Python网络爬虫的基础理解-对应的自我理解误区
##通过一个中国大学大学排名爬虫的示例进行基础性理解
以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:(1)按照排名先后顺序输出不同年份的前10位大学信息,并要求对输出结果的排版进行优化;访问的网址:https://www.shanghairanking.cn/rankings/bcur/2021
##网络爬虫定义
Python语言的简洁性和脚本特点非常适合链接和网页处理。
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。 源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。 前面讲了请求和响应的概念,向网站的服务器发送一个请求,返回的响应体便是网页源代码。
##基本的操作步骤
A:通过网络链接获取网页的内容
B:对获得到的网页内容进行处理
##所涉及到的库
##最主流的两个函数库:requests和beautifulsoup4
##requests库的使用
该库是一个简洁且简单的处理HTTP请求的第三方库,最大优点是程序编写过程更接近正常URL的访问过程。




##beautifulsoup4库的使用
使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,提取有用的信息。


##Robots协议
Robots 排除协议(Robots Exclusion Protocol) 也被称为爬虫协议,它是网站管理者表达是否希望爬虫自动获取网络信息意愿的方法。管理者可以在网站根目录放置一个 robots.txt文件,并在文件中列出哪些链接不允许爬虫爬取。一般搜索引擎的爬虫会首先捕获这个文件,并根据文件要求爬取网站内容。Robots排除协议重点约定不希望爬虫获取的内容,如果没有该文件则表示网站内容可以被爬虫获得,然而,Robots协议不是命令和强制手段,只是国际互联网的一种通用道德规范。绝大部分成熟的搜索引擎爬虫都会遵循这个协议,建议个人也能按照互联网规范要求合理使用爬虫技术。
(一般来说,不允许访问的网址,相应的网址会进行对应的加密操作。)
##代码示例
"""网络爬虫代码示例"""
import requests
from bs4 import BeautifulSoup
import bs4
#用来获取网页html
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#将对应的网页用python中对应的数据结构进行存储
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")#BeautifulSoup的一个对象
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):#bs4.element.Tag用来访问html指定的元素标签
a = tr('a')
tds = tr('td')
ulist.append([tds[0].text.strip(), a[0].text.strip(), tds[4].text.strip()])#strip()函数用来去除对应的字符
#print(ulist)
#及逆行格式设置用来设置美观的打印格式
def printUnivList(ulist, num):
tplt = "{0:^5}\t{1:{3}^15}\t{2:^5}"
print(tplt.format("排名", "学校名称", "学校总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
print("suc" + str(num))
"""由于大学名称的被a标签包含,所以我们可以定义一个列表存放a标签中的内容(与td标签进行区分开来)
为了视觉方面更加美观,可采用中文字符的空格填充chr(12288),目的是为了对齐"""
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 10)
main()##代码的运行结果:
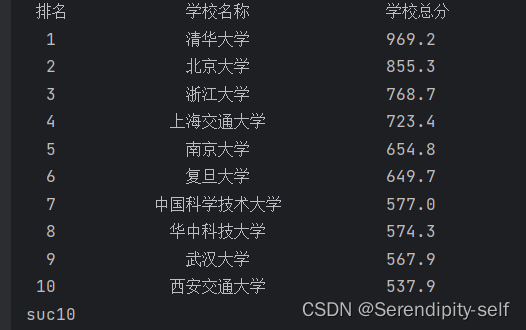
访问网址的源码示例:
##网络爬虫的一个自我小小误区
由于部分的网页的访问收到服务器的拒绝,因此通过自己制作网页来进行对应的访问,但是在这里忽略了一个特别重要的问题,自己所编写的网页并没有受到对应的服务器链接,只是一个单纯的html文件,因此我们的处理方法改成了访问html文件,然后利用request库beautifulsoup4库进行处理。
(真正的网址需要受到服务器的请求的处理才可以进行解析)
##test.html源文件代码
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<table border="1" >
<caption>大学排名</caption>
<tr>
<td>排名</td>
<td>学校名称</td>
<td>省市</td>
<td>总分</td>
<td>培养规模</td>
</tr>
<tr>
<td>1</td>
<td>清华大学</td>
<td>北京市</td>
<td>95.9</td>
<td>37342</td>
</tr>
<tr>
<td>2</td>
<td>北京大学</td>
<td>北京市</td>
<td>82.6</td>
<td>36317</td>
</tr>
<tr>
<td>3</td>
<td>浙江大学</td>
<td>浙江省</td>
<td>80</td>
<td>41188</td>
</tr>
<tr>
<td>4</td>
<td>上海交通大学</td>
<td>上海市</td>
<td>78.7</td>
<td>40417</td>
</tr>
<tr>
<td>5</td>
<td>复旦大学</td>
<td>上海市</td>
<td>70.9</td>
<td>25519</td>
</tr>
<tr>
<td>6</td>
<td>南京大学</td>
<td>江苏省</td>
<td>66.1</td>
<td>20072</td>
</tr>
<tr>
<td>7</td>
<td>中国科学技术大学</td>
<td>安徽省</td>
<td>65.5</td>
<td>18507</td>
</tr>
<tr>
<td>8</td>
<td>哈尔冰工业大学</td>
<td>黑龙江省</td>
<td>63.5</td>
<td>25249</td>
</tr>
<tr>
<td>9</td>
<td>华中科技大学</td>
<td>湖北省</td>
<td>62.9</td>
<td>23503</td>
</tr>
<tr>
<td>10</td>
<td>中山大学</td>
<td>广东省</td>
<td>62.1</td>
<td>23837</td>
</tr>
</table>
</body>
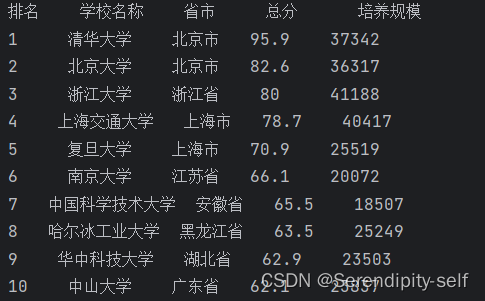
</html>##效果显示图

##网页中显示的源码

##以文件形式处理的代码示例
"""网络爬虫"""
import requests
from bs4 import BeautifulSoup
alluniv = []
def fillluniv(soup):
data = soup.find_all("tr")
for tr in data:
ltd = tr.find_all("td")
if len(ltd) == 0 :
continue
oneuniv = []
for td in ltd :
oneuniv.append(td.string)
alluniv.append(oneuniv)
# print(alluniv)
def printUniv(num):
print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","培养规模"))
for i in range(1,num+1):
print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(alluniv[i][0],alluniv[i][1],alluniv[i][2],alluniv[i][3],alluniv[i][4]))
with open("test.html",'r',encoding="utf-8") as file:
content = file.read()
soup = BeautifulSoup(content,"html.parser")
fillluniv(soup)
printUniv(10)##代码的运行结果
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!