基于ChatGLM搭建专业领域问答机器人的思路
如果我们对ChatGLM进一步提出涉及专业领域的问题,而此方面知识是ChatGLM未经数据训练的,那么ChatGLM的回答效果如何呢?本节将考察ChatGLM在专业领域的问答水平,并尝试解决此方面的问题。
在使用ChatGLM制作专业领域问答机器人之前,我们需要了解ChatGLM能否完整地回答使用者所提出的问题。下面提出一个专业医学问题交于ChatGLM回答,代码如下:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
prompt_text = "小孩牙龈肿痛服用什么药"
"-------------------------------------------------------------------------------------------------------------------------------------------------------"
print("普通ChatGLM询问结果:")
response, _ = model.chat(tokenizer, prompt_text, history=[])
print(response)
这是一份最常见的生活类医学问答,问题是“小孩牙龈肿痛服用什么药”,在这里我们使用已有的ChatGLM完成此问题的回答,结果如图17-2所示(注意,在使用ChatGLM回答问题时,结果会略有不同)。
 图17-2? ChatGLM询问结果
图17-2? ChatGLM询问结果
这是一个较经典的回答,其中涉及用药建议,但是并没有直接回答我们所提出的问题,即“服用什么药”。专业回答建议如图17-3所示。

图17-3? 专业回答建议
其中灰底部分是对这个问题的回答,即通过服用牛黄解毒丸可以较好地治疗小孩牙龈肿痛。这是一种传统的治疗方案。我们的目标就是希望ChatGLM能够根据所提供的文本资料回答对应的问题,而问题的答案应该就是由文本内容所决定的。
下面我们分析使用ChatGLM根据文本回答问题的思路。一个简单的办法就是将全部文档发送给ChatGLM,然后通过Prompt的方式告诉ChatGLM需要在发送的文档中回答特定的问题。
显然这个方法在实战中并不可信。首先,需要发送的文档内容太多,严重地消耗硬件的显存资源;其次,庞大的数据量会严重拖慢ChatGLM的回答;再次数据量过大还会影响ChatGLM查询文档的范围。
因此,我们需要换一种思路来完成实战训练。如果只发送与问题最相关的“部分文档”信息给ChatGLM,是否可行呢?整体流程如图17-4所示。
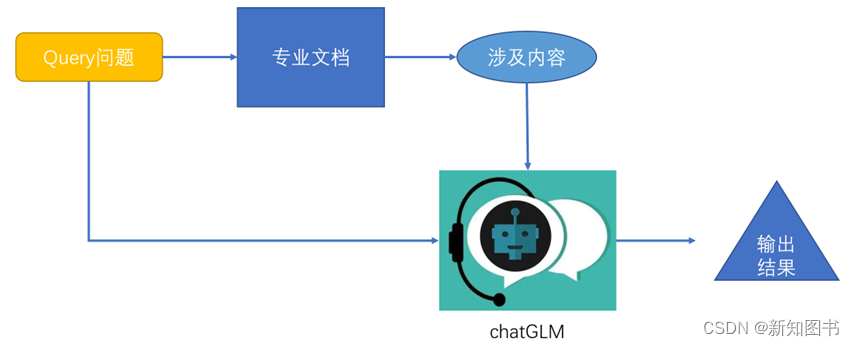
图17-4? 整体流程
这只是一个思路,具体是否能够成功还需要读者自行尝试。
本文节选自《从零开始大模型开发与微调:基于PyTorch与ChatGLM》,获出版社和作者授权共享。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!