Paper Survey——NeRF SLAM
NeRF SLAM(Neural Radiance Fields Simultaneous Localization and Mapping)是一种结合神经辐射场(NeRF)和SLAM(Simultaneous Localization and Mapping)的先进技术,用于实时地构建三维环境地图并同时估计相机的姿态。目前NeRF-SLAM主要有以下两个方向:
- SLAM为NeRF训练提供位姿,然后建立稠密细腻的三维场景。简而言之就是NeRF只做mapping
- 在NeRF里建立各种损失函数反过来优化pose和depth。 简而言之就是full slam
那么基于这两个方向,目前的NeRF SLAM的工作主要分为以下三类:仅优化NeRF、仅优化位姿、位姿和NeRF联合优化。与此同时,本文也把最新的3D Gaussian Splatting也加入调研序列中。每个工作介绍的时候都会给出论文的下载链接、源代码(如有)、demo video(如有)
本博文,意在记录本人调研NeRF-SLAM的时候做的学习记录,部分资料来源于网络,本博文仅仅供本人学习记录用~
目录
什么是NeRF?
NeRF 所做的任务是 Novel View Synthesis(新视角合成),即在若干已知视角下对场景进行一系列的观测(相机内外参、图像、Pose 等),合成任意新视角下的图像。传统方法中,通常这一任务采用三维重建再渲染的方式实现,NeRF 希望不进行显式的三维重建过程,仅根据内外参直接得到新视角渲染的图像。为了实现这一目的,NeRF 使用用神经网络作为一个 3D 场景的隐式表达,代替传统的点云、网格、体素、TSDF 等方式,通过这样的网络可以直接渲染任意角度任意位置的投影图像。

?NeRF 的思想比较简单,就是通过输入视角的图像每个像素的射线对于密度(不透明度)积分进行体素渲染,然后通过该像素渲染的 RGB 值与真值进行对比作为 Loss。由于文中设计的体素渲染是完全可微的,因此该网络可学习:

关于更详细的什么是NeRF,我们接下来看看NeRF的开山之作,通过阅读这篇论文,看看到底什么是NeRF。由于这属于整个NeRF SLAM的基础,故此,此处做更深入的理解与学习。
NeRF
NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
论文采用的只是fully-connected(non-convolutional)deep network,也就是只是MLP而不是CNN。论文中一个示意的网络结构如下:
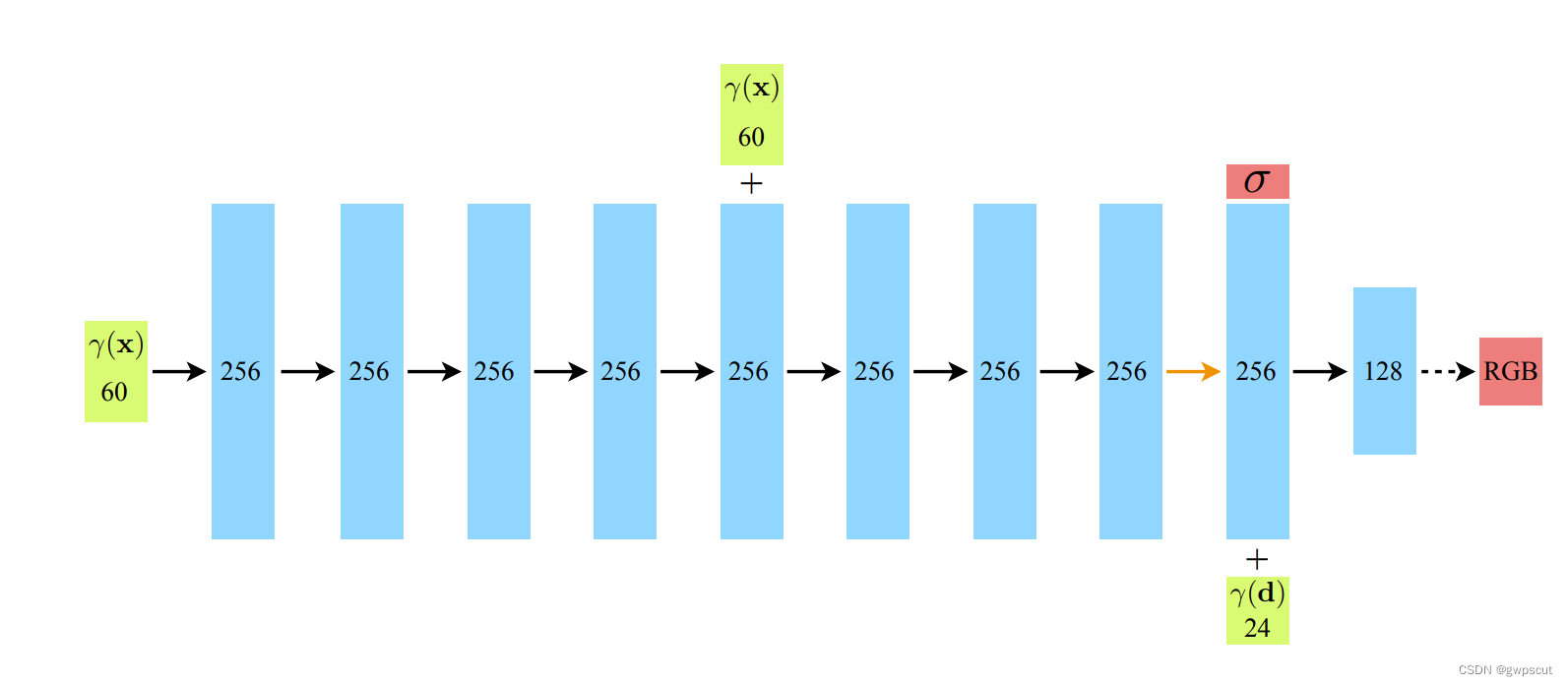
而这个网络的输输入则是一个5D的数据,包括了3D 位置 x=(x,y,z)?和 2D 视角方向(θ,?),一共5D。对于其中的 2D 视角方向可以用下图进行直观解释(个人理解其实就是6-DoF pose中的x、y、z、row、pitch)。

?在实际实现中,论文将视角方向表示为一个三维笛卡尔坐标系单位向量d,也就是图像中的任意位置与相机光心的连线,我们用一个 MLP 全连接网络表示这种映射(x为3D位置):

通过优化这样一个网络的参数?Θ?来学习得到这样一个 5D 坐标输入到对应颜色c和密度σ输出的映射。
而网络的输出则是volume density (体积密度) and view-dependent emitted radiance at that spatial location(对应位置的辐射radiance )。对于每个5D位置都输出一个对应的辐射(radiance 其实也就是RGB信息)以及density(其实也就是不透明度)。
所谓的不透明度就是控制光线通过位置xyz的累计的幅度。
通过沿着相机光线查询5D坐标来合成视图,并使用经典的体积渲染技术将输出的颜色和密度投影到图像中。
此外,还需要image对应的camera pose已知来作为输入(也就是经典的SLAM中已知pose纯mapping的问题)。
总而言之,所谓的“神经辐射场(Neural Radiance Field)”可以理解为物体发出辐射,从而在观察者传感器(人眼)上形成颜色。在NeRF中是5D的,用来表达复杂的几何+材质连续场景的方法,该辐射场使用 MLP 网络进行参数化,而这个MLP的网络的输入与输出如下:
- 输入为:3D 位置 x=(x,y,z)?和 2D 视角方向(θ,?),一共5D
- 输出为:发射颜色 c=(r,g,b)?和体积密度(不透明度)σ。
最后,再通过经典的体素渲染(Volume Rendering)将获得的一系列颜色和密度累计到一个2D图像上。由于这个过程是可微的,因此采用梯度下降法来对观测到的image以及渲染的视角(views rendered from our representation)进行优化。将这个误差在多个视图之间最小化,鼓励网络通过分配高体积密度和准确颜色给包含真实场景内容的位置来预测场景的一致模型。下图为NeRF的流程
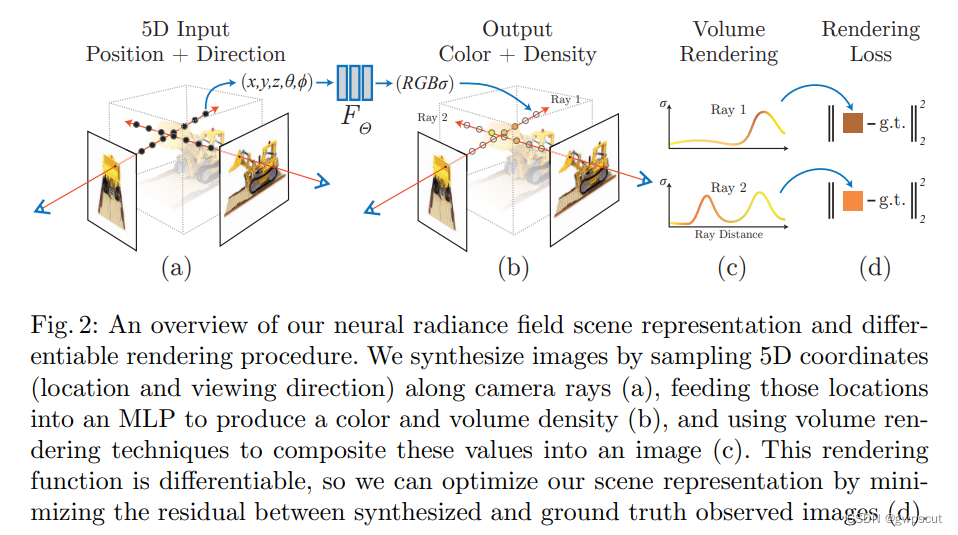
这篇论文主要工作和创新点如下:
1)提出一种用 5D 神经辐射场 (Neural Radiance Field) 来表达复杂的几何+材质连续场景的方法,该辐射场使用 MLP 网络进行参数化;(这个神经辐射场是用来通过优化来保证真实感)
2)提出一种基于经典体素渲染 (Volume Rendering) 改进的可微渲染方法,能够通过可微渲染得到 RGB 图像,并将此作为优化的目标。该部分包含采用分层采样的加速策略,来将 MLP 的容量分配到可见的内容区域;
3)提出一种位置编码 (Position Encoding) 方法将每个 5D 坐标映射到更高维的空间,这样使得我们可以让我们优化神经辐射场更好地表达高频细节内容。
个人认为:前面的两个contribution算是NeRF中最主要的思想,第三点算是一个提升。因为最基本的形式并不足以handle复杂的场景下的高分辨率渲染。通过Position Encoding来让MLP实现高频的表达,通过hierarchical sampling策略来降低高频场景表达所需的采样。

为了让网络学习到多视角的表示,论文有如下两个合理假设:
- 体积密度(不透明度)?σ?只与三维位置?x?有关而与视角方向?d?无关。物体不同位置的密度应该和观察角度无关,这一点比较显然。
- 颜色?c?与三维位置?x?和视角方向?d?都相关。(这也是natural的)
预测体积密度?σ?的网络部分输入仅仅是输入位置?x,而预测颜色?c?的网络输入是视角和方向?d。在具体实现上:
- MLP 网络
 首先用 8 层的全连接层(使用 ReLU 激活函数,每层有 256 个通道),处理 3D 坐标?x,得到?σ?和一个 256 维的特征向量。
首先用 8 层的全连接层(使用 ReLU 激活函数,每层有 256 个通道),处理 3D 坐标?x,得到?σ?和一个 256 维的特征向量。 - 将该 256 维的特征向量与视角方向?d?与视角方向一起拼接起来,喂给另一个全连接层(使用 ReLU 激活函数,每层有 128 个通道),输出方向相关的 RGB 颜色。
如下图所示
接下来看看,如何基于辐射场进行体素渲染(Volume Rendering with Radiance Fields)
采用经典的渲染方式来对场景中的颜色进行渲染。对于基于辐射场的体素渲染。为了理解文中的 Volume Rendering 和 Radiance Field 的概念首先我们回顾下图形学中最基础的渲染方程:
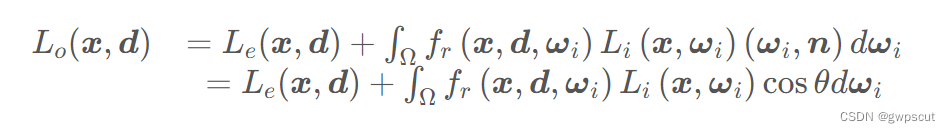
如下图所示,渲染方程表达了 3D 空间位置?x?在方向?d?的辐射(出射光)![]() 。该辐射表达为该点自身向外的辐射(发射光)
。该辐射表达为该点自身向外的辐射(发射光)![]() 和该点反射外界的辐射(反射光)之和。
和该点反射外界的辐射(反射光)之和。


简单理解辐射概念,在物理学中,光就是电磁辐射,电磁波长?λ?与频率?ν?的关系式为

也就是二者的乘积为光速?c。而我们又知道可见光的颜色 RGB 就是不同频率的光辐射作用于相机的结果。因此在 NeRF 中认为辐射场就是对于颜色的近似建模。
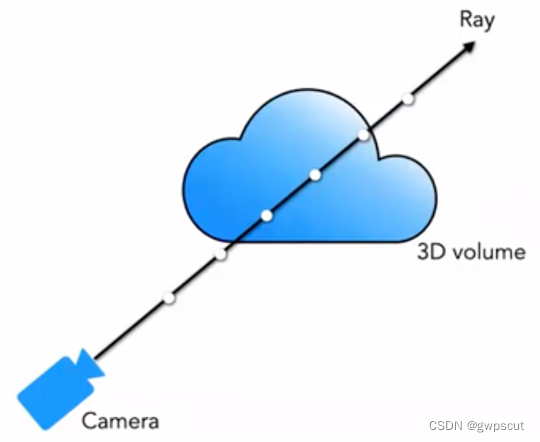
经典的体素渲染方法有网格渲染、体素渲染等,对于很多类似云彩、烟尘等等特效。而5D 神经辐射场将场景可以表示为:其所在空间中任意点的体素密度和有方向的辐射亮度。体素密度?σ(x)?定义为光线停留在位置?x?处无穷小粒子的可导概率(或者也可以理解为光线穿过此点后终止的概率)。使用经典的立体渲染的原理,我们可以渲染出任意射线穿过场景的颜色。因此对于某个视角?o?发出的方向为?d?的光线,其在t?时刻到达点为:

那么沿这个方向在时间范围(tn?,tf?)?对颜色积分,获得最终的颜色值C(r)?为:

函数T(t)?表示光线从?tn??到?t?累积的透明度 (Accumulated Transmittance)。换句话说,就是光线从tn??到?t?穿过没有碰到任何粒子的概率。按照这个定义,视图的渲染就是表示成对于?C(r)?的积分,它是就是虚拟相机穿过每个像素的相机光线,所得到的颜色。

不过在实际的渲染中,并不能进行连续积分。因此论文通过采用分层采样 (stratified sampling) 的方式对?[tn?,tf?]?划分成均匀分布的N个小区间,对每个区间进行均匀采样,划分的方式如下:

对于采样的样本,论文采用离散的积分方法:

其中,![]() 是相邻样本之间的距离。下图非常形象地演示了体素渲染的流程:
是相邻样本之间的距离。下图非常形象地演示了体素渲染的流程:

上述方法就是 NeRF 的基本内容,但基于此得到的结果并能达到最优效果,存在例如细节不够精细、训练速度较慢等问题。为了进一步提升重建精度和速度,论文还引入了下面两个策略来优化一个神经辐射场(Optimizing a Neural Radiance Field ):
- Positional Encoding (位置编码):通过这一策略,能够使得 MLP 更好地表示高频信息,从而得到丰富的细节;
- Hierarchical Sampling Procedure (分层采样方案/金字塔采样方案):通过这一策略,能够使得训练过程更高效地采样高频信息。
对于Positional Encoding (位置编码)。尽管神经网络理论上可以逼近任何函数,但是通过实验发现仅用 MLP 构成的?FΘ??处理输入 (x,y,z,θ,?)?不能够完全表示出细节。即:神经网络倾向于学习到频率较低的函数。同时通过将输入通过高频函数映射到高维空间中,可以更好地拟合数据中的高频信息。通过这些发现应用到神经网络场景表达任务中,论文将?FΘ??修改成两个函数的组合:

