RocketMQ系统性学习-RocketMQ高级特性之消息存储的高效与刷盘策略、Broker 快速读取消息机制
🌈🌈🌈🌈🌈🌈🌈🌈
【11来了】文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
消息存储的高效与刷盘策略
RocketMQ 是通过文件进行存储消息的,那 RocketMQ 是如何保证存储的高效性的呢?
-
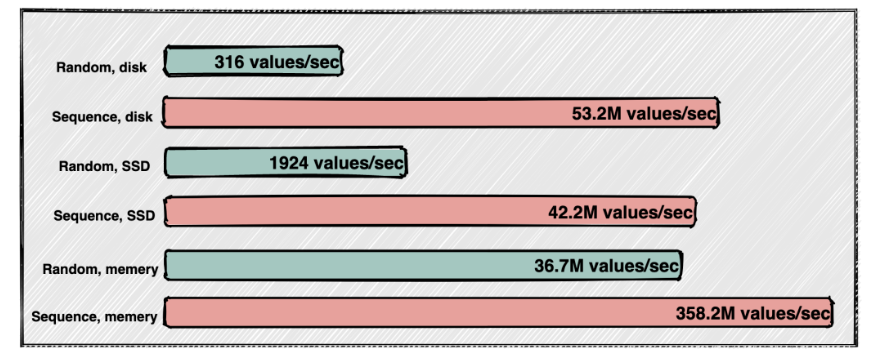
首先是通过对磁盘进行
顺序写可以保证高性能的文件存储:- 随机写速度 10KB/s
- 顺序写速度 600MB/s
(图片来源于网络)
-
文件拷贝利用了
零拷贝以及内存映射技术(MMP)通过使用零拷贝减少数据拷贝次数
利用内存映射技术(MMP)可以像读写磁盘一样读写内存,可以获得很大的 IO 提升,但是写道 MMP 中的数据并没有被真正写到磁盘中,操作系统会在程序主动调用 flush 的时候才把数据真正的写入到磁盘
-
刷盘策略:分为同步刷盘和异步刷盘同步刷盘会造成阻塞,需要等待刷盘完成,降低吞吐量
异步刷盘不会阻塞,提升吞吐量,但是会丢失部分数据
Broker 快速读取消息机制
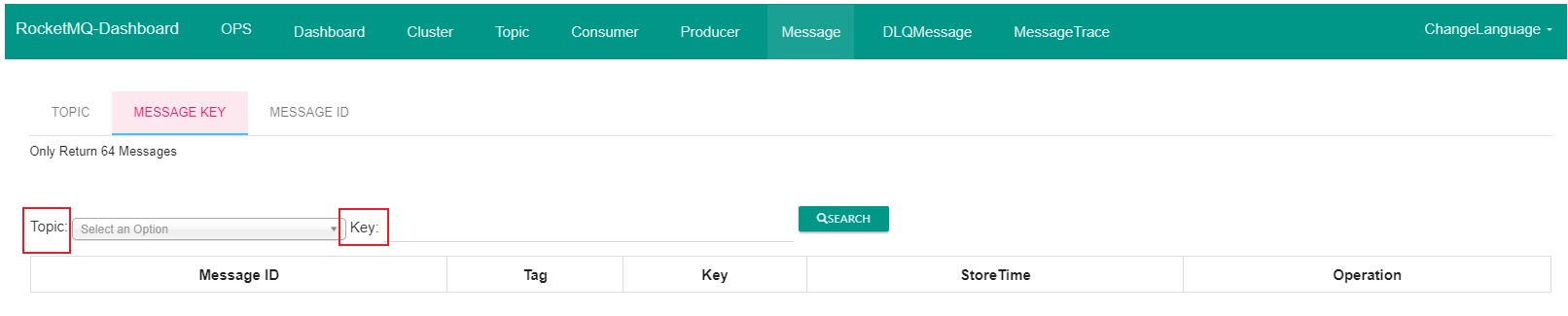
首先还是通过 DashBoard 项目的页面进行查看,发现检索消息有两种方式:
-
Topic + Key
-
Topic + MessageId

那么这两种检索的方式其实就是通过上边我们讲的 Broker 中文件的布局
不知道大家还记不记得 IndexFile # putKey() 这个方法,就是将一个 Key 放到 IndexFile 中作为索引,那么这里我们通过生产者发送一条消息,其实是会在 Broker 中调用两次 putKey() 这个方法,只不过两个 Key 是不同的,分别是: Topic + Key、 Topic + MessageId,这样当然就可以通过这两种方式来检索消息了!
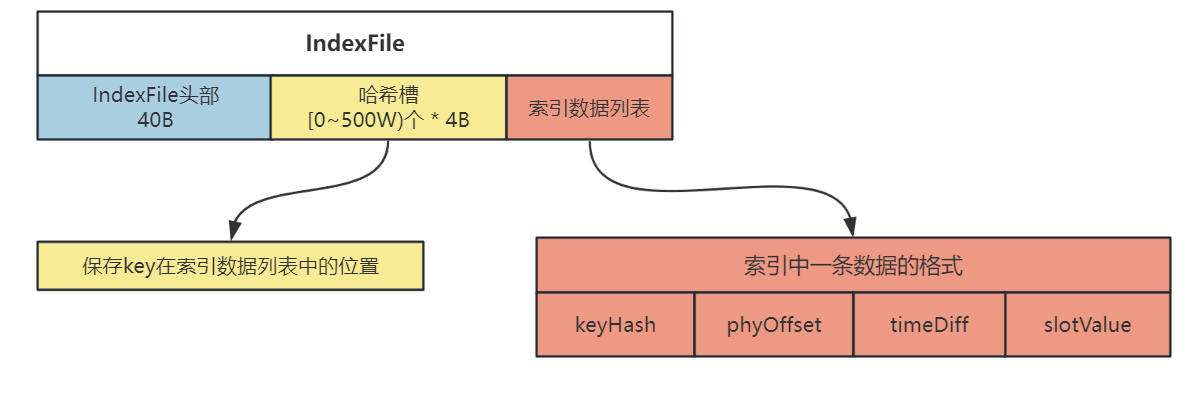
而 IndexFile 既然存储了这两个 Key 所对应消息的索引,也就是在 Commitlog 中的物理偏移量,这个类就一定还提供了根据 Key 查询消息在 Commitlog 中物理偏移量的方法,也就是 IndexFile # selectPhyOffset,在这个方法中,会通过传入的 Key 在 IndexFile 中查询到对应的索引,从索引中取出对应的物理偏移量 phyOffset,流程如下:
- 根据 Key 拿到哈希值,并且对哈希槽数量取模,得到这个 Key 在哈希槽中的相对位置
- 去哈希槽中取到这个 Key 在索引数据列表中的位置,在索引数据列表中拿到这个 Key 的索引,就可以取出这个索引的在 Commitlog 中的物理偏移量
phyOffset
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!