面向多智能体博弈对抗的对手建模框架
作者:罗俊仁? 张万鹏? 袁唯淋? 胡振震? 陈少飞? 陈璟
“人工智能技术与咨询”? ?发布
摘 要
对手建模作为多智能体博弈对抗的关键技术,是一种典型的智能体认知行为建模方法。介绍了多智能体博弈对抗几类典型模型、非平稳问题和元博弈相关理论;梳理总结对手建模方法,归纳了对手建模前沿理论,并对其应用前景及面对的挑战进行分析。基于元博弈理论,构建了一个包括对手策略识别与生成、对手策略空间重构和对手利用共三个模块的通用对手建模框架。期望为多智能体博弈对抗对手建模方面的理论与方法研究提供有价值的参考。
关键词
多智能体;对手建模;认知行为建模;元博弈
引? 言
人工智能技术的发展经历了计算智能、感知智能阶段,云计算、大数据、物联网等技术的发展正助力认知智能飞跃发展。其中认知智能面向的理解、推理、思考和决策等主要任务,主要表现为擅长自主态势理解、理性做出深度慎思决策,是强人工智能(strong AI)的必备能力,此类瞄准人类智能水平的技术应用前景广阔,必将影响深远。机器博弈是人工智能领域的“果蝇” [1],面向机器博弈的智能方法发展是人工智能由计算智能、感知智能的研究迈向认知智能的必经之路。
多智能博弈对抗环境是一类典型的竞合(竞争-合作)环境,从博弈理论的视角分析,对手建模主要是指对除智能体自身以外其它智能体建模,其中其他智能体可能是合作队友(合作博弈,cooperative game)、敌对敌人(对抗博弈,adversarial game)和自身的历史版本(元博弈,meta game)。本文关注的对手建模问题,属于智能体认知行为建模的子课题。研究面向多智能体博弈对抗的对手建模方法,对于提高智能体基于观察判断、态势感知推理,做好规划决策、行动控制具有重要作用。
本文首先介绍多智能体博弈对抗基础理论;其次对对手建模的主要方法进行分类综述,研究分析各类方法的区别联系,从多个角度介绍当前对手建模前沿方法,分析了应用前景及面临的挑战;最后在元博弈理论的指导下,构建了一个拥有“对手策略识别与生成、对手策略空间重构、对手策略利用”共3个模块的通用对手建模框架。
1? 多智能体博弈对抗
近年来,多智能体博弈对抗的相关研究取得了很大的突破。如图1所示,以AlphaGo/AlphaZero (围棋AI) [2]、Pluribus (德州扑克AI) [3]、AlphaStar (星际争霸AI) [4]、Suphx (麻将AI) [5]等为代表的人工智能AI在人机对抗比赛中已经战胜了人类顶级职业选手,这类对抗人类的智能博弈对抗学习为认知智能的研究提供了新的研究范式。

图1智能博弈对抗研究进展
多智能体博弈对抗的研究就是使用新的人工智能范式设计人工智能AI并通过人机对抗、机机对抗和人机协同对抗等方式研究计算机博弈领域的相关问题,其本质就是通过博弈学习方法探索人类认知决策智能习得过程,研究人工智能AI升级进化并战胜人类智能的内在生成机理和技术途经,这是类人智能研究走上强人工智能的必由之路。
1.1???多智能体模型
在人工智能领域,马尔可夫决策过程(markov decision process, MDP)常用于单智能体决策过程建模。近些年,一些新的马尔可夫决策模型相继被提出,为获得多样性策略和应对稀疏反馈,正则化马尔可夫决策过程将策略的相关信息或熵作为约束条件,构建有信息或熵正则化项的马尔可夫决策过程 [6]。相应的,一些新型带熵正则化项的强化学习方法 [7](如时序空间的正则化强化学习,策略空间的最大熵正则化强化学习与Taillis熵正则化强化学习)和一些新的正则化马尔可夫博弈模型 [8](如最大熵正则化马尔可夫博弈、迁移熵正则化马尔可夫博弈)也相继被提出。面向多智能体决策的模型主要有多智能体MDPs(multi-agent MDPs, MMDPs)及分布式MDPs(decentralized MDPs, Dec-MDPs) [9]。其中在MMDPs模型中,主要采用集中式的策略,不区分单个智能体的私有或全局信息,统一处理再分配单个智能体去执行。而在Dec-MDPs模型中,每个智能体有独立的环境与状态观测,可根据局部信息做出决策。重点针对智能体间信息交互的模型主要有交互式POMDP(interactive POMDP, I-POMDP) [10],其主要采用递归推理(recursive reasoning)的对手建模方法对其他智能体的行为进行显式建模,推断其它智能体的行为信息,然后采取应对行为。以上介绍的主要是基于决策理论的智能体学习模型及相关方法。如图2所示,这些模型都属于部分可观随机博弈(partial observation stochastic game, POSG)模型的范畴。

