
2.创建log4j2.xml日志控制文件
在src同级创建,相当于日志的开关。log4j2默认会在classpath目录下寻找log4j.json、log4j.jsn、log4j2.xml等名称的文件,如果都没有找到,则会按默认配置输出,也就是输出到控制台。
<?xml?version="1.0"?encoding="UTF-8"?>?? <Configuration?status="WARN">?? ????<Appenders>?? ????????<Console?name="Console"?target="SYSTEM_OUT">?? ????????????<PatternLayout?pattern="%d{HH:mm:ss.SSS}?[%t]?%-5level?%logger{36}?-?%msg%n"?/>?? ????????</Console>?? ????</Appenders>?? ????<Loggers>?? ????????<Root?level="error">?? ????????????<AppenderRef?ref="Console"?/>?? ????????</Root>?? ????</Loggers>?? </Configuration>??
3.配置文件节点解析
(1)Configuration根节点
①status属性
这个属性表示log4j2本身的日志信息打印级别。如果把status改为TRACE再执行测试代码,可以看到控制台中打印了一些log4j加载插件、组装logger等调试信息。
?????在log4j2中,?共有8个级别,按照从低到高为:ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF。(默认为INFO)
? ? ? ? ??All:最低等级的,用于打开所有日志记录.
Trace:是追踪,就是程序推进一下.
Debug:指出细粒度信息事件对调试应用程序是非常有帮助的.
Info:消息在粗粒度级别上突出强调应用程序的运行过程.
Warn:输出警告及warn以下级别的日志.
Error:输出错误信息日志.
Fatal:输出每个严重的错误事件将会导致应用程序的退出的日志.
?OFF:最高等级的,用于关闭所有日志记录.
???程序会打印高于或等于所设置级别的日志,设置的日志等级越高,打印出来的日志就越少。
②monitorInterval属性
表示每隔多少秒重新读取配置文件,可以不重启应用的情况下修改配置
(2)Appender节点
Appender可以理解为日志的输出目的地,log4j2支持的输出源有很多,有控制台Console、文件File、RollingRandomAccessFile、MongoDB、Flume 等。
①Console:控制台输出源是将日志打印到控制台上,开发的时候一般都会配置,以便调试
- name:指定Appender的名字.
- target:SYSTEM_OUT 或 SYSTEM_ERR,一般只设置默认:SYSTEM_OUT.
- PatternLayout:输出格式,不设置默认为:%m%n。
详解:https://blog.csdn.net/bugzeroman/article/details/102803857
②File:文件输出源,用于将日志写入到指定的文件,需要配置输入到哪个位置(例如:D:/logs/mylog.log)
- name:指定Appender的名字.
- fileName:指定输出日志的目的文件带全路径的文件名.
- PatternLayout:输出格式,不设置默认为:%m%n.
③RollingRandomAccessFile: 该输出源也是写入到文件,不同的是比File更加强大,可以指定当文件达到一定大小(如20MB)时,另起一个文件继续写入日志,另起一个文件就涉及到新文件的名字命名规则,因此需要配置文件命名规则。这种方式更加实用,因为你不可能一直往一个文件中写,如果一直写,文件过大,打开就会卡死,也不便于查找日志。
- fileName 指定当前日志文件的位置和文件名称
- filePattern 指定当发生Rolling时,文件的转移和重命名规则
- SizeBasedTriggeringPolicy 指定当文件体积大于size指定的值时,触发Rolling
- DefaultRolloverStrategy 指定最多保存的文件个数
- TimeBasedTriggeringPolicy 这个配置需要和filePattern结合使用,注意filePattern中配置的文件重命名规则是${FILE_NAME}-%d{yyyy-MM-dd HH-mm}-%i,最小的时间粒度是mm,即分钟
- TimeBasedTriggeringPolicy指定的size是1,结合起来就是每1分钟生成一个新文件。如果改成%d{yyyy-MM-dd HH},最小粒度为小时,则每一个小时生成一个文件
- NoSql:MongoDb, 输出到MongDb数据库中
- Flume:输出到Apache Flume(Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。)
- Async:异步,需要通过AppenderRef来指定要对哪种输出源进行异步(一般用于配置RollingRandomAccessFile)
④RollingFile节点用来定义超过指定大小自动删除旧的创建新的的Appender.