通过这样的方式可以明显提升细节表达的性能,其中:

论文使用的编码函数如下:
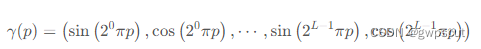
该函数?γ(?)?会应用于三维位置坐标?x?(归一化到 [?1,1])和三维视角方向笛卡尔坐标?d。在论文中对于?γ(x)?设置?L=10;对于γ(d)?设置?L=4。因此可以得到对于三维位置坐标的编码长度为:3×2×10=60,对于三维视角方向的位置编码为?3×2×4=24,这也与网络结构图上的输入维度相对应。
接下来看看Hierarchical Sampling Procedure (分层采样方案)
分层采样方案来自于经典渲染算法的加速工作,在前述的体素渲染 (Volume Rendering) 方法中,对于射线上的点如何采样会影响最终的效率,如果采样点过多计算效率太低,采样点过少又不能很好地近似。那么一个很自然的想法就是希望对于颜色贡献大的点附近采样密集,贡献小的点附近采样稀疏,这样就可以解决问题。基于这一想法,NeRF 很自然地提出由粗到细的分层采样方案(Coarse to Fine)。
Coarse 部分:首先对于粗网络,采样?Nc??个稀疏点(c 表示 Coarse),并将公式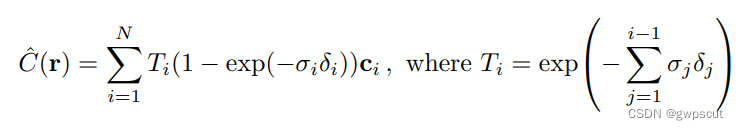 用新的形式修改(加入权重):
用新的形式修改(加入权重):

其中权重需要进行归一化:

这里面的权重![]() 可以看成沿着射线的分段常数概率密度函数 (Piecewise-constant PDF)。通过这个概率密度函数可以粗略地得到射线上物体的分布情况。
可以看成沿着射线的分段常数概率密度函数 (Piecewise-constant PDF)。通过这个概率密度函数可以粗略地得到射线上物体的分布情况。
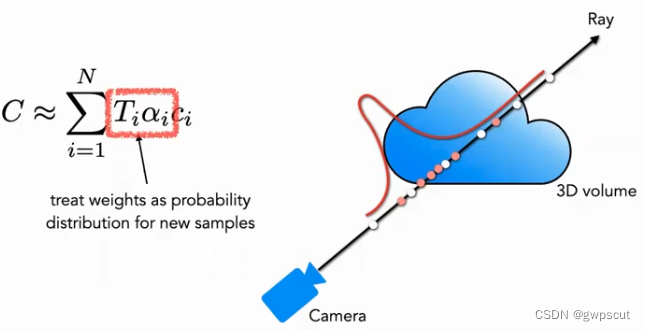
Fine 部分:在第二阶段,论文使用逆变换采样 (Inverse Transform Sampling),根据上面的分布采样出第二个集合?Nf?,最终我们仍然使用公式 来计算?![]() 。但不同的是使用了全部的
。但不同的是使用了全部的![]() 个样本。使用这种方法,第二次采样可以根据分布采样更多的样本在真正有场景内容的区域,实现了重要性抽样 (Importance Sampling)。如上图所示,白色点为第一次均匀采样的点,通过白色均匀采样后得到的分布,第二次再根据分布对进行红色点采样,概率高的地方密集,概率低的地方稀疏 (很像粒子滤波)。
个样本。使用这种方法,第二次采样可以根据分布采样更多的样本在真正有场景内容的区域,实现了重要性抽样 (Importance Sampling)。如上图所示,白色点为第一次均匀采样的点,通过白色均匀采样后得到的分布,第二次再根据分布对进行红色点采样,概率高的地方密集,概率低的地方稀疏 (很像粒子滤波)。
至于在训练优化函数方面,论文的定义非常简单直接,就是对于粗网络和精网络都用渲染的?L2??Loss,公式如下:


与其他的多视角合成(View Synthesis)的方法对比。
定量对比可以发现NeRF优异于其他经典的渲染方法的。
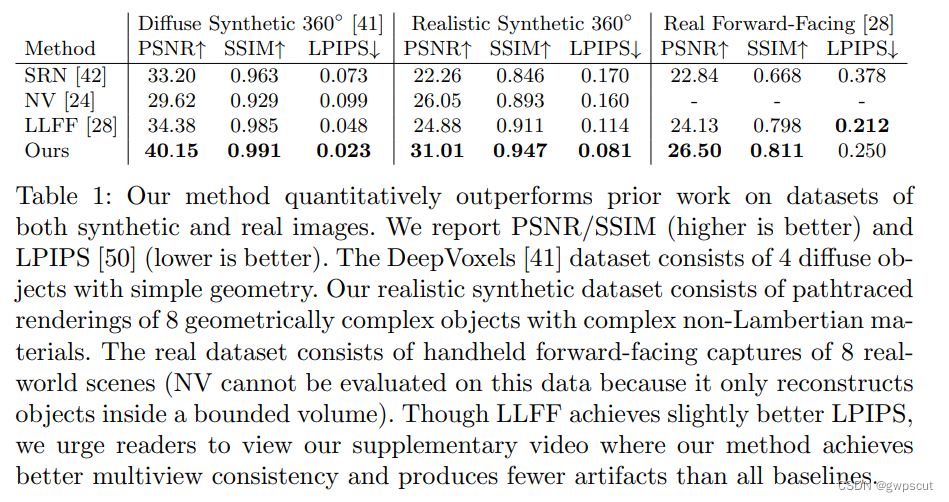
定性对比的效果如下。在合成的数据集上,纹理恢复的效果也是好很多的,跟GT非常的接近。

而在真是的数据集上性能也是非常强大的。

仅优化NeRF
这部分介绍的就是仅仅用NeRF来做mapping的工作,image的pose需要已知或者通过其他算法提供。这也是原本的NeRF提出的时候主要的解决问题(三维重建),大量NeRF的各种变种也属于这个类别。
NeRF++
Nerf++: Analyzing and improving neural radiance fields
GitHub - Kai-46/nerfplusplus: improves over nerf in 360 capture of unbounded scenes
?NeRF++是在NeRF基础上进行的研究,主要分析了NeRF能够处理三维形状歧义性的原因;以及给出NeRF在大规模无边界场景的360°视角合成的一种处理方案。

Shape-Radiance Ambiguity
-
问题:使用二维图像做渲染,目标是渲染出新视角下的颜色分布,而无须特别关注真实的几何形状,并且根据三维点到相机原点的射线上所有点的成像特征也无法确定深度,导致几何解的不唯一,存在歧义性。
-
NeRF能够处理歧义性的原因在于,不同的观测角度下同一点产生的颜色值不同,采用原始点(颜色)与坐标点(位置)的分开输入和分开进行编码,使得观测角度独立,保证了渲染的细节信息,消除歧义性。

Parameterization of Unbounded Scenes
-
问题:较小的场景深度范围内,NeRF可以通过积分(离散求和)还原辐射场和体密度。但户外360°场景的背景景深可能非常大(如山脉、天空),巨大的动态深度范围使得积分逼近变得困难,无法兼顾近景和远景的分辨率。
-
NeRF++将原始NeRF扩展到无边界场景中。利用两个NeRF分别处理前景和背景,解决NeRF前景清晰背景模糊的问题。

NeRF++引入逆球面参数化的方法优化无边界场景。球内部使用原始的NeRF进行渲染;对于球外点

重新使用一个四元组来表示,如下:
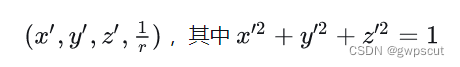
r能够唯一确定这个方向上的一个球外点。在这样的表示下,四元组中的每个参数都是有界的,1/r相当于将外部点逆转到球内部,然后可套用NeRF进行渲染这个四元组。
于穿过球体内外两部分的光线分别积分,将两个NeRF的渲染结果进行融合,得到一条射线上的颜色和透明度,因此重新渲染积分公式如下:

在单位球外的点(x,y,z),通过几何变换即可映射到球面上的点(x',y',z'),该点由圆心o和p点连线与球面交点确定,同时记录距离r。

效果如下:确实在一些纹理细节上的恢复比传统的NeRF有提升~

Instant-NGP
Instant neural graphics primitives with a multiresolution hash encoding
Instant neural graphics primitives with a multiresolution hash encoding (1)
下面介绍的比较有意思的两个工作Orbeez-SLAM与GO-SLAM都是基于Instan-NGP来实现实时的渲染的,为此,深入了解一下这个工作~
这是英伟达一个工作,最快可以将训练 NeRF 模型缩至 5 秒。而这一实现这是来自于论文所提出的多分辨率哈希编码技术(multiresolution hash encoding)。论文在4 个代表性任务中对多分辨率哈希编码技术进行验证,它们分别是神经辐射场(NeRF)、十亿(Gigapixel)像素图像近似、神经符号距离函数(SDF)和神经辐射缓存(NRC)。每个场景都使用了 tiny-cuda-nn 框架训练和渲染具有多分辨率哈希输入编码的 MLP。

将神经网络输入映射到更高维空间的编码过程,从紧凑模型中提取高近似精度。在这些编码中,通过可训练、特定于任务的数据结构,承担了很大一部分学习任务。进而可以使用更小、更高效的多层感知机。因此,本文提出一种多分辨率哈希编码。
通过对输入做哈希encoding的方式,来让很小的网络也能学到很高的质量。之所以小网络就可以学到很好结果是因为,它把很多可学习的特征存在了多个不同分辨率的哈希表里,让那些feature来承担了很大部分的学习负担。
对于神经网络,它们把数据信息存储在了网络权重中,但信息完全存在网络中会导致计算很慢,网络表达能力也会受到的限制。于是考虑把latent feature用结构化的方式存储,比如存在3d grid上,这样表达能力不会受到网络权重数量的限制,每次bp的参数也只和3d grid对应的cell还有小网络相关,训练时间大大缩短。但是,3d grid这种结构化数据其实是很浪费的,因为只有表面信息是有意义的,绝大多数cell是空的。用acorn那样的树形数据结构可以减少内存以及需要训练的数据量,但是训练过程中动态维护树的结构,带来比较大的开销。所以论文就提出了一种多层次的hash encoding方式,来解决像acorn这样的树形结构存在的弊端。它其实就是提出了用多分辨率的哈希表这个数据结构来存feature。
对于一个3维空间,我们可以认为它是由两个部分的信息组成的。
1、低分辨率(coarse部分)相当于低频部分,此部分可以大致刻画局部趋势。低分辨率下,网格点与阵列条目呈现 1:1 映射;
2、高分辨率部分(fine)相当于高频部分,此部分可以刻画局部细节。高分辨率下,阵列被当作哈希表,并使用空间哈希函数进行索引,其中多个网格点为每个阵列条目提供别名。这类哈希碰撞导致碰撞训练梯度平均化,意味着与损失函数最相关的最大梯度将占据支配地位。因此,哈希表自动地优先考虑那些具有最重要精细尺度细节的稀疏区域。
因此,通过multi-resolution grids就是为了兼顾不同方面(低分辨率局部趋势)(高分辨率局部细节)而设置的结构。? 最后不同分辨率的特征将被concat在一起。
不同分辨率下的哈希表都可以并行地查询,进而保证了高效性。
步骤:
1、分层(Hashing of voxel verticles)。先把现在的定义域划分成不同resolution的L层,比如下图(1)中的红色和蓝色线就划分了不同resolution的格点。确定好最精细和最粗糙的grid划分的resolution之后,中间层的resolution通过等比级数计算得到。
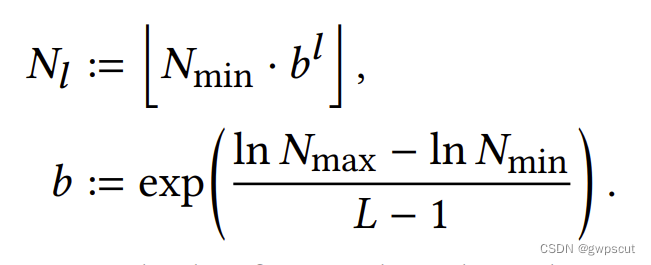
这里的b是通过Nmax(最精细resolution)和Nmin(最粗糙resolution)算出来的一个系数。然后l是指第多少层。

2、hash encoding(Look up - Hashing)。把不同层的grid全都映射到这个层对应的一个哈希表里(如图2所示)。最理想的情况当然是最精细的resolution下,每个格点也能有一个在哈希表上对应的位置来存它的feature,但是这会很费空间。所以这篇文章设定了哈希表最大的一个T。现在蓝色和红色情况下,格点数小于T,所以每一个grid都有一个对应的哈希槽来存它的feature。但如果grid数大于这个T,那通过哈希函数的映射后,很多格点会对应到哈希表上同一个位置。这里为了节省时间/空间,它不对hash collision(哈希冲突)做任何处理,如果算出来哈希值一样,那就用同一个feature来刻画这些格点。
3、线性插值(Linear interpolation)。每个点都是由周围格点的线性插值来得到自己的feature(如图3所示)。
4、网络学习(Concatenation and Network learning)。然后它把这个点和它对应的所有层的feature全都concat起来喂给网络去学习。见上图的(4)操作。
之后论文就对这个处理方式进行了论证,包括F(每个feature的维度),L(multiresolution的层数),T(每层哈希表的最大entry个数)等进行了大量的消融实验。此外,由于不处理hash collision,会出现在较高resolution的层出现很多个格点对应同一个feature的现象。那这就会带来歧义。这就体现了multiresolution的好处,虽然这某几个个格点在这一层对应了同一个feature,但是它俩不太可能在所有层都对应同一个feature。而网络input又是这个点以及它对应的所有feature一起送到网络里的,所以网络在学习的过程中是可以区分不同点的。
但同时,虽然在比较精细的层,很多点都在优化同一个feature。但是最重要的点,比如nerf里表面的点,它对应的梯度会比空间中那些空的点更大,因此它也会对这个feature的优化起主导作用,从而让真正重要的点的信息去支配这个最精细feature的学习。
由于本博文主要是关于NeRF的,所以关注?NeRF 场景的效果。对于大型的?360 度场景(左)以及具有许多遮蔽和镜面反射表面的复杂场景(右)都得到了很好的支持。实时渲染这两种场景模型,并在 5 分钟内通过随意捕获的数据进行训练:左边的一个来自 iPhone 视频,右边的一个来自 34 张照片。效果可以说是很惊艳了,而且这篇论文在本人写这篇博客的时候citation已经达1000+了,也有大量基于这个工作的延申了,故此后续开发直接基于源代码做就好了,这个图结构以及压缩编码的具体原理应该是不需要深入推敲的。

RO-MAP
RO-MAP:Real-Time Multi-Object Mapping with Neural Radiance Fields
RO-MAP:Real-Time Multi-Object Mapping with Neural Radiance Fields
第一个不依赖于3D先验的单目多对象建图pipeline。同时可以定位object的位置以及渲染。(由于不是相机的自定位只是物体的定位,所以不归为下面SLAM中,但这其实也属于SLAM的一种,Object-SLAM,利用语义等信息来定位以及重建物体)。对于每个检测的物体都单独每个目标都单独训练一个MLP,建立物体级NeRF地图。

整个框架分为物体级SLAM和物体级NeRF两部分。物体级SLAM基于ORB-SLAM2实现,识别目标没有使用学习方法,而是使用一种轻量级的手工方法来定位。还采用一种基于稀疏点云的语义信息和统计信息的方法来自动关联多视图观测与目标地标。在估计 了物体级SLAM的边界框和相机姿态后,就可以用NeRF学习物体的稠密几何形状。每当检 测到一个新的对象实例,初始化一个新的NeRF模型(也是用Instant-NGP)。注意,这里的 NeRF不重建整个场景,而是只表示单个对象,也就是可以使用轻量级网络加快训练速度。

实验效果如下:



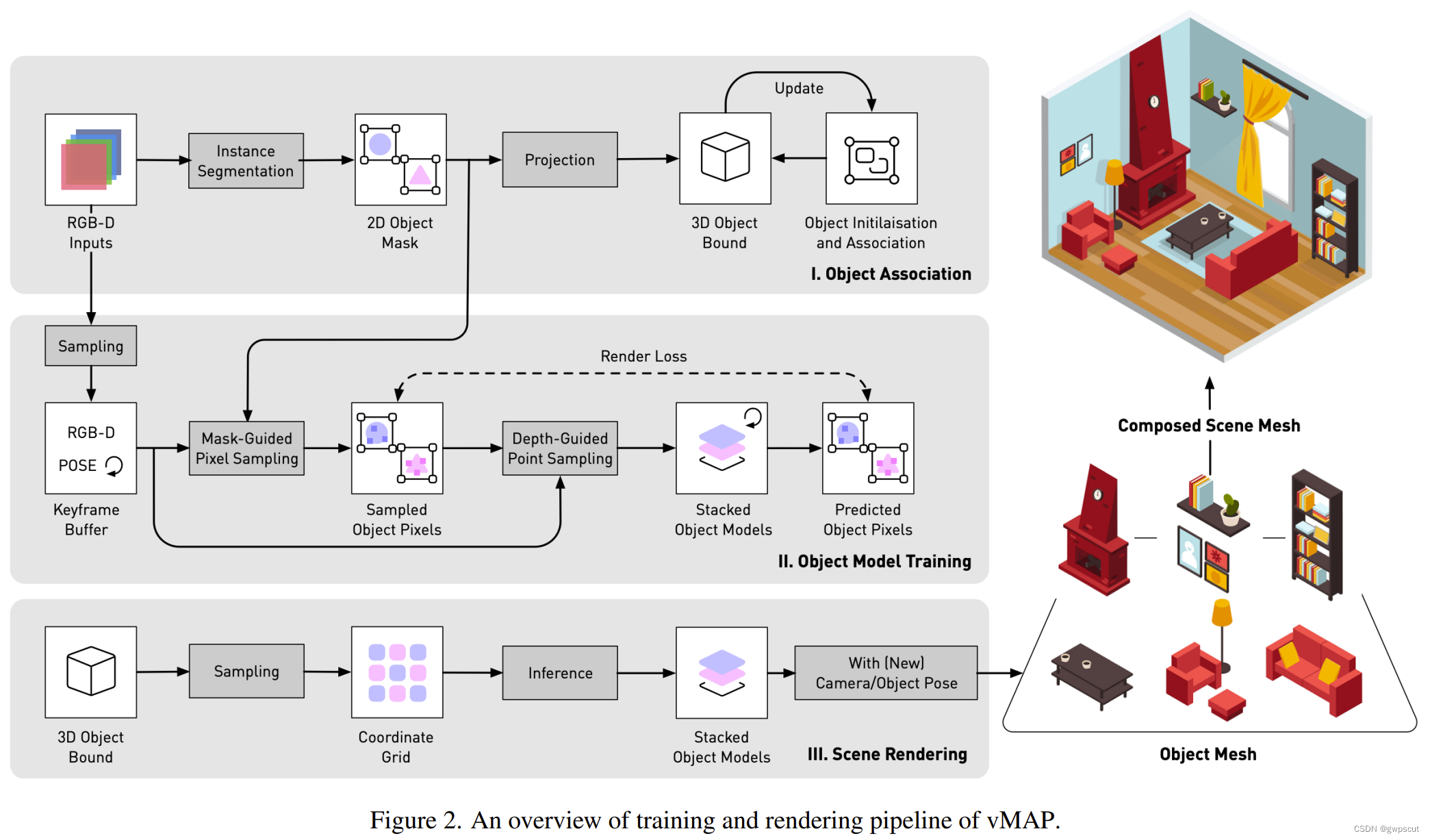
vMAP
vMAP:Vectorised Object Mapping for Neural Field SLAM
vMAP:Vectorised Object Mapping for Neural Field SLAM
这也是一篇物体级NeRF SLAM方案,同样是为每个目标单独分配一个MLP。vMAP的输入包括RGB图像、深度图、位姿、实例分割结果。位姿由ORB-SLAM3计算, 实例分割由Detic计算,再根据实例分割区域对RGB和深度图进行采样,之后就可以使用 NeRF进行训练和渲染。此外还需要执行一个帧间对象关联,包括语义一致性关联(类别 相同)和空间一致性关联(位置相同),用来判断是否是同一个物体。
vMAP处理的一个场景最多可以有50个独立的物体,并且有以5HZ的输出更新map。性能上挺不错的~同时论文也展示了在单个GPU下同时训练及优化大量的MLP object model。
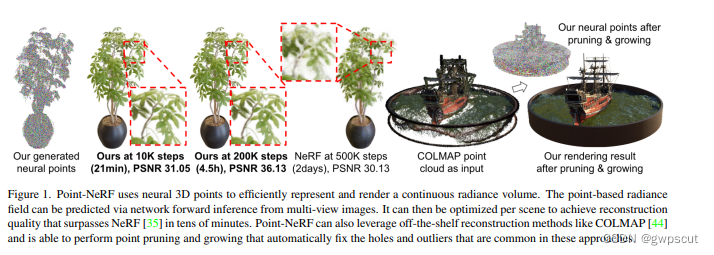
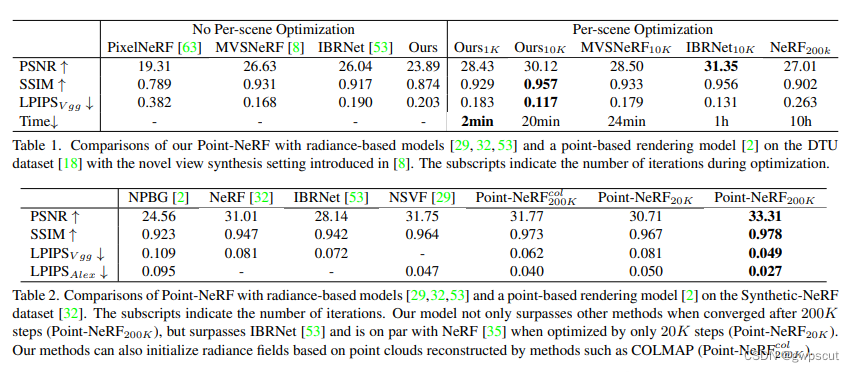
Point-NeRF
Point-NeRF:Point-based Neural Radiance Fields
Point-NeRF:Point-based Neural Radiance Fields
传统的NeRF渲染需要很长的时间,因为要求MLP把整个图像的一切都渲染出来,需要对每个场景进行优化。而另一方面,deep multi-view stereo方法可以较快进行场景的重建,因此Point-NeRF就是结合MVS和NeRF,过neural features相关联,使用neural 3D point cloud来渲染,实现训练时间快30倍。
Point-NeRF使用其他方法获得初始的点云来指导NeRF。Point-NeRF 表现形式为:每个点云都有一个neural feature,而每个neural point都编码了3D几何信息和点表面信息(appearance)。对于每个3D位置,采用MLP网络来累计它的体素密度(volume densiy)以及辐射信息(radiance)。
初始点云的获得使用了learning-based的MVS。然后采用deep CNN(用图像与2D特征点来做训练)来获取点云特征(这一波操作就属实有点很cv了hhh)。而多个视角下的这些点组成所谓的point-based radiance field。然后通过网络训练如何由这些neural point变成渲染后的三维模型。从下图也确实可以看到,Point-NeRF训练了10k steps(21分钟)的渲染效果要比NeRF训练2天的效果好上不少~
至于为什么呢?我也感到好奇,难道真的是加入的网络越多,网络越大效果就越好?如果把deep CNN提取特征点,改为非learning提取特征点。MVS产生的点云改为其他方式产生的点云,那是否也是效果更好呢?还是因为是MVS已经恢复出来一个比较好的三维结构,在此上做渲染,所以耗费不多就可以超越NeRF呢?
论文的主要contribution:
- 提出了以神经点云表征为基础的神经渲染方法。相较于 NeRF,Point-NeRF 的MLP 额外使用了神经点云(neural 3D point cloud)作为输入。这样做的好处是将三维场景表征的任务从MLP中分离出来,加快了训练速度。
- 结合传统 MVS 方法和CNN图像表征网络,Point-NeRF 的初始点云可以通过可泛化的神经网络由图像和其相应位姿推理得到。经过针对每一个场景的微调,Point-NeRF得以结合传统三维重建方法和神经渲染方法的优势,快速有效地获得高质量渲染结果。
- 传统 MVS 方法生成点云有时包含部分噪音以及表面孔洞,影响最终的神经渲染结果,本文通过对神经点云进行增长(growing)和剪枝(pruning)的方法解决这一问题。如上图右侧,COLMAP产生的点云是有空洞的,但是Point-NeRF就可以直接恢复得良好(那问题来了,输入多线激光雷达点云或者livox的点云也行吗?)
Point-NeRF的ppeline如下图所示。以图像序列及其对应的相机位姿为输入,通过 MVSNet 预测这些图像的深度图从而生成一个初始点云,再通过一个 VGG 网络提取多级图像特征将初始点云扩展为神经点云。这个初始的神经点云。为了合成新视图,只在神经点云附近进行可微射线积分和计算阴影。在每个阴影位置,聚集K个神经点邻域的特征,并计算辐射率和体密度。整个过程可以端到端训练。

至于具体的神经点云的渲染以及点云的增长和剪枝此处就不介绍了。下面直接看看它的实验效果。首先是定量分析。这里虽然有标出point-NeRF不同代数的结果,但是没有标出其他方法的代数。以及还有一个很大的疑问就是代数跟计算量相关联吗?就是会不会存在一种情况就是:Point-NeRF的参数量远大于某个baseline,而计算量也大于某个baseline。那如果代数*单代的计算量并不能划等号,单纯这样的对比好像没有什么意义。就相当于我用台超算跑一个小时比你用2048GPU跑10个小时要好,那能说明什么?
目前看来NeRF跟之前做过的超分是很类似的,都只是评估相似度,但是三维重建不是应该评价深度恢复的精度吗?还是说以及默认learning恢复的精度比较好,单纯只评估恢复的场景的纹理相似度?
定性分析:还是存在定量的问题啦~至于视觉效果,选一下总能选到比较好的~

下图的这个实验比较有意思,这其实就是跟depth completion比较类似,或者image inapinting很像。理论上按这个思路,通过如此稀少的点就重建稠密深度,那完全就可以用于lidar或livox了。

NeRF-SLAM?
NeRF-SLAM:Real-Time Dense Monocular SLAM with Neural Radiance Fields
NeRF-SLAM:Real-Time Dense Monocular SLAM with Neural Radiance Fields
这是第一个实现基于dense SLAM与NeRF的环境重建的pipeline,但它的NeRF部分其实也是做mapping的工作。
基于learning的单目三维重建已经是比较的成熟。但是单目稠密SLAM也好,直接进行单目深度估计也好,得到的深度图很多数值是不能用的(难以用来恢复几何geometrically和光度photometrically较精确的3D map)。而NeRF的发展,带来了光度恢复较好的优势(哦!这大概也就是NeRF系列的论文只看光度恢复效果的原因?),但是却不能实时,同时也是需要ground truth pose来作为输入的。(虽然像BARF这些工作也证明了pose并不是必须的)
本文利用单目稠密SLAM与分层体积神经辐射场(hierarchical volumetric neural radiance fields)的各自优势,通过单目dense SLAM来提供信息(pose与depth map,同时带有它们相应的uncertainty),利用这些信息进行深度边缘协方差加权的稠密深度损失训练,进而来实现实时构建环境的神经辐射场。通过所提出的uncertainty-based depth loss来实现良好的光度恢复以及几何结构的恢复。
整个算法的流程如下图所示
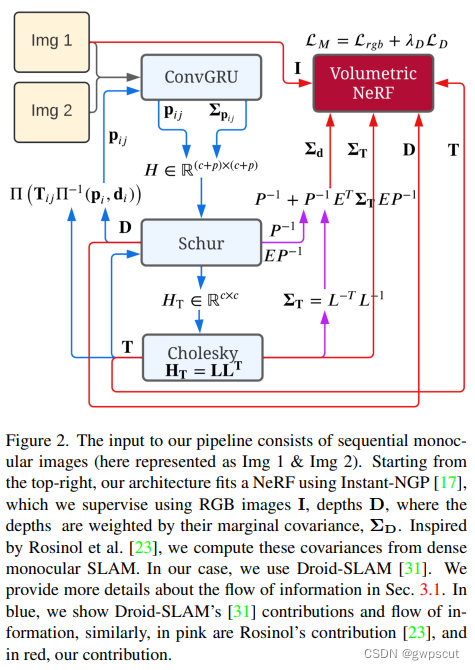
NeRF-SLAM的输入是连续的单目序列,采用Droid-SLAM (DROID-SLAM:Deep Visual SLAM for Monocular, Stereo and RGB-D Cameras,此处不展开介绍,下方给出该论文的视频)。Droid-SLAM的流程种也就是包括了图中的这个ConvGRU来估计稠密光流和光流权重,之后就是一个稠密BA问题估计位姿和深度,并将系统方程线性化为近似相机/深度箭头块状的稀疏Hseeian矩阵(以及舒尔补等处理了)最后把图像、位姿、深度图、位姿不确定性、深度不确定性全部馈送给NeRF进行训练。
DROID-SLAM:Deep Visual SLAM for Monocular, Stereo and RGB-D Cameras
定量实验的结果如下。光度学误差用PSNR来对比,几何误差用L1,所谓的L1是:we use the L1 depth error between the estimated and the ground-truth depth-maps as a proxy for geometric accuracy (Depth L1),应该也就是深度精度评估中的depth error了

关于depth error,常用的指标应该是下面几个。而所谓的L1应该是Mean Absolute Error(绝对平均误差)![]()

而视觉对比的话,则是如下:

而下面这个对比实验比较有意思:作者的应该就是noisy pose与noisy depth了,视觉效果上还是比较好的,可以跟用了GT depth的持平。但是跟GT Pose No Depth相比好像差别不大~
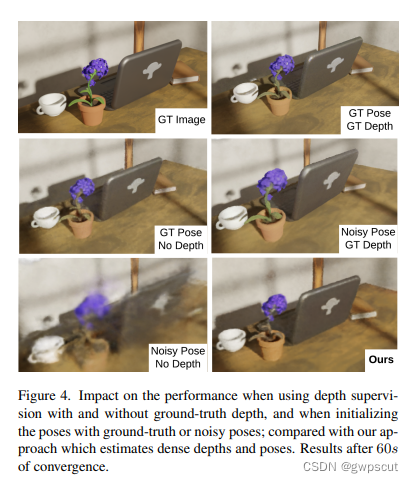
论文也分析了这个framework的缺陷就是内存占用比较大~
感觉这篇论文还是带来一些inspiration的,应该也算是NeRF进军SLAM的引路?
SMERF
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
SMERF:Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Expl
该成果最主要的突破就是没有利用3D Gaussian Splatting(关于Gaussian Splatting请见下面介绍)技术就可以实现NeRF大场景在笔记本以及手机端的实时流式加载和渲染。主要是通过分层模型(a hierarchical model)与蒸馏训练(distillation training strategy)。?
SMERF是以Merf: Memory-efficient radiance fields for real-time view synthesis in unbounded scenes为基础的,然后构建自主约束的MERF子模块的分层结构。由于还涉及到其他的结构,暂时理论部分看得比较迷糊,这里就先跳过了~
根据论文的描述,SMERF的提出有几个比较重要的研究基础:
1、提升NeRF的速度,NeRF虽然在效果上还不错,但是其在训练速度以及实时方面都存在耗时过长的问题,所以也就针对这个问题出现了不少的研究方案,比如通过预先计算一些与视角无关的颜色以及透明度,并将他们存储到一些稀疏的体数据结构,或者将一个大的场景分解为一些小的MLPs网格,可以提升训练以及渲染的效率,但是这种以空间换时间的做法一般会导致内存的消耗增加。
所以针对如何平衡内存使用以及渲染时间这个问题,又产生了类似MERF这方案,该方案就研究如何在受限的内存上实现这种MLPs网格的快速表达,这也是SMERF的研究基础。
2、提升NeRF的质量,NeRF在抗锯齿,去除毛刺以及稳定性方面提出了很多方法,但是这种方案在高分辨的情况下难以满足实时渲染的效率要求,因而论文就考虑使用蒸馏技术将训练好的模型蒸馏到MERF的子模型中,从而来提升渲染速度。
3、基于栅格化的视图合成,其实在这个方面比较具备代表性的就是3D Gaussian Splatting技术,这个技术其实是介于点云以及NeRF中间的一种表达方式,在表达上没有直接使用点,也没有用辐射场,而是使用了类似高斯椭圆这种“软点”,然后再利用神经网络训练优化进行这些软点的融合和叠加,从而取得比较好的表达效果,同时又可以利用当前GPU的栅格化渲染的能力,所以可以实现实时渲染,但是这种方法会在一些地方形成比较明显的“毛刺”,这也是SMERF重点对比的对象。
4、大尺度场景NeRF表达,NeRF最早的构建方式主要还是针对围绕对象的局部场景,但是要扩展到更大的场景目前在这个方面的两个主要做法就是:第一、融合抗锯齿技术的基于网格的辐射场;第二、基于相机的位置将大的场景分成多个区域的场景,分开为每个区域训练NeRF,但是这里面需要针对一些重迭的区域设置冗交叉的场景,所以难以扩展到城市级别。
而在SMERF的方案中,其将整个场景氛围多个子模型区域,每个子模型使用局部坐标,每个子模型都可以表达整个场景,但是大部门的模型容量只用于自己归属的区域,然后每个么分区中都实例化了一系列和当前空间位置铆定的MLPs权重,参数化延迟外观模型,它是一个渲染期间和相机位置相关的三线性插值函数,下图的b&c呈现的就是相机位于子模型内和子模型外的可视化处理方式。

