Attention-Challenging Multiple Instance Learning for Whole Slide Image(ACMIL)
Attention-Challenging Multiple Instance Learning for Whole Slide Image(ACMIL)
问题:
- predictive instances 与 instances有什么区别?
0. Abstract
-
针对领域:MIL的过拟合
-
现有问题:当前的MIL方法只关注预测实例的子集,阻碍了有效的模型泛化
-
ACMIL:迫使注意力机制捕捉更具挑战性的预测实例。
-
算法构成:
-
多分支注意力(MBA)来捕获更丰富的预测实例
-
随机TopK实例掩蔽(STKIM)来抑制简单的预测实例。
-
-
实验:三个WSI数据集的评估优于最先进的方法。
1. Introduction
-
常见的WSI数据集内在特征:
-
数据规模有限——通常由数量相对较少的幻灯片组成,通常为数百张
-
超高分辨率
-
严重的类不平衡——阳性病例的比例相对较低
-
-
bias——误导机器学习模型根据虚假特征而非潜在的生物特征进行分类:
-
组织制备
-
染色方案 IBMIL
-
数字扫描方法变化
-
-
ABMIL显示出严重的过拟合,因为随着训练过程的进行,损失急剧增加,验证指标显著降低。
-
热图可视化是一种有价值的工具,通常用于增强模型的可解释性。事实上,热图在将实例特征聚合为袋特征方面也发挥着关键作用,这直接影响最终预测。
-
现有的研究主要集中在热图的可解释性方面,很少探讨它们与过拟合问题的联系。
-
本文工作:
-
研究了利用热图的过度拟合挑战
-
热图显示,现有的注意力机制(ABMIL)主要集中在预测实例的子集上,而忽略其余的预测实例
-

-
仅根据简单预测特征训练的模型可能难以推广到分布外的数据。
-
热图中注意力值的过度集中与过度拟合密切相关。
-
算法提出:
-
问题一:预测实例之间存在各种模式,现有的注意力机制只能捕捉其中的一部分。
-
解决方法:多分支注意力(MBA)方法
-
MBA利用多个注意力分支,每个分支负责捕捉具有特定模式的实例,确保更丰富的预测实例有助于最终预测。
-
-
问题二:在现有的注意力机制中,少数示例会占据大多数注意力。
-
解决方法:随机Top-K实例掩码(STKIM)
-
STKIM在每次迭代时随机屏蔽具有最高注意力值的实例的一部分,然后将其注意力值分配给其余实例。(有点类似于MHIM-MIL)
-
-
2. Related Work
我们的工作可能与这些工作有着相似的动机。然而,我们的解决方案是基于热图的观察和分析,而现有的方法更多地依赖于直觉。
我们的工作是独立完成的,并与MHIM-MIL[45]同时进行。
重要的是要认识到热图在将实例特征聚合为袋级特征方面发挥着核心作用,这会显著影响模型的泛化能力。本文率先使用热图作为分析过拟合挑战的工具,从而脱颖而出。
3. Method
Baseline: ABMIL
3.2. Mutiple Branch Attention(MBA)
为了捕捉更多的预测性实例,我们设计了由多个注意力分支组成的MBA。每个分支负责捕获具有特定模式的实例,确保更多的预测模式有助于最终预测。


为了保证模式之间的预测语义和语义多样性,分别提出了语义正则化和多样性正则化:
-
语义正则化:
- 在每个模式嵌入后面挂上MLP层,并配备交叉熵损失函数来实现语义正则化:

Y ^ i = g i ( z i ) \hat Y_i=g_i(z_i) Y^i?=gi?(zi?)是第i个模式的预测结果。
-
多样性正则化:
-
仅配备交叉熵损失可能会学习相似的模式,并且无法挖掘出更多的预测信息。
-
多样性损失:
-
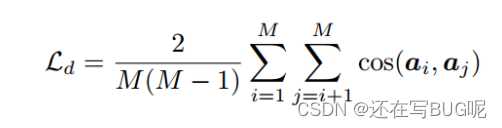
a i = { a i 1 , . . . , a i N } a_i=\{a_{i1},...,a_{iN}\} ai?={ai1?,...,aiN?} 是第i个模式的所有注意力值。(被定义为热图(heatmap))
通过使热图多样化,每个分支的嵌入可以集中于不同的预测模式。(按理说最佳预测模式应该只有一种???)
- 为了聚合捕获的模式以进行预测,使用热图的平均值作为整个袋子的热图:
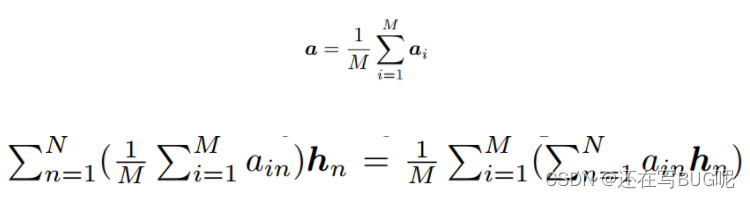
均值注意力池化==注意力池化的均值
- 包分类器损失误差——交叉熵损失

- 总损失:

Discussion
-
当M为1时,MBA本质上等于ABMIL的特征聚合过程,它只能识别一个单一的模式。
-
将MBA视为用于捕获更多样化预测模式的ABMIL的扩展
-
我们强调在我们的MBA和最近的工作DTFD-MIL中使用平行注意力模块的不同目标。DTFD-MIL的目标是通过将袋随机分成几个子袋来增强袋,并使用并行的注意力模块来捕获每个子袋中的判别实例。对于MBA,平行注意力模块用于从整个包中捕获不同的预测模式。
3.3. Stochastic Top-K Instance Masking(STKIM)
Motivation:
- 我们发现在ABMIL中,少数实例可能占据大部分注意力。(按照注意力机制的解释性,这种情况不是应该的吗?)