图2部分可观随机博弈相关模型
当前,直接基于博弈理论的多智能体博弈模型得到了广泛关注。如图3所示,其中有两类典型的多智能体博弈模型:随机博弈(stochastic game),也称马尔可夫博弈(markov game)模型适用于即时战略游戏、无人集群对抗等问题的建模;而扩展型博弈(extensive form game, EFG)模型常用于基础设施防护,麻将、桥牌等回合制游戏(turn-based game)的序贯交互,多阶段军事对抗决策等问题的建模。最新的一些研究为了追求两类模型的统一,将扩展型博弈模型的建模成因子可观随机博弈(factored observation stochastic game)模型。

图3典型多智能体博弈模型
1.2???非平稳问题
多智能体博弈对抗面临信息不完全、行动不确定、对抗空间大规模和多方博弈难求解等挑战,在博弈对抗过程中,每个智能体的策略随着时间在不断变化,因此每个智能体所感知到的转移概率分布和奖励函数也在发生变化,故其行动策略是非平稳的。当前,非平稳问题主要采用在线学习 [11]、强化学习和博弈论理论进行建模 [12]。智能体处理非平衡问题的方法主要有五大类:无视(ignore) [13],即假设平稳环境;遗忘(forget) [14],即采用无模型方法,忘记过去的信息同时更新最新的观测;标定(target)对手模型 [15],即针对预定义对手进行优化;学习(learn)对手模型的方法 [16],即采用基于模型的学习方法学习对手行动策略;心智理论(theory of mind, ToM)的方法 [17],即智能体与对手之间存在递归推理。面对拥有有限理性欺骗型策略的对手,对手建模(也称智能体建模)已然成为智能体博弈对抗时必须拥有的能力 [18-20?],它同分布式执行中心化训练、元学习、多智能体通信建模为非平稳问题的处理提供了技术支撑 [21]。
2 对手建模
合理的预测对手行为并安全的利用对手弱点,可为己方决策提供可效依据。要解决博弈中非完全信息的问题,最直接的思想就是采取信息补全等手段将其近似转化为其完全信息博弈模型而加以解决。本文中,对手建模主要是指利用智能体之间的交互信息对智能体行为进行建模,然后推理预测对手行为、推理发掘对手弱点并予以利用的方式。
2.1?? 对手建模主流方法?
?2.1.1??? ?显式对手建模方法
常用的显式(explicit)对手建模方法大致可以分为规划行动意图识别方法,行为分类与类型推理方法、策略重构方法、认知推理方法、博弈最佳响应方法等 [22]。
(1)规划行动意图识别
计划行动意图识别(plan, activity and intention recognition, PAIR) [23-24 ]方法是一类典型符号主义人工智能方法,主要采用层次化计划库(plan library)或畴理论(domain theory),预测对手的意图和可能计划,丰富的计划库有助于识别复杂行为模式。根据智能体之间的竞合关系,意图识别可以分为:面向非对抗非合作的无关识别(keyhole recognition) [25];面向合作的有意识别(intended recognition) [26],智能体有意通过隐式通信的方式将自己的行为告知其它合作队友;面向对抗的对抗识别(adversarial recognition) [27],智能体采用欺骗的方式防止敌对敌人识别。
(2)行为分类与类型推理
行为分类(action classification) [28-29 ]方法根据不同信息源,运用机器学习的方法学习选定模型的参数,根据预测模型的多种属性预测风格类别,然后将风格类别标签(例如,攻击型/中立型/防御型,松凶型/紧凶型/松弱型/紧弱型)分配给对手 [28,30-31 ];类型推理(type reasoning) [32-34 ]方法,假设对手有几种已知类型中的一种,并使用在实时交互过程中获得的新观察来更新信念,其中对手“类型”有可能是“黑盒”(black-box)。