5、蒸馏和NeRF,蒸馏的核心就是通过训练一个小模型来近似一个大模型的能力,把大场景的MLPs蒸馏到一个小的网格MLPs中以及把一些代价比较高的二次光线反射能力蒸馏到一个清凉的模型中。而Google SMERF的关键工作就是要将预训练好的大尺度、高质量的Zip-NeRF模型蒸馏到一系列的类似MERF的子模型中。

下面看看实验效果


说实话,这些图上我没有看出很明显的差异(就是一些模糊,sharp不sharp的区别吧?)数值指标差异也不太大,但是论文网站中给出的示例,可以发现根据视角的变化,后台持续在加载一系列的RAW文件,然后马上渲染出三维结构,这点倒是很惊艳的。
当然啦,此处所谓的大场景更多是一种相对的说法,指的是全部的室内空间(但也比下面几个工作中提到的large scale要大些~论文中提到最大可达300平米),而不是像城市那样的大级别的地图,且目前主页只是demo没有代码开源,这也是目前看到的第一个在手机端可以实现实时的NeRF渲染的工作了。
Nerfies
Nerfies:Deformable Neural Radiance Fields
Nerfies:Deformable Neural Radiance Fields
这是第一个可变形场景的NeRF(主要就是针对场景并不是刚体的,是可以形变的),如下图所示,就是从多个不同的视角下拍的图片,合成一个新的视角。这是通过continuous volumetric deformation field以及对应的elastic regularization来实现的。

Pipeline 方面应该就是在传统的NeRF前面多加了个code以及deformation field进而生成canonical(范式) 的表达,利用这个表达来反应不同的观测量。

仅优化位姿
与采用NeRF来进行mapping相反,这个类型的工作是使用NeRF反过来优化pose,但如果只是设计损失函数再梯度回传的话,定位精度应该很难和传统SLAM比。
Photorealistic and differentiable rendering of NeRF enables many applications such as direct pose optimization and training set expansion!
iNeRF
INeRF:Inverting Neural Radiance Fields for Pose Estimation
INeRF:Inverting Neural Radiance Fields for Pose Estimation
本文就是使用NeRF来反过来优化位姿。通过image获取camera相对于3D 物体或者场景的6-DoF pose。通过NeRF渲染的图像与observed image的光度误差来计算位姿。
iNeRF的输入有三个:
- 当前观测的图像
- 初始估计的位姿
- NeRF表征的3D场景或者oject
这其实就有点像PTAM中的2D-3D model alignment,用直接法来估算pose,只是需要解决如何构建NeRF与image直接的光度误差。那么这个思路就非常的直接了~如下图所示。通过不停的迭代,直到渲染的image与观测的image对齐

当然这个计算量应该是巨大的,INeRF中还通过一些策略来sampling合适的point来构建优化。同时采用INeRF也可以给NeRF提供pose(这应该就是鸡生蛋、蛋生鸡的最基本的SLAM问题)。整个pipeline如下图所示

前面和传统的NeRF一样,只不过后面渲染图像和真实图像的光度误差反过来又优化位姿。
一个定性的实验如下:其中的百分比代表了用了百分之多少的数据来训练NeRF,而后面+INeRF就代表用INeRF的pose来提供训练的pose。右侧四栏其实可以看到用了INeRF来提供pose的效果更好。

至于pose估计的精度嘛~感觉这个验证不够说服力
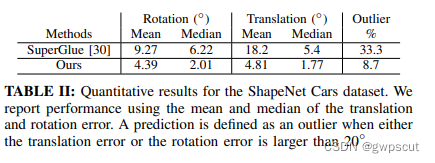
个人感觉这篇论文是提供了一个很好的思路,但是实验感觉没有太大的说服力,也没有很好验证算法的有效性。
NeRF-Loc
NeRF-Loc:Visual Localization with Conditional Neural Radiance Field
这也是一篇NeRF模型和图像直接匹配进行定位的文章。论文的框架如下。这篇论文是re-localization,那应该只是一个解决重定位的问题(不过INeRF本质上也是一个重定位而不是轨迹推进吧)?利用学习到的条件NeRF三维模型,计算3D描述子,直接与图像匹配,实现由粗到精的视觉定位。
类似于INeRF,也是采用NeRF来作为3D场景的表达(不同的是,INeRF只能在pre-training scene下定位,泛化能力与场景的先验之间是互相矛盾的~),通过利用feature matching以及场景对应的坐标,模型学习可推广知识和场景先验。也提出一个appearance adaptation layer的结构解决training和testing之间的gap。

整个Pipeline里场景表示为可泛化NeRF,从3D场景中随机采样点,并将3D点馈送到NeRF模型中以生成3D描述子。然后直接根据3D和2D描述符来匹配,由PnP解算相机位姿。因此大大提升了泛化能力以及对pre-training scene的要求降低了。
作者采用conditional NeRF model,它可以产生任意3D locations下的3D特征。为了保持泛化性,该conditional NeRF model建立在一个支持集(support set)上,支持集由几幅给定的参考图像和深度图组成。基于这个支持集来产生3D描述子。模型不仅在多个场景的联合训练学习了一般匹配,还在每个场景优化过程中以残差的方式记忆了基于坐标的场景。
论文中conditional NeRF模型的架构,通过新视图合成和3D-2D匹配来共享任意三维位置的特征生成器。
为了解决训练支持图像和查询图像之间的外观变化,还提出了一个外观自适应层,在匹配之前查询图像和三维模型之间的图像风格对齐。
虽然前面吹嘘了一顿。但从contribution中可以看到,所谓的conditional NeRF model是multi-scenes pretraining then per-scene finetuning。简而言之就是“50步笑百步”,总之就是比INeRF等更好🤭
而提出的conditional NeRF模型架构如下:

appearance adaptation layer的结构如下:

这里就不深入去看了。直接看看结果如何:定量分析(localization基本就是只看定量分析啦~),确实比其他的learning的方法都好些(当然是没有跟非learning的方法对比的,同样的实验也是很不solid的)

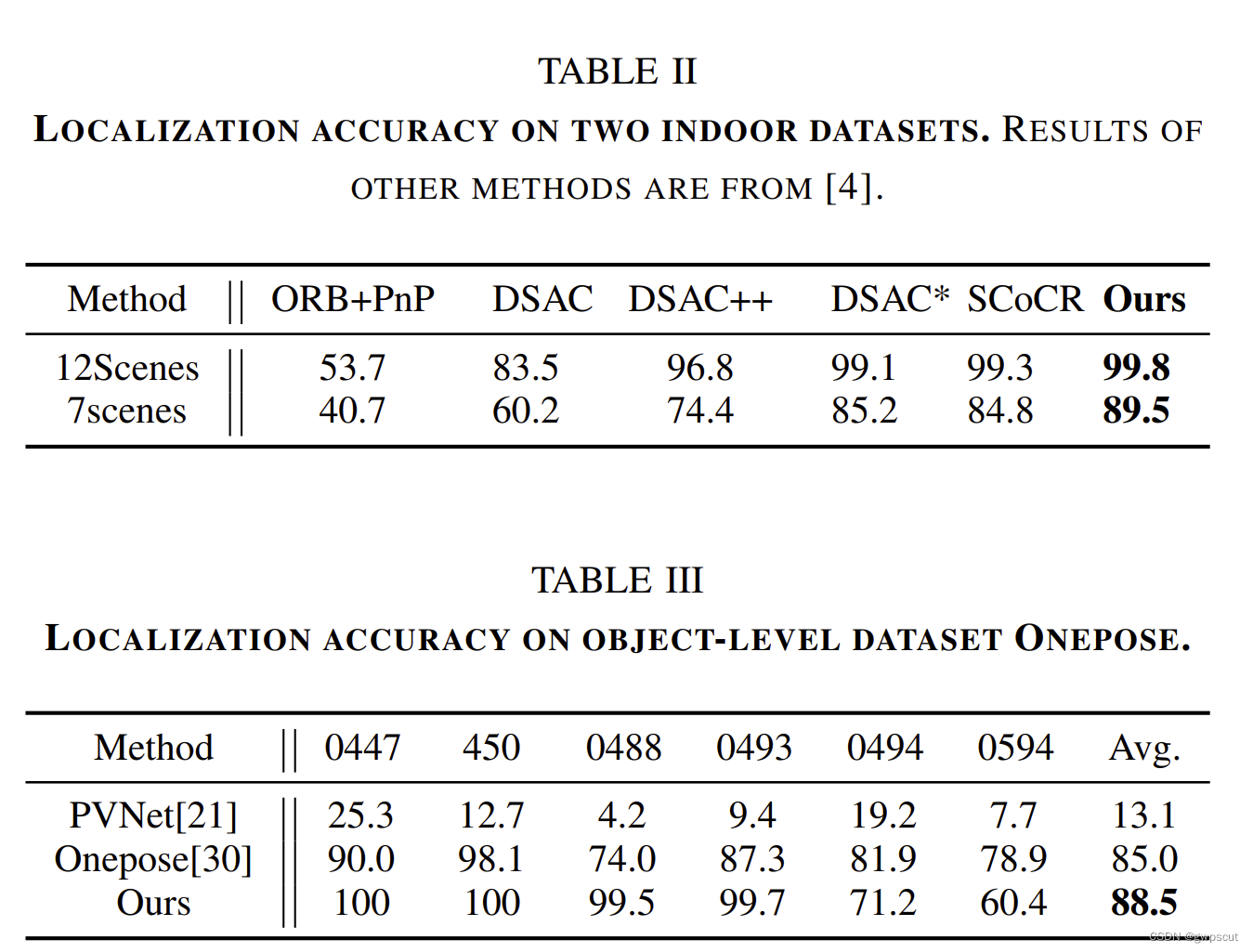
Loc-NeRF
Loc-NeRF:Monte Carlo Localization using Neural Radiance Fields
Loc-NeRF:Monte Carlo Localization using Neural Radiance Fields
这是将Monte Carlo定位与NeRF结合的一篇工作。大部分的NeRF-based 的定位方法需要较好的初值位姿,这其实是很搞笑的,一个定位系统每次计算都需要一个良好的位姿作为输入(甚至ground truth pose),那就没有意义了。因此本文采用Monte Carlo来提供NeRF-based localization所需要的初值。由于这篇论文本质上就是多加了蒙特卡洛而已,所以理论甚至连图都没有可以展示的,也没有跟其他算法对比定位的精度~
NeRF-VINS
NeRF-VINS:A Real-time Neural Radiance Field Map-based Visual-InertialNavigation
NeRF-VINS:A Real-time Neural Radiance Field Map-based Visual-InertialNavigation System
这项工作是OpenVINS的扩展(huangguoquan老师团队的工作),首先离线训练NeRF,然后基于NeRF地图进行定位和导航。充分利用NeRF新视角合成的能力,处理有限视角和回环问题(感觉更像是用NeRF来做回环匹配中的一环,其余应该就是原本的Open-VINS),实现基于NeRF地图的定位和导航规划。同时要求整个系统可以在嵌入式设备上运行。
传统的基于关键帧进行定位的策略,由于FOV较小,容易陷入局部优化,因此效果比较差。因此本文提出了基于NeRF的VINS,采用基于滤波的优化框架来处理单目image、IMU以及NeRF合成的地图。同时可以pose estimation的频率可达15HZ(在Jetson AGX平台上)。
其实思路很简单,就是合成当前图像的临近视角图像,用这两幅图像进行匹配和定位,特征提取使用的是SuperPoint。整篇论文其实更像一个工程问题,为了在嵌入式设备上落地,用了大量的TRT、CUDA等技巧,生成图像的时候为了实时运行也降低了分辨率。

实验效果如下:可以看到论文所提出的算法确实效果比较优异,比VINS-Fusion、ROVIO、OpenVINS等都要好不少。

并且对于环境的变换也有较好的robustness(当然,这个所谓的环境变换个人认为比较牵强,某种程度上还是同一个环境,但这也是learning的局限了)。

个人认为本文比前面几篇NeRF-localization虽然创新性不一定好很多,但至少实验是有说服力,且实际很多的。但是个人觉得NeRF做localization不是很有必要,虽然NeRF-VINS实验上取得了比非learning的效果要好,但是这也可能只是单一的场景,且以大量的计算量与对场景的预学习带来了,实用性还是不如传统方法。
位姿和NeRF联合优化
将位姿和NeRF放到一起优化,也就是SLAM中的localization与mapping。在NeRF SLAM应用里,位姿和NeRF联合优化是最主要的方向
iMAP
iMAP:Implicit Mapping and Positioning in Real-Time
iMAP:Implicit Mapping and Positioning in Real-Time
这是首个基于RGB-D相机,用MLP做场景表征实时SLAM系统。传统的稠密建图SLAM使用占用栅格图 occupancy map 或者 signed distance function 做场景表征,占用的内存空间很大;为此,论文提出利用一个MLP网络达到了整个场景的表征,然后给定相机视野,可以恢复给定角度下的图片。 因此,在保存地图时,不需要再保存整个房间的稠密的点云了,只需保存1M的网络参数。 甚至可以渲染房间各个地方的视野。?
论文验证MLP可以作为RGBD SLAM的唯一场景表征。同时也是第一个既优化NeRF又优化位姿的NeRF SLAM方案(虽然前面的abstract和introduction等都没有提及NeRF,但所采用的Implicit Scene Neural Network就是NeRF),基于RGBD跟踪,同时优化NeRF和位姿。论文采用PTAM的框架,两个线程,一个负责tracking,一个负责建隐式表征地图。论文里面的地图和常用的slam的地图不一样,这里没有保存地图的点云信息(关键点或者稠密点云),只有一个网络用来表征地图。传统的tracking都是根据显式地图里面保存的信息进行tracking的,但是现在没有显式地图。
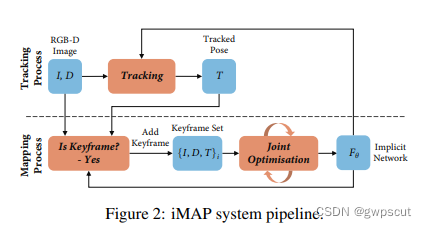
Tracking?固定网络(场景表征),优化当前帧对应的相机位姿(就是经典的2D-3D model alignment用RGB-D与逆渲染深度进行匹配计算出pose的增量);Mapping?对网络和选定的关键帧做联合优化。优化的损失函数也包括光度损失和深度损失两部分,后面很多工作也都是使用这两个损失。针对网络参数和相机位姿做联合优化(网络的参数其实就是对应的map,所以就是map与pose的联合优化)。使用ADAM优化器,使用的loss是光度误差和几何误差的加权。
其中定义的光度误差(photometric error):

几何误差 geometric error,使用到了深度的方差 :