- name:指定Appender的名字.
- fileName:指定输出日志的目的文件带全路径的文件名.
- PatternLayout:输出格式,不设置默认为:%m%n.
- filePattern:指定新建日志文件的名称格式.
- Policies:指定滚动日志的策略,就是什么时候进行新建日志文件输出日志.
- TimeBasedTriggeringPolicy:Policies子节点,基于时间的滚动策略,interval属性用来指定多久滚动一次,默认是1 hour。modulate=true用来调整时间:比如现在是早上3am,interval是4,那么第一次滚动是在4am,接着是8am,12am...而不是7am.
- SizeBasedTriggeringPolicy:Policies子节点,基于指定文件大小的滚动策略,size属性用来定义每个日志文件的大小.
- DefaultRolloverStrategy:用来指定同一个文件夹下最多有几个日志文件时开始删除最旧的,创建新的(通过max属性)。
PatternLayout
控制台或文件输出源(Console、File、RollingRandomAccessFile)都必须包含一个PatternLayout节点,用于指定输出文件的格式(如 日志输出的时间 文件 方法 行数 等格式),例如 pattern=”%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n”
%d{HH:mm:ss.SSS} 表示输出到毫秒的时间 %t 输出当前线程名称 %-5level 输出日志级别,-5表示左对齐并且固定输出5个字符,如果不足在右边补0 %logger 输出logger名称,因为Root Logger没有名称,所以没有输出 %msg 日志文本 %n 换行 其他常用的占位符有: %F 输出所在的类文件名,如Client.java %L 输出行号 %M 输出所在方法名 %l ?输出语句所在的行数, 包括类名、方法名、文件名、行数
(3)Loggers日志器?
①Root节点用来指定项目的根日志,如果没有单独指定Logger,那么就会默认使用该Root日志输出
- level:日志输出级别,共有8个级别,按照从低到高为:All?< Trace < Debug <?Info?<?Warn?< Error < Fatal <?OFF.
- AppenderRef:Root的子节点,用来指定该日志输出到哪个Appender.
②Logger节点用来单独指定日志的形式,比如要为指定包下的class指定不同的日志级别等。
- level:日志输出级别,共有8个级别,按照从低到高为:All?< Trace < Debug <?Info?<?Warn?< Error < Fatal <?OFF.
- name:用来指定该Logger所适用的类或者类所在的包全路径,继承自Root节点.
- AppenderRef:Logger的子节点,用来指定该日志输出到哪个Appender,如果没有指定,就会默认继承自Root.如果指定了,那么会在指定的这个Appender和Root的Appender中都会输出,此时我们可以设置Logger的additivity="false"只在自定义的Appender中进行输出,不会输出Root
<Configuration?status="WARN"?monitorInterval="300">?? ????<Appenders>?? ????????<Console?name="Console"?target="SYSTEM_OUT">?? ????????????<PatternLayout?pattern="%d{HH:mm:ss.SSS}?[%t]?%-5level?%logger{36}?-?%msg%n"?/>?? ????????</Console>?? ????</Appenders>?? ????<Loggers>?? ????????<Logger?name="mylog"?level="trace"?additivity="false">?? ????????<AppenderRef?ref="Console"?/>?? ????</Logger>?? ????????<Root?level="error">?? ????????????<AppenderRef?ref="Console"?/>?? ????????</Root>?? ????</Loggers>?? </Configuration>??
(4)properties属性?
使用来定义常量,以便在其他配置的时候引用,该配置是可选的,例如定义日志的存放位置?D:/logs
4.设置日志内容
public?static?void?main(String[]?args)?{?? ????Logger?logger?=?LogManager.getLogger("mylog");?? ????logger.trace("trace?level");?? ????logger.debug("debug?level");?? ????logger.info("info?level");?? ????logger.warn("warn?level");?? ????logger.error("error?level");?? ????logger.fatal("fatal?level");?? }??
5.log4j2默认在classpath下查找配置文件,可以修改配置文件的位置(可选操作)
<context-param>?? ????<param-name>log4jConfiguration</param-name>?? ????<param-value>/WEB-INF/conf/log4j2.xml</param-value>?? </context-param>?? ?? <listener>?? ????<listener-class>org.apache.logging.log4j.web.Log4jServletContextListener</listener-class>?? </listener>??