(3)策略重构
策略重构(policy reconstruction) [35]方法通过建立模型对对手的行动做出明确的预测来重建对手的决策过程。假设模型有固定的结构,可根据被观察对手的行为,预测行为概率,学习满足条件的任意模型结构。这类方法包括有条件行为概率模型方法 [35-36 ]、案例推理方法 [37]、紧致模型表示方法 [38]和效用重构方法 [39]。
(4)概率及认知推理
基于图模型(graph model)的贝叶斯概率推理方法 [40],使用各种图模型来对对手的决策过程及偏好进行建模,预测对手的可能行为,采用图形化表示有助于提高计算效率,但无法扩展至序贯决策。对抗推理(adversarial reasoning)是一种认知推理方法,通常采用心智模型进行意图识别与欺骗推理 [41]。近来年,基于心智理论 [42]的推理方法得到了广泛研究 [43-44 ],其中递归推理(Recursive Reasoning) [45-47 ]方法对嵌套信念进行建模(例如,“我相信你相信我相信……”)并模拟对手的推理过程来预测他们的行动,递归持续推理对手的可能模型,预测行为的可能性。基于层次推理与无悔学习的方法可以很好地为在线对抗学习提供支撑 [48]。此外,基于Level-K的认知层次模型也常被用于认知推理相关研究 [49-50?]。
(5)博弈最佳响应
博弈最佳响应(best response)方法 [51],通过观察对手的动作频率,并通过将近似均衡策略的信息与观察值相结合来构建对手模型,根据对手模型计算并实行最佳响应,不断进行实时更新。局部最佳响应(local best response)、数据偏差响应(data biased response) [52]、定量响应(quantal response) [53-54 ]和安全最佳响应(safe best response) [55-56 ]也常用于智能体行为建模。
?2.1.2? ??隐式对手建模方法
通常显式建模主要试图通过观察对手在不同情况下的行为来推断对手的策略,通过为对手建立一个模型来实现。隐式(implicit)对手建模 [57]试图找到一个好的对抗策略而不需要直接识别对手的策略。因此,与显式建模不同的是,对手的行动并没有从当前状态中分离出来进行分析。另外,显式建模需要对手在线对局的数据进行模型的实时估计和策略制定,而隐式建模采用的方法是首先离线计算出若干策略组合,然后通过与对手的对局数据来评估这些策略组合的效用,从而避免了在线对手建模存在的计算量大、响应慢等问题。然而隐式建模也需要克服探索(exploration)与利用(exploitation)之间的矛盾,虽然其在在线博弈之前已经预先准备好若干种不同对手模型的对抗策略,但在比赛中找到其中的最优策略需要花费一定的代价,因此平衡探索与利用之间的矛盾,即何时开始与停止探索寻优是隐式建模方法中最大的问题。
(1)元学习
基于元学习的对手隐式建模方法主要通过与对手进行有限的交互,生成对手用于训练,从而获得利用不同对手的能力。Wu设计的自动动手生成模块包括难以被利用的对手生成和多样性 [58]。Maruan提出了一种模型无关的连续自适应对手的元学习方法 [59]。针对多智能体的情况,Kim设计了一种元多智能体策略梯度优化元学习方法 [60]。
(2)在线学习
在线对抗过程中,通常一开始很难进行对手建模,对抗过程中由于对手可能会随机切换风格,导致建立的单个对手模型不确定性很高 [61]。当前面向在线对抗的隐式建模方法主要分两类:一类是多臂机组合(portfolio)在线凸优化方法,其主要利用已经获得的对手模型信息进行在线动态对手建模与优化 [62-63 ];另一类是在线无悔学习方法,其将在线序贯决策过程构建成在线/对抗马尔可夫决策过程(online/adversarial MDP)模型 [64-65 ],通过采样生成多个策略,采用多臂机在线凸优化控制动态后悔值(dynamic regret) [66-68 ]。
(3)对手感知学习