具体的关键帧选取策略,是用逆渲染深度与RGBD获取的深度值比对,超过一定阈值则认为是关键帧。
同时论文也验证了iMAP在SLAM建图中可以进行很好的空洞补全。


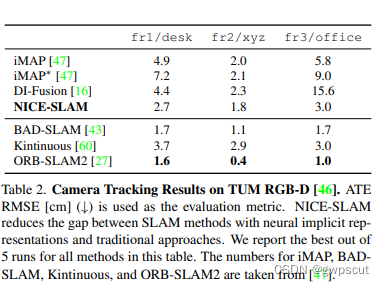
同时了,论文也在TUM数据集上对定位精度进行了验证:

作者强调虽然定位精度不够,但是mapping的效果还是比较好的~

BARF
BARF:Bundle-Adjusting Neural Radiance Fields
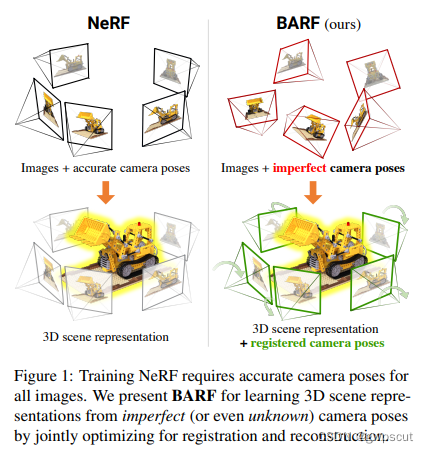
BARF:Bundle-Adjusting Neural Radiance Fields
传统的NeRF训练需要非常精确的位姿,而NeRF SLAM反向传播优化位姿时,对位姿初值很敏感,容易陷入局部最优。本文提出了Bundle-Adjusting NeRF (BARF) ,可以用不完美的(甚至不知道)相机位姿进行训练,同时学习三维表示(reconstruction,就是mapping)和配准相机帧(registration,也就是localization)。对于传统的sfm或者SLAM问题,就是把定位与建图用BA来进行处理计算的,因此,这篇文章也将BA引入NeRF SLAM的工作,给定不完美的位姿也可以训练NeRF。主要工作是应用传统图像对齐理论(image alignment)来联合优化位姿和NeRF,并且提出一个由粗到精的策略来优化位姿,使其对位置编码的噪声不敏感。
对于经典的图像对齐求pose,其实就是下面的光度误差最小化:

W就是warp function从2维映射到2维,由p维向量作为权重参数化,由于是个非线性问题,可以用梯度下降法,其中

如果用随机梯度下降法A就是一个标量学习率,而J(?dsteepest descent imag)则可以表示为:
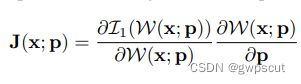
其中是warp雅可比矩阵限制对预定义warp的像素位移。基于梯度方法的配准核心是图像梯度
建模了一个局部的逐像素的表面和空间位移之间的线性关系,经常由有限差分来估计。显然的是如果每像素的预测之间有关系(即信号是光滑的),那么
的估计会更有效。

因此,通过在配准的早期阶段模糊图像,有效地扩大吸引区域和smoothening the alignment landscape,实践了从粗到细的策略。
另外一种计算P的方式,就是采用神经网络来学习coordinate-based image representation,神经网络参数是

或者对每个图分别学一个p:

神经网络使得梯度不再是数值估计而是网络参数对位置的偏导,不再依赖图像,这使得能泛化到三维情况。(这个推论有点没搞懂。。。)而后续的基于NeRF来对p进行求解,就是经过一系列推导得出:
一个相机的参数,而相机坐标系下的x也可以通过W映射变到世界坐标系下,那么颜色可以写成关于像素坐标u和相机位姿p的函数

这个网络参数就是学习的神经辐射场的三维表示。如果有M张图,那么目标就是优化NeRF学习三维表示,并且优化相机位姿
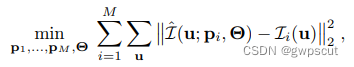
同样地可以推导出J的表达式用于更新p
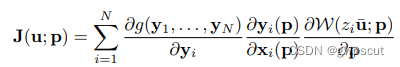
接下来看看实验。如下图所示。通过给gt pose加入高斯噪声来获得imperfect pose,可以看到BARF确实可以handleimperfect pose而传统的NeRF就会出现比较明显的失真。?


至于pose error方面,并没有有效的实验支撑~基本是要imperfect pose(加了高斯噪声的GT pose)个人认为这其实不够说服力的~
NeRF--
NeRF--:Neural Radiance Fields Without Known Camera Parameters
没有相机参数(包括内参和位姿),只有RGB图像时无法训练NeRF。因此NeRF--提出将相机内参、外参(位姿)设置成可学习的参数,其余部分与NeRF步骤相同。

将相机内参和外参设置为可学习的参数,在训练时先将相机参数设为一个固定的初始化值,通过这个相机参数和并根据NeRF射线积分,从而获得对应点的体密度和RGB,获得完整图像后计算光度误差。NeRF--可以未知相机的RGB图像来端到端地训练整个pipeline。

论文将NeRF--的framework建模为:

其中Π 代表了相机的参数,包括了内参与6DoF pose.Θ是NeRF对应的mapping映射的参数(NeRF model)。这一思路应该是类似于sfm中的BA,也跟上面的BARF类似(至于具体如何求解这个优化函数,就看看原文吧哈,此处直接跳过了~)。
此外,为了提高模型的效果,可以重复优化相机内参,即将训练完后的相机内参保存为新的初始化值,重新训练。
在不知内参和位姿的情况下,也可以达到与NeRF相当的重建效果,恢复的位姿也和COLMAP持平。

NICE-SLAM
NICE-SLAM:Neural Implicit Scalable Encoding for SLAM
NICE-SLAM:Neural Implicit Scalable Encoding for SLAM
现有的NeRF-SLAM由于仅仅采用全连接层,没有包含局部的信息(比如iMAP仅仅有一个MLP来代表整个场景)。具有以下问题:
1、场景重建过于平滑,丢失高频细节
2、大场景存在网络遗忘问题,难以处理大尺度下的mapping
因此,本文通过引入基于特征网格的层次场景表达(hierarchical scene representation),嵌入多层局部信息(multi-level local information,使用多个MLP组合多分辨率空间网格),并使用预训练的几何先验实现大尺度室内场景重建。
对于一个真正有意义的SLAM系统应该具备以下几点要求:
- 实时性
- 对于没有观测到的区域能做出合理的预测
- 可以用于大尺寸环境
- 对于噪声或者遗漏的观测具有鲁棒性
NICE-SLAM分为Tracking和Mapping两部分,Tracking根据输入的RGBD信息估计位姿

Mapping生成RGB和Depth来做深度和光度损失(引用前面iMAP提到过的光度误差和几何误差)。

Mapping包含Mid & Fine-level、Coarse-level、Color-level。首先由Mid Level进行重建,然后使用Fine level进行refine精细化。Mid level优化网格特征,Fine level捕获更小的高频几何细节。Coarse-level用来捕捉高层的几何场景,例如墙,地板,等具有几何结构的物体(可以保证Tracking不会太差),用于预测未观测到的几何特征,还有外插的能力(未见视角的合成)。Color-level储存颜色信息,用于生成场景中更为细致的颜色表征,从而提高在追踪线程的准确度。

关于提到的几种特征的表达方式就先不深入学习了,直接看看效果吧。mapping方面确实比iMAP好不少

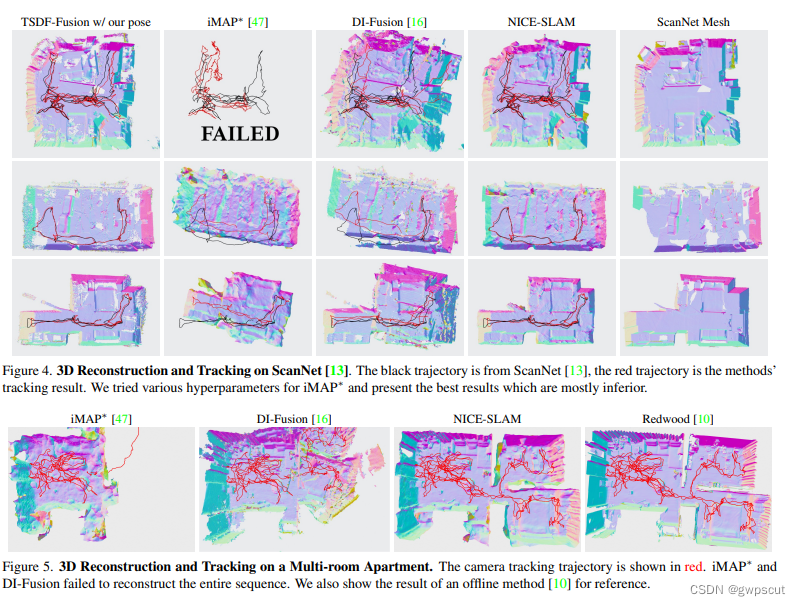
在TUM数据集上的定位精度的对比,可以发现还是不如ORB-SLAM2这些传统方法。
Vox-Fusion
Vox-Fusion:Dense Tracking and Mapping with Voxel-based Neural ImplicitRepresenta
Vox-Fusion:Dense Tracking and Mapping with Voxel-based Neural ImplicitRepresentation
传统的NeRF使用单个MLP,所以难以表达几何细节,并且很难扩展到大场景。将NeRF与稀疏体素网格(volumetric fusion methods,采用voxel-based neural implicit surface representation来渲染每个voxel中的场景)结合,使用八叉树结合莫顿码实现体素的快速分配和检索。同时,再通过多线程技术来实现实时。
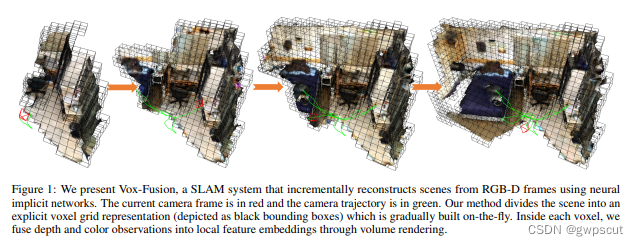
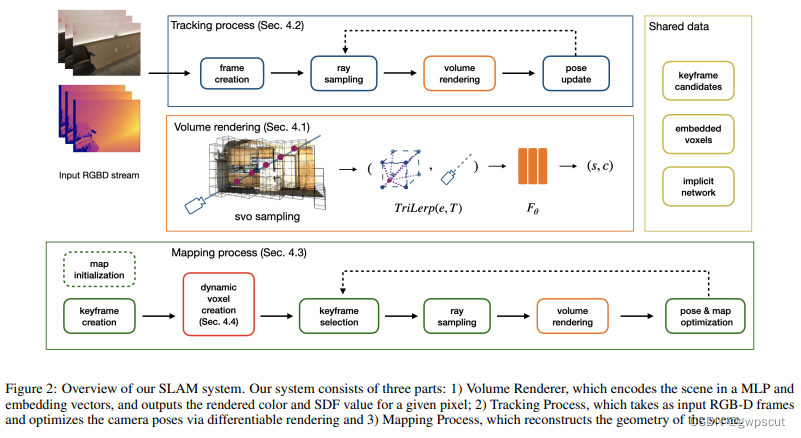
Vox-Fusion将体密度更改为了体素,存储的是SDF和RGB。Vox-Fusion由三部分组成:1、体渲染,将场景编码为MLP和嵌入向量,并输出给定像素的渲染颜色和SDF值;2、跟踪过程,将RGB-D作为输入,并通过微分优化相机姿态;3、建图过程,重构场景的几何形状。Vox-Fusion支持场景的动态扩展,这就意味着它不需要像之前的NeRF一样先预定义地图大小,而是可以像SLAM一样增量得去构建地图。
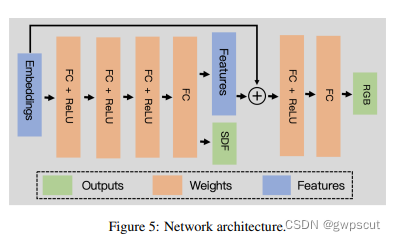
体素渲染的网络结构如下图所示。输出中包含了SDF与RGB信息
相较于iMap和NICE-SLAM,各项指标都有了全面的提升。主要对比的点是Vox-Fusion使用更大的分辨率也可以得到更多的高频细节。如下面的定性对比,即使使用比NICE-SLAM更大的分辨率,还是对桌腿、花这种更细小的物体重建效果更好,而NICE-SLAM对这些高频细节不敏感。


而定位精度上却没有跟传统方法进行对比

NoPe-NeRF
NoPe-NeRF:Optimising Neural Radiance Field with No Pose Prior
NoPe-NeRF:Optimising Neural Radiance Field with No Pose Prior
虽然已经有好些用NeRF来联合优化pose与map的工作了,但是在相机运动较大(dramatic camera movement,等同于large camera motion)时还是存在挑战。因此,本文引入无畸变单目深度先验(undistorted monocular depth priors),它是通过在训练期间校正尺度和平移参数生成的,从而能够约束连续帧之间的相对姿态,同时构建新的loss function来实现这一约束。
其他的基于NeRF的pose estiimation 方法局限于forward-facing scenes,很难处理大运动的情况。这主要有以下两个原因:
- 没有考虑images之间的相对位姿。
- 存在shape-radiance ambiguity(几何-辐射模糊性)(几何-辐射模糊性(shape-radiance ambiguity)指的是一种现象:即在缺少正则化处理的情况下,本应该出现结果退化(degenerate solution,不同的shape在训练时都可以得到良好的表现,但是在测试时效果会明显退化)的情况。这也是NeRF++解决的点)
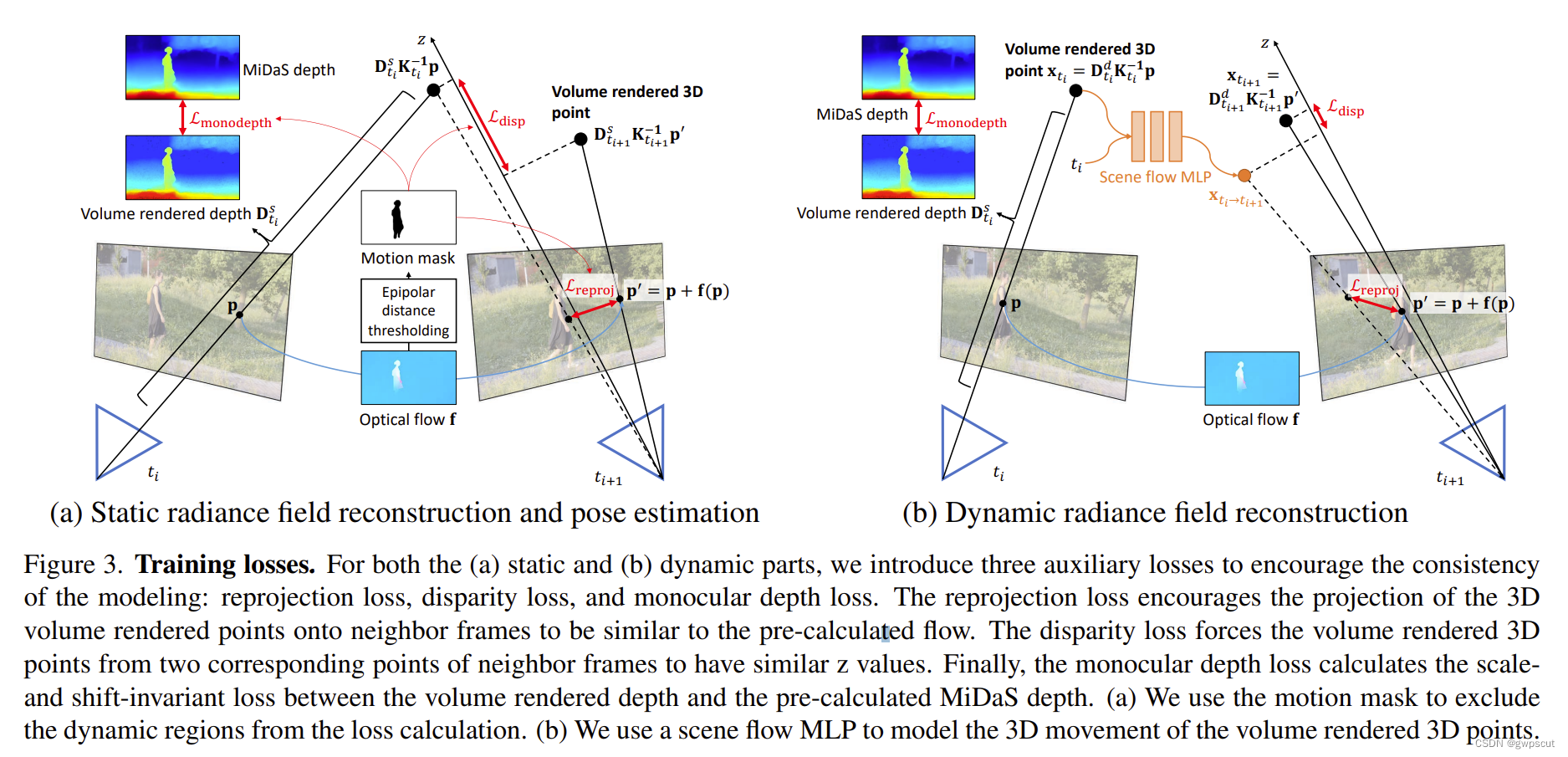
NoPe-NeRF的输入是RGB序列,首先从单目深度估计网络(DPT)生成单目深度图,并重建点云,然后优化NeRF、相机位姿、深度失真参数。训练主要也是依靠单目深度估计的深度图和渲染出来的深度图做损失。
具体来说,无畸变深度图提供了两个约束条件(Chamfer Distance loss与depth-based surface rendering loss,)。通过在无畸变深度图中反投影出的两个点云距离的来提供相邻图像的相对姿态,从而约束全局姿态估计。然后通过将无畸变深度视为表面,使用基于表面的光度一致性来约束相对姿态估计。