三、项目应用
1.引入slf4j和log4j需要的依赖
<!-- slf4j + log4j2 begin --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.10</version> </dependency> <dependency> <!-- 桥接:告诉Slf4j使用Log4j2 --> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.2</version> </dependency> <dependency> <!-- 桥接:告诉commons logging使用Log4j2 --> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-jcl</artifactId> <version>2.2</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>${log4j.version}</version> </dependency> <!-- log4j end-->
2.配置log4j2.xml
3.Java设置日志内容(此时使用的是Root)
getLogger(class)的参数用途:追踪产生此日志的类.
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class Log4j2Test { // Logger和LoggerFactory导入的是org.slf4j包 private final static Logger logger = LoggerFactory.getLogger(Log4j2Test.class); public static void main(String[] args) { long beginTime = System.currentTimeMillis(); for(int i = 0; i < 100000; i++) { logger.trace("trace level"); logger.debug("debug level"); logger.info("info level"); logger.warn("warn level"); logger.error("error level"); } try { Thread.sleep(1000 * 61); } catch (InterruptedException e) {} logger.info("请求处理结束,耗时:{}毫秒", (System.currentTimeMillis() - beginTime)); //第一种用法 logger.info("请求处理结束,耗时:" + (System.currentTimeMillis() - beginTime) + "毫秒"); //第二种用法 } }
4.运行结果?
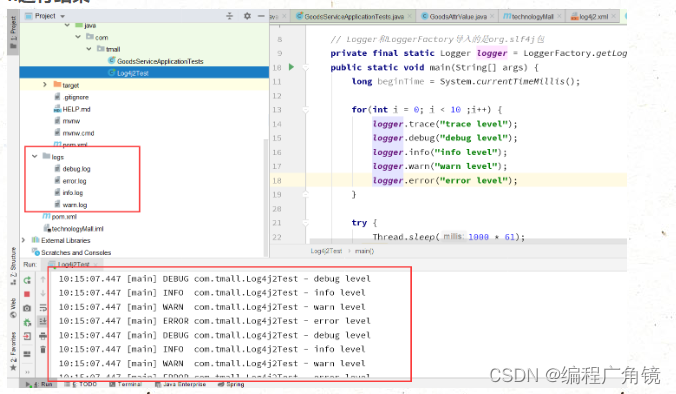
四、日志使用规范
- 「编程语言提示异常」:如今各类主流的编程语言都包括异常机制,业务相关的流行框架有完整的异常模块。这类捕获的异常是系统告知开发人员需要加以关注的,是质量非常高的报错。应当适当记录日志,根据实际结合业务的情况使用warn或者error级别。
- 「业务流程预期不符」:除开平台以及编程语言异常之外,项目代码中结果与期望不符时也是日志场景之一,简单来说所有流程分支都可以加入考虑。取决于开发人员判断能否容忍情形发生。常见的合适场景包括外部参数不正确,数据处理问题导致返回码不在合理范围内等等。
- 「系统核心角色,组件关键动作」:系统中核心角色触发的业务动作是需要多加关注的,是衡量系统正常运行的重要指标,建议记录INFO级别日志,比如电商系统用户从登录到下单的整个流程;微服务各服务节点交互;核心数据表增删改;核心组件运行等等,如果日志频度高或者打印量特别大,可以提炼关键点INFO记录,其余酌情考虑DEBUG级别。
- 「系统初始化」:系统或者服务的启动参数。核心模块或者组件初始化过程中往往依赖一些关键配置,根据参数不同会提供不一样的服务。务必在这里记录INFO日志,打印出参数以及启动完成态服务表述。
1.不同级别日志使用
(1)ERROR
①使用场景
影响到程序正常运行、当前请求正常运行的异常情况:
- 打开配置文件失败
- 所有第三方对接的异常(包括第三方返回错误码)
- 所有影响功能使用的异常,包括:SQLException和除了业务异常之外的所有异常(RuntimeException和Exception)
不应该出现的情况:
- 比如要使用Azure传图片,但是Azure未响应
②注意事项
如果有Throwable信息,需要记录完成的堆栈信息:
log.error("获取用户[{}]的用户信息时出错",userName,e);
如果进行了抛出异常操作,请不要记录error日志,由最终处理方进行处理
ERROR级别的日志意味着系统中发生了非常严重的问题,必须有人马上处理,比如数据库不可用,系统的关键业务流程走不下去等等。所以只有在影响到业务功能的时候才应该输出error日志,否则这个警报也就失去了原始的意义
log.error(“[接口名或操作名]?[Some?Error?Msg]?happens.?[Probably?Because].?[Probably?need?to?do]?[params]?.”); log.error(“[接口名或操作名]?[Some?Error?Msg]?happens.?[Probably?Because].?[please?contact?xxx@xxx]?[params]?.”);
(2)WARN
不应该出现但是不影响程序、当前请求正常运行的异常情况:用于需要关注的问题
- 有容错机制的时候出现的错误情况
- 找不到配置文件,但是系统能自动创建配置文件
- 即将接近临界值的时候,例如:缓存池占用达到警告线
- 业务异常的记录,比如:当接口抛出业务异常时,应该记录此异常
(3)INFO
①使用场景
- 输出系统运行信息
- Service方法中对于系统/业务状态的变更
- 重要流程信息,主要逻辑中的分步骤、分支语句(将注释中的步骤通过日志输出)
- 初始化系统配置
- 外部接口部分
- 客户端请求参数(REST/WS)
- 调用第三方时的调用参数和调用结果
②注意事项
- 并不是所有的service都进行出入口打点记录,单一、简单service是没有意义的(job除外,job需要记录开始和结束,)。
- 对于复杂的业务逻辑,需要进行日志打点,以及埋点记录,比如电商系统中的下订单逻辑,以及OrderAction操作(业务状态变更)。
- 对于整个系统的提供出的接口(REST/WS),使用info记录入参
- 如果所有的service为SOA架构,那么可以看成是一个外部接口提供方,那么必须记录入参。
- 调用其他第三方服务时,所有的出参和入参是必须要记录的(因为你很难追溯第三方模块发生的问题)
(4)DEBUG
- 用于开发调试,可以填写所有的想知道的相关信息(但不代表可以随便写,debug信息要有意义,最好有相关参数)
- 生产环境需要关闭DEBUG信息
- 如果在生产情况下需要开启DEBUG,需要使用开关进行管理,不能一直开启。
(5)如何选择WARN/ERROR

①常见的WARN级别异常
- 用户输入参数错误
- 非核心组件初始化失败
- 后端任务处理最终失败(如果有重试且重试成功,就不需要WARN)
- 数据插入幂等
②常见的ERROR级别异常
- 程序启动失败
- 核心组件初始化失败
- 连不上数据库
- 核心业务访问依赖的外部系统持续失败
- OOM
③不要滥用ERROR级别日志。
一般来说在配置了告警的系统中,WARN级别一般不会告警,ERROR级别则会设置监控告警甚至电话报警,ERROR级别日志的出现意味着系统中发生了非常严重的问题,必须有人立即处理。
错误的使用ERROR级别日志,不区分问题的重要程度,只要是问题就采用ERROR级别日志,这是极其不负责任的表现,因为大部分系统中的告警配置都是根据单位时间内ERROR级别日志出现的数量来定的,随意打ERROR日志将会造成极大的告警噪音,造成重要问题遗漏。
(6)日志级别的判断
日志框架提供的参数化日志记录不能完全取代日志级别的判断,如果日志量很大,获取日志参数代价很大,就要进行相应的日志级别的判断,避免不记录日志也要花费时间获取日志参数的问题
logger . debug( " Processing trade with id : " + id + " and symbol : " + symbol);如果日志级别是 warn ,上述日志不会打印,但是会执行字符串拼接操作,如果 symbol 是对象,会执行 toString() 方法,浪费了系统资源,执行了上述操作,最终日志却没有打印。
正例: ( 条件 )
if (logger.isDebugEnabled()) { logger.debug("Processing trade with id: " + id + " and symbol: " + symbol); }
正例: ( 占位符 )
logger.debug("Processing trade with id: [{}] and symbol : [{}] ", id, symbol);
2.日志记录原则
- 隔离性:日志输出不能影响系统正常运行;
- 安全性:日志打印本身不能存在逻辑异常或漏洞,导致产生安全问题;