基于对手感知(opponent-aware)的对手建模方法主要通过假设对手也在学习己方模型,与对手共同学习演化是其主要思路,其中假设对手也在学习,故在对手建模过程中要考虑到这一层推理关系。当前,对手感知学习方法常被用于与对手交互学习的环境下的对手建模 [69]。相比传统对手模型学习方法,此类方法通过引入一个包含对手值函数的二阶项来考虑对手策略的变化,可用于更加稳定的对手模型塑造 [70-71 ]。
2.2???对手建模的典型应用
对手建模在人机交互与协同、即时策略对抗规划、可解释性人工智能和智能蓝军等领域有着广泛的应用前景。
2.2.1? ??人机交互与协同
近年来,在人机交互方面,关于人与机器之间的意图推理与共享(intention reasoning and sharing)得到了广泛关注 [72]。2017年AAAI设置了特殊主题“具有人类意识的AI (human-aware AI)”研讨会,2018年,AAAI设置了特别主题“人机协作(human-AI collaboration)”。其研究范围都是基于心智理论向外扩展。2019年,IBM研究提出的具有人类意识(human-aware)的AI系统,围绕“如何才能让人工智能在人类面前表现出可解释的行为”的问题展开研究,其得出的结论是“为了综合可解释的行为,智能体需要超出自己的世界模型进行规划,并考虑到人类在循环中的心智模型。这里的心智模型不只是循环中人类的目标和能力,还包括智能体目标/能力的人类模型。”
2.2.2? ??即时策略对抗规划
对抗规划(adversarial planning) [73]可划分为两个相互影响的部分:对抗推理(adversarial reasoning)和反制规划(counter planning),来表示在一个对抗环境下,一方通过计算求解对手的决定性状态,意图和行为并尽全力反制敌方的行动和计划的动态规划过程。这个领域的子问题包括信念和意图识别,对手策略预测,规划识别,欺骗计划发现,欺骗计划和计划生成等。在21世纪初,美军筹建了CADET系统,这是一个集中在旅级地面行动的战斗规划系统,其中重要一环就是对抗推理和反制规划。DARPA从2004年就开展了实时对抗情报和决策项目(real-time adversarial intelligence and decision-making, RAID) [23],关注如何将敌人在军事行动中的对抗行为纳入反制规划考虑范畴。
2.2.3? ??可解释性人工智能
可解释性人工智能(XAI,eXplainable artificial intelligence)是可信任人工智能(trustable AI)的主要内容。2017年,DARPA 发起“可解释人工智能”项目研究 [74]。竞合环境下的对手建模可用于理解队友行动的透明性(transparency)、可预测性(predictability),明确性(legibility)和可解释性(explicability)程度,理解敌方行动混淆性(obfuscation)、含糊性(ambiguity)、隐私性(privacy),欺骗性(deception)和安全性(security)程度等 [75]。通过对手建模可获得可解释的对手模型,从而提供可解释的推理,并进行决策和行动推荐。
2.2.4? ??智能蓝军
从模拟仿真、平行系统到数字孪生,智能体认知行为建模是其主要技术。在军事模拟仿真训练中,通常需要建立红蓝双方的指挥机构和实兵交战系统,但由红军充当的“蓝军”往往带有“红军”的烙印,使得训练的对手不像真正的蓝军。在红蓝双方博弈对抗过程中,通常蓝方的指挥员由我方指挥员担任,其思路方法与真实的蓝方相差甚远,无法满足对抗需要。由对手建模所生成的智能体模型可填充蓝军模型库,帮助构建蓝军的完整“画像”,可以较为逼真地建立起“智能蓝军”,探索不可知的蓝方策略,是组织红蓝对抗的重要依托,作为训练红方指挥员的“磨刀石”。其实,美军一直将红队技术(red teaming) [76]作为一种辅助决策方法,用来扮演对手,扮演恶魔的拥护者反对自己的概念、计划、策略或系统,以“测试和评估”和改善决策能力。
2.3? ??对手建模面临的挑战
2.3.1? ??有限理性与欺骗