联合优化pose和NeRF的方程跟NeRF--一样:

在训练时,整体的优化函数可以写为:

其中优化了NeRF的参数Θ,、canera poseΠ,以及失真参数Ψ。而对应的loss为:

包含了photometric error,depth loss,point cloud loss,surface-based photometric loss。简而言之就是想方设法加些不同的loss,调出好一点点的效果,然后再给这些loss赋予意义。
相比起其他方法,pose的精度确实要好些。不过这里有个疑问,GT标着的是COLMAP呢,而所有的pose estimation trajectory都是跟COLMAP就没有跟真正的GT pose对比,这就有点不够说服力了。。。
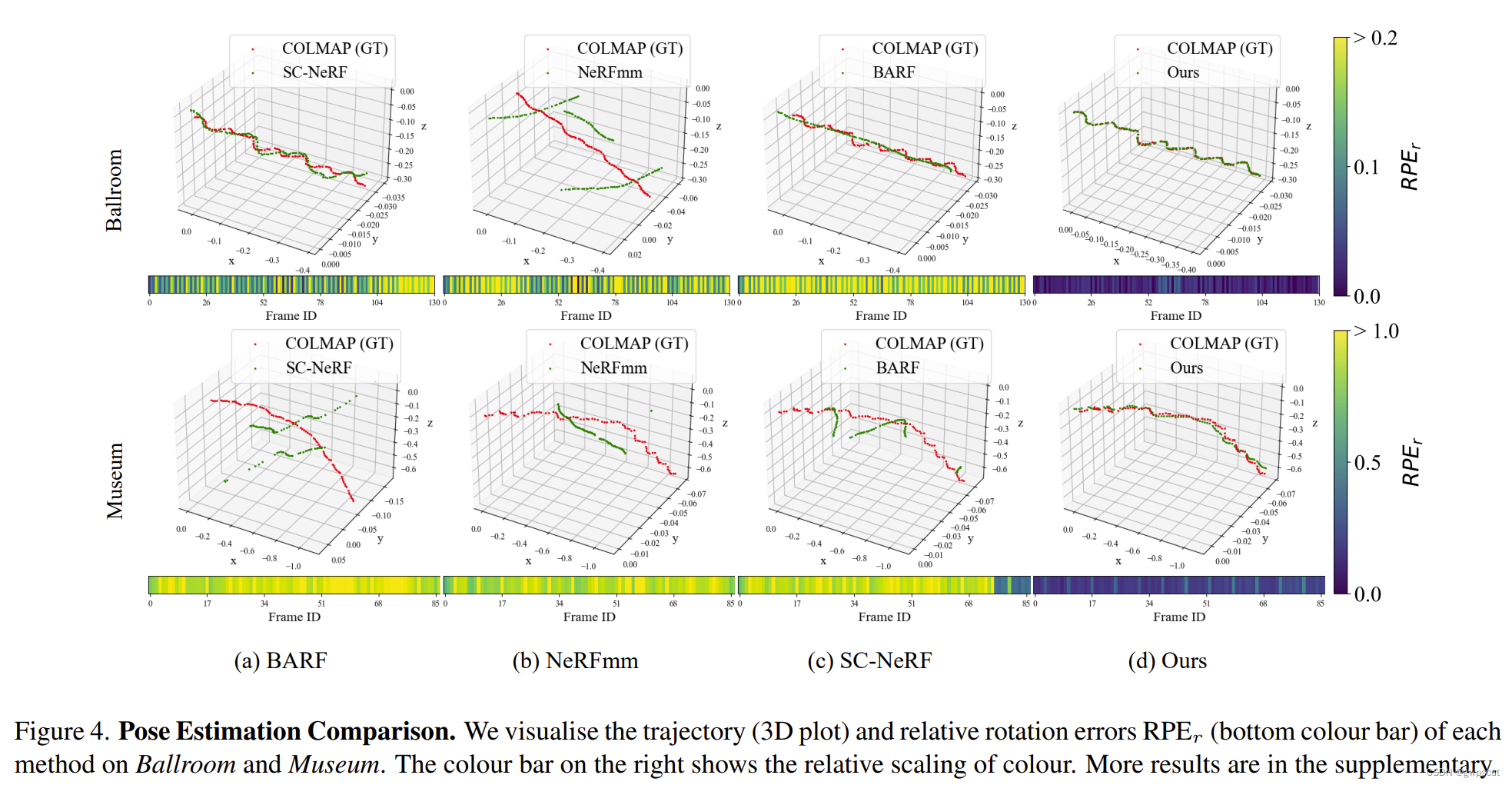

而渲染的效果也是比NeRFmm、BARF、SC-NeRF等几个方法要好的:

RoDynRF
Robust Dynamic Radiance Fields
Robust Dynamic Radiance Fields
RoDynRF: Robust Dynamic Radiance Fields
本身这篇文章研究的是动态NeRF(就是场景是动态的,里面有运动物体。但看论文里的图,估计也只支持小范围内的动态NeRF,并不支持大场景),但是和NeR--一样都可以在没有位姿和内参的情况下联合优化位姿和NeRF(但NeRF--只能用于静态环境),所以也算是NeRF SLAM的一种。

上面表格对基于NeRF的一些方法进行了对比。其中他们有以下缺陷:
- 传统的NeRF基于静态环境假设
- 动态环境下通常需要由SfM(COLMAP)估计的位姿不准确
因此,本文联合优化静态、动态辐射场(static and dynamic radiance fields)和相机参数(位姿和焦距)。
对于运动的目标论文是采用光流与Mask R-CNN结合的方式,同时也仅仅考虑场景中出现小量或者运动一致性比较强动态物体。
用静态和动态辐射场分别建模静态和动态场景。
静态辐射场就是一个普通的NeRF,使用坐标和方向作为输入,并预测体密度和颜色。静态部分的密度不随时间和观察方向而变化,因此可以使用查询特征的总和作为密度(而不是使用MLP),静态区域loss同时优化静态体素场和相机参数。静态场景采用Coarse-to-fine的形式,同时获取静态辐射场与camera pose
动态辐射场取采样坐标和时间t,得到正则空间中的变形坐标(deformed coordinates)。然后利用这些变形坐标对动态体素场中的特征进行查询,并将特征随时间指数传递给随时间变化的浅层MLP,得到动态部分的颜色、密度和非刚性。最后在体渲染之后,从静态和动态部分以及非刚性Mask获得RGB图像和深度图。
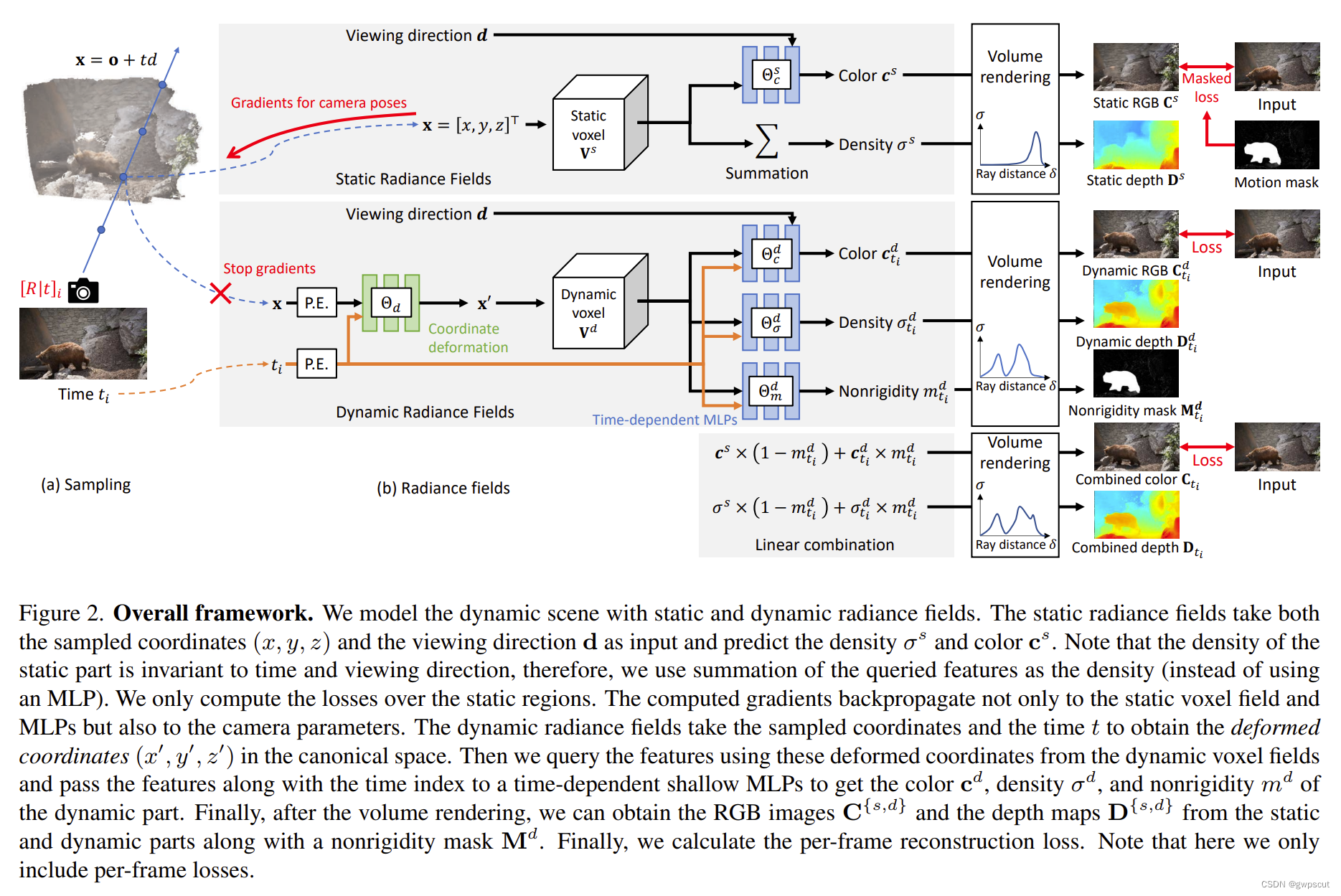
对于静态和动态部分,作者引入了三个辅助损失以促进建模的一致性:重新投影损失、视差损失和单目深度损失。重新投影损失鼓励将3D体渲染点投影到相邻帧上,使其与预先计算的流相似。视差损失强制要求来自相邻帧对应点的体渲染3D点具有相似的z值。最后,单目深度损失计算了体渲染深度与预先计算的 MiDaS 深度之间的尺度和平移不变损失。在(a)中,使用运动掩码将动态区域排除在损失计算之外。在(b)中,使用场景流 MLP 来建模体渲染3D点的3D移动。
从实验对比可以发现其他SOTA方案在动态场景下表现都稍差些。

而对于pose estimation的精度,跟大部分的NeRF-based localization一样,也就是做了而已。

DIM-SLAM
Dense RGB SLAM with Neural Implicit Maps
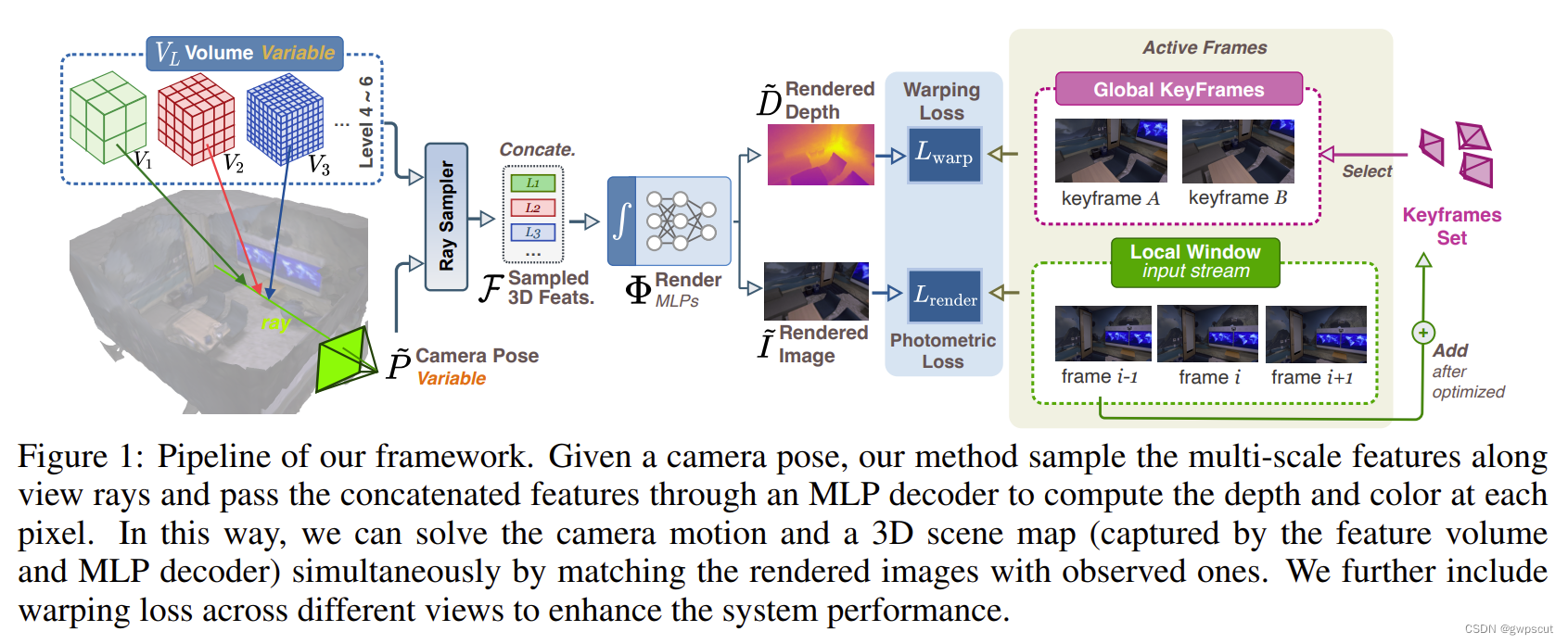
这篇论文宣称这是第一个具有神经隐式建图表示的稠密RGB SLAM(没有使用深度信息),只有RGB的情况下训练NeRF。DIM-SLAM是一个完全RGB的SLAM系统,不需要任何单目深度估计和光流预训练模型 (这个还是挺亮眼的),就能同时优化场景和相机位姿,相机位姿的精度甚至超过了一 些RGB-D SLAM方法。NeRF在没有深度监督的情况下难以收敛,为了解决这个问题,DIM-SLAM引入了一个分层的特征体素(hierarchical feature volume)以提高场景表示能力。DIM-SLAM在给定摄像机姿态的情况下,对多尺度特征沿射线进行采样,并通过MLP解码器将多尺度特征计算出每个像素的深度和颜色。 这样,通过将所呈现的图像与观察到的图像进行匹配,可以同时求解相机位姿和三维场景建图。同时,还用了不同视角下的warping loss来提高精度。
看看定位精度的定量对比,已经可以媲美ORB-SLAM2这种传统方法和DROID-SLAM这种学习方法。