掩盖机制:

-
主要目标:掩盖一些最具预测性的实例,将更多的注意力转移到从属实例上
-
直接解决方案:屏蔽top-K实例
-
挑战:
-
可能导致丢失与关键实例相关的信息,而这些信息对辨别性至关重要
-
可能导致丢弃这些关键实例之前和之后的特征表示之间的统计不匹配
-
-
方法启发:神经网络中常用的dropout技术
-
方案:随机掩蔽一些示例
-
具体过程:
-
将所有注意力值从高到低排序
-
将top-K个实例的关注值随机设置为0,概率为p。
-

其中p和K是两个控制掩蔽强度的超参数。
-
更新注意力,保证和为1:
a n → 1 ∑ n = 1 N a n a n a_n\to{1\over \sum_{n=1}^N a_n}a_n an?→∑n=1N?an?1?an?
Discussion
-
STKIM和MHIM-MIL之间存在显著的技术差异
-
区别一:
-
MHIM-MIL采用两阶段训练过程,使用第一阶段获得的最佳检查点初始化第二阶段训练的模型。
-
STKIM是一个单阶段框架,不需要预先训练的检查点,从而提供更好的可伸缩性。
-
-
区别二:
-
MHIM-MIL在动量教师模型上使用实例掩蔽,使用掩蔽的实例来训练学生模型。这涉及计算注意力值和产生袋预测的两种前向传播。
-
STKIM利用单一模型,只需要一次前向传播,因此与MHIM-MIL相比,执行速度更快。
-
-
区别三:
-
MHIMMIL采用了三种掩蔽策略,并引入了五个掩蔽超参数,这可能是一个复杂且耗时的试错过程,以达到最佳性能。
-
STKIM主要涉及两个超参数p和K。
-
消融研究表明,设置p = 0.6和K = 10在所有数据集上都能实现近乎最佳的性能,显著减少了与试错调优相关的工作量和时间。
-
STKIM具有更好的可伸缩性、更快的执行速度和更低的试错成本。
-
4.Experiments
Datasets:
-
Camelyon16(public)训—验:9 : 1
-
BRACS(public)不用重新划分,官方已划分为395个训练集,65个验证集和87个测试集。
-
LBC(液体细胞学)(private):
-
收集了1989例wsi,包括4类,即阴性、ASC-US、LSIL和ASC-H/HSIL。
-
随机分成训练集、验证集和测试集,比例为6 : 2 : 2。
-
WSI 3级分类的挑战:良性肿瘤、非典型肿瘤和恶性肿瘤。
Evaluation Metrics
-
由于三个数据集都是类不平衡的
-
macro-AUC
-
macro-F1
每个主要实验进行了5次随机参数初始化,并报告了平均分类性能和标准差。
Baselines
-
Max-pooling
-
Mean-pooling
-
ABMIL
-
DSMIL
-
TransMIL
-
CLAM-SB
-
DTFD-MIL
-
mhimm -MIL
-
IBMIL
原始特征提取:
-
在ImageNet数据集上预训练的ResNet-18
-
在36,666个wsi上使用DINO预训练的ViT-S/16
performance

Heatmap Visualization

对于肿瘤切片,ABMIL倾向于将其注意力集中在肿瘤区域的一小部分,而可能忽略其他重要区域。相比之下,ACMIL将注意力分配到更广泛的肿瘤区域,从而更好地与专家注释对齐。
MBA可以捕捉各种预测模式
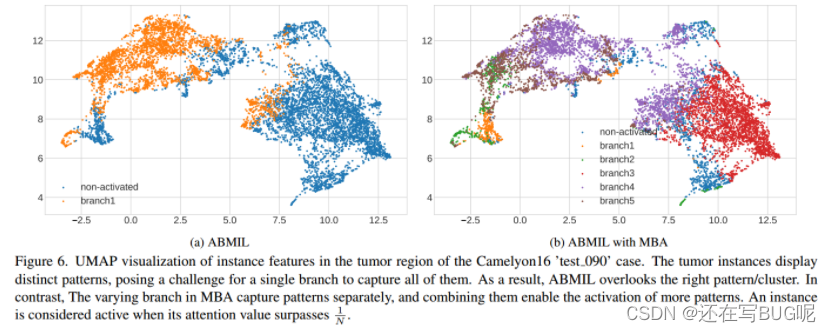
STKIM可以抑制过度集中的注意力值

ACMIL可以学习到更多鉴别包的特征

Do we need STKIM at the test phase? Answer is No.

Do we need diversity loss in MBA? Answer is Yes.

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!