- 数据安全:不允许输出机密、敏感信息,如用户联系方式、身份证号码、token等;
- 可监控分析:日志可以提供给监控进行监控,分析系统进行分析;
- 可定位排查:日志信息输出需有意义,需具有可读性,可供日常开发同学排查线上问题。
3.日志格式
(1)摘要日志
摘要日志是格式化的标准日志文件,可用于监控系统进行监控配置和离线日志分析的日志,通常系统对外提供的服务以及集成的第三方服务都需要打印对应的服务摘要日志,摘要日志格式一般需包含以下几类关键信息:
- 调用时间
- 日志链路id(traceId、rpcId)
- 线程名
- 接口名
- 方法名
- 调用耗时
- 调用是否成功(Y/N)
- 错误码
- 系统上下文信息(调用系统名、调用系统ip、调用时间戳、是否压测(Y/N))
2022-12-12 06:05:05,129 [0b26053315407142451016402xxxxx 0.3 - /// - ] INFO [SofaBizProcessor-4-thread-333] - [(interfaceName,methodName,1ms,Y,SUCCESS)(appName,ip地址,时间戳,Y)
(2)详细日志
详细日志是用于补充摘要日志中的一些业务参数的日志文件,用于问题排查。详细日志一般包含以下几类信息:
- 调用时间
- 日志链路id(traceId、rpcId)
- 线程名
- 接口名
- 方法名
- 调用耗时
- 调用是否成功(Y/N)
- 系统上下文信息(调用系统名、调用系统ip、调用时间戳、是否压测(Y/N))
- 请求入参
- 请求出参
2022-12-12 06:05:05,129 [0b26053315407142451016402xxxxx 0.3 - /// - ] INFO [SofaBizProcessor-4-thread-333] - [(interfaceName,methodName,1ms,Y,SUCCESS)(appName,ip地址,时间戳,Y)(参数1,参数2)(xxxx)
(3)业务执行日志
业务执行日志就是系统执行过程中输出的日志,一般没有特定格式,是开发人员用于跟踪代码执行逻辑而打印的日志,个人看来在摘要日志、详细日志、错误日志齐全的情况下,需要打印系统执行日志的地方比较少。如果一定要打印业务执行日志,需要关注以下几个点:
- 这个日志是否一定要打印?如果不打印是否会影响后续问题排查,如果打印这个日志后续输出频率是否会太高,造成线上日志打印过多。
- 日志格式是否辨识度高?如果后续对该条日志进行监控或清洗,是否存在无法与其他日志区分或者每次打印的日志格式都不一致的问题?
- 输出当前执行的关键步骤和描述,明确的表述出打印该条日志的作用,方便后续维护人员阅读。
- 日志中需包含明确的打印意义,当前执行步骤的关键参数。
建议格式:[日志场景][日志含义]带业务参数的具体信息
[scene_bind_feature][feature_exists]功能已经存在[tagSource='MIF_TAG',tagValue='123']
4.其它注意事项
(1)合理打印日志
- 不要过度依赖日志,什么都记,日志应当简洁明晰,具有实际价值。
- 在保证可理解的同时适当减少日志的长度,比如把 this is an apple 简化为 apple。
- 统一日志的格式,便于后续处理分析,通常在日志框架配置即可。
- 不要把日志当成存储数据的工具!注意日志信息中不能出现敏感信息,也不要对外公开
(2)日志格式
使用参数化形式{}占位,[]进行参数隔离
log.debug("Save order with order no:[{}], and order amount:[{}]"); log.debug("Save order with order no:[{}], and order amount:[{}]");
(3)日志文件名
当前正在写入的日志文件名:<应用名>[-<功能名>].log 已经滚入历史的日志文件名:<应用名>[-<功能名>].log.<yyyy-MM-dd>
(4)不允许记录日志后又抛出异常
如捕获异常后又抛出了自定义业务异常,此时无需记录错误日志,由最终捕获方进行异常处理。不能又抛出异常,又打印错误日志,不然会造成重复输出日志。
void?foo()?throws?LogException{ ????try{ ????????//do?somehing? ????}catch(Exception?e){ ????????log.error("Bad?Things",e);//正确 ????????throw?new?LogException("Bad?Things",e); ????} }
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!