而建图方面也比iMAP(RGB-D)在细节恢复的sharp程度上要好些

Orbeez-SLAM
Orbeez-SLAM:A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
Orbeez-SLAM:A Real-time Monocular Visual SLAM with ORB Features and NeRF-realize
这是一篇传统SLAM和NeRF结合很好的一篇文章,使用的是ORB-SLAM2和InstantNGP的组合方案,同样不需要深度信息。跟踪和建图同时运行,首先使用ORB-SLAM2 进行跟踪获取pose。mapping线程会通过三角化产生map points(稀疏的点云)以及联合pose一起做BA优化。如果定位精度较高并且建图线程不繁忙则添加为关键帧,再用map points和位姿去训练NeRF(Instant-NGP,NeRF的改进版可以提升traing speed)。同时通过NeRF的光度误差来进一步的优化pose。实际上,这一framework可以用于任何可以提供稀疏点云的SLAM(这一点个人认为是很好的inspiration)。

很多NeRF SLAM需要针对每个新场景重新训练,实际应用要求SLAM具备泛化性(without pre-training and generates dense maps for downstream tasks in real-time)。传统SLAM可以在NeRF训练初期提供较为准确的位姿,使其没有深度信息也可以快速收敛。作者宣称可以比NICE-SLAM快800倍(360~800)。至于所谓的pre-training-free准确来说应该是the training process is online and real-time without pre-training。
在TUM数据集下的定位精度对比,这个不太好,本身就是ORB-SLAM2提供的初始位姿,优化后还不如ORB-SLAM2了(但也只是稍弱于)。

至于mapping效果,个人觉得是有点为了速度牺牲掉mapping精度了,那篇同样是RGB-D输入,感觉比NICE-SLAM要差些。

GO-SLAM
GO-SLAM:Global Optimization for Consistent 3D Instant Reconstruction
GO-SLAM:Global Optimization for Consistent 3D Instant Reconstruction
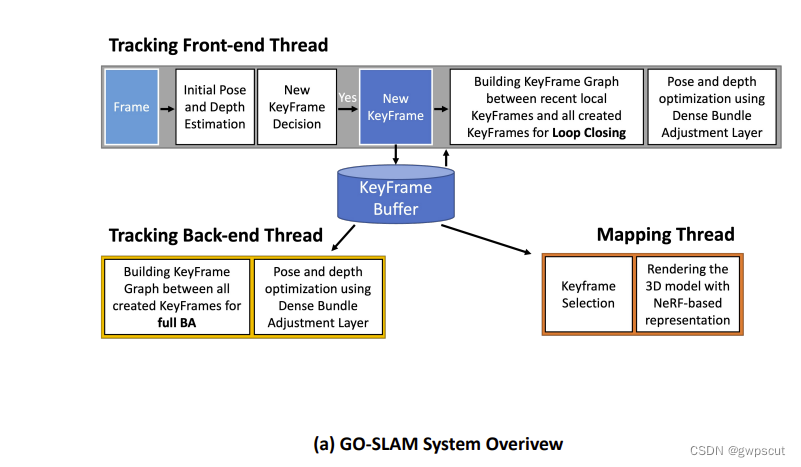
NeRF SLAM定位精度较低,且重建的时候存在失真。因此GO-SLAM使用BA和回环来优化全局的位姿,同时实现实时的重建。GO-SLAM本身是基于DROID-SLAM和Instant-NGP的组合(有点类似与前面的Orbeez-SLAM,只不过上面用的是ORB-SLAM2+Instan-NGP),主要工作是引入了BA和回环模块。GO-SLAM由三个并行线程组成:前端跟踪、后端跟踪,以及实例建图。GOSLAM的前端跟踪线程是直接用的DROID-SLAM的跟踪模块,后面训练过程也是直接调用DROID-SLAM的预训练权重,只不过加入了新的回环和BA优化。然后使用RAFT来计算新一帧相对于最后一个关键帧的光流,如果平均流大于阈值,则创建新关键帧。后端跟踪线程的重点是通过全BA生成全局一致的位姿和深度预测。最后,实例建图线程根据最新的位姿信息实时更新三维重建。GO-SLAM的输入支持单目、双目与RGBD。
GO-SLAM主要还是基于NeRF进行稠密重建,可以发现相较于NICE-SLAM这些SOTA方案,GO-SLAM重建场景的全局一致性更好,这主要是因为它引入了回环和全局BA来优化累计误差。对比效果如下所示,虽然单目的效果好像比较差,但是RGBD的重建效果比其他的几个算法都要好上不少~

而比起DROID-SLAM在纹理恢复上要好些

下面来看看定位的效果。实验还是比较solid的,首先在EuRoc下,比ORB-SLAM,SVO这些方法都要好些,并且在传统方法failed的情况下仍然可以提供比较稳定的pose estimation。

而在TUM数据集上,效果就更加明显了。这应该是目前看到效果比较好也比较有实验说服力的工作了。

当然这么好的性能在硬件要求上可能要高些:

NICER-SLAM
NICER-SLAM:Neural Implicit Scene Encoding for RGB SLAM
NICER-SLAM:Neural Implicit Scene Encoding for RGB SLAM
这是NICE-SLAM的升级版,由RGBD输入改为了RGB输入。RGB数据没有深度信息,无法产生高质量的NeRF渲染结果。因此,论文引入了单目深度估计进行监督,同时还引入了warping loss来保证几何结构的一致性,此外还为SDF表征建立分层神经隐式编码。

NICER-SLAM以RGB流作为输入,并输出相机位姿,以及学习的几何和颜色的分层场景表示。实际上是在NICE-SLAM的基础上引入单目深度估计,同时融合了重建、颜色、位姿、光流、warping-loss、深度、Eikonal Loss损失等等。其实这篇文章的启发意义不大,但是证明了引入各种各种的损失可以提升性能(CV或者learning的常规操作~)。
重建效果对比,在只是用RGB的方法里效果不错,甚至和RGBD方法持平。

而定位精度方面,并不如Vox-fusion或者DROID等方法,更没有跟非learning的方法进行对比了。整体看上去不如前面的GO-SLAM与Orbeez-SLAM。


Co-SLAM
Co-SLAM:Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Co-SLAM:Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SL
Co-SLAM将场景表示为多分辨率哈希网格,以利用其高收敛速度和表示高频局部特征的能力。此外,Co-SLAM结合了one-blob编码,以促进未观察区域的表面一致性和补全。这种联合参数坐标编码通过将快速收敛和表面孔填充这两方面的优点结合起来,实现了实时性和鲁棒性。此外,通过射线采样策略允许Co-SLAM在所有关键帧上执行全局BA,而不是像其它的神经SLAM方法那样需要关键帧选择来维持少量活动关键帧。
1、使用one-blob编码提高哈希编码的连续性。从而保证了表面的完整性(smoothness and coherence,fast convergence and surface hole filling)
2、在所有关键帧上采样来训练NeRF(进行全局的BA优化),而不是像NICE-SLAM那样维护一个关键帧列表。
关于第一点。Optimizable feature grids, also known as parametric embeddings最近已经成为单片MLP的一种强大的场景表示替代方案,因为它们能够表示高保真的局部特征,并且具有极快的收敛速度(快几个数量级)。最近的研究集中在这些参数嵌入的稀疏替代方案上,如八叉树、三平面、哈希网格(Instant-NGP)或稀疏体素网格,以提高稠密网格的存储效率。虽然这些表示可以快速训练,非常适合实时操作,但它们从根本上缺乏MLP固有的平滑性和一致性先验,在没有观察到的区域难以填补孔洞。NICE-SLAM是一个基于多分辨率特征网格的SLAM方法的最新例子。虽然它没有过于平滑,能捕捉到局部细节(如下图所示),但它不能进行补孔,补孔可能会导致相机位姿估计出现漂移。

因此,Co-SLAM为输入点设计一个联合坐标和稀疏网格编码,将两者的优点结合到实时SLAM框架中。一方面,坐标编码提供的平滑性和一致性先验(本文使用one-blob编码),另一方面,稀疏特征编码(本文使用哈希网格)的优化速度和局部细节,能得到更鲁棒的相机跟踪和高保真建图,更好的补全和孔洞填充。此外。大多数NeRF-SLAM系统都使用从所选关键帧的一个非常小的子集中采样的光线来执行BA。将优化限制在非常少的视点数量会降低相机跟踪的鲁棒性,并由于需要关键帧选择策略而增加计算量。相反,Co-SLAM执行全局BA,从所有过去的关键帧中采样光线,这在位姿估计的鲁棒性和性能上得到了重要的提高。
Co-SLAM可以实现10+HZ的输出。
Co-SLAM首先将传统NeRF中的体密度改为TSDF,训练也是联合优化NeRF和相机位姿。Co-SLAM的输入是RGBD序列,场景表示: 使用新的联合坐标+参数编码,输入坐标通过两个浅MLP映射到RGB和SDF值。2)跟踪: 通过最小化损失来优化每帧相机的位姿。3)建图: 用从所有帧采样的射线进行全局BA,联合优化场景表示和相机位姿。(对于Co-SLAM的理论部分,特别是one-blob编码看得有点迷糊,先mark一下,后面再深入学习~)

实现效果轨迹精度的对比,在TUM上相比NICE-SLAM精度有所提升,但还是不如传统的ORB-SLAM2。

mapping方面比RGBD的NICE-SLAM有一点提升。但感觉没有特别明显,可能就是实时性好些吧?

雷达NeRF SLAM
LiDAR-NeRF
LiDAR-NeRF:Novel LiDAR View Synthesis via Neural Radiance Fields
LiDAR-NeRF:Novel LiDAR View Synthesis via Neural Radiance Fields
该工作提出第一个可微框架用于LiDAR新视图合成(differentiable end-to-end LiDAR rendering framework);本论文意在给定一个物体的多个LiDAR 视角,可以从任意的视角下的点云对物体进行渲染(学习3D点云的几何结构以及特征信息)。然而,传统的NeRF不能直接作用于点云(由于它只关注于学习独立的pixel而忽略局部信息,准确来说应该是只有photometric loss这对于点云是不适用的),而模拟器产生的却不够真实。
因此,首先将LiDAR点云转换为Range图像,在不同的视图中会突出显示一个对象以便于可视化。然后在每个伪像素上生成距离(x、y、深度)、强度(反射光强)和射线下降概率(ray-drop)的三维表示。通过利用多视图一致性的三维场景,以帮助网络产生准确的几何形状。注意,LiDAR-NeRF还会 学习LiDAR模型的物理性质,例如地面主要表现为连续的直线。同时,作者还提出一种结构正则化方法,以有效保持局部结构细节,从而引导模型更精确的几何估计;建立NeRF-MVL数据集,以评估以对象为中心的新LiDAR视图合成。

理论上,LiDAR-NeRF可以应用到所有自动驾驶LiDAR数据集。但目前大多数数据集都只有场景级的LiDAR观测,这篇文章对应的提出了以对象为中心的数据NeRF-MVL用于新 视图合成。
而所提出的NeRF-MVL数据集使用带有多个LiDAR的自动驾驶车辆来收集,车辆在一个正方形的路径上绕着物体行驶两次,一个大正方形,一个小正方形,还标注了常见的9个目标。

如上图a所示,把lidar 点云转变为range image representation。对于一个具有垂直平面上H束激光和水平方向上W个发射的LiDAR,返回的属性(例如,距离d和强度i)构成了一个H × W的伪图像。具体而言,对于伪图像(range pseudo image)中的2D坐标(h,w),有:

其中![]() 是 LiDAR 传感器的垂直视场角。相反,LiDAR 帧中的每个3D点(x,y,z)都可以投影到大小为 H × W 的伪图像上,如下:
是 LiDAR 传感器的垂直视场角。相反,LiDAR 帧中的每个3D点(x,y,z)都可以投影到大小为 H × W 的伪图像上,如下:

请注意,如果多个点投影到相同的伪像素上,则仅保留距离最小的点。未投影点的像素用零填充。除了距离之外,该范围图像还可以编码其他点的特征,如强度。
而由于上面所产生的伪图像跟普通的image不一样,因此对于NeRF也应该有所改变。详细的就请见原本解说吧,本质上这篇论文是把lidar变成特别的image然后再设计对应的loss以及正则化来实现渲染。
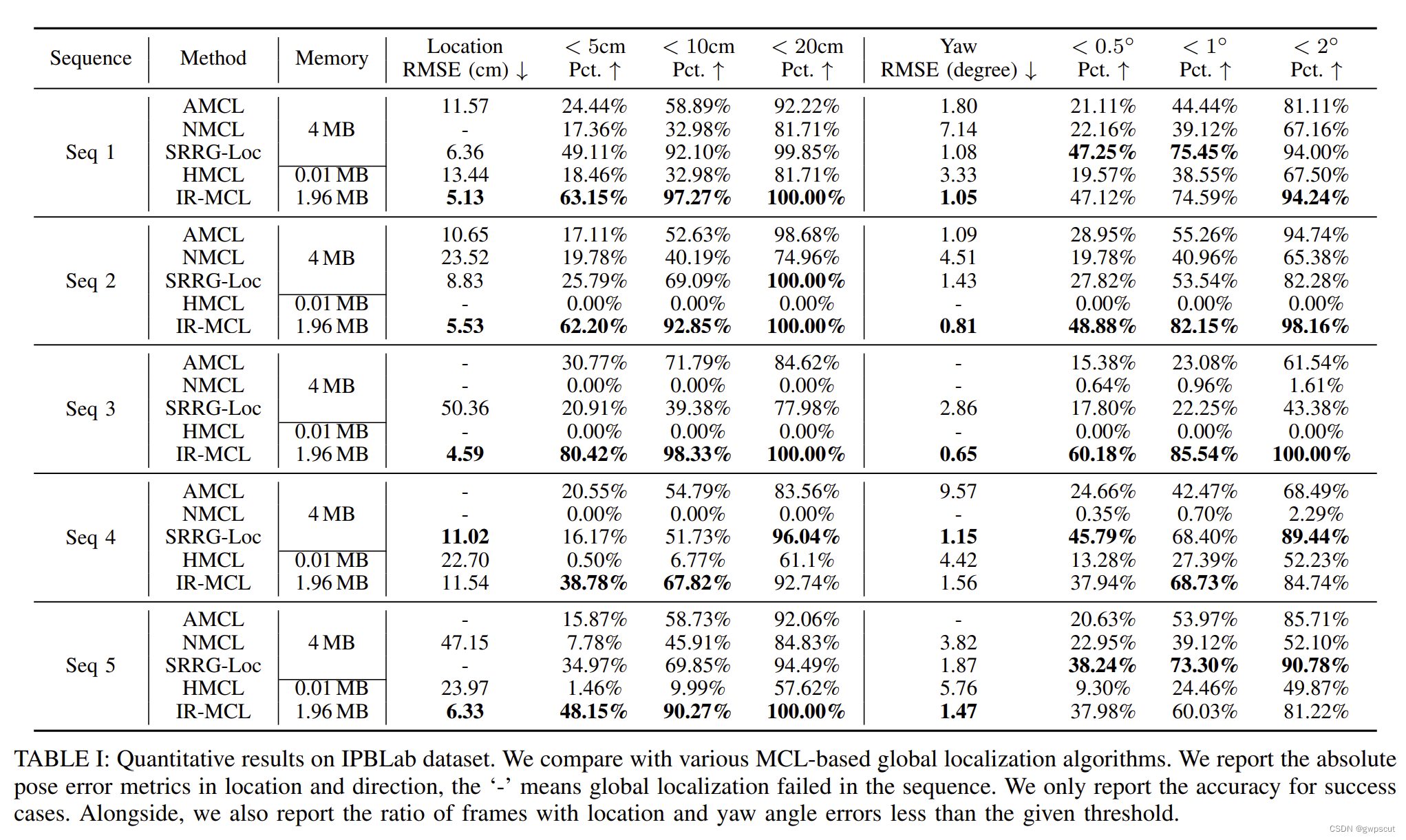
IR-MCL
IR-MCL:Implicit Representation-Based Online Global Localization
本文提出一种神经占据场(neural occupancy field, NOF),将NeRF扩展到机器人定位任务中的2D LiDAR地图。对于2D栅格地图而言,其离散的特性会损失很多场景的细节,从而导致定位不够精确。因此采用NeRF-based representtation来作为环境的地图表示。
利用一组已知准确姿态的2D激光扫描来训练,根据每个样本的姿态和2D雷达内参计算得到激光雷达每条射线的方向,接着在每条射线上均匀采样N个空间点。之后,NeRF将采样得到的每个空间点作为输入,并输出该空间点所对应的占据概率。对每条射线利用光线投射算法根据采样点深度及其占据概率渲染得到深度值。最终,估计出当前机器人姿态下可能会观测到的2D激光扫描,通过计算几何损失以及对预测的占据概率添加正则化来优化网络参数。基于该隐式地图,计算渲染扫描和真实扫描之间的相似性,并将其集成到MCL系统中就进行定位。