有限理性是指介于完全理性和非完全理性之间的在一定限制下的理性 [46,53-54 ]。欺骗是一类典型的偏离了理性假设的行为。在经济、军事、安全等领域,欺骗和反欺骗的理论研究相对比较深入,Ettingery等在《走向欺骗理论》一文中给出了欺骗的平衡方法,并通过应用案例说明了标准经济学视角的欺骗的影响 [77]。Latimer在《战争中的欺骗》一书中分析了一些著名战争中的军事欺骗 [78]。Zhu为网络问题概述了欺骗和反欺骗的,提出了博弈理论模型和设计机制 [79]。Fugate 针对网络欺骗问题提出了结合博弈理论的人工智能算法用于估计攻击者的隐藏状态,并学习最好的防御系统策略 [80]。Oey运用心智理论分析了人类在欺骗和欺骗识别中的特征 [81]。在扑克AI的动态博弈研究中,Mealing针对隐藏信息的策略多变对手在线建模问题,以隐藏信息推断、行动序列预测、对手模型对抗模拟等3个步骤开展建模 [82]。在人工智能领域,Bontrageret分析了深度强化学习算法在解决一些欺骗性游戏时面临的挑战 [83]。Schneider分析了人工智能决策的欺骗性解释问题,提出在缺乏领域知识情况下很难识别欺骗 [81,84]。
2.3.2? ??对手利用
对手利用(opponent exploitation)是博弈对抗过程中发现对手弱点,充分利用己方认知优势剥削对手的主要方法。在纳什均衡解概念中,双方都采用均衡策略,任何偏离均衡策略的一方所获得的收益将减小。对于非完全理性的对手,其策略和纳什均衡策略之间的“距离”,为其它均衡策略玩家创造了可利用性。在求解(近似)纳什均衡解时,可利用性(exploitability)是均衡策略质量的衡量标准,指该策略在预期中相对于最坏情况下的对手策略所达到的少于博弈价值的量。通常也将这个差值称为一个策略的可利用度,其衡量了对手从未采用纳什均衡策略中获利的程度,即因未采用纳什均衡策略,对手用强有力的应对策略对其作出惩罚的程度,这是对策略最坏情况下质量的度量 [55,85-86 ],故其常被用来评估和训练算法。Ganzfried从安全利用的角度研究了重复零和博弈安全的问题,给出了安全策略的完整特性,开发了一种利用次优对手并保证安全的高效算法 [87]。Li使用进化递归神经网络(evolved RNN)估计己方赢率和对手弃牌率的方式来利用对手 [88]。当前对手利用主要有基于博弈的安全对手利用(safe opponent exploitation) [56]、在线无悔学习(online no-regret learning) [89]、集成学习(ensemble learning) [90]和元学习(meta-learning) [58]等方法。其中安全对手利用方法在线实时对抗过程中,通过利用对手模型预测对手状态及可能采取的行动,发掘可利用空间,增加己方收益。基于集成学习的方法将多个对手模型纳入强化学习的过程中,学习鲁棒的应对策略。基于元学习的方法通过与不同风格的对手进行有限的交互来训练学习,从而习得“利用”不同对手的能力。在线无悔学习方法通过博弈对抗序列进行决策优化,约束后悔值及时调整策略。
2.3.3? ??策略平衡
如何应对多种风格对手一直是智能体策略应对的难点 [91]。此前的一些研究将着力点放在了多目标博弈对手建模方法的研究上 [92],最新的一些研究更注重“策略平衡”。在安全保底的博弈理念驱动下,McCracken提出在对手建模过程寻找安全策略的方法 [93],Wang提出在对手建模时时要平衡安全与可利用性 [55],安全对手利用 [56]、安全搜索 [94]、安全嵌套搜索 [95]等方法也相继被提出。在元博弈理论的指引下,一些关于多样性(diversity)的研究也相继被提出,强调在博弈对抗过程中,同样要考虑策略的多样性 [96]。
3? 基于元博弈理论的对手建模框架
针对多智能体博弈对抗中的非平稳问题,以及对手建模面临的挑战,本文基于元博弈理论,从智能体认知行为出发,试图建立一个满足多智能体博弈对抗需求的通用对手建模框架。
3.1? ??元博弈
基于博弈理论的策略训练方法为多智能体学习方法提供了全新的求解架构 [97],其中基于元博弈的(meta-game)的策略评估与提升融合为多智能体学习提供了通用训练方法 [98]。元博弈亦称博弈的博弈(game of a game) [99],是一种典型的实证博弈分析方法 [100],交互的智能体可以采用智能体模型池中不同的参数策略进行对抗。理论分析表明,元博弈的纳什均衡是原始博弈的2 ε纳什均衡 [100]。