NOF是一个神经网络,以2D位置p =(x,y)为输入,并输出其占用概率,通过体渲染沿着LiDAR光束的所有预测来合成范围值。学习在场景中生成任意传感器位置的2D LiDAR扫描(scan),也就是学习pose与对应的LiDAR scan的关系,从而实现给一个pose就可以预测栅格的概率。

而对于观测模型,为每个粒子渲染一个2D LiDAR扫描,然后通过将合成的测量与来自LiDAR传感器的真实测量进行比较来更新粒子的权重。

实验也确实证明了用NeRF作为map representation的方式来做map-based localization可以提高定位的精度。并且地图的存储容量更少。
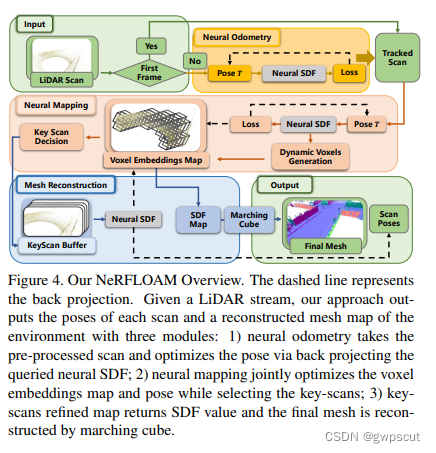
NeRF-LOAM
NeRF-LOAM:Neural Implicit Representation for Large-Scale Incremental LiDAR Odometry and Mapping
这篇论文应该是真正意义上的第一个LiDAR NeRF SLAM(同时实现odometry与dense mapping)。它主要包含以下三个模块:
- neural odometry。以预处理的lidar scan作为输入,通过查询neural SDF来优化位姿
- neural mapping。在选择关键帧(key scan)时联合优化Voxel embeddings map以及位姿
- mesh reconstruction。
这三个模块都主要基于提出的神经符号距离函数(Neural SDF),该函数将激光雷达点分离为地面和非地面点,以减少z轴漂移,同时优化里程计和体素的嵌入(Voxel embeddings ),并最终生成环境的稠密光滑mesh地图。而这种联合优化使NeRF-LOAM不需要预训练,直接泛化到新场景,这个算是摆脱了 NeRF对场景的依赖性。前两个模块作为前端和后端并行运行。第三个模块单独运行以获得全局网格地图和细化的扫描位姿。主要contribution如下:
- 基于Lidar数据 采用隐式神经方式计算里程计和建图
- 将基于稀疏八叉树的体素(sparse octree-based voxels)与神经隐式嵌入(neural implicit embeddings)结合,然后通过神经隐式decoder来解码为SDF(符号距离函数,signed distance function)。embeddings、decoder以及pose一起联合优化使得SDF误差最小
- 结合SFD模块采用动态生成策略(a dynamic voxel embedding generation strategy)和key-scans优化策略
- 动态生成策略是用来handle未知的大尺度室外环境,而key-scans优化是进一步refine pose和map,同时缓解灾难性的遗忘或预训练过程。
- online联合优化使得不需要预训练适应不同环境,增强泛化能力
对于所提出的neural SDF如下图所示。感觉单纯从图上看,这个结构与上面的LiDAR-NeRF的很类似,只是上面是变为range representation而此处是voxel embeddings。
对激光雷达发射的光线上的点进行采样,进行voxel embeddings操作后输入MLP(Neural SDF Query)。在当前给定的体素上,与该体素相交的射线并且和该体素产生交点 设置一个阈值来避免表面遮挡的影响 由于Lidar光线是由扫描位姿变换得到的,所以每条射线包含姿态信息 这样优化时就能同时优化位姿和体素嵌入。

与基于视觉的NeRF方法不同 SDF是直接表示场景的方法,所以不适合室外环境的Lidar数据所以对每个采样点通过体素嵌入的三线性插值进行回归

激光雷达提供了精确的距离测量 能够得到从采样点到射线端点的符号距离,即SDF值。如图所示 蓝线代表SDF的真实值 红线为近似值 当角度?θ \thetaθ接近0时 两个距离之间的差异可以显著 这个问题在z轴上更加显著 因为在Lidar扫描中约束z轴漂移的点较少。这里提出将Lidar点分为地面点和非地面点


论文定义了三种不同的loss来优化Neural SDF。此处就直接直接跳过了~
接下来直接看看实验效果:首先是mapping效果,感觉跟baseline相比提升没有很明显~

定位精度方面也没跟LOAM这些对比吖?个人看来不够有说服力

LONER?
LONER:LiDAR Only Neural Representations for Real-Time SLAM
LONER:LiDAR Only Neural Representations for Real-Time SLAM
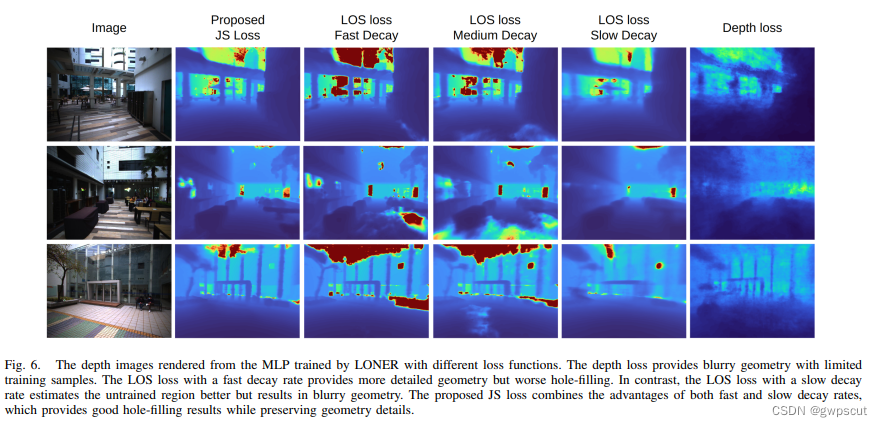
这是第一个可以实时的LiDAR-based NeRF-SLAM框架。LONER首先将雷达扫描降采样(将为5 Hz),然后用ICP跟踪(point-to-plane,相当于只用NeRF做mapping),并从场景几何中分割出天空区域。对于建图线程,是使用当前关键帧和随机选择的过去关键帧来更新,并维护一个滑窗来优化。跟踪和建图两个线程并行运行,但是建图线程的帧率较低,并准备关键帧用来训练NeRF。最后使用专门设计的损失函数(information-theoretic loss function)来更新位姿和MLP权重,生成的隐式地图可以离线渲染为各种格式,比如深度图和Mesh。

接下来看看实验。首先是一个跟NICE-SLAM和Lego-LOAM的精度对比,LONER的精度明显优于LeGO-LOAM,这个还挺惊讶的,因为本身LONER没有为SLAM设计什么特殊的模块。而NICE-SLAM的精度明显比其他两个低,还容易跟丢,这也很容易理解,因为NICE-SLAM本身 就是为室内场景设计的。这个实验也证明了LONER自身的损失函数是有效的。

然后是一个地图重建性能的定量评估,包括准确性(估计地图中每个点到真值中每个点的 平均距离)和完整性(真值地图中每个点到估计地图中每个点的平均距离)。LONER效果也 很不错。

同时也对不同的loss的效果进行杜比:
3D Gaussian Splatting
3D Gaussian Splatting是最近NeRF方面的突破性工作,对应论文“3D Gaussian Splatting for Real-Time Radiance Field Rendering”是2023年SIGGRAPH最佳论文。下面github列举了3D Gaussian Splatting相关的研究工作。实在太多了,留到以后做调研吧,此处mark一下~
此处主要看看下面两篇论文
1. 3D Gaussian Splatting for Real-Time Radiance Field Rendering
3D Gaussian Splatting for Real-Time Radiance Field Rendering
论文引入新方法实现了NeRF的实时渲染,能够在较少的训练时间中,实现SOTA级别的视觉效果,且可以以 1080p 分辨率进行高质量的实时(≥ 30 fps)新视图合成。具体而言,即从已有点云模型出发,以每个点为中心,建立可学习的3D高斯表达,用Splatting的方法进行渲染,实现了高分辨率的实时渲染,其中包含三个关键步骤:
-
3D高斯场景表示:从相机校准过程中产生的稀疏点开始,用3D高斯(3D Gaussians)表示场景,3D高斯保留连续体积辐射场的理想属性以进行场景优化,同时避免了在空白空间中进行不必要的计算。
-
交错优化和密度控制:对3D高斯各种属性(如位置、不透明度、各向异性协方差和球面谐波系数)进行了交错优化/密度控制,特别优化了各向异性协方差(anisotropic covariance)以实现场景的准确表示。
-
快速可见性感知渲染算法:开发了一种快速可见性感知渲染算法(fast visibility-aware rendering algorithm),该算法支持各向异性抛雪球(anisotropic splatting),既能加速训练,又能保持高质量进行实时渲染。
这里所谓的各向异性(anisotropic):指的是从各个方向上看过去,物体的外观表现都不同。而抛雪球(splatting):是计算机图形学中用三维点进行渲染的方法,该方法将三维点视作雪球往图像平面上抛,雪球在图像平面上会留下扩散痕迹,这些点的扩散痕迹叠加在一起就构成了最后的图像,是一种针对点云的渲染方法。
系统的框图如下所示:系统首先对SfM产生的稀疏点云进行初始化,创建3D高斯模型,然后借助相机外参(就是pose了)将点投影到图像平面上(即Splatting),接着用可微光栅化,渲染得到图像。得到渲染图像Image后,将其与Ground Truth图像比较求loss,并沿蓝色箭头反向传播。蓝色箭头向上,更新3D高斯中的参数,向下送入自适应密度控制中,更新点云。

首先对于上面的第一步,就是引入了各向异性的3D高斯分布,作为高质量非结构化的辐射场表达。每个3D高斯点云中的每一个点里面储存了:位置坐标,协方差矩阵(决定高斯形状),不透明度(用于Splatting),球谐函数(拟合视角相关的外观)。3D高斯的定义为:

其中3D高斯点云作为一种图元,在拥有场景表达能力的同时可微,且显式地支持快速渲染,其中的参数可在迭代优化的过程中更新。系统采用Splatting的方法可轻易将3D高斯点云投影到2D图像上,实现快速的?![]() 混合(即渲染)。渲染时,需要将3D高斯投影到2D。给定视角变换W,相机坐标系下的协方差矩阵Σ ′
混合(即渲染)。渲染时,需要将3D高斯投影到2D。给定视角变换W,相机坐标系下的协方差矩阵Σ ′
![]()
其中J 为投影变换仿射近似的雅可比矩阵。
直接优化3D高斯协方差不可行,因为协方差矩阵仅当在半正定情况下有意义,而对所有元素进行梯度下降的优化不能保证这个条件。因此,本文使用另一方法,将协方差矩阵分解为缩放矩阵S和旋转矩阵R:
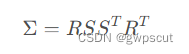
将S表达为3D向量s,R表达为四元数q,这样只需通过归一化保证q满足单位四元数的条件。
对于上面的第二步(交错优化和密度控制)点云中点存储的参数通过随机梯度下降策略,快速光栅化实现优化。Sigmoid函数将参数中的不透明度限制在?[0,1)?中。协方差矩阵中的尺度用Exponential激活函数。损失函数为?L1 loss 。而点云密度的自适应控制则如下图所示。

对重建不充分的区域进行处理,针对“欠重建”(under-reconstruction)区域,对点云进行clone,对“过重建”(Over-reconstruction)的区域进行split。判断重建是否充分的依据为梯度,若该点梯度过大,则该位置误差较大,需进行操作,而判断是哪种操作则是通过方差,若方差大,则点过大,需分割,否则克隆。该组件也周期性将不透明度重置为0,剔除不透明度太低的点,用于去除画面中靠近相机处学出的floaters,并周期性移除较大的高斯用于避免重叠。
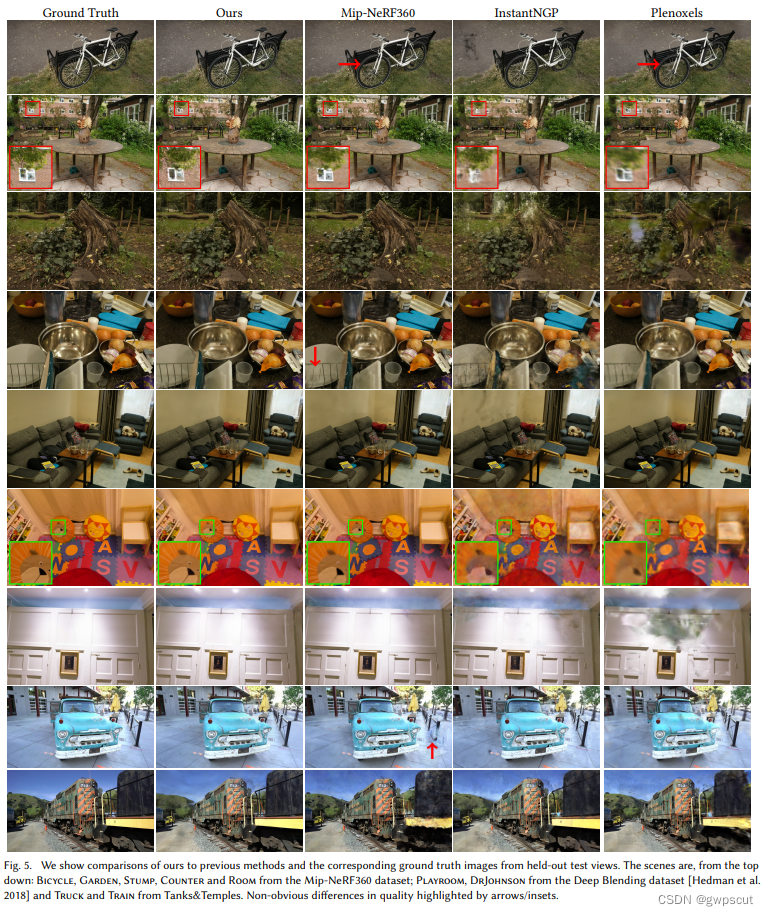
实验效果如下。好像没有实时性分析~
2.?SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
SplaTAM Splat, Track Map 3D Gaussians for Dense RGB-D SLAM
PS:调研的内容实在太多了,一轮下来不免有点囫囵吞枣,还是通过复现代码,实操测试来更深入了解吧~
参考文献
大盘点!22项开源NeRF SLAM顶会方案整理!(上) - 哔哩哔哩
大盘点!22项开源NeRF SLAM顶会方案整理!(中) - 哔哩哔哩
大盘点!22项开源NeRF SLAM顶会方案整理!(下) - 哔哩哔哩
论文笔记:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - 技术刘
3D Gaussian Splatting为什么牛啵?原理、应用场景及最新进展
Google NeRF实时大场景渲染重大突破,可终端流式加载~
CVPR2023 | Co-SLAM: 联合坐标和稀疏参数编码的神经实时SLAM
Instant Neural Graphics Primitives | Event Horizon
如何评价 NVIDIA 最新技术 5 秒训练 NERF? - 知乎
论文解读 | Instant Neural Graphics Primitives with a Multiresolution Hash Encoding - 知乎
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!