利用元博弈理论,有助于理解博弈的策略空间结构,探索人工智能AI训练方法。表1所示为强化学习、博弈论与元博弈的相关要素。
下面首先从博弈动力学的角度,分析现实世界中的博弈策略空间的几何结构。现实世界的博弈是由传递压制部分和循环压制部分混合组成的,其博弈策略空间几何结构类似于一个旋转的陀螺,可以用图4所示的旋转陀螺的几何结构来表示,其中直立轴为传递压制维,径向轴为循环压制维 [101]。从博弈动力学的角度,可以分析博弈策略空间几何体的梯度,散度和旋度 [102],定义为
式中:旋度为0表示传递压制博弈,散度为0表示循环压制博弈。

图4博弈策略几何体[101]
任何一个函数形式博弈(function form game, FFG)都可以分解为传递博弈(transitive game)和循环博弈(cycle game)两部分:
函数 φ( υ, ω)表示从 v到 w的流,根据霍奇分解可知,传递博弈的旋度为0,循环博弈的散度为0,博弈的向量空间满足正交分解:
基于势博弈(potential game)理论的传递压制博弈模型可以求得均衡解,用于评判智能体策略层次水平;而循环压制博弈模型由于存在首尾循环压制关系,无法评判单个智能体策略水平高低。智能体智能水平的提升主要依赖传递博弈均衡策略的优劣和循环博弈策略的多样性。旋转陀螺几何体揭示了智能体策略水平从底部到顶层的提升过程中,循环压制维(即策略多样性)首先需要得到拓展,在突破陀螺中间部分后,则需要明确的压制性目标驱动学习压制性策略。
对于多智能体博弈对抗问题,当我们拥有大算力,去尽可能的遍历环境中的各种情况,虽然不是一个最优的解法,也可以在某些环境下取得一定的效果。如图5所示,当前用于训练单智能体的方法主要有最小最大(min-max)、搜索(search)、奖励塑造(reward shaping)、强先验(strong priors)、模仿初始化(imitation init)等方法,多智能体学习方法主要有自博弈(self-play)、协同学习(co-play)、神经虚拟自博弈(fictitious self-play)、种群博弈(population play)等方法 [103]。其中自博弈的主要思路是让策略进行子博弈,每次去找到一个对于剩余策略的最佳响应,然后固定最佳响应策略循环迭代训练。此外,神经虚拟自博弈(neural fictitious self- play) [104],采用对历史的策略都作最佳响应并加权。
基于元博弈的策略学习方法通常包括策略评估与策略提升。与强化学习中不同的是,这里的策略(strategy)指的是群体的纯策略或技能(skill)。相比于直接评估提升单个策略的状态动作对,元博弈重点在于找到群体中最好的策略并提高它。目前最好的策略评估和策略提升方法分别是α-Rank和PSRO(policy space response oracle)与一些新的变体 [105]。其中α-Rank与其的一些变种α α-Rank [106]通过对群体策略两两之间连接,构成一个策略间的响应图(response graph),构建图上的汇点强连接组件(sink strongly connected component, SSCC),在这个图中去游走寻找一些只有“进度”没有“出度”的节点或子图。通过将边软化(soft),使之可以被建模为Markov-Conley链并且保证了Markov链平稳解的存在性和唯一性。通过上述方法可以评价群体策略并对其进行排名,之后需要对这些策略进行提升。目前PSRO算法得到广泛的应用,PSRO首先抽样一个初始策略并计算效用函数,并初始化元策略(记录策略分布的函数),元博弈开始于一个单一的策略,并在每个轮(epoch)中添加策略Oracle,这些策略将尽可能地响应其他玩家的元策略。Yan提出基于Sink均衡的策略评估与搜索方法 [107],Stephen提出要采用并行化PSRO的方法来加快策略分层与提升 [108],Nieves和Liu等提出要利用多样性来引导博弈策略提升 [96,109]。总之,元博弈理论描述了博弈策略空间几何体的空间形态,为我们利用各类“对手模型”,学习训练评估和提升智能体各类策略提供了理论支撑和方法指导。
3.2????对手建模框架
基于元博弈理论,本文设计了包括“对手策略识别与生成、对手策略空间重构、对手策略利用”共3个模块的对手建模框架。如图6所示。
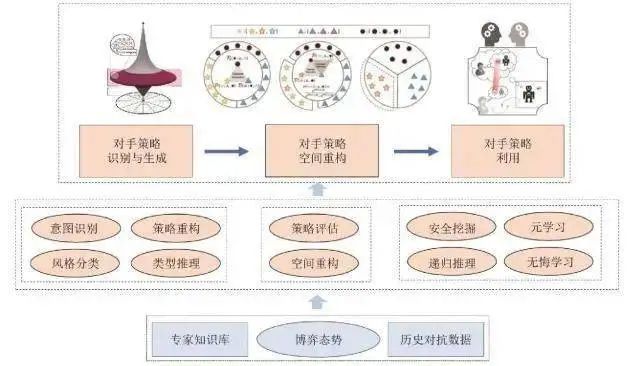
图6面向多智能体博弈对抗的对手建模框架
对手建模框架利用专家知识和博弈态势识别对手意图、风格类型,做好对手策略重构和类型推理;评估对手的策略空间,从博弈动力学的角度分析传递压制和循环压制策略并进行空间重构;基于安全利用策略,设计可在在线决策过程中应对非平稳对手的元学习及无悔学习等对手策略利用方法。下面对各个模块展开分析。
(1)对手策略识别与生成
该模块主要负责识别对手策略,离线或在线生成对手模型。主要采用意图识别、风格分类、策略重构、类型推理等方法统计分析对手的行动规律、风格类型等。
(2)对手策略空间重构
该模块主要依据元博弈理论分析智能体模型策略空间形态,重构传递压制与循环压制策略空间。在对手策略识别与生成的基础上,完成对当前对手策略的能力水平进行有效地评估。对手策略空间重构就是为了从更高的战略层级评估当前对手策略与己方策略的相对关系,为下一步对手模型利用提供衡量的手段。
(3)对手策略利用
该模块主要利用安全策略挖掘与递归推理方法学习己方应对策略模型,在线对抗过程中依托己方基线模型,采用元学习与在线无悔学习方法自主调节利用对手。
3.3????未来研究方向
(1)基于异构模型的对抗集成学习
当对手模型由不同方法学习得到时,此时获得的是参数不一致的异构模型,可以采用集成学习(ensemble learning)方法 [29,90]组织博弈对抗训练。
(2)基于同构模型的神经演化学习
当对手模型由相同的方法学习得到时,此时获得的是参数模型一致的同构模型,可以采用神经演化学习(neuroevolutionary learning)方法 [90,110]组织博弈对抗训练。
(3)基于种群演化的多样性课程学习
面对复杂的任务,智能体需要掌握多种不同技能,此时可以采用分阶段课程学习(curriculum learning) [111]或多样性自主课程学习(auto- curriculum) [112],通过种群课程训练和演化选择学习技能。
(4)基于双层嵌套优化的元学习
当对手模型未知时,智能体需要与未知对手进行对抗,可以利用元学习(meta-learning)方法 [58],通过学习历史交互信息,在线生成难以被利用(hard to exploit)对手和多样性(diverse)对手模型来指导博弈对抗。
(5)基于在线凸优化的无悔学习
面对可能随意变换风格的对手,在线对抗可以采用无悔学习(no-regret learning)方法 [48],通过分析交互过程中的动态后悔值来指导博弈对抗。在线重复博弈过程中若只能接收到赌博机(bandit)式反馈 [58],可以设计满足末轮迭代收敛(last iterate convergence)的无悔学习方法 [113]。
(6)基于不确定性建模的自适应学习
对手策略的变化导致历史交互信息不完全可用、决策信息集大导致状态不完全可知、对手采用欺骗与诈唬等方式导致信息不完全可信。可以设计基于鲁棒性、贝叶斯优化、对抗学习、博弈控制和变分推理 [114]等理论的自适应策略学习方法。
4 结 论
多智能体博弈对抗过程中,可能面临对手信息不完全、信息不完美、信息不对称等挑战。本文旨在构建面向非平稳环境的通用对手建模框架。首先从多智能体博弈对抗的角度介绍了当前多智能体博弈的几类典型模型和非平稳问题。其次,结合对手建模前沿理论梳理总结了两大类共八小类对手建模方法,并对其应用前景和面临的挑战进行详细分析。最后,基于元博弈理论,从对手策略识别与生成、对手策略空间重构、对手策略利用三个方面构建了一个通用的对手建模框架,并指出了对手建模的未来六大主要研究方向。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询”? 发布